深入理解Kubernetes探针和.NET服务健康检查机制
前言
随着越来越多的软件采用云原生和微服务架构,我们面临着更多的技术挑战,比如:
- Kubernetes如何在容器服务异常终止、死锁等情况下,发现并自动重启服务;
- 当服务依赖的关键服务(例如数据库,Redis)无法正常连接时,如何及时发出告警;
- 在需要同时部署有依赖关系的服务时,如何确保它们可以按正确的顺序进行初始化;
- ......
我将介绍如何利用.NET框架的健康检查机制以及Kubernetes的探针来确保微服务集群的稳定性和可靠性。
本文主要分为Kubernetes探针介绍,.NET健康检测机制介绍,最佳实践原则,以及一个简单的Demo。你可以在我的Azure仓库找到完整的项目文件,并在本地部署和测试:
k8s-helm-micro-services - Repos (azure.com) https://dev.azure.com/1903268310/k8s-helm-tpl/_git/k8s-helm-micro-services
https://dev.azure.com/1903268310/k8s-helm-tpl/_git/k8s-helm-micro-services
Kubernetes Probe
什么是探针
Kubernetes使用三种容器探针,分别是Liveness、Readiness和Startup,来检查容器的运行状态。
简而言之,探针检测需要在服务中创建健康检查接口,该接口根据语义正确返回服务当前的健康状态。然后,Kubernetes根据部署时的探针配置,自动调用服务的健康检查接口,并根据返回的状态码判断当前服务是否健康。
Kubernetes支持HTTP、TCP和Grpc三种类型的探针接口,本文将重点介绍HTTP类型的探针接口,其中大于等于200并且小于400的状态码表示服务健康,其他状态码表示服务不健康。
Liveness Probe
Liveness Probe用于表示容器服务是否活跃。Kubernetes会在容器生命周期中不断检测Liveness Probe状态,当Liveness Probe返回失败并且次数超过配置阈值时,Kubernetes将认为容器服务已经终止或者无法继续处理请求,进而杀死容器所在的Pod并重新创建。
Readiness Probe
Readiness Probe用于表示服务当前是否可以正常处理请求,例如当服务依赖的某个重要组件状态异常时,我们可以让Readiness接口返回Unhealthy,当Kubernetes发现Readiness探针失败时,它会停止向Pod发送请求,但不会重启Pod,直到服务变为可用为止。
Startup Probe
与前两者不同,在Startup探针探测成功之前,Kubernetes不会向Pod发送流量,也不会启动Liveness和Readiness探测。
例如,如果我们在部署服务时使用了错误的数据库连接字符串,在服务接入集群之后将会导致大量的数据库连接错误。如果我们在Startup阶段进行了数据库连接检查,那么k8s启动探针检查失败之后将认为该容器启动失败,因此可以帮助我们尽早发现问题。
另外,Startup探针还可以用来保护慢启动容器,避免故障误判,控制多服务启动顺序,避免过早初始化等。
在Kubernetes为init container提供了更好的支持之后,越来越多的服务开始将Startup检查放在独立的init container来进行,这样的好处是容器职责更加清晰,并且init container作为服务的前置容器,可以使用独立的技术栈,拥有独立的生命周期,且易于批量定制化和替换。
.NET健康检查
接下来,让我们结合.NET项目,在实践中了解Kubernetes探针检测和.NET服务健康检查机制。
服务状态
ASP.NET Core框架将服务定义为三种健康状态:Healthy(状态码:200)、Degraded(状态码:200)、Unhealthy(状态码:503)。
- Healthy:服务健康,可以正常处理外部请求。
- Degraded:应用程序处于降级状态,例如依赖的某些非关键服务失败,导致某些功能或性能受影响。Degraded可能是一个暂时的状态,服务可能会在一段时间内恢复到正常状态。
- Unhealthy:服务处于不健康状态,无法处理外部请求。
IHealthCheck
在.NET项目中,我们需要多种IHealthCheck接口的实现,以检查依赖的服务是否可用。一个广泛应用的健康检查开源库:Github: AspNetCore.Diagnostics.HealthChecks,它提供了许多服务和中间件的健康检查方案。
以针对PostgreSQL数据库的检查为例,该检查从服务配置中读取PostgreSQL相关配置,在CheckHealthAsync方法中尝试打开数据库连接并执行一条测试语句。成功执行则认为PostgreSQL服务是健康的;否则,认为数据库服务不健康,并返回相应的健康状态。
public class NpgSqlHealthCheck : IHealthCheck
{
private readonly NpgSqlHealthCheckOptions _options;
public NpgSqlHealthCheck(NpgSqlHealthCheckOptions options)
{
Debug.Assert(options.ConnectionString is not null || options.DataSource is not null);
Guard.ThrowIfNull(options.CommandText, true);
_options = options;
}
/// CheckHealthAsync(HealthCheckContext context, CancellationToken cancellationToken = default)
{
try
{
