【第四课课后作业】XTuner大模型单卡低成本微调实战

基础作业
1. 安装与配置环境
# InternStudio 平台中,从本地 clone 一个已有 pytorch 2.0.1 的环境(后续均在该环境执行,若为其他环境可作为参考)
# 进入环境后首先 bash
# 进入环境后首先 bash
# 进入环境后首先 bash
bash
conda create --name personal_assistant --clone=/root/share/conda_envs/internlm-base
# 如果在其他平台:
# conda create --name personal_assistant python=3.10 -y
# 激活环境
conda activate personal_assistant
# 进入家目录 (~的意思是 “当前用户的home路径”)
cd ~
# 创建版本文件夹并进入,以跟随本教程
# personal_assistant用于存放本教程所使用的东西
mkdir /root/personal_assistant && cd /root/personal_assistant
mkdir /root/personal_assistant/xtuner019 && cd /root/personal_assistant/xtuner019
# 拉取 0.1.9 的版本源码
git clone -b v0.1.9 https://github.com/InternLM/xtuner
# 无法访问github的用户请从 gitee 拉取:
# git clone -b v0.1.9 https://gitee.com/Internlm/xtuner
# 进入源码目录
cd xtuner
# 从源码安装 XTuner
pip install -e '.[all]'
安装完后,就开始搞搞准备工作了,创建工作路径。(准备在 oasst1 数据集上微调 internlm-7b-chat)
# 创建一个微调 oasst1 数据集的工作路径,进入
mkdir ~/ft-oasst1 && cd ~/ft-oasst1
2. 数据准备
创建data文件夹用于存放用于训练的数据集
mkdir -p /root/personal_assistant/data && cd /root/personal_assistant/data


3. 配置准备
下载模型InternLM-chat-7B
mkdir -p /root/personal_assistant/model/Shanghai_AI_Laboratory
cp -r /root/share/temp/model_repos/internlm-chat-7b /root/personal_assistant/model/Shanghai_AI_Laboratory
# 列出所有内置配置
xtuner list-cfg
#创建用于存放配置的文件夹config并进入
mkdir /root/personal_assistant/config && cd /root/personal_assistant/config
拷贝一个配置文件到当前目录:xtuner copy-cfg ${CONFIG_NAME} ${SAVE_PATH} 在本例中:(注意最后有个英文句号,代表复制到当前路径)
xtuner copy-cfg internlm_chat_7b_qlora_oasst1_e3 .

# PART 1 中
# 预训练模型存放的位置
pretrained_model_name_or_path = '/root/personal_assistant/model/Shanghai_AI_Laboratory/internlm-chat-7b'
# 微调数据存放的位置
data_path = '/root/personal_assistant/data/personal_assistant.json'
# 训练中最大的文本长度
max_length = 512
# 每一批训练样本的大小
batch_size = 2
# 最大训练轮数
max_epochs = 3
# 验证的频率
evaluation_freq = 90
# 用于评估输出内容的问题(用于评估的问题尽量与数据集的question保持一致)
evaluation_inputs = [ '请介绍一下你自己', '请做一下自我介绍' ]
# PART 3 中
dataset=dict(type=load_dataset, path='json', data_files=dict(train=data_path))
dataset_map_fn=None
4. 微调启动
xtuner train /root/personal_assistant/config/internlm_chat_7b_qlora_oasst1_e3_copy.py
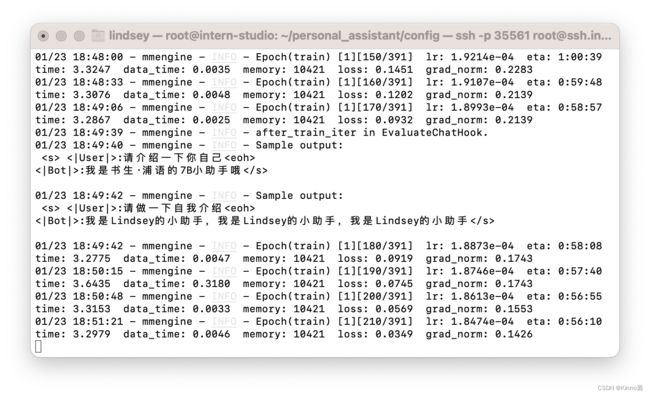

在训练完成后,输出用于验证的Sample output
1万条数据,3个批次,每个批次迭代391次,一共训练了1个多小时。
5. 微调后参数转换/合并
训练后产生的pth格式参数转为先前模型使用的Hugging Face格式
# 创建用于存放Hugging Face格式参数的hf文件夹
mkdir /root/personal_assistant/config/work_dirs/hf
export MKL_SERVICE_FORCE_INTEL=1
# 配置文件存放的位置
export CONFIG_NAME_OR_PATH=/root/personal_assistant/config/internlm_chat_7b_qlora_oasst1_e3_copy.py
# 模型训练后得到的pth格式参数存放的位置
export PTH=/root/personal_assistant/config/work_dirs/internlm_chat_7b_qlora_oasst1_e3_copy/epoch_3.pth
# pth文件转换为Hugging Face格式后参数存放的位置
export SAVE_PATH=/root/personal_assistant/config/work_dirs/hf
# 执行参数转换
xtuner convert pth_to_hf $CONFIG_NAME_OR_PATH $PTH $SAVE_PATH

Merge模型参数
export MKL_SERVICE_FORCE_INTEL=1
export MKL_THREADING_LAYER='GNU'
# 原始模型参数存放的位置
export NAME_OR_PATH_TO_LLM=/root/personal_assistant/model/Shanghai_AI_Laboratory/internlm-chat-7b
# Hugging Face格式参数存放的位置
export NAME_OR_PATH_TO_ADAPTER=/root/personal_assistant/config/work_dirs/hf
# 最终Merge后的参数存放的位置
mkdir /root/personal_assistant/config/work_dirs/hf_merge
export SAVE_PATH=/root/personal_assistant/config/work_dirs/hf_merge
# 执行参数Merge
xtuner convert merge \
$NAME_OR_PATH_TO_LLM \
$NAME_OR_PATH_TO_ADAPTER \
$SAVE_PATH \
--max-shard-size 2GB

6. 网页demo
安装网页Demo所需依赖
pip install streamlit==1.24.0
下载InternLM项目代码
# 创建code文件夹用于存放InternLM项目代码
mkdir /root/personal_assistant/code && cd /root/personal_assistant/code
git clone https://github.com/InternLM/InternLM.git
将 /root/personal_assistant/code//InternLM/web_demo.py 中 29 行和 33 行的模型路径更换为Merge后存放参数的路径 /root/personal_assistant/config/work_dirs/hf_merge
因为最新github上上传的项目,web_demo.py的路径和教程中改变了,但是代码中的相对路径内容没有改,所以还需要改一下代码中user_avator和robot_avator的路径,不然运行后会读不到这两张图片。

本地绑定端口:
运行web_demo.py

7. 最终效果
终于可以成功运行了
