K8S:二进制安装K8S(单台master)
目录
一、安装K8S
1、拓扑图编辑
2、系统初始化配置
3、部署docker引擎
4、部署etcd集群
①etcd简介
②准备签发证书环境
③etcd部署
5、master部署组件
6、 部署 Worker Node 组件
7、 node节点部署flannel网络插件
一、安装K8S
1、拓扑图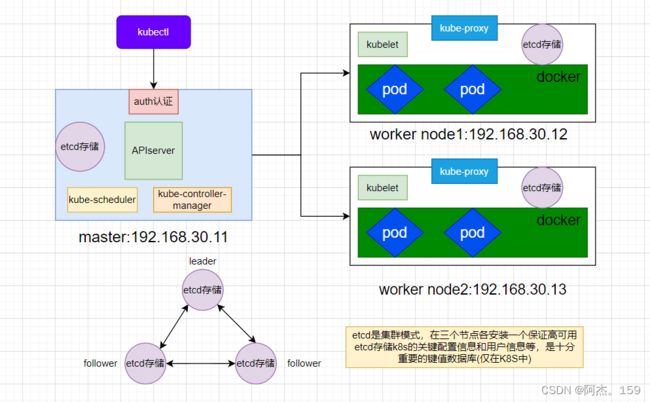
2、系统初始化配置
#所有节点执行
systemctl stop firewalld
systemctl disable firewalld
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
#永久关闭firewalld并清空iptables所有表规则
setenforce 0
sed -i 's/enforcing/disabled/' /etc/selinux/config
swapoff -a
sed -ri 's/.*swap.*/#&/' /etc/fstab
#永久关闭selinux和swap分区
#三个节点分开执行
hostnamectl set-hostname master01
#192.168.30.11的master上执行修改主机名
hostnamectl set-hostname node01
#192.168.30.12的node1上执行修改主机名
hostnamectl set-hostname node02
#192.168.30.13的node2上执行修改主机名
#所有节点执行
bash
#刷新bash使得修改的主机名生效
cat >> /etc/hosts << EOF
192.168.30.11 master01
192.168.30.12 node1
192.168.30.13 node2
EOF
#使用多行重定向将主机名对应的ip写到hosts里面加快访问速度,注意改为自己的ip
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv6.conf.all.disable_ipv6=1
net.ipv4.ip_forward=1
EOF
#使用多行重定向调整内核参数,前2行为开启网桥模式后2行为关闭ipv6协议和开启路由转发
sysctl --system
#加载内核使得配置内核参数生效
yum install ntpdate -y
ntpdate time.windows.com
#安装ntpdate时间同步程序,并与本机的windows同步时间
3、部署docker引擎
#2个node节点执行
yum install -y yum-utils device-mapper-persistent-data lvm2
#安装依赖包以便在系统上安装docker
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
#添加Docker官方源,并将它设置为docker-ce.repo文件
yum install -y docker-ce docker-ce-cli containerd.io
#yum安装docker-ce和docker客户端以及容器io
systemctl start docker.service
systemctl enable docker.service
#开机自启并现在启动docker
4、部署etcd集群
①etcd简介
etcd是CoreOS团队于2013年6月发起的开源项目,它的目标是构建一个高可用的分布式键值(key-value)数据库。etcd内部采用raft协议作为一致性算法,etcd是go语言编写的。
etcd 作为服务发现系统,有以下的特点:
简单:安装配置简单,而且提供了HTTP API进行交互,使用也很简单
安全:支持SSL证书验证
快速:单实例支持每秒2k+读操作
可靠:采用raft算法,实现分布式系统数据的可用性和一致性
etcd 目前默认使用2379端口提供HTTP API服务, 2380端口和peer通信(这两个端口已经被IANA(互联网数字分配机构)官方预留给etcd)。 即etcd默认使用2379端口对外为客户端提供通讯,使用端口2380来进行服务器间内部通讯。
etcd 在生产环境中一般推荐集群方式部署。由于etcd 的leader选举机制,要求至少为3台或以上的奇数台。
②准备签发证书环境
本文使用CFSSL工具签发证书
CFSSL 是 CloudFlare 公司开源的一款 PKI/TLS 工具。 CFSSL 包含一个命令行工具和一个用于签名、验证和捆绑 TLS 证书的 HTTP API 服务。使用Go语言编写。
CFSSL 使用配置文件生成证书,因此自签之前,需要生成它识别的 json 格式的配置文件,CFSSL 提供了方便的命令行生成配置文件。
CFSSL 用来为 etcd 提供 TLS 证书,它支持签三种类型的证书:
1、client 证书,服务端连接客户端时携带的证书,用于客户端验证服务端身份,如 kube-apiserver 访问 etcd;
2、peer 证书,相互之间连接时使用的证书,如 etcd 节点之间进行验证和通信。
这里全部都使用同一套证书认证。
3、server 证书,客户端连接服务端时携带的证书,用于服务端验证客户端身份,如 etcd 对外提供服务;本次实验使用的是server证书。
③etcd部署
#master节点操作,#本文的所有需要上传资源在博客资源包中K8S压缩包中均有
cd /usr/local/bin
