《动手学深度学习(PyTorch版)》笔记2
Chapter2 Preliminaries
Automatic Differentiation
让计算机实现微分功能, 有以下四种方式:
- 手工计算出微分, 然后编码进代码
- 数值微分 (numerical differentiation)
- 符号微分 (symbolic differentiation)
- 自动微分(automatic differentiation)
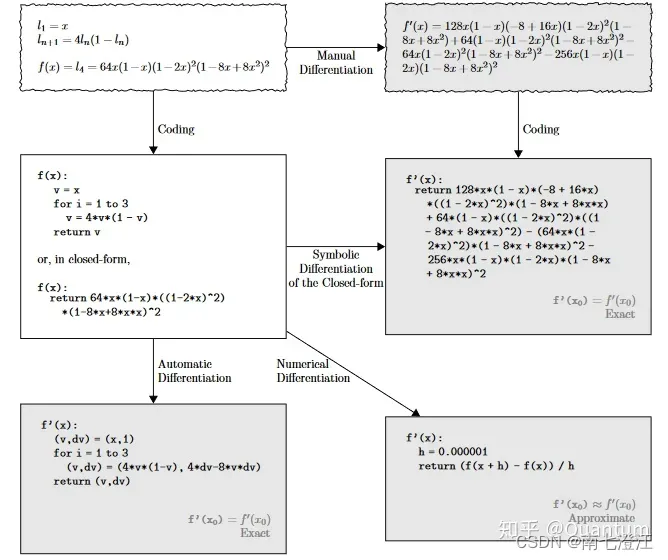
深度学习框架通过自动微分来加快求导。
实际中,根据设计好的模型,系统会构建一个计算图(computational graph),来跟踪计算是哪些数据通过哪些操作组合起来产生输出。自动微分使系统能够随后反向传播梯度。这里,反向传播(backpropagate)意味着跟踪整个计算图,填充关于每个参数的偏导数。自动微分以链式法则为基础,将一个复杂的数学运算过程分解为一系列简单的基本运算,把公式中一些部分整理出来成为一些新变量,然后用这些新变量整体替换这个公式,而且每一项基本运算都可以通过查表得出来。自动微分有两种形式
- 前向模式 (forward mode)
- 反向模式 (reverse mode)
前向模式是在计算图前向传播的同时计算微分。下面的前向模式微分中, v i ˙ = ∂ v i ∂ x 1 \dot{v_i}=\frac{\partial v_i}{\partial x_1} vi˙=∂x1∂vi 。

反向模式需要对计算图进行一次正向计算, 得出输出值,再进行反向传播, 其中 v i ˉ = ∂ y j ∂ v i \bar{v_i}=\frac{\partial y_j}{\partial v_i} viˉ=∂vi∂yj 。

前向模式的一次正向传播能够计算出输出值以及导数值, 而反向模式需要先进行正向传播计算出输出值, 然后进行反向传播计算导数值,所以反向模式的内存开销要大一点, 因为它需要保存正向传播中的中间变量值,这些变量值用于反向传播的时候计算导数。当输出的维度大于输入的时候,适宜使用前向模式微分;当输出维度远远小于输入的时候,适宜使用反向模式微分。
从矩阵乘法次数的角度来看,前向模式和反向模式的不同之处在于矩阵相乘的起始之处不同。当输出维度小于输入维度,反向模式的乘法次数要小于前向模式。

