【论文阅读】LLM-to-LM Interpreter for Enhanced Text-Attributed Graph Representation Learning
文章目录
- 0、基本信息
- 1、研究动机
- 2、创新点
- 3、准备
-
- 3.1、文本属性图
- 3.2、语言模型用于文本分类
- 3.3、大语言模型和提示
- 3.4、结点分类
- 4、方法论
-
- 4.1、生成基于LLM的预测和解释
- 4.2、LM解释器的微调与节点特征提取
-
- 4.2.1、原始文本和特征解释
- 4.2.2、排序后的预测特征
- 4.3、GNN在语义丰富的特征上训练
- 4.4、理论分析
- 5、实验
-
- 5.1、数据集
- 5.2、主要结果
- 5.3、消融实验
- 6、结论
-
- 6.1、TAG未来的前景
- 6.2、**局限性和今后的工作**
0、基本信息
- 会议:2024-ICLR
- 作者:Xiaoxin He, Xavier Bresson, Thomas Laurent
- 文章链接:Harnessing Explanations: LLM-to-LM Interpreter for Enhanced Text-Attributed Graph Representation Learning
- 代码链接:Harnessing Explanations: LLM-to-LM Interpreter for Enhanced Text-Attributed Graph Representation Learning
1、研究动机
文本属性图(TAG)上的表征学习成为近几年一个重要的研究课题。现有的文本属性图表征学习方法,将每个结点的文本属性编码为浅层或人工制作的特征,例如skip-gram或bag-of-words方法,然后将得到的结点特征作为GNN的输入。然而,这些浅层的文本嵌入难以捕获的复杂的语义特征。
基于LM方法的文本属性图学习,旨在设计更好的LM方法来更好的捕获TAG中文本的上下文和细微差别。首先,对预训练的LMs进行微调,生成特定TAG任务的文本嵌入。但是,这类方法需要复杂的设计与大量的计算资源。此外,现有的工作大多数依赖相对较小的LMs,比如BERT,DeBERTa,因此缺乏像大语言模型强大的推理能力。
尽管大语言模型的出现彻底改变了自然语言领域,增强了处理各种各样自然语言处理任务,但是他们在文本属性图上的应用还未探索,本文的工作就是探索LLM在文本属性图上的潜力。
本文关键的思想是,解释作为特征。通过提示语言模型去解释他的预测,我们提取相关先验知识和推理步骤,使这些信息能够被较小的模型处理,类似于人类专家如何使用解释来传达见解。
文本属性图(TAGs)——节点通常表示文本实体,而边表示这些实体之间的关系。
Bag of Words——对于给定的文本,不考虑词序、语法的情况下,删除像the,and这样的停用词和文本中的低频词,根据剩下文本的词频构建词频向量。局限性——它忽略了语法和语义结构,可能导致在某些情况下无法准确地表示文本内容,无法捕捉到所有的重要信息。
Skip-gram基本思想——其基本假设是,如果两个词在上下文中有相似的用法,那么它们的向量表示也应该是相似的。
2、创新点
本文提出LMaaS-compatible方法——利用大语言模型去增强文本属性图上的表征学习。
- 首先,从LLM提取解释信息;
- 其次,使用LLM-to-LM解释器将文本解释翻译为结点特征向量表示;
- 最后,将特征向量用于处理下游任务的GNNs;
整体模型架构如虚线框所示

3、准备
3.1、文本属性图
一个文本属性图可以被表示为 G = ( V , A , { s n } n ∈ V ) \mathcal{G}=(\mathcal{V},A,\{s_{n}\}_{n\in\mathcal{V}}) G=(V,A,{sn}n∈V), V \mathcal{V} V表示具有 N N N个结点的集合, A ∈ R N × N A\in\mathbb{R}^{N\times N} A∈RN×N是邻接矩阵, s n ∈ D L n s_n\in \mathcal{D}^{L_n} sn∈DLn是与结点 n ∈ V n\in\mathcal{V} n∈V相关的文本序列, D \mathcal{D} D是单词或tokens字典, L n L_n Ln是序列长度。本文研究结点分类任务,给定一些被标记的结点 L ⊂ V \mathcal{L}\subset \mathcal{V} L⊂V,预测剩余未被标记的结点 U = V ∖ L \mathcal{U}=\mathcal{V}\setminus \mathcal{L} U=V∖L
3.2、语言模型用于文本分类
在TAG上下文中,可以使用LM来编码与每个节点相关的文本属性,并学习捕获文本的语义含义的表示。
s n ∈ D L n s_n\in \mathcal{D}^{L_n} sn∈DLn定义为结点n的文本属性,LM是一个预训练的网络,比如BERT或DeBERTa。结点 n n n的文本属性可以通LM来编码:
h n = L M ( s n ) ∈ R d h_n=\mathrm{LM}(s_n)\in \mathbb{R}^d hn=LM(sn)∈Rd
其中, h n h_n hn是LM的输出,d是输出向量的维度。目标是学习一个函数,将编码的文本属性映射到相应的节点标签。
3.3、大语言模型和提示
M \mathcal{M} M定义为一个LLM,tokens序列 x = ( x 1 , x 2 , . . . , x q ) x=(x_1,x_2,...,x_q) x=(x1,x2,...,xq)作为输入,tokens序列 y = ( y 1 , y 2 , . . . , y q ) y=(y_1,y_2,...,y_q) y=(y1,y2,...,yq)作为输出。模型 M \mathcal{M} M通常被训练优化条件概率分布 p ( y ∣ x ) p(y| x) p(y∣x),其在给定 x x x的情况下为每个可能的输出序列 y y y分配概率。
为了在输入序列 x x x中包含提示符 p p p,我们可以将它们连接成一个新的序列 x = ( p , x 1 , x 2 , . . . , x q ) x =(p,x_1,x_2,...,x_q) x=(p,x1,x2,...,xq)。然后,我们使用 x ^ \hat{x} x^来计算条件概率分布 p ( y ∣ x ^ ) p(y|\hat{x}) p(y∣x^)。在形式上,输出序列y在给定x的情况下的概率为:
p ( y ∣ x ^ ) = ∏ i = 1 m p ( y i ∣ y < i , x ^ ) p(y|\hat{x})=\prod_{i=1}^{m}p(y_{i}|y_{
其中, y < i y_{
3.4、结点分类
节点分类中,任务是根据其属性和与其他节点的连接来标记图中的每个节点。GNN通过聚合来自节点邻居的信息来操作,然后基于聚合的信息更新节点的表示。GNN的第k层为:
h i k = f k ( h i k − 1 , AGG ( { h j k − 1 : j ∈ N i } ) ) ∈ R d h_i^k=f^k(h_i^{k-1},\text{AGG}(\{h_j^{k-1}:j\in\mathcal