流畅的Python(三)-字典和集合
一、底层存储结构
1. 字典和集合数据都是以散列表的形式存储
2. 数据要放入散列表,首先需要计算元素(字典中的key/集合中的元素)的散列值-通过hash(key)算法计算所得,并且将散列值的部分位数(低位)作为索引,所以无论是字典中的key还是集合元素必须满足的条件是-可散列的,而一个对象可散列必须满足如下要求:
- 支持hash()函数,并且通过__hash__()方法所得到的散列值是不变的
- 支持通过__eq__()方法来检测相等性
- 若a == b为真,则hash(a) == hash(b)也为真
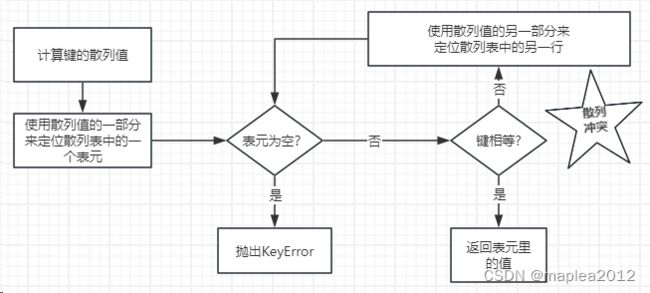
3. 散列表算法-以字典数据查询为例说明
比如有一个字典d1:{'name':'Bill','age':18,'gender':'male'},为了获取d1['name']的值,Python首先会调用hash('name')来计算name的散列值(假设是10110100101001110000000101000001),把该值的最低几位数字(比如01000001))当作偏移量,在散列表中查找表元,若找到的表元是空的,则抛出KeyError;若不是空的,则表元里会有一对key:value值,比如是'name':'Bill',这个时候Python会检查search_key == found_key (比例是'name' == 'name')是否成立, 如果成立,就返回found_value-本例是‘Bill’,如果search_key ≠ found_key, 这种情况称为散列冲突,此时算法会在散列值中另外再取几位(比如0000000101000001),然后用特殊的方法处理一下,把新得到的数字再当作索引来寻找表元,具体示意图如下:
4. 散列算法优势和劣势
(1)优势
- 键查询速度快
(2)弊端
- 内存开销大
5. 关于Python字典数据结构的相关文章
【python资料】字典的hash散列结构_python字典和散列表-CSDN博客
二、代码实现
1、小的tips:正则表达式finditer用法
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2024/1/13 14:46
# @Author : Maple
# @File : 00-相关背景知识.py
# @Software: PyCharm
import re
if __name__ == '__main__':
# 1. 关于正则表达式finditer(4-setdefault中用到)
"""和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
"""
# 匹配字符串中的所有数字
content = '12hello32WE10'
regex1 = re.compile(r'\d+')
# 返回的是一个迭代器
result = regex1.finditer(content)
# 遍历迭代器中的元素
# for number in result:
# """
#
# """
# print(number)
# 获取匹配到的具体值
for num in result:
print(num.group()) # 12 32 10 2、字典构造方法
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2024/1/13 14:00
# @Author : Maple
# @File : 01-字典构造方法.py
# @Software: PyCharm
if __name__ == '__main__':
# 方式1: 字面量
d1 = {'one':1,'two':2,'three':3}
print(d1)
# 方式2:利用dict,参数传入key=value键值对
d2 = dict(one = 1,two = 2 ,three = 3)
print(d2) # {'one': 1, 'two': 2, 'three': 3}
# 方式3: 利用dict,参数传入zip
d3 = dict(zip(['one','two','three'],[1,2,3]))
print(d3) # {'one': 1, 'two': 2, 'three': 3}
# 方式4:利用dict,参数传入列表
d4 = dict([('one',1),('two',2),('three',3)])
print(d4) # {'one': 1, 'two': 2, 'three': 3}
# 方式5:利用dict,参数传入字面量
d5 = dict({'one':1,'two':2,'three':3})
print(d5) # {'one': 1, 'two': 2, 'three': 3}
# 判断上述字典是否相等
print(d1 == d2 == d3 == d4 == d5) #True3、字典推导
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2024/1/13 14:09
# @Author : Maple
# @File : 02-字典推导.py
# @Software: PyCharm
if __name__ == '__main__':
university = [
(1,'MIT'),
(2, 'Cambridge'),
(3, 'Oxford'),
(4,'Harvard'),
(5,'Imperial College London')
]
uni_dict = {rank:name for rank, name in university}
print(uni_dict) # {'1': 'MIT', '2': 'Cambridge', '3': 'Oxford', '4': 'Harvard', '5': 'Imperial College London'}
# 筛选排名前三的大学
uni_dict_filter = {rank:name.upper() for rank,name in uni_dict.items() if rank <= 3}
print(uni_dict_filter) # {1: 'MIT', 2: 'CAMBRIDGE', 3: 'OXFORD'}4、setdefault和defaultdict
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2024/1/13 14:30
# @Author : Maple
# @File : 03-setdefault和defaultdict.py
# @Software: PyCharm
import collections
import re
"""
1. setdefault
-字典的一个方法
-功能: 如果字典中的某个key不存在,可以为其对应的value设置一个默认值
2. defaultdict
-另外一种字典数据类型
-特性:该类型对象.__getitem__时,如果找不到对应的键, 会返回一个数据类型(作为参数传入)空对象的引用
"""
if __name__ == '__main__':
# 1. setdefault
# 匹配所有字母和数字
WORD_RE = re.compile(r'\w+')
index = {}
with open('data/words.txt',encoding='utf-8') as fp:
# enumerate中的参数1代表 序列号从1开始
for line_no,line in enumerate(fp,1):
for match in WORD_RE.finditer(line):
# 获取匹配到的单词
word = match.group()
# 获取单词所在的列
column_no = match.start() + 1
location = {line_no:column_no}
# 如果单词不存在,首先会在index中新增一个元素word:[];然后将location append到该word对应的空列表([])中
index.setdefault(word,[]).append(location)
for word in sorted(index,key=str.upper):
print(word,':', index[word])