chmod +x /usr/local/bin/cfssl*
#将cfssl证书签发的工具和命令(cfssl、cfssljson、cfssl-certinfo)上传到/usr/local/bin目录下并添加执行权限
#本文的cfssl工具在博客资源包中K8S压缩包中有
#cfssl:证书签发的工具命令
#cfssljson:将 cfssl 生成的证书(json格式)变为文件承载式证书
#cfssl-certinfo:验证证书的信息
#cfssl-certinfo -cert <证书名称> #查看证书的信息
mkdir /opt/k8s
cd /opt/k8s/
#上传 etcd-cert.sh(生成证书脚本) 和 etcd.sh(创建etcd集群脚本) 到 /opt/k8s/ 目录中
chmod +x etcd-cert.sh etcd.sh
#添加可执行权限
mkdir /opt/k8s/etcd-cert
#创建etcd-cert目录用于存放etcd的证书
mv etcd-cert.sh /opt/k8s/etcd-cert
#移动生成证书的脚本到存放etcd证书的目录下
vim /opt/k8s/etcd-cert/etcd-cert.sh
#此脚本ip需要修改80到82行master,node1,node2顺序保存退出
vim ./etcd-cert.sh
#修改脚本中的ip为自己的ip
./etcd-cert.sh
#生成CA证书、etcd 服务器证书以及私钥
ls /opt/k8s/etcd-cert
#查看生成的证书是否为4个.pem结尾3个.json结尾
#上传 etcd-v3.4.9-linux-amd64.tar.gz(etcd程序命令及证书) 到 /opt/k8s 目录中,启动etcd服务
cd /opt/k8s/
tar zxvf etcd-v3.4.9-linux-amd64.tar.gz
ls etcd-v3.4.9-linux-amd64
#解压上传的etcd包,内容为3个.md文件一个目录,一个etcd和一个etcdctl启动控制脚本
mkdir -p /opt/etcd/{cfg,bin,ssl}
#创建用于存放etcd配置文件,命令文件,证书的目录
cd /opt/k8s/etcd-v3.4.9-linux-amd64
#进入解压的etcd包中
mv etcd etcdctl /opt/etcd/bin/
#将etcd启动和etcdctl控制脚本移动到创建的用于存放etcd命令文件的bin目录下
cd /opt/k8s/etcd-cert
#进入创建etcd证书的目录
cp ./*.pem /opt/etcd/ssl
#将本目录下所有证书全部拷贝一份到创建的用于存放etcd证书的路径ssl上
cd /opt/k8s
./etcd.sh etcd01 192.168.30.11 etcd02=https://192.168.30.12:2380,etcd03=https://192.168.30.13:2380
#进入存放etcd.sh部署etcd集群的脚本目录执行etcd.sh脚本 后面跟三个etcd集群的ip注意格式,进入卡住状态等待其他节点加入,这里需要三台etcd服务同时启动,如果只启动其中一台后,服务会卡在那里,直到集群中所有etcd节点都已启动,先操作不然不会生成system管理和配置文件,重新开启一个shell查看etcd状态
#另一个窗口执行
ps -ef | grep etcd
#查看etcd集群状态是否为自己的三个etcd ip
scp -r /opt/etcd/ [email protected]:/opt/
scp -r /opt/etcd/ [email protected]:/opt/
scp /usr/lib/systemd/system/etcd.service [email protected]:/usr/lib/systemd/system/
scp /usr/lib/systemd/system/etcd.service [email protected]:/usr/lib/systemd/system/
#把etcd相关证书文件、命令文件和服务管理文件全部拷贝到另外两个etcd集群节点
#node1节点执行
vim /opt/etcd/cfg/etcd
#修改scp过来的etcd配置文件
#[Member]
ETCD_NAME="etcd02" #修改为etcd02
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://192.168.30.12:2380" #修改为node1的ip地址
ETCD_LISTEN_CLIENT_URLS="https://192.168.30.12:2379" #修改为node1的ip地址
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.30.12:2380" #修改为node1的ip地址
ETCD_ADVERTISE_CLIENT_URLS="https://192.168.30.12:2379" #修改为node1的ip地址
ETCD_INITIAL_CLUSTER="etcd01=https://192.168.10.80:2380,etcd02=https://192.168.10.18:2380,etcd03=https://192.168.10.19:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
#node2节点执行
vim /opt/etcd/cfg/etcd