await using var connection = _options.DataSource is not null
? _options.DataSource.CreateConnection()
: new NpgsqlConnection(_options.ConnectionString);
_options.Configure?.Invoke(connection);
await connection.OpenAsync(cancellationToken).ConfigureAwait(false);
using var command = connection.CreateCommand();
command.CommandText = _options.CommandText;
var result = await command.ExecuteScalarAsync(cancellationToken).ConfigureAwait(false);
return _options.HealthCheckResultBuilder == null
? HealthCheckResult.Healthy()
: _options.HealthCheckResultBuilder(result);
}
catch (Exception ex)
{
return new HealthCheckResult(context.Registration.FailureStatus, description: ex.Message, exception: ex);
}
}
} 注册健康检测
在.NET项目中,我们可以通过注册实现了IHealthCheck接口的服务来进行健康检测。为了后续创建相应的探针端点,我们可以为每个HealthCheck指定name或者tag。
public const string StartupCheck = "/health/startup";
public const string ReadinessCheck = "/health/ready";
public const string LivenessCheck = "/health/live";
public static IHealthChecksBuilder AddAppsHealthChecks(this IHealthChecksBuilder healthChecksBuilder) =>
healthChecksBuilder
.AddCheck(StartupCheck)
.AddCheck(ReadinessCheck)
.AddCheck(LivenessCheck, () => HealthCheckResult.Healthy()); 创建探针接口
.NET提供了两种方式来创建健康检测接口:UseHealthChecks与MapHealthChecks。Kubernetes将利用这些接口来确定容器当前状态,它们的最大区别在于中间件管道中的顺序不同。
以下是一个示例,我们将创建一个请求路径为"/health/startup"的健康检测端点,该端点将根据HealthCheck的注册名字来筛选Startup Probe所需检查的服务。
public static IApplicationBuilder UseAppsHealthChecks(this IApplicationBuilder app) =>
app.AddLivenessProbe().AddReadinessProbe().AddLivenessProbe();
public static IApplicationBuilder AddStartupProbe(this IApplicationBuilder app) =>
app.UseHealthChecks(new PathString(StartupCheck), new HealthCheckOptions
{
Predicate = check => check.Name == StartupCheck,
});实践原则
服务依赖
在微服务架构中,服务之间的依赖关系会非常复杂。因此,在创建探针接口时,我们要充分考虑Kubernetes三种探针的运行机制以及服务之间的依赖关系,避免形成死锁,例如A依赖B可用,B又依赖C可用,而C又依赖A可用等。
探针配置
在Kubernetes中,配置容器的探针检测周期与超时时间时,需要综合考虑服务的负载和问题发现的时效性。通过结合日志和监控,可以调整服务探针机制到最佳状态。
探针实现
通常来说,Startup探针的目的是检测容器工作时机是否合适。因为其成功后通常不再运行,适合用于充分的状态检查。
对于Liveness探针,通常越简单越好。我们可以使用下面的代码添加一个基本的Liveness健康检查,即服务能够接受请求并返回,即认为其存活。
healthChecksBuilder.AddCheck(LivenessCheck, () => HealthCheckResult.Healthy());Readiness探针的设计需要根据服务的具体情况而定,必须弄清楚在当前微服务架构中,哪些服务对于当前服务是必须的,或者在什么状态下需要将当前服务标记为Unhealthy,即无法正常处理请求。
实践教程
在示例代码k8s-helm-micro-services - Repos (azure.com)中,我创建了三个服务并使用helm template创建了helm chart,其中,app1依赖app2,app2又依赖app3。
探针配置
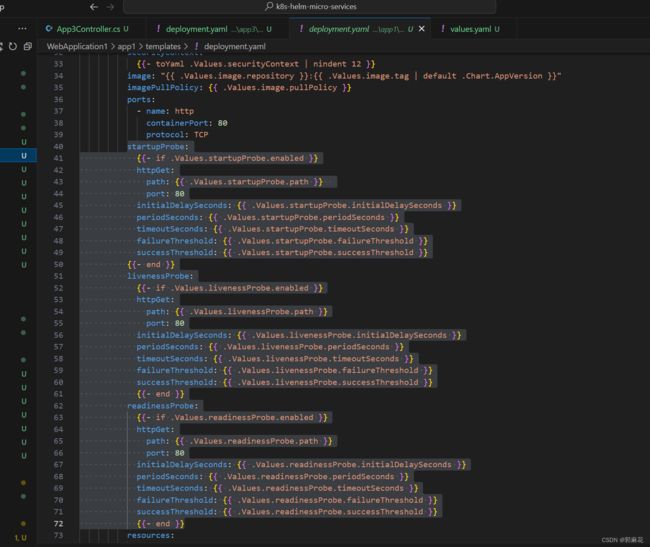
因为我使用helm template创建deployment等文件,因此我在values.yaml文件中配置了探针相关参数,并在deployment.yaml中引用,以app1为例:

安装微服务
我们先使用minikube和helm命令,部署app2和app3到cluster:
docker build -t app3:v1 .