一个简单的例子
假设我们想对函数 y = 2 x ⊤ x y=2\mathbf{x}^{\top}\mathbf{x} y=2x⊤x关于列向量 x \mathbf{x} x求导。首先,我们创建变量x并为其分配一个初始值。
import torch
x = torch.arange(4.0)
x
结果:
tensor([0., 1., 2., 3.])
在我们计算 y y y关于 x \mathbf{x} x的梯度之前,需要一个地方来存储梯度。重要的是,我们不会在每次对一个参数求导时都分配新的内存。因为我们经常会成千上万次地更新相同的参数,每次都分配新的内存可能很快就会将内存耗尽。注意,一个标量函数关于向量 x \mathbf{x} x的梯度是向量,并且与 x \mathbf{x} x具有相同的形状。
x.requires_grad_(True) # 等价于x=torch.arange(4.0,requires_grad=True)
x.grad #
y = 2 * torch.dot(x, x)
y
结果:
tensor(28., grad_fn=)
x \mathbf{x} x是一个长度为4的向量,计算 x \mathbf{x} x和 x \mathbf{x} x的点积,得到了我们赋值给y的标量输出。
接下来,通过调用反向传播函数来自动计算y关于x每个分量的梯度,并打印这些梯度。
y.backward()
x.grad
结果:
tensor([ 0., 4., 8., 12.])
函数 y = 2 x ⊤ x y=2\mathbf{x}^{\top}\mathbf{x} y=2x⊤x关于 x \mathbf{x} x的梯度应为 4 x 4\mathbf{x} 4x,显然计算结果正确。
现在计算 x \mathbf{x} x的另一个函数。
# 在默认情况下,PyTorch会累积梯度,我们需要清除之前的值
x.grad.zero_() #将张量x的梯度清零
y = x.sum()
y.backward()
x.grad
结果:
tensor([1., 1., 1., 1.])
非标量变量的反向传播
当y不是标量时,向量 y \mathbf{y} y关于向量 x \mathbf{x} x的导数的最自然解释是一个矩阵。
对于高阶和高维的y和 x \mathbf{x} x,求导的结果可以是一个高阶张量。
然而,虽然这些更奇特的对象确实出现在高级机器学习中,但当调用向量的反向计算时,我们通常会试图计算一批训练样本中每个组成部分的损失函数的导数。这里我们的目的不是计算微分矩阵,而是单独计算批量中每个样本的偏导数之和。
# 对非标量调用backward需要传入一个gradient参数,该参数指定微分函数关于self的梯度。
# 本例只想求偏导数的和,所以传递一个1的梯度是合适的
x.grad.zero_()
y = x * x
y.sum().backward()#等价于y.backward(torch.ones(len(x)))
x.grad
结果:
tensor([0., 2., 4., 6.])
分离计算
有时,我们希望将某些计算移动到记录的计算图之外。例如,假设y是作为x的函数计算的,而z则是作为y和x的函数计算的。想象一下,我们想计算z关于x的梯度,但由于某种原因,希望将y视为一个常数,并且只考虑到x在y被计算后发挥的作用。这里可以分离y来返回一个新变量u,该变量与y具有相同的值,但丢弃计算图中如何计算y的任何信息。换句话说,梯度不会向后流经u到x。因此,下面的反向传播函数计算z=u*x关于x的偏导数,同时将u作为常数处理,而不是z=x*x*x关于x的偏导数。
x.grad.zero_()
y = x * x
u = y.detach()
z = u * x
z.sum().backward()
x.grad == u
结果:
tensor([True, True, True, True])
由于记录了y的计算结果,我们可以随后在y上调用反向传播,
得到y=x*x关于的x的导数,即2*x。
x.grad.zero_()
y.sum().backward()
x.grad == 2 * x
结果:
tensor([True, True, True, True])
Python控制流的梯度计算
使用自动微分的一个好处是:
即使构建函数的计算图需要通过Python控制流(例如,条件、循环或任意函数调用),我们仍然可以计算得到的变量的梯度。
在下面的代码中,while循环的迭代次数和if语句的结果都取决于输入a的值。
def f(a):
b = a * 2
while b.norm() < 1000:
b = b * 2
if b.sum() > 0:
c = b
else:
c = 100 * b
return c
a = torch.randn(size=(), requires_grad=True)
d = f(a)
d.backward()
a.grad == d / a
我们现在可以分析上面定义的f函数。
请注意,它在其输入a中是分段线性的。
换言之,对于任何a,存在某个常量标量k,使得f(a)=k*a,其中k的值取决于输入a,因此可以用d/a验证梯度是否正确。
结果:
tensor(True)
小结
- 深度学习框架可以自动计算导数:我们首先将梯度附加到想要对其计算偏导数的变量上,然后记录目标值的计算,执行它的反向传播函数,并访问得到的梯度。
参考文献
- 一文看懂AD原理
- AD的正反向模式
- AD的常用实现方案
- 反向OO实现自动微分(Pytroch核心机制)
- Automatic differentiation in machine learning: a survey