#修改scp过来的etcd配置文件
#[Member]
ETCD_NAME="etcd03" #修改为etcd03
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://192.168.30.13:2380" #修改为node1的ip地址
ETCD_LISTEN_CLIENT_URLS="https://192.168.30.13:2379" #修改为node1的ip地址
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.30.13:2380" #修改为node1的ip地址
ETCD_ADVERTISE_CLIENT_URLS="https://192.168.30.13:2379" #修改为node1的ip地址
ETCD_INITIAL_CLUSTER="etcd01=https://192.168.10.80:2380,etcd02=https://192.168.10.18:2380,etcd03=https://192.168.10.19:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
#master节点执行
cd /opt/k8s
./etcd.sh etcd01 192.168.30.11 etcd02=https://192.168.30.12:2380,etcd03=https://192.168.30.13:2380
#重新启动etcd集群
#node1 node2执行
systemctl enable --now etcd
#设置开机启动并立即启动etcd,然后回到master上查看是否成功。不是一直前台运行状态即成功
#master执行:
ETCDCTL_API=3 /opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem --cert=/opt/etcd/ssl/server.pem --key=/opt/etcd/ssl/server-key.pem --endpoints="https://192.168.30.11:2379,https://192.168.30.12:2379,https://192.168.30.13:2379" endpoint health --write-out=table
#检查集群监控状态,health全部未true即可
ETCDCTL_API=3 /opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem --cert=/opt/etcd/ssl/server.pem --key=/opt/etcd/ssl/server-key.pem --endpoints="https://192.168.30.11:2379,https://192.168.30.12:2379,https://192.168.30.13:2379" endpoint status --write-out=table
#检查集群状态,有一个is leader为true即可
ETCDCTL_API=3 /opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.m --key=/opt/etcd/ssl/server-key.pem --endpoints="https://192.168.30.13:2379" --write-out=table member list
##查看etcd集群成员列表
5、master部署组件
//在 master01 节点上操作
#上传 master.zip(master组件) 和 k8s-cert.sh(证书) 到 /opt/k8s 目录中,解压 master.zip 压缩包
cd /opt/k8s/
unzip master.zip
cd master
chmod +x *.sh
mv * /opt/k8s
#解压master组件包,里面有master的4个组件脚本,添加权限移动到/opt/k8s文件夹中
mkdir -p /opt/kubernetes/{bin,cfg,ssl,logs}
#创建kubernetes工作目录
mkdir /opt/k8s/k8s-cert
#创建k8s的证书存放路径
mv /opt/k8s/k8s-cert.sh /opt/k8s/k8s-cert
#将k8s证书移动到创建的k8s的证书存放路径
cd /opt/k8s/k8s-cert/
vim /opt/k8s/k8s-cert/k8s-cert.sh
#修改脚本中的ip56-60行顺序是第一个为master、第二个为master高可用ip、第三个为master虚拟ip、第四load balancer01(master)第五为load balancer01(backup)。第四第五可以删除。单节点master不用,若后面需要做集群需要提前规划好ip
chmod +x k8s-cert.sh
./k8s-cert.sh
#生成CA证书、相关组件的证书和私钥
ls *pem
#显示生成的证书等一共8个.pem结尾
cp ca*pem apiserver*pem /opt/kubernetes/ssl/
#将ca证书和apiserver证书拷贝到创建的存放证书的ssl/目录下
cd /opt/k8s/
tar zxvf kubernetes-server-linux-amd64.tar.gz
