可观测实践丨如何利用 AI 算法解决告警配置三大难题?
作者:陈昆仪(图杨)
每个运维工程师都躲不开的噩梦
为了更代入感地解读业务场景,这里我们以运维工程师小 A 的视角来开始今天的解读。
年轻有为的运维工程师 小 A 刚接手公司最核心业务系统的稳定性保障工作。但他发现这个任务非常具有挑战性,可以说是噩梦。
1)有没有合适工具,告诉小 A 应该对哪些指标配告警?
这个系统非常复杂,既有像 CPU 使用率、内存使用率等基础指标,又有像响应时间、调用量等业务指标,又因为包含着很多 Java 应用,还需要关注一下 JVM 指标,林林总总几百个指标。小 A 不知道哪些指标是最重要的,也不知道应该对哪些指标配告警。
2)有没有合适工具,给小 A 自动推荐合适的告警阈值?
小 A 请教资深运维工程师“稳哥”,“稳哥”根据他 10 年运维经验,给小 A 划了需要重点监控的十几个指标。小 A 非常开心的开始配告警。但小 A 填告警阈值时,发现“阈值设置得太松,有可能漏掉问题;阈值设置的太严,一天下来告警 999+”。小A又回去请教“稳哥”,“稳哥”表示阈值这种东西,必须参考每个指标历史表现来设置。而且现在公司的业务不断发展壮大,需要不断地调整阈值,他也没有办法给小 A 一组长期有效的阈值。
3)有没有合适工具,帮小 A 给起伏不定的指标配告警?
小 A 经过不断地调整阈值和试错,终于慢慢得到了一组还算有效的阈值。但小 A 发现有的指标天然起伏不定,无论用什么阈值都不大合适。比如打车业务每天上下班的时段,下单接口每分钟有 1000+ 调用量,如果低于这个阈值就可能是系统出现了故障引发资损,需要及时告警。但在非高峰期时段,每分钟调用量为 0 也非常正常,这种场景不需要告警。但现有可观测产品好像并不支持给不同时间段设置不同告警阈值。
针对小 A 的这三个问题,阿里云应用实时监控服务(ARMS)给的答案是“有”、“有”以及“有”。
围绕小 A 遇到的这三个问题,接下来给大家介绍更简单、精准的智能告警能力,手把手教小 A 配出“系统无异常时不误告,有异常时及时告”的高质量告警规则,完成公司最核心业务系统的稳定性保障任务。
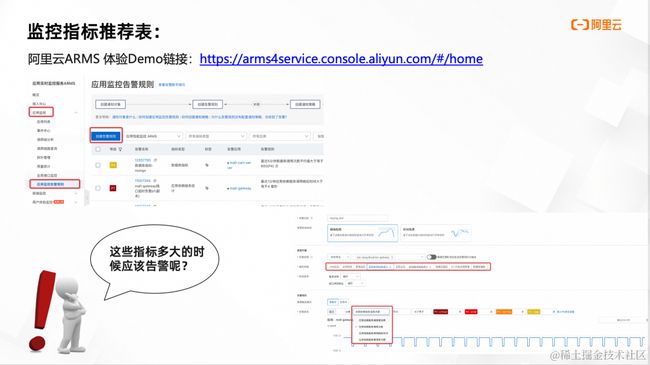
“不知道该监控哪些指标?” ——监控指标推荐表
先来看看应该对什么指标配告警。其实对于已经接入 ARMS 应用监控的用户来说,常见的、重要的监控指标 ARMS 探针都是会自动采集。这里 ARMS 对比较重要的指标分了类,可以结合自身业务特征来决定对哪些指标配告警。

