Python 算法交易实验67 第一次迭代总结
说明
在这里对第一次迭代(2023.7~ 2024.1)进行一些回顾和总结:
回顾:
- 1 实现了0~1的变化
- 2 在信息隔绝的条件下,无控制的操作,导致被套
总结:
思路可行,在春暖花开的时候,迭代完一版,应该可以取得不错的结果。
内容
1 失败分析
第一次迭代最后的失败的主因还是因为急功近利的心理,然后不受约束的开始买入,导致被套。我认为市场大跌并不会有这种后果:因为模型分已经知道市场不是一个很好的状态。
主要是主观的想象力,认为要出现V字反转,抱有侥幸心理的操作,从而导致被套的局面。
客观上一个很大的原因是因为在项目中不允许使用电脑和手机,本质上已经脱离了数据决策的基本环境(目前V1的系统,没有自动化的决策支持)。正是孙子兵法说的:乱军引胜。
故君之所以患于军者三:不知军之不可可以进而谓之进,不知军之不可以退而谓之退,是谓縻军;不知三军之事,而同军之政者,则军士惑矣;不知三军之权,而同三军之任,则军士疑矣。三军既惑且疑,则诸侯之难至矣,是谓乱军引胜。
主观上有两个错误,第一个错误是最根本的错误,无限放大了主观决策的权力;第二个错误没有将交易当成一个严肃的business,没有全局的资金计划和风控。
2 改进计划
要避免再次犯错误,必须立规矩,并约定好流程,形成习惯。
虽然我不太喜欢走流程,但是不得不承认,对于关键的决策,遵循流程(尽量短)是必要的。
假设我自己就是一家公司,有一定的原始资金,作为公司的CEO会怎么决定,站在股东的角度又会怎样挑刺,从而形成一套具有约束性的规范。
在寻求利益的稳定和最大化之前具有矛盾,在控制运行风险与利益最大化之间也有矛盾,可以先设置一些合理的规范,然后程序化,设置一个顶层的控制对象,来确保公司的整体运营平稳。
业务的核心逻辑很简单,具有资金,根据实时数据进行判断,作出投资决策。业务的本质类似于信贷:市场行情作为一个虚拟人,在每个时刻向公司申请(无抵押)贷款,公司根据其信用评分作出放贷决定。一笔成功的放贷会在指定的一段时间内获取一定的收益,可能是半个点到十几个点,试不同的类型决定;一旦失败,本金将会损失流动性,或者输掉几个点到几十个点。总体上,一个单子的损失是远大于收益的。
所以,获益的核心是尽量提升成功率,同时也尽量的提前识别并避免损失(减少错误,止损)。
就市场本身而言,其状态是复杂的。最简单的维度是大盘整体的指数点位,所以在不同的点位应当留有准备金。投资最大的风险是在一个区间段发生剧变,所以可以按时段,例如每个自然月限制允许投资的最大值。
如果机械的按照大盘点位和时间划分成网格的话,风险虽然绝对控制了,但是由于资金的使用率过低,就会造成盈利效率过低的问题。
Topic1: 根据历史数据进行分析,明确是否可以简单的按月进行风险控制,例如,假设总资金60万,每个月投资上限是10万。
Assumption 1:市场行情的变化不会太持久,按较大的时隙(月)错开之后,资金不会被套。
平摊的周期越长,抗风险的能力越长,但是资金的盈利效率相应的也就降低了。等于只使用10万运营,每月如果盈利2%,年盈利则是24% ,按60万本金摊,那么才4%的年化。如果分为3股,那么就是8%,利益翻倍,风险也随之翻倍。
【月目标】低风险(6个月)的参考基准(无风险利率)是2%,中风险(3个月)的参考基准是1%
Topic2: 宏观判断,次月是否下跌。
每个月有投资授信上限,但是没有投资下限。这意味着,如果识别投资月处于下跌可能,可以减少投资额,甚至不投资。