#上传 kubernetes-server-linux-amd64.tar.gz 到 /opt/k8s/ 目录中,解压 kubernetes 压缩包
cd /opt/k8s/kubernetes/server/bin
#进入解压后的k8s的bin目录中将4个组件拷贝到创建的k8s存放bin文件的路径下
cp kube-apiserver kubectl kube-controller-manager kube-scheduler /opt/kubernetes/bin/
cp /opt/kubernetes/bin/* /usr/local/bin/
#将脚本程序存放到 /usr/local/bin下可以全局使用4个命令
cd /opt/k8s/
vim token.sh
[脚本内容]
#!/bin/bash
#获取随机数前16个字节内容,以十六进制格式输出,并删除其中空格
BOOTSTRAP_TOKEN=$(head -c 16 /dev/urandom | od -An -t x | tr -d ' ')
#生成 token.csv 文件,按照 Token序列号,用户名,UID,用户组 的格式生成
cat > /opt/kubernetes/cfg/token.csv <
6、 部署 Worker Node 组件
#node1执行
mkdir -p /opt/kubernetes/{bin,cfg,ssl,logs}
#创建kubernetes工作目录
cd /opt/
unzip node.zip
#上传 node.zip 到 /opt 目录中,解压 node.zip 压缩包,获得kubelet.sh、proxy.shchmod +x kubelet.sh proxy.sh
#master执行
cd /opt/k8s/kubernetes/server/bin
scp kubelet kube-proxy [email protected]:/opt/kubernetes/bin/
#把 kubelet、kube-proxy 节点的组件拷贝到 node1 节点
mkdir /opt/k8s/kubeconfig
cd /opt/k8s/kubeconfig
chmod +x kubeconfig.sh
vim kubeconfig.sh
./kubeconfig.sh 192.168.30.11 /opt/k8s/k8s-cert/
#上传kubeconfig.sh文件到/opt/k8s/kubeconfig目录中,生成kubelet初次加入集群引导kubeconfig文件和kube-proxy.kubeconfig文件
scp bootstrap.kubeconfig kube-proxy.kubeconfig [email protected]:/opt/kubernetes/cfg/
#把配置文件 bootstrap.kubeconfig、kube-proxy.kubeconfig 2个授权文件拷贝到 node1 节点
kubectl create clusterrolebinding kubelet-bootstrap --clusterrole=system:node-bootstrapper --user=kubelet-bootstrap
#RBAC授权,使用户 kubelet-bootstrap 能够有权限发起 CSR 请求证书
kubectl create clusterrolebinding cluster-system-anonymous --clusterrole=cluster-admin --user=system:anonymous
#若执行失败,可先给kubectl绑定默认cluster-admin管理员集群角色,授权集群操作权限
##node1节点执行
cd /opt/
./kubelet.sh 192.168.30.12
ps aux | grep kubelet
#node1节点执行kubelet安装脚步,注意要写node1节点的ip地址,查看kubelet服务是否正常运行
#在 master01 节点上操作,通过 CSR 请求
kubectl get csr
#可以查看有谁发起请求Pending 表示等待集群给该节点签发证书,查看的内容如下
NAME AGE SIGNERNAME REQUESTOR CONDITION
node-csr-saZodXI7_rtwU6VJGMB1UKPx8sHUsAonx4l1BKJRXOo 53m kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Pending
kubectl certificate approve node-csr-saZodXI7_rtwU6VJGMB1UKPx8sHUsAonx4l1BKJRXOo
#执行命令授权csr请求并签发证书
kubectl get csr
#再次查看请求的csr状态Approved,Issued 表示已授权 CSR 请求并签发证书
kubectl get node
#查看节点,状态为NotReady 由于网络插件还没部署
NAME STATUS ROLES AGE VERSION
192.168.30.12 NotReady 108s v1.20.11



![]()
7、 node节点部署flannel网络插件
K8S 中 Pod 网络通信:
●Pod 内容器与容器之间的通信
在同一个 Pod 内的容器(Pod 内的容器是不会跨宿主机的)共享同一个网络命名空间,相当于它们在同一台机器上一样,可以用 localhost 地址访问彼此的端口。
●同一个 Node 内 Pod 之间的通信
