流畅的Python(二)-序列构成的数组
一、本章主要内容
主要介绍Python内置的各种序列类型,包括列表、元组、队列和数组等,以及该类型通用的一些操作,包括切片、拼接和排序等。
二、代码示例
1、列表推导式
作用: 主要用于生成新的列表
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2023/12/30 20:05
# @Author : Maple
# @File : 01-列表推导式.py
# @Software: PyCharm
"""列表推导式
主要用于生成新的列表
"""
if __name__ == '__main__':
# 1.列表推导式
symbols = 'maple'
# ord函数:返回字符对应的ASCII数值
# 利用列表推导式生成一个新的列表
codes = [ord(s) for s in symbols]
print(codes) #[109, 97, 112, 108, 101]
# 2.列表推导式中 添加判断逻辑
codes_2 = [ord(s) for s in symbols if ord(s)> 100]
print(codes_2) # [109, 97, 112, 108, 101]
# 列表推导式: 二维
height = [172,180,165]
gender = ['female','male']
people = [(h,g) for h in height
for g in gender]
print(people) # [(172, 'female'), (172, 'male'), (180, 'female'), (180, 'male'), (165, 'female'), (165, 'male')]2、生成器表达式
-
与列表推导式语法类似:唯一区别是[] 替换成()
-
与列表推导式相比,生成的是一个迭代器,因此结果不会大量占用内存,而是在迭代的过程中,才真正逐步 生成每一个元素
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2023/12/30 20:17
# @Author : Maple
# @File : 02-生成器表达式.py
# @Software: PyCharm
"""生成器表达式
1. 与列表推导式语法类似:唯一区别是[] 替换成()
2. 与列表推导式相比,生成的是一个迭代器,因此结果不会大量占用内存,而是在迭代的过程中,才真正逐步 生成每一个元素
"""
if __name__ == '__main__':
# 1. 利用生成器表达式初始化元组和数组
symbols = 'maple'
# ord函数:返回字符对应的ASCII数值
# 利用生成器表达式生成一个新的元组
codes = (ord(s) for s in symbols)
# 生成器表达式的结果是一个生成器(ps: 一种特殊的迭代器)
print(codes) # at 0x0000016251581350>
# 迭代输出每一个元素
for code in codes:
print(code)
# 2. 生成器表达式: 二维
height = [172, 180, 165]
gender = ['female', 'male']
people = ('%s %s' % (h, g) for h in height
for g in gender)
# 迭代输出每一个元素信息
"""172 female
172 male
180 female
180 male
165 female
165 male
"""
for person in people:
print(person) 3、元组
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2023/12/30 20:28
# @Author : Maple
# @File : 03-元组.py
# @Software: PyCharm
import collections
if __name__ == '__main__':
# 1. 元组拆包
## 1-1 利用name,gender和age分别接收元组中的元素
name,gender,age = ('Maple','male',88)
print('name:', name,'gender:',gender,'age:',age)
print('------------------------')
## 1-3 for循环提取元组中的元素
people = [(172, 'female'),
(180, 'female'),
(165, 'female')
]
# 只需要提取身高,性别对我们没用,因此可以使用"_"占位符
for height,_ in people:
print('height:',height)
print('------------------------')
# 1-3 打印元组信息
for p in people:
print('height:%s,gender:%s' %p)
print('------------------------')
## 1-4 "*" 使用
# 作为函数参数
t = (10,8)
r = divmod(*t)
print(r) # (1, 2)
# -->等价于
print(divmod(10,8)) # (1, 2)
# 获取不定参数
a,b,*rest = range(5)
print(rest) # [2, 3, 4]