对于应用监控的用户来说,建议先对黄金三指标:调用次数、响应时间、错误率和错误次数配上告警。这是因为如果出了突增或突降,很有可能会直接影响业务。值得关注的还有一些 Http 状态码的里面 4xx、5xx 指标、Full GC 次数、数据库调用响应时间这类指标。如果负责的功能使用 Java 开发的,就配上 JVM 监控相关指标,如果强依赖于某个数据库,就把数据库指标也配上告警。
在帮助文档里有对这些指标更详细的说明,可以查看下方的链接:
https://help.aliyun.com/zh/arms/application-monitoring/developer-reference/alert-rule-metrics?spm=a2c4g.11186623.0.0.54063cb0urqdAj
另外,这些指标其实在 ARMS 告警配置页面可以直接选,ARMS 用户配告警时可以直接看到所有指标。
”不知道该设置什么阈值?” ——智能阈值推荐及告警预览功能
当选好了需要监控指标和应用,马上会遇到下一个问题 – 不知道该如何设置告警阈值。或者说,不知道当系统的响应时间、错误率、机器的 CPU 使用率大于多少时,表示这个系统目前处于异常状态。
这其实可以算是一个异常检测的问题,业界比较常见的思路是推出“无阈值告警”服务。一般会给出一个下拉框,里面有十几种异常检测算法,告诉运维工程师说“选一个适合你的”。但一般也不知道哪个适合对应的业务系统。而且异常检测算法少说有几百种,并没有绝对“最优”的算法,一个一个试也不大现实。
但 ARMS 应用监控配告警时,就像把大象塞入冰箱一样,选合适的阈值只需要三步:
-
选好需要监控的应用和指标
-
点击“填入 P4 建议阈值”
-
根据 24h 指标真实历史数据,帮助用户做校验和修改

这个时候,可能会有人问:我怎么知道你给我推荐的阈值合不合适呢?这是一个非常关键的问题。所以,ARMS 不仅自动根据指标生成一个阈值,并把过去 24h 指标及阈值的水位线画出来,方便进行比较和验证阈值设置的合理性。展示的都是用户自身数据,可以一眼看出来推荐的阈值是否合理,也非常方便后面进行调节。
也会有人觉得 ARMS 这种产品设计不够“智能”。但再高端的算法,被验证了 99.9% 的准确性,也没人能保证用户不是那额外的 0.1%。如果那次漏掉的告警刚好背后是一个大故障,是会对业务造成很大损失的。在告警配置环节,ARMS 希望给到一种“最让人放心”的方案。可以清晰看到阈值和实际数据的对比,给出足够信息帮助调节阈值。这也是目前能找到的最直观能验证告警规则合理性的方式。

这里解释一下“填入 P4 建议阈值”的“P4”是什么意思。ARMS 告警支持同一指标配置不同阈值来显示告警不同严重程度,从 P1 到 P4 ,严重程度依次递减。比如同个应用,响应时间大于 1s 只是有点卡顿,大于 5s 也还行,但 1min 都还没有返回结果,可能就是系统出故障了,需要排查。这里默认给出了稍微异常的建议阈值,可根据P4给的阈值来填 P1、2、3。当然也支持只填一个 P4 阈值。ARMS 对每个填写的阈值都会画出水位线,协助进行调整。
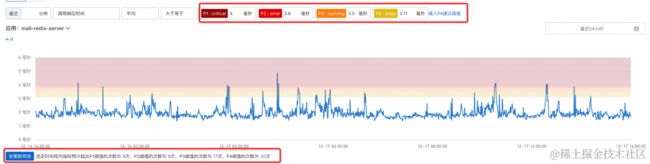
配置完成之后,就可以点击“告警数预测按钮”,可以看到在当前配置下,过去24小时内实际值超出每个阈值多少次。如果它显示 3、4 次,也可以知道过去 1 天确定发生过一些异常,需要通知到运维工程师,也可以理解为当前阈值设置是合理的。但如果过去 1 天发生了 1000 多次告警,建议还是把阈值调高一些。
此外,ARMS 也支持多种指标结合方式来配置告警。比如运维工程师用的比较多的是“每分钟调用量”超过 200 次,且错误率大于 5% 就发出告警,这样可以有效地过滤掉一下,比如一共就 2 次调用,出错了一次,导致错误率上涨到 50% 的误告警。

