MapReduce案例(五)
案例一:求订单的最大金额
1、数据源
Order_000001 Pdt_01 223.8
Order_000001 Pdt_05 25.8
Order_000002 Pdt_03 522.8
Order_000002 Pdt_04 122.4
Order_000002 Pdt_06 722.8
Order_000003 Pdt_02 122.8
Order_000003 Pdt_07 222.8
其中第一列是订单编号,第二列是商品编号,第三列是商品金额
2、需求
求每个订单内部最大的商品金额;结果按照订单编号分成2个区,并写出到不同的文件
3、需求分析
- 按照订单进行分组:需要自定义GroupingComparator类
- 对组内商品按照金额从大到小排列:需要重写compareTo方法,然后取第一个值
- 按照订单编号分成2个区:需要自定义Partitioner
- 同上:主程序需要设置reduce task任务数量为2
4、代码实现
(1)主程序
package com.wakedata.mapreducer.case_1;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class JobMain extends Configured implements Tool {
@Override
public int run(String[] strings) throws Exception {
//获取job
Job job = Job.getInstance(super.getConf(), "Group_mapreduce");
job.setJarByClass(JobMain.class);
//设置输入类和数据路径
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("file:///D:\\input\\Group_Order_Top1"));
//设置自定义map类
job.setMapperClass(GroupMapper.class);
job.setMapOutputKeyClass(OrderBean.class);
job.setMapOutputValueClass(Text.class);
//设置自定义分区
job.setPartitionerClass(OrderPartition.class);
//设置分组
job.setGroupingComparatorClass(OrderGroupComparator.class);
//设置自定义reduce类
job.setNumReduceTasks(3);
job.setReducerClass(GroupReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//设置输出类和路径
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("file:///D:\\output\\Group_Order_Top2"));
//设置任务等待
boolean b1 = job.waitForCompletion(true);
return b1?0:1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
int run = ToolRunner.run(configuration, new JobMain(), args);
System.exit(run);
}
}
(2)Map Task
>> ①将从文件中读到的每一行数据,封装成一个Java Bean对象,该对象包含两个属性:订单id和订单金额。
package com.wakedata.mapreducer.case_1;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class GroupMapper extends Mapper {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1.拆分文本数据,得到订单id和订单金额
String[] split = value.toString().split("\t");
//2.封装orderbean,得到k2
OrderBean orderBean = new OrderBean();
orderBean.setOrderId(split[0]);
orderBean.setPrice(Double.valueOf(split[2]));
//将k2和v2写入上下文
context.write(orderBean,value);
}
}
结合MapReduce数据处理流程(四),可知Map Task最终的结果,其实会按照分区(默认分区器是HashPartioner)写出文件,如下图所示:
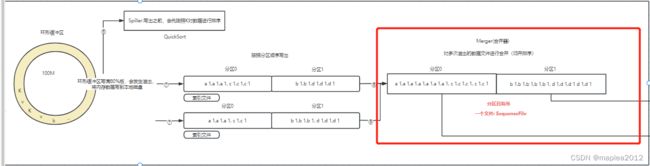
在本例中context.write(orderBean,value),那么就会根据orderBean的Hash值进行分区,而根据本例需求,应该按照OrderBean中的订单进行分区,所以需要自定义Partitoner
>> ②在Reduce Task中拉取 Map task写出的数据时,要获取最大的金额,因此context.write(orderBean,value)写出orderBean时,orderBean中相同id内部的金额需要从大到小排序,这样Reduce Task读取到数据时,只要取第一条数即可满足需求。为了实现该需求 ,需要为orderBean重写compareTo方法。
(3)自定义OrderPartition
package com.wakedata.mapreducer.case_1;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class OrderPartition extends Partitioner {
//分区规则,根据订单ID实现分区
/***
*
* @param orderBean k2
* @param text v2(一行的文本数据)
* @param i ReduceTask个数
* @return 分区编号
*/
@Override
public int getPartition(OrderBean orderBean, Text text, int i) {
//根据订单id进行分区
return (orderBean.getOrderId().hashCode() & 2147483647) % i;
}
}
(4)重写orderBean compareTo方法
package com.wakedata.mapreducer.case_1;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class OrderBean implements WritableComparable {
private String OrderId;
private Double price;
public String getOrderId() {
return OrderId;
}
public void setOrderId(String orderId) {
OrderId = orderId;
}
public Double getPrice() {
return price;
}
public void setPrice(Double price) {
this.price = price;
}
@Override
public String toString() {
return OrderId + "\t" + price;
}
@Override
public int compareTo(OrderBean orderBean) {
int i = 0;
//如果订单id相同,根据价格进行从大到小排序
i = this.getOrderId().compareTo(orderBean.getOrderId());
if(i==0) {
i = this.price.compareTo(orderBean.price)*-1;
}
return i;
}
@Override
public void write(DataOutput output) throws IOException {
output.writeUTF(OrderId);
output.writeDouble(price);
}
@Override
public void readFields(DataInput in) throws IOException {
this.OrderId = in.readUTF();
this.price = in.readDouble();
}
}
Tips:write和readFields是因为Map Task写到环形缓冲区的时候,要进行序列化,Reduce Task拉取数据后,要进行反序列化。
(5)Reduce Task
package com.wakedata.mapreducer.case_1;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class GroupReduce extends Reducer {
@Override
protected void reduce(OrderBean key, Iterable values, Context context) throws IOException, InterruptedException {
for (Text value:values) {
int i =0;
context.write(value,NullWritable.get());
i++;