a,b,*rest = range(3) #[2]
print(rest)
a, b, *rest = range(2) #[]
print(rest)
a,*body, c,d = range(5) # [1, 2]
print(body)
# 2. 具名元组:nametuple
# 定义一个名字叫Person,且具有name,age,gender三个属性的具名元组类
Person = collections.namedtuple('Person', ['name', 'age', 'gender'])
# 类的内置方法1:_fields,用于获取具名元组类的所有字段名
print(Person._fields) # ('name', 'age', 'gender')
# 类的内置方法2:_make,用于生成具名类的实例
person =('Jacky', 22, 'Male')
p1 = Person._make(person)
print(p1) # Person(name='Jacky', age=22, gender='Male')
# 类的内置方法3:_asdict, 将具名元组实例以collection.OrderedDict的形式返回
print(p1._asdict()) # {'name': 'Jacky', 'age': 22, 'gender': 'Male'}
# 更直接生成实例的方式
p2 = Person('Maple', 23, 'Male') # Person(name='Maple', age=23, gender='Male')
print(p2) # Person(name='Maple', age=23, gender='Male')
# 根据字段名提取元素
print(p2.name) # Maple4、数组
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2023/12/31 11:15
# @Author : Maple
# @File : 07-数组.py
# @Software: PyCharm
"""
如果我们仅仅需要一个包含数字的列表,那么array.array比list的效率更高
"""
from array import array
from random import random
if __name__ == '__main__':
#1. 创建一个有1000万个随机浮点数的数组
floats =array('d',(random() for i in range(10**7)))
print(floats[-1]) # 0.4501303662679138
#2.写入文件
with open('data/floats.bin','wb') as fp:
floats.tofile(fp)
#3.读取文件
with open('data/floats.bin','rb') as fp:
# 创建一个空的双精度浮点数数组
floats2 = array('d')
floats2.fromfile(fp,10**7)
# 判断floats和floats2是否相同
print(floats == floats2) # True
5、双向队列
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2023/12/31 11:28
# @Author : Maple
# @File : 08-双向队列.py
# @Software: PyCharm
"""主要应用于删除和添加首位元素
因为在列表中,删除第一个元素,或者在第一个元素之前添加一个元素之类的操作比较耗时
劣势: 从队列中间删除元素 会比较慢
"""
from collections import deque
if __name__ == '__main__':
dq = deque(range(10),maxlen=10)
print(dq) #deque([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=10)
# 将最右边的3个元素( 7, 8, 9)移到左边
dq.rotate(3)
print(dq) #deque([7, 8, 9, 0, 1, 2, 3, 4, 5, 6], maxlen=10)
# 将最左边的4个元素(7, 8, 9, 0)移到右边
dq.rotate(-4)
print(dq) # deque([1, 2, 3, 4, 5, 6, 7, 8, 9, 0], maxlen=10)
# 最左边添加元素-1
dq.appendleft(-1)
print(dq) # deque([-1, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=10)
# 尾部添加3个元素
dq.extend((10,20,30))
print(dq)
# 将序列中的元素依次添加到最左边
dq.extendleft((-100,-200,-300))
print(dq) # deque([-300, -200, -100, 3, 4, 5, 6, 7, 8, 9], maxlen=10)6、切片操作
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2023/12/30 21:10
# @Author : Maple
# @File : 04-切片.py
# @Software: PyCharm
"""
