Flink编程——基础环境搭建
基础环境搭建
文章目录
-
- 基础环境搭建
-
- 准备环境搭建
- 源码环境搭建
-
- 克隆代码
- 编译
- 导入IDEA
- 集群环境搭建
-
- 本地模式安装
-
- 步骤 1:下载
- 步骤 2:启动集群
- 步骤 3:提交作业(Job)
- 步骤 4:停止集群
- 总结
准备环境搭建
我们先把电脑的准备环境给安装好,这样后面才能顺利的学习和时间
因为后面可能用到的有:Kafka、MySQL、ElasticSearch 等,另外像 Flink 编写程序还需要依赖Java,还有就是我们项目是用 Maven来管理依赖的,所以需要把这些环境搭建起来,如果可以的话也可以把Hadoop 的环境搭建起来,后面学习数据湖的时候要用。
源码环境搭建
源码环境是我们理解和阅读源代码的最有用的工具了,搭建好源码环境后我们可以对源代码进行调试和二次开发
克隆代码
Flink GitHub 仓库地址:https://github.com/apache/flink 但是GitHub 经常由于网络的一些问题不稳定,我们可以使用Gitee
git clone https://gitee.com/apache/flink.git
’
我们可以切到对应的目录下,查看一下分支情况
编译
mvn clean install -DskipTests -Dfast -Pskip-webui-build -T 1C
- -DskipTests:跳过测试代码
- -Dfast:跳过 QA 的插件和 JavaDocs 的生成
- -Pskip-webui-build:跳过 WebUI 编译
fast 和 skip-webui-build 这两个 Maven profiles 对整体构建时间影响比较大,特别是在存储设备比较慢的机器上,因为对应的任务会读写很多小文件。
注意: maven 的 settings.xml 文件的 mirror 添加下面这个
<mirror>
<id>nexus-aliyunid>
<mirrorOf>*,!jeecg,!jeecg-snapshots,!mapr-releasesmirrorOf>
<name>Nexus aliyunname>
<url>http://maven.aliyun.com/nexus/content/groups/publicurl>
mirror>
<mirror>
<id>mapr-publicid>
<mirrorOf>mapr-releasesmirrorOf>
<name>mapr-releasesname>
<url>https://maven.aliyun.com/repository/mapr-publicurl>
mirror>
可以加速依赖包的下载
’
导入IDEA
IDEA 作为目前我们最长使用的开发工具,我们可以使用IDEA 阅读和理解Flink 的源代码,导入项目之前我们先配置一下Maven,不然我们它默认的目录是在用户目录下,这样就会导致我们在编译时候下载的的依赖还有再下载一遍,所以我们这里配置一下我们的Maven
’
接下来开始导入,步骤参考如下
- 启动 IntelliJ IDEA 并选择 New → Project from Existing Sources。
- 选择已克隆的 Flink 存储库的根文件夹。
- 选择 “Import project from external model”,然后选择 “Maven”。
- 保留默认选项,然后依次单击 “Next”,直到到达 SDK 部分。
- 如果未列出 SDK,请使用左上角的 “+” 号创建一个。选择 “JDK”,选择 JDK 主目录,然后单击 “OK”。选择最合适的 JDK 版本。注意:一个好的经验法则是选择与活动 Maven 配置文件匹配的 JDK 版本。
- 单击 “Next” 继续,直到完成导入。
- 右键单击已导入的 Flink 项目 → Maven → Generate Sources and Update Folders。请注意:这会将 Flink 库安装在本地 Maven 存储库中,默认情况下位于 “/home/$USER/.m2/repository/org/apache/flink/"。另外
mvn clean package -DskipTests也可以创建 IDE 运行所需的文件,但无需安装库。 - 编译项目(Build → Make Project)
我们选择我们的下载目录打开即可
或者这里你可以选择导入项目,然后根据提示一步步完成设置
‘
选择maven
’
最后成功导入,这下我们可以在IDEA 中进行堆代码的调试和开发了
’
集群环境搭建
Apache Flink 可以以多种方式在不同的环境中部署,抛开这种多样性而言,Flink 集群的基本构建方式和操作原则仍然是相同的。
一个 Flink 集群总是包含一个 JobManager以及一个或多个 TaskManager。JobManager 负责处理 Job提交、 Job 监控以及资源管理。Flink TaskManager 运行 worker 进程, 负责实际任务 Tasks的执行,而这些任务共同组成了一个 Flink Job。
本地模式安装
请按照以下几个步骤下载最新的稳定版本开始使用。
步骤 1:下载
为了运行Flink,需提前安装好 Java 11 或者 Java8。你可以通过以下命令来检查 Java 是否已经安装正确。
java -version
下载 release 1.18.0 并解压。
$ tar -xzf flink-1.18.0-bin-scala_2.12.tgz
$ cd flink-1.18.0-bin-scala_2.12
步骤 2:启动集群
Flink 附带了一个 bash 脚本,可以用于启动本地集群。
$ ./bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host.
Starting taskexecutor daemon on host.
因为我这里在worker 文件里配置在本地启动了三个TaskManager 进程
‘
‘
步骤 3:提交作业(Job)
Flink 的 Releases 附带了许多的示例作业。你可以任意选择一个,快速部署到已运行的集群上。
$ ./bin/flink run examples/streaming/WordCount.jar
$ tail log/flink-*-taskexecutor-*.out
(nymph,1)
(in,3)
(thy,1)
(orisons,1)
(be,4)
(all,2)
(my,1)
(sins,1)
(remember,1)
(d,4)
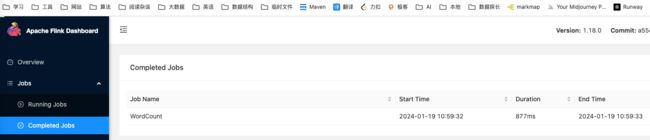
另外,你可以通过 Flink 的 Web UI 来监视集群的状态和正在运行的作业,可以看到作业已经运行结束了
’
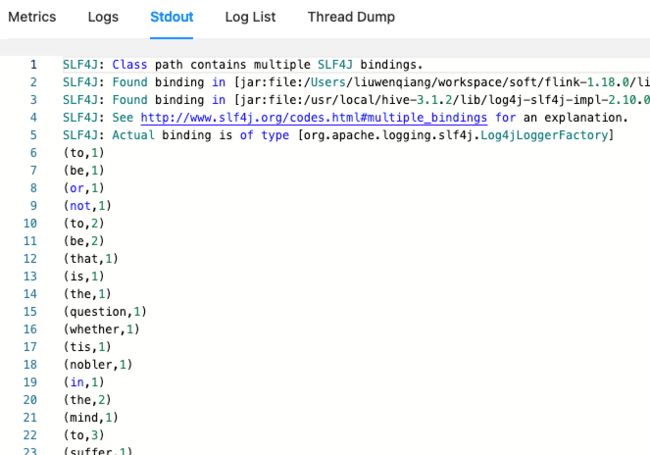
上面的日志输出,你也可以在Flink 的 Web UI 上看,但是因为我们这里启动了三个TaskManager,但是我们的任务并行度是1 ,也就是只有某一个的TaskManager 日志可以看到
 ‘
‘
下面就是 Web UI 上的日志
’
步骤 4:停止集群
完成后,你可以快速停止集群和所有正在运行的组件。
$ ./bin/stop-cluster.sh
’
总结
到这里我们的环境搭建就完成了主要包括
- 准备环境搭建
- 源码环境搭建
- 集群环境搭建