除了以上的常规用法之外,ARMS 发现有些聪明的运维工程师研究出了“告警数预测”按钮,更高级的“明天再说”用法。就是有的告警他收到了,发现是个不大重要的 P4 告警,而且他已经下班了,就先不处理,第二天回来看,点一下告警数预测这个按钮,查一下异常发生时刻,开始定位问题。他会开始找异常发生时段对应 CPU 使用率、内存使用率等指标,定位根因,并想办法对系统进行进一步的优化。
“指标正常情况就起伏不定,怎么配告警?”——阈值检测和区间检测搭配
最后解决前文提到的最后一个问题:“对于起伏不定的指标,怎么配告警”。这种“起伏不定的指标,一般是业务指标”。比如上文提到的打车业务早晚高峰与非高峰时段的起伏问题。有的运维工程师会表示,那晚上自动把告警关掉就好了,但现实生活中,这种起伏不定的指标,很难有像“1000”这么规整的阈值,现实生活中的调用量指标是下面的样子,就是会有一些令人意想不到的“大毛刺”。
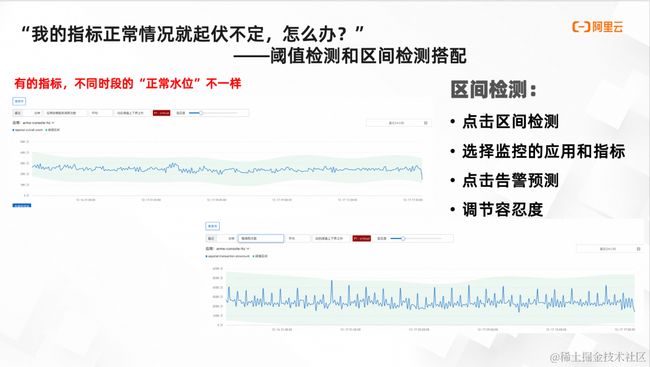
针对这个场景,ARMS 做了区间检测功能。进入区间检测功能之后,选好要监控的应用和指标。ARMS 就会自动根据指标历史数据,对正常情况下变化范围进行学习,得到上下边界。ARMS 提供上下边界预览功能,可以对算法计算出来的上下边界进行预览。下图中,蓝线是指标的实际值,绿色的阴影是上下边界。也可以根据实际需要调节灵敏度,也就是这个绿色阴影的宽度。
这篇文章主要是一个最佳实践,对算法感兴趣的同学可以看我们另一篇文章:《只需半分钟,ARMS 帮你配置出“高质量”告警》[1]
与静态阈值推荐功能不同的地方在于当业务变化导致指标正常水位发生变化,运维工程师不需通过手动编辑告警规则的方式来更新阈值。这是因为 ARMS 以每天一次的频率持续学习指标特征,并只预测未来一天的上下边界。运维工程师无需再一遍遍来回地调整阈值。ARMS 区间检测告警,仅需一次配置,自适应学习指标特征,持久有效。
总结
在这篇文章中,我们通过运维工程师小 A 的故事,为大家介绍了在配置告警时过程中比较常见的三个问题,以及如何使用 ARMS 智能告警解决它们:
Q 1 :“不知道该监控哪些指标”?
A 1:ARMS 应用监控告警中,覆盖了几乎所有重要的告警指标,也给大家提供了指标的说明文档和实践指南,可以参考[2]。
Q 2:“不知道该设置什么阈值”?
A 2:使用 ARMS 最近推出的【告警阈值推荐】功能得到一个建议阈值,以及与真实指标的对比图。结合图标以及【告警数】预测功能进行调整。
Q 3:“指标正常情况下就起伏不定,怎么配告警”?
A 3:使用【区间检测】功能,可以直接使用 ARMS 生产的上下边界,也可以通过和实际指标的对比调节灵敏度。目前,应用监控与智能告警都提供免费额度,使大家更好的构建应用监控与智能告警体系。
- 应用监控每月提供 50GB 免费额度
- 智能告警每天提供 15 次短信免费额度,每天提供 3 次电话免费额度

对智能告警或者是其他 AIOps 功能感兴趣的同学可以通过搜索钉钉群号加入我们的 ARMS-Insights 客户交流群。(群号:25125004458)
相关链接:
[1] 只需半分钟,ARMS 帮你配置出“高质量”告警
[2] 监控指标推荐文档
https://help.aliyun.com/zh/arms/application-monitoring/developer-reference/alert-rule-metrics?spm=a2c4g.11186623.0.0.54063cb0urqdAj