列表、元组、生成器等可使用切片
"""
if __name__ == '__main__':
"""
以列表为例:
1.切片的使用方式:形如mylist[a:]、mylist[a:b:c]等
2.本质上就是通过[]的方式,给列表传递了一个 切片对象,比如[a:b:c]返回的切片对象为slice(a,b,c)
,然后列表通过调用mylist.__getitem__(slice(a,b,c))方法,返回最终的结果
3.所以切片除了可以通过形如[a:b:c]这样的硬编码数字区间方式调用,还可以通过定义 有名字的切片对象(斗胆将之定义为具名切片),更方便地使用
"""
mylist = [10,20,30,40,50]
# 1. 基本应用
# 截取前3个元素
print(mylist[:3]) #[10, 20, 30]
# 截取第三个元素之后的元素
print(mylist[3:])
# a:b:c,截取a和b之间以c为间隔的值
# 从头到尾,每隔1个元素取一个值
print(mylist[::2]) #[10, 30, 50]
# 从头到尾,以-1为间隔取值:也就是从尾部开始,逆序取值
print(mylist[::-1]) # [50, 40, 30, 20, 10]
# 从头到尾以-2为间隔取值:也就是从尾部开始,每隔一位,取一个值
print(mylist[::-2]) # [50, 30, 10]
print('----------------------')
# 2. 具名(有名字的)切片
weather_data = """
2023-12-30 广州 晴转多云 13-30℃
2023-12-30 珠海 阴 15-33℃
2023-12-30 深圳 小雨 10-34℃ """
# 定于具名切片
date = slice(0,11)
city = slice(11,16)
weather = slice(16,22)
tmp = slice(22,None)
lines = weather_data.split('\n')[2:]
print(lines)
for line in lines:
# 通过具名切片截取城市和温度值
print(line[city],line[tmp])
print('----------------------')
#3. 切片赋值
l = list(range(10))
print(l) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# 第3-5个元素替换为[20,30]
l[2:5] = [20,30]
print(l) # [0, 1, 20, 30, 5, 6, 7, 8, 9]
# 删除第6和第7个元素
del l[5:7]
print(l) # [0, 1, 20, 30, 5, 8, 9]
# 从第4个元素开始,每间隔一位,截取一个,并替换成[11,22]
l[3::2] = [11,22]
print(l) # [0, 1, 20, 11, 5, 22, 9]
# 第3-5位元素替换成100(注意等式右边不要写成100,而是[100])
l[2:5] = [100]
print(l) # [0, 1, 100, 22, 9]7、拼接和增量操作
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2023/12/31 10:14
# @Author : Maple
# @File : 05-拼接和增量操作.py
# @Software: PyCharm
"""
1.拼接: + 和 *,底层对应的方法是__add__和__mul__
2.增量: += 和*=,对于可变数据类型(比如list),底层调用的是__iadd__和__imul__,
对于不可变数据类型(比如str),底层调用的是__add__和__mul__(也就是和+ 和 * 运算符其实一样了)
3.如果调用的是__iadd__和__imul__,那么运算结果会直接改变被操作对象本身
如果调用的是__add__和__mul__,那么运算结果会生成一个新的对象,被操作对象本身不会发生变化
"""
if __name__ == '__main__':
# 拼接(以*为示例):底层调用__mul__,会生成一个新的对象,原对象不会发生变化
l = [1,2,3,4,5]
l2= l * 5
print(l2) #[1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 1, 2, 3, 4, 5]
print(l) #[1, 2, 3, 4, 5],原对象并没有发生变化
l2[1] = 10
print(l2)
print('--------------------')
# 初始化镶嵌列表
board = [['_'] * 3 for i in range(3)]
print(board) # [['_', '_', '_'], ['_', '_', '_'], ['_', '_', '_']]
board[1][2] = 'x'
print(board) # [['_', '_', '_'], ['_', '_', 'x'], ['_', '_', '_']]
# 注意以下初始化列表的方式与上面的区别
board2 = [['_'] * 3] * 3
board2[1][2] = 3
print(board2) # [['_', '_', 3], ['_', '_', 3], ['_', '_', 3]]