从数学上考虑,这样是合理的。当下跌可能变大时,通常也会有上涨的可能,这些幅度通常都会比较大的。当这种剧变的概率高,那么降低投资额,从风险上显然是会有规避作用;即便从收益上看,也可以取得较为平均的结果。即:损失超额(下跌/上涨)而取其平均。
这样做是符合理想Business的设定的:一个稳定收益,随时间不断增长的的业务。这个稳定业务,年化收益是以无风险收益作为下限参考,20%作为及格线参考,50%作为风险控制的上限参考的。
也就是说,当收益超过50%时,会采取策略提高安全性,而不是继续追高收益。
【抓手】还得是报表。
同样地,我也不喜欢报表,但看起来在初期阶段,还是需要开发报表来完成管理职能。报表将用于宏观的决策:是否对策略、投资标的进行增删改?是否扩大或者缩小经营规模等。
临时分析:
- 1 获取数据,按月计算统计

- 2 计算月均值的差
比较让人意外的是,月均值上涨的月份数竟然更多
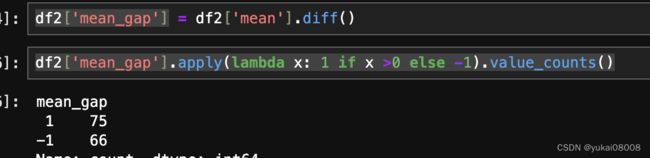
最好是根据变号的方式来统计连续值的个数,所以从统计上看,最近连跌6个月是比较罕见的。所以,大概率月底会翻红,或者2月份。

按月来看,指数显示出了更好的统计特性:围绕均值为0上下波动。
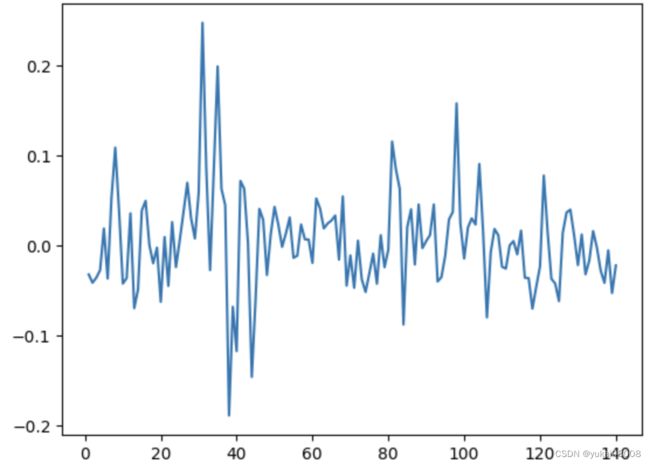
从变异系数来看, 月波动一般都是1个点以上。

最近6个月的最大回撤约为14%,历史上的最大回撤约为38%,所以现在的行情也算是毛毛雨了。
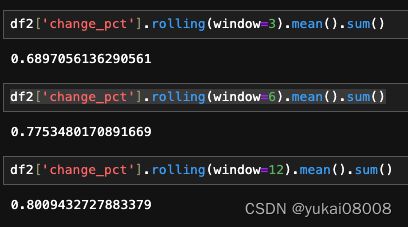
回答最初的猜想:将资金分散到3个月投资是否可行。

总体的rolling,6个月风险会小很多:
最近24个月的rolling(所以恶劣情况下还是不太行的)
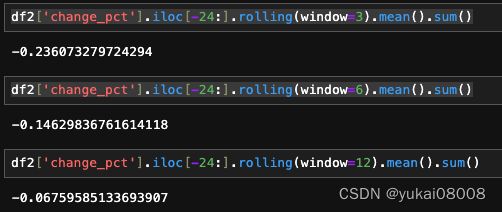
所以看起来,如果是简单投资,那么6个月的rolling是一个较好的选择。随之而来的问题是,有没有规律可以改善不同情况下的资金利用状态:是不均分的分布方式。
例如,在回撤已经特别大的时候,加大投资的授信额度,反之如果已经正向盈利较多,就减少最大授信额度(当月)。通过这种动态的授信方法,可以从宏观上控制风险。
当然,在具体的授信环节,模型本身也会具有风险识别的功能,这是一种自发的,业务性质的风控:当判断较为悲观时,交易会自发减少,这就会进一步避免错误的交易。
【结论】 初期还是以6个月为限比较合适,根据月最大回撤或最大升幅来动态调整月授信额度,最大可达50%。
所以,理论上2024.2可以是1.5倍月授信。
另外,可以约定每个标的每月的敞口不得大于当月授信总额的1/3。
每个月的收益及格线是5个点,良好得10个点。所以这个就有点难了,不过由于宏观控制了风险,所以单月的策略可以更激进。
单月额度 * 单月利润率 * 月份数 ÷ 2 ÷ 总额度
【估算】如果单月是5个点,那么一年大约是5个点,如果单月是10个点,那么一年大约就是10个点。
3 细节分析
3.1 回测对象的Bug
回测对象在运行时,其时隙的计算是错误的,虽然临时魔改修正了,但似乎还是有问题。这导致了持有周期的评估偏差。
这直接导致了最后信息传导时失效,前面所有的工作在这一步失败了,所以第一次迭代,最大的意义是打通关键环节,但并不足以作为生产。
3.2 信息缺失
之前主要考虑了短信通知的模板/字数限制,在大量的信息涌入时,已经完全分不清楚这个信息代表的交易,到底效果如何了。只能知道模型提出的买卖时点是否合理。
这起到了部分模型验证的作用,但也没有达到生产级。
3.3 建模方法