每个 Pod 都有一个真实的全局 IP 地址,同一个 Node 内的不同 Pod 之间可以直接采用对方 Pod 的 IP 地址进行通信,Pod1 与 Pod2 都是通过 Veth 连接到同一个 docker0/cni0 网桥,网段相同,所以它们之间可以直接通信。
●不同 Node 上 Pod 之间的通信
Pod 地址与 docker0 在同一网段,docker0 网段与宿主机网卡是两个不同的网段,且不同 Node 之间的通信只能通过宿主机的物理网卡进行。
要想实现不同 Node 上 Pod 之间的通信,就必须想办法通过主机的物理网卡 IP 地址进行寻址和通信。因此要满足两个条件:Pod 的 IP 不能冲突;将 Pod 的 IP 和所在的 Node 的 IP 关联起来,通过这个关联让不同 Node 上 Pod 之间直接通过内网 IP 地址通信。
Overlay Network:
叠加网络,在二层或者三层基础网络上叠加的一种虚拟网络技术模式,该网络中的主机通过虚拟链路隧道连接起来。
通过Overlay技术(可以理解成隧道技术),在原始报文外再包一层四层协议(UDP协议),通过主机网络进行路由转发。这种方式性能有一定损耗,主要体现在对原始报文的修改。目前Overlay主要采用VXLAN。
VXLAN:
将源数据包封装到UDP中,并使用基础网络的IP/MAC作为外层报文头进行封装,然后在以太网上传输,到达目的地后由隧道端点解封装并将数据发送给目标地址。
Flannel:
Flannel 的功能是让集群中的不同节点主机创建的 Docker 容器都具有全集群唯一的虚拟 IP 地址。
Flannel 是 Overlay 网络的一种,也是将 TCP 源数据包封装在另一种网络包里面进行路由转发和通信,目前支持 UDP、VXLAN、Host-gw 3种数据转发方式。
#Flannel UDP 模式的工作原理:
数据从主机 A 上 Pod 的源容器中发出后,经由所在主机的 docker0/cni0 网络接口转发到 flannel0 接口,flanneld 服务监听在 flannel0 虚拟网卡的另外一端。
Flannel 通过 Etcd 服务维护了一张节点间的路由表。源主机 A 的 flanneld 服务将原本的数据内容封装到 UDP 报文中, 根据自己的路由表通过物理网卡投递给目的节点主机 B 的 flanneld 服务,数据到达以后被解包,然后直接进入目的节点的 flannel0 接口, 之后被转发到目的主机的 docker0/cni0 网桥,最后就像本机容器通信一样由 docker0/cni0 转发到目标容器。
#ETCD 之 Flannel 提供说明:
存储管理Flannel可分配的IP地址段资源
监控 ETCD 中每个 Pod 的实际地址,并在内存中建立维护 Pod 节点路由表
由于 UDP 模式是在用户态做转发,会多一次报文隧道封装,因此性能上会比在内核态做转发的 VXLAN 模式差。
#VXLAN 模式:
VXLAN 模式使用比较简单,flannel 会在各节点生成一个 flannel.1 的 VXLAN 网卡(VTEP设备,负责 VXLAN 封装和解封装)。
VXLAN 模式下封包与解包的工作是由内核进行的。flannel 不转发数据,仅动态设置 ARP 表和 MAC 表项。
UDP 模式的 flannel0 网卡是三层转发,使用 flannel0 时在物理网络之上构建三层网络,属于 ip in udp ;VXLAN 模式是二层实现,overlay 是数据帧,属于 mac in udp 。
#Flannel VXLAN 模式跨主机的工作原理:
1、数据帧从主机 A 上 Pod 的源容器中发出后,经由所在主机的 docker0/cni0 网络接口转发到 flannel.1 接口
2、flannel.1 收到数据帧后添加 VXLAN 头部,封装在 UDP 报文中
3、主机 A 通过物理网卡发送封包到主机 B 的物理网卡中
4、主机 B 的物理网卡再通过 VXLAN 默认端口 4789 转发到 flannel.1 接口进行解封装
5、解封装以后,内核将数据帧发送到 cni0,最后由 cni0 发送到桥接到此接口的容器 B 中。
#node1节点操作
#上传 cni-plugins-linux-amd64-v0.8.6.tgz 和 flannel.tar 到 /opt 目录中
cd /opt/
docker load -i flannel.tar
mkdir /opt/cni/bin -p
tar zxvf cni-plugins-linux-amd64-v0.8.6.tgz -C /opt/cni/bin
#master节点操作
#上传 kube-flannel.yml 文件到 /opt/k8s 目录中,部署 CNI 网络
cd /opt/k8s
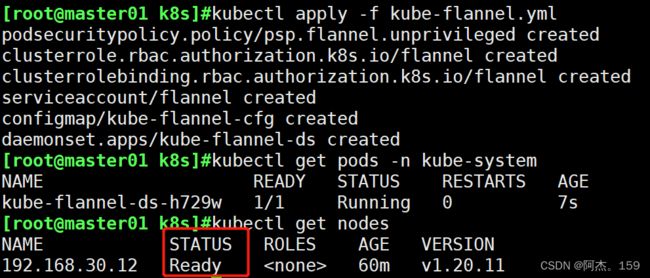
kubectl apply -f kube-flannel.yml
#加载上传的flannel的yml文件部署 CNI 网络
kubectl get pods -n kube-system
#用于在Kubernetes集群中获取kube-system命名空间中所有Pod的状态信息
NAME READY STATUS RESTARTS AGE
kube-flannel-ds-hjtc7 1/1 Running 0 7s
#查看节点状态为ready正常
kubectl get nodes
NAME STATUS ROLES AGE VERSION
192.168.30.12 Ready 81m v1.20.11