print('--------------------')
# 2. 增量
l3 = [1,2,3]
print(id(l3)) #2322766315328
l3 *= 2
# l3为可变对象,因此*=底层会调用__imul__,l3本身会发生变化
print(l3) # [1, 2, 3, 1, 2, 3]
print(id(l3)) #2322766315328,仍然是同一个对象
# 元素为不可变对象,*=底层调用的是__mul__,因此会生成一个新的对象
t = (1,2,3)
print(id(t)) # 1908996061824
t*=3
print(t)
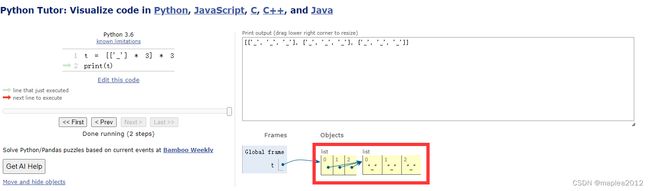
print(id(t)) # 1908995618400,是一个新的对象>>补充说明: [['_'] * 3 for i in range(3)] 和 [['_'] * 3] * 3创建列表方式的内存图示
- [['_'] * 3 for i in range(3)]方式:每一个元素都指向一个独立的内存地址

-
[['_'] * 3] * 3方式:列表中的三个子列表其实是同一个对象
8、排序
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2023/12/31 10:46
# @Author : Maple
# @File : 06-排序.py
# @Software: PyCharm
"""
1.对象.sorted不改变原对象本身,返回的是None
2.内置函数sorted(对象),会生成一个新的对象,返回的是新的对象
"""
import bisect
if __name__ == '__main__':
#1. 对象.sorted使用
fruites = ['banana','apple','pear','grape']
print(fruites.sort())
print(fruites) #['apple', 'banana', 'grape', 'pear'],对象本身已经发生了变化
# 逆序
fruites.sort(reverse=True)
print(fruites) #['pear', 'grape', 'banana', 'apple']
# 根据长度由小到大排序
fruites.sort(key=len)
print(fruites) #['pear', 'grape', 'apple', 'banana']
print('------------------------')
#2.sorted(对象)使用
fruites_new = sorted(fruites)
print(fruites_new) # ['apple', 'banana', 'grape', 'pear']
print(fruites) # ['pear', 'grape', 'apple', 'banana'],原对象本身并没有发生变化
#3.bisect使用
# 用途: 在一个已经排好序的对象中,插入新的元素,且能保证原有对象整体上仍然是有序的
org_list = [1,3,10,11,20]
new_elements = [0,2,3,14,21]
##3-1 bisect_left 和 bisect_right: 获取新的元素应该插入到原有对象的哪个位置
bisect_fn = bisect.bisect_left
for e in new_elements:
position = bisect_fn(org_list,e)
"""
新的元素 0 应该插入到原列表的位置: 0
新的元素 2 应该插入到原列表的位置: 1
新的元素 3 应该插入到原列表的位置: 1
新的元素 14 应该插入到原列表的位置: 4
新的元素 21 应该插入到原列表的位置: 5
"""
print('新的元素', e , '应该插入到原列表的位置:',position)
print('--------------')
# bisect_right 和 bisect_left有啥区别?
# new_elements 中的3在原list中已经存在,那么如果使用bisect_right,new_elements中的3会插入到原list的3中的右边,
# 而如果使用bisect_left,则会插入到其左边
# 如果新旧元素都是整数,这两种处理方法的结果其实是一致的,但如果一个是1,一个是1.0, 虽然1 == 1.0,但1和1.0其实是两个不同的元素,这种情况下,两种方法就会形成不同的结果
bisect_right = bisect.bisect_right
for e in new_elements:
position = bisect_right(org_list, e)
"""
新的元素 0 应该插入到原列表的位置: 0
新的元素 2 应该插入到原列表的位置: 1
新的元素 3 应该插入到原列表的位置: 2
新的元素 14 应该插入到原列表的位置: 4
新的元素 21 应该插入到原列表的位置: 5
"""
print('新的元素', e, '应该插入到原列表的位置:', position)
##3-2 如果不关心新元素应该插入的位置,可以使用bisect.insort直接完成插入
for e in new_elements:
bisect.insort(org_list,e)
# 完成插入后的 org_list
print(org_list) # [0, 1, 2, 3, 3, 10, 11, 14, 20, 21]