pytorch(三)反向传播
文章目录
-
- 反向传播
- tensor的广播机制
反向传播
- 前馈过程的目的是为了计算损失loss
- 反向传播的目的是为了更新权重w,这里权重的更新是使用随机梯度下降来更新的。
前馈过程
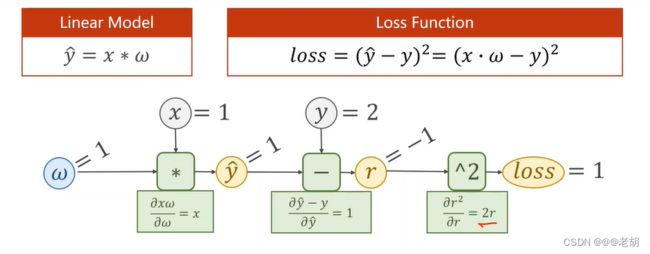
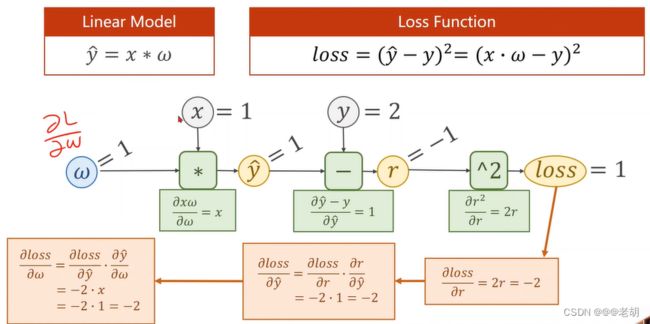
反馈过程
import torch
x_data=[1.0,2.0,3.0]
y_data=[2.0,4.0,6.0]
w=torch.Tensor([1.0])
# 表示需要计算梯度,默认不需要计算梯度
w.requires_grad=True
def forward(x):
return x*w # w是tensor类型,则运算会被重载成tensor之间的运算,x会被自动类型转换为tensor类型
def loss(x,y):
y_pred=forward(x)
return (y_pred-y)**2
print('predict before:',4,forward(4).item())
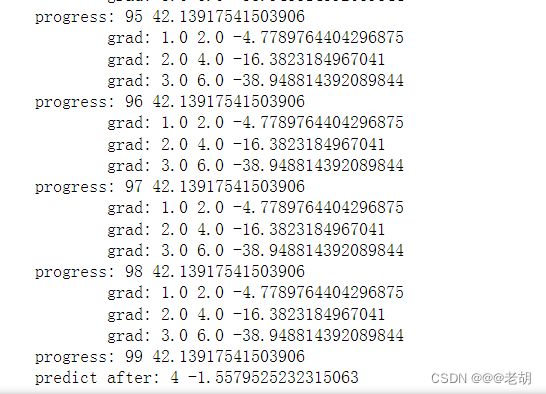
for epoch in range(100):
for x,y in zip(x_data,y_data):
# 前馈过程
l=loss(x,y)
# 反馈过程,会自动计算,存储在w中,完成存储后释放计算图
l.backward()
print('\tgrad:',x,y,w.grad.item())
# 权重更新,使用data标量,grad也是tensor
w.data=w.data=0.01*w.grad.data
# 权重中的梯度数据清零
w.grad.data.zero_()
print('progress:',epoch,l.item())
print('predict after:',4,forward(4).item())
运行结果
在神经网路中,经常对线性的结果做一个非线性函数的变幻的展开,这就是激活函数。激活函数可以使得模型具有非线性。激活函数给神经元引入了非线性因素,神经网络就可以毕竟任意的非线性函数。如果不增加激活函数,模型展开之后还是线性模型,就还是只有一层。
tensor的广播机制
在tensor的使用过程中,我们经常需要对不同形状的tensor进行计算,这个时候就需要用到tensor的广播机制
tansor的广播机制就是在不同的rensor之间进行计算时,自动将数据进行扩展的一种方式。简单来说,就是当两个tensor的形状不同时,tensor会自动的将自己的形状扩展为另一个tensor的相同形状,然后进行计算。通常情况下,小一点的数组会被广播成大一点的数组,这样才能保持大小一致。
tensor的广播机制需要遵循以下规则:
- 每个tensor至少有一个维度
- 遍历tensor所有维度时,从末尾开始遍历(从右向左),两个tensor可能存在以下情况
- tensor维度相同
- tensor维度不同但是其中一个维度为1
- tensor维度不等且其中一个维度不存在
满足以上规则的tensor可以进行广播,维度扩展的过程就是将数值进行复制的过程。示例如下
import torch
a=torch.Tensor([1,2,3])
b=torch.Tensor([[1],[2],[3]])
# b=torch.Tensor([2,3])
c=a+b
print('c',c)
c=b+a
print('c',c)
运行结果
c tensor([[2., 3., 4.],
[3., 4., 5.],
[4., 5., 6.]])
c tensor([[2., 3., 4.],
[3., 4., 5.],
[4., 5., 6.]])
有如下情况是不可以进行广播的:
- 参与运算的tensor维度不等但是其中没有一个的维度为1
- 参与运算的tensor其中一个没有任何维度,示例如下
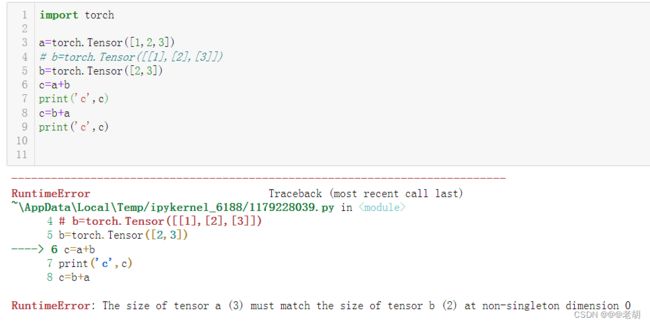
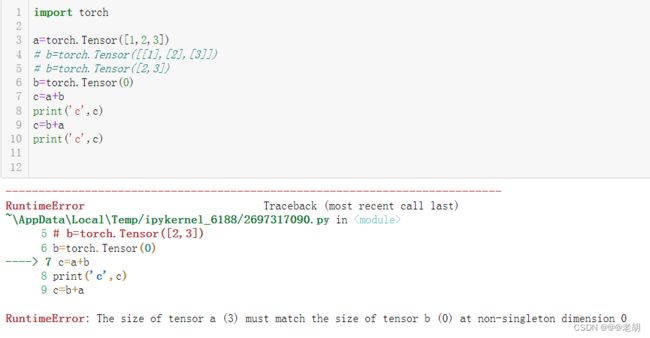
ps:这种广播机制并不是tensor独有的,numpy数组也可以广播,详情可以查看 numpy的广播机制