minikube image load app3:v1
helm upgrade -i app3 .\app3\ -n test
docker build -t app2:v1 .
minikube image load app2:v1
helm upgrade -i app2 .\app2\ -n test测试Readiness探针
为了方便测试,我在app3中添加了一个REST接口用来修改服务的HealthStatus,并且作为Readiness检查的结果:
public static HealthStatus HealthStatus;
[HttpGet("set")]
public HealthStatus Set(HealthStatus healthStatus)
{
HealthStatus = healthStatus;
return HealthStatus;
}
public class ReadinessCheck : IHealthCheck
{
public Task CheckHealthAsync(HealthCheckContext context, CancellationToken cancellationToken = default)
=> Task.FromResult(new HealthCheckResult(App3Controller.HealthStatus));
} 由于HealthStatus默认值是Unhealthy,因此在部署之后我们可以看到Pod的状态是:Readiness probe failed: HTTP probe failed with statuscode: 503

此时,如果我们从app2中请求app3的接口,将会得到一个Connection refused错误,这是因为Readiness probe failed时,集群将停止向该Pod发送任何请求。
但此时app3容器是依然存活的,且其中的.NET服务依然在运行,因此我们可以通过kubectl port-forward等手段,访问到它的接口。 我们通过调用set接口,将服务健康状态设置为Healthy。
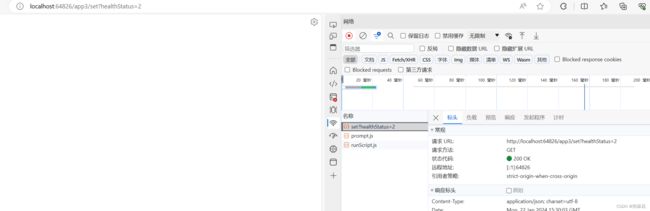
之后,app3服务探针检查恢复正常,app2可以成功的从app3中查询数据了
 测试Startup和Liveness探针
测试Startup和Liveness探针
我在app1当中添加了Startup探针,检测的内容是app3是否存活,因此在部署app1到cluster之前,我们先删除app3,以此来测试Startup探针的工作情况。
public class App3StartupCheck : IHealthCheck
{
private readonly ILogger _logger;
public App3StartupCheck(ILogger logger)
{
_logger = logger;
}
public async Task CheckHealthAsync(HealthCheckContext context, CancellationToken cancellationToken = default)
{
try
{
using var client = new HttpClient { BaseAddress = new Uri("http://app3.test") };
var result = await client.GetStringAsync("health/live");
return new HealthCheckResult(Enum.Parse(result));
}
catch (Exception ex)
{
_logger.LogError(ex, "App3 is not ready");
return HealthCheckResult.Unhealthy();
}
}
} 可以看到,在部署app1之后,因为app3服务已经被我们删除掉了,所以会出现:Startup probe failed: HTTP probe failed with statuscode: 503,Startup探针检查失败导致该Pod一直被k8s重启。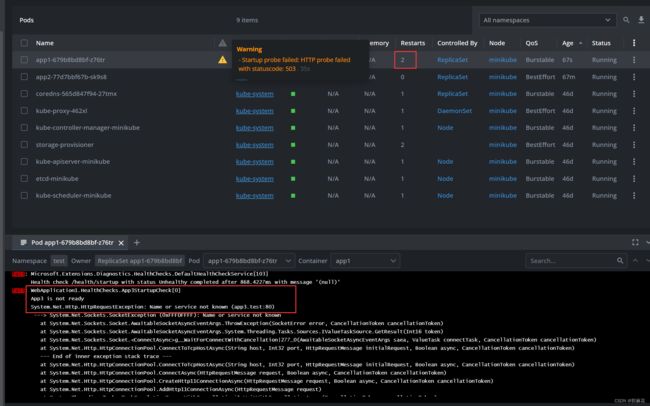
当我们将app3重新部署回来之后,因为app3的Readiness默认健康状态是Unhealthy,所以尽管它处于存活状态,但此时仍无法处理任何请求。app1仍然无法通过接口获取到app3的Liveness状态,所以app1依然处于Startup probe failed。

接下来,我们通过上面提到的port-forward的方式,直接访问app3的容器接口,将HealthStatus的值修改为Healthy:

我们可以看到app3的探针状态已经恢复正常,而app1也会在下一次Pod重建时成功通过Startup探针检查。
 总结
总结
本文以非常简单的示例,为大家介绍了如何将.NET服务的健康检查机制与Kubernetes探针结合使用,希望能够对大家有所启发。