print('-------------------------')
# 2. defaultdict
# list是指列表数据类型,不是某个实例
"""
defaultdict特性举例:index2['name'],如果index2中之前并不存在name这个属性,那么底层会有如下操作:
1. 调用list()来建立一个列表实例
2. 把这个列表作为值,name作为键,新增到index2中
3. 返回这个列表的引用
"""
index2 = collections.defaultdict(list)
with open('data/words.txt', encoding='utf-8') as fp:
# enumerate中的参数1代表 序列号从1开始
for line_no, line in enumerate(fp, 1):
for match in WORD_RE.finditer(line):
# 获取匹配到的单词
word = match.group()
# 获取单词所在的列
column_no = match.start() + 1
location = {line_no: column_no}
# index2去get word时,如果单词不存在,首先会在index中新增一个元素word:[];然后将location append到该word对应的空列表([])中
index2[word].append(location)
for word in sorted(index2, key=str.upper):
print(word, ':', index2[word])5、特殊方法missing
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2023/12/31 20:15
# @Author : Maple
# @File : 04-特殊方法missing.py
# @Software: PyCharm
"""自定义数据类型,并且实现get key时如果获取不到,返回一个默认值的方法
1.当有非字符串的键被查找时,将其转换为字符串,并返回一个默认值None
2.判断某个Key(无论是字符串还是非字符串)是否存在于字典
"""
import collections
# 1. 以普通的dict类为父类 自定义子类,需要重写get方法
class StrKeyDict(dict):
def __missing__(self, key):
if isinstance(key,str):
raise KeyError(key)
# ①底层调用的是__getitem__,所以如果不写上面的raise KeyError,对于不存在的键,1和2会无限递归调用
return self[str(key)]
def get(self, key, default=None):
# 如果key能够找到,正常返回
try:
# ② self[key]底层调用的是__getitem__
return self[key]
# 如果找不到key(会调用__missing__方法),最终会给字典赋值一个{key:None},注意如果初始key为非字符串,也会被转化成字符串
except KeyError as e:
return default
def __contains__(self, key):
"""
:param key:字典中的key
:return: 如果key存在于字典,返回True,否则返回False
"""
return key in self.keys() or str(key) in self.keys()
# 2. 以UserDict为基类,不再需要重写get方法,因为UserDict类的get方法和我们上面自己写的一样
# 多了一个data属性,用来存放数据
class StrKeyDict2(collections.UserDict):
def __missing__(self, key):
if isinstance(key,str):
raise KeyError(key)
return self[str(key)]
def __contains__(self, key):
return str(key) in self.data
def __setitem__(self, key, value):
# 新增数据时,传入的键最终都会以字符串的形式存储
self.data[str(key)] = value
if __name__ == '__main__':
# 1. StrKeyDict测试
sd = StrKeyDict((['2','two'],[3,'three'],['4','four']))
print(sd) # {'2': 'two', 3: 'three', '4': 'four'}
r1 = sd.get('2')
print(r1) # two
r2 = sd.get(3)
print(r2) # three
"""查询流程
调用get方法,发现找不到 ->调用__missing__,5判断为非str--> return self[str(key)],即会重新查找字典中是否存在key为'5'的值
-->self['5']仍然找不到,再次调用__missing__,发现'5'是str类型,抛出KeyError,再次return self['5'] --> 调用self['5'],满足KeyError,最终返回None
"""
r3 = sd.get(5)
print(r3) # None
"""查询流程:
调用get方法,发现找不到 ->调用__missing__,4判断为非str--> return self[str(key)],即会重新查找字典中是否存在key为'4'的值-->找到,返回four
"""
r4 = sd.get(4)
print(r4) # four
# 2. StrKeyDict2测试
sd2 = StrKeyDict2((['2','two'],[3,'three'],['4','four']))
# [3,'three']中的key 虽然是以数字形式传入, 最终还是会以字符串形式'3'存储
print(sd2) # {'2': 'two', '3': 'three', '4': 'four'}
# 无论是以3还是'3' get数据,都能得到结果
r5 = sd2.get(3)
print(r5) # three
r6 = sd2.get('3')
print(r6) # three
r7 = sd2.get(5)
print(r7) # None6、集合
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2024/1/14 10:15
# @Author : Maple
# @File : 05-集合.py
# @Software: PyCharm
if __name__ == '__main__':
# 1. 构造方法
## 1-1 字面量方式
s1 = {1,2,4}
print(s1)
##1-2 构造器方式
s2 = set([1,2,4])
print(s2)
# 2. 集合推导式
from unicodedata import name
# 编码在32-255之间的字符,且名字里有'SIGN'的单词集合
s3 = {chr(i) for i in range(32,256) if 'SIGN' in name(chr(i),'')}
print(s3) #{'¢', '÷', '×', '%', '$', 'µ', '#', '>', '¥', '¬', '<', '+', '=', '®', '§', '¶', '¤', '©', '±', '°', '£'}
# 3. 集合的应用举例
needles = {1,2,3,4}
haystack = {1,2,3,4,5,6,7,8,9,10,11,12,13,14}
## needles中的元素,有多少存在于haystack中,
## 传统写法
found = 0
for i in needles:
if i in haystack:
found +=1
print(found)
# 也可以使用如下方法,当集合数据量很大时,效率比传统方式高:
print(len(needles & haystack)) #4
# 或者
print(len(needles.intersection(haystack))) #4