if (i >=1){
// 取完第一条数据就直接退出
break;
}
}
}
}
结合MapReduce数据处理流程(四),Reduce task默认是按照Key的二进制字节来判断相邻两条数据是否属于同一个组,而根据本例需求,应该按照订单id进行分组,因此要自定义GroupComparator
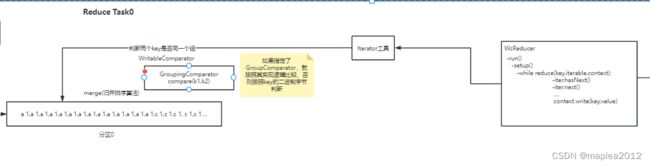
本例实际数据(分区0):

(6)自定义GroupComparator
package com.wakedata.mapreducer.case_1;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
/***
* 1:继承WritableComparable
* 2:调用父类的有参构造
* 3:指定分组的规则(重写方法)
*/
public class OrderGroupComparator extends WritableComparator {
//* 2:调用父类的有参构造
//true是允许创建OrderBean实例
public OrderGroupComparator() {
super(OrderBean.class,true);
}
//3.指定分组的规则(重写方法)
@Override
public int compare(WritableComparable a, WritableComparable b) {
//3.1 对形参做强制类型转换
OrderBean first = (OrderBean)a;
OrderBean second = (OrderBean)b;
//3.2 指定分组规则(根据id进行分组)
//OrderId相等则分为同一组
return first.getOrderId().compareTo(second.getOrderId());
}
}
(7)运算结果



案例二:获取商品详细信息(小表join大表):Map端join
一、数据源
(1)products(字典表):产品详细信息
P10001 小米5 1000 2000
P10002 锤子T1 1000 3000
其中P10001 是产品编号
(2)orders:订单表
1001 20150710 P10001 2
1002 20150710 P10002 3
1003 20150710 P10001 2
1004 20150710 P10002 3
1005 20150710 P10002 2
1006 20150710 P10002 3
其中P10001是产品编号
二、需求
订单表中拼接产品详细信息, Example:
P10001 1001 20150710 P10001 2 小米5 1000 2000
三、需求分析
products是字典表,通常数据量很小,而order订单数据量可能很大,所以如果能够在每个Map Task内部实现两张表的Join,并直接输出结果,省略Reduce Task, 能够极大提升效率。而要实现Map端join,需要将小表数据放入缓存,这样每个Map Task都能够读到该缓存数据,从而达到最终目的。
四、代码实现
(1)上传products文件到HDFS
[root@master ~]# hadoop fs -put products.txt /cache_file(2)主程序
package com.wakedata.mapreducer.map_join;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.net.URI;
public class JobMain extends Configured implements Tool {
@Override
public int run(String[] strings) throws Exception {
//获取Job对象
Job job = Job.getInstance(super.getConf(), "Map_join");
job.setJarByClass(JobMain.class);
//设置job对象(将小表放在分布式缓存中)
job.addCacheFile(new URI("hdfs://master:8020/cache_file/products.txt"));
//第一步:设置输入类和输入路径
job.setInputFormatClass(TextInputFormat.class);
//大表的输入路径(order表)
TextInputFormat.addInputPath(job,new Path("file:///D:\\input\\orders"));
//第二步:设置Mapper类和数据类型
job.setMapperClass(MapJoinMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//指定不走Reduce Task
job.setNumReduceTasks(0);
//第八步:设置输出类和输出路径
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("file:///D:\\output\\map_join_output2"));
//等待任务结束
boolean b1 = job.waitForCompletion(true);
return b1 ? 0:1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
int run = ToolRunner.run(configuration, new JobMain(), args);
System.exit(run);
}
}
(3)MapJoinMapper
package com.wakedata.mapreducer.map_join;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.HashMap;
public class MapJoinMapper extends Mapper {
private HashMap map = new HashMap<>();
//第一件事情:将分布式缓存的小表数据读取到本地Map集合(只需要做一次)
@Override
protected void setup(Context context) throws IOException, InterruptedException {
//1.获取分布式缓存文件列表
URI[] cacheFiles = context.getCacheFiles();
//2.获取指定的缓存文件的文件系统(Filesystem)
//cacheFiles[0]是文件的URI
FileSystem fileSystem = FileSystem.get(cacheFiles[0], context.getConfiguration());
//3.获取文件的输入流
FSDataInputStream inputStream = fileSystem.open(new Path(cacheFiles[0]));
//4.读取文件内容,并将数据存入Map集合
//4.1将字节输入流转为字符缓冲流FSDataInputStream——>bufferedReader
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(inputStream));
//4.2 读取小表文件内容,以行为单位,并将读取的数据存入map集合
String line = null;
while ((line = bufferedReader.readLine()) != null){
String[] split = line.split("\t");
map.put(split[0],line);
}
//5.关闭流
bufferedReader.close();
fileSystem.close();
}
//第二件事情:对大表处理业务逻辑,而且要实现大表与小表的join操作
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1.行文本数据中获取商品的id:P10001,P10002
String[] split = value.toString().split("\t");
String productId = split[2];
//2.在Map集合中,将商品的id作为键,获取值,将value和值拼接,得到v2
String productLine = map.get(productId);
String productLine_new = productLine.split("\t")[1] + "\t" + productLine.split("\t")[2] + "\t" + productLine.split("\t")[3];
String valueLine = value.toString() + "\t" + productLine_new;
//3.将k2和v2写入上下文中
context.write(new Text(productId),new Text(valueLine));
}
}
(4)运算结果
P10001 1001 20150710 P10001 2 小米5 1000 2000
P10002 1002 20150710 P10002 3 锤子T1 1000 3000
P10001 1003 20150710 P10001 2 小米5 1000 2000
P10002 1004 20150710 P10002 3 锤子T1 1000 3000
P10002 1005 20150710 P10002 2 锤子T1 1000 3000
P10002 1006 20150710 P10002 3 锤子T1 1000 300