最初的模型只考虑盈利,这是不对的,至少不完全对。盈利模型更可能是双刃剑,但是也存在帕累托的可能。前者对于稳定运营的意义不大,所以一迭真是做了个寂寞。
追寻帕累托,至少是避险模型才是对的。
4 第二次迭代的推进目标
4.1 新BT(BackTesting)
这将是控制力更强,更可靠的工具。
设计上的改变:
- 1 记录级对象(Rec Class )。这会确保控制的灵活性,特别是在debug上,非常精细。另外,未来这些将与数据库结合,仍然可以并行处理(群啸)。
- 2 FlipFlop。对象的执行将分为计算元数据与数据两个固定步骤,元数据将决定状态,状态将影响数据的执行。
- 3 Block吞吐。所有的数据执行将以Block作为单位进行吞吐,这个或许是影响最大的程序改变。
首先,原来的UCS设计是面向空间,或者说是日志型的。一个空间下,或者没有数据时间,或者有度量单位不一的多个标的的数据时间。现在将按照时间轴进行主数据合并,称为TBDB(Time-Based DataBase)。这意味着按照时间轴优先,然后去合并不同空间下的数据。每个空间在时间轴上的数据都是唯一的。TBDB是时序数据库的概念,其空间维度的拓展可以由其他的UCS而来。UCS由shard, part和block三个层级,以及项目名称构成唯一识别标志。例如, project_000.part_000.block_000 ~ task_id ,这个规范足以支撑千亿级别的数据。
Note: TBDB在存储格式上实际上也是UCS的,只不过task_id是时隙,block就是时间块了。
其次,每个worker将不直接从数据库请求数据,而是向Block Manager发出取数请求,BM会根据请求进行取数,这将带来很多好处。
- a 减少不必要的数据库压力或磁盘吞吐。如果有n个worker在请求同样数据时,不会重复从数据库/磁盘取,而是从内存中取。多个worker是几乎一定会发生的事。
- b 预取数。当worker处于历史回测状态时,BM可以预先将需要的后续block取好放在内存中,这样worker就不需要停等。
- c 增强了数据规范,便于更大规模协同。由于数据的需求变成了离散化的块需求,即使通过文件系统也很容易进行协同。这将为使用拓展算力提供良好的基础。
4.2 前端
情况更清晰,辅助操作的能力更强
通过表格和其他前端技术实现:
- 1 实现每月的资金使用、利润及订单报表。这样可以贯彻宏观的资金控制,并对交易进行细致的控制,用于迭代。
- 2 订单的交易明细表设计。务求信息简洁且完整,足以让我第一时间信赖它,作出交易决定。
- 3 消息列表设计。SMS将不提供明细,而是提供一个id号,在 前端提供完整的交易信息。
回测对象会生成Order对象
Order对象会在前端显示,从订单开始,手机用户的反馈。如果用户没有在合适的机会响应订单,订单将会关闭。
订单对象负责收集用户的反馈和交互,所以会在前端进行合理的展示。具有总分的特质,在外层显示基本信息,点进去可以显示详细信息。
特征将处理到若干表,所以在提取这些特征进行建模和分析时,需要async请求,要观察这些async是否会错乱。
要按时间建立主表,基于这些主表建立报表
4.3 建模方法
采用风险模型 + 固定利率的交易
在能够有效控制双刃剑/帕累托模型之前,将使用风险模型,以传统信贷模型的方式给出交易信号。并按照固定利率的交易方式触发交易。
以每单毛利 1%, 2% 建立日频的交易策略进行实验(A卡),之后在交易过程中进行追踪(B卡 ),最后对失败的订单进行清算(C卡)。
初期可以简化为A卡买入,在指定周期达标抛售,或者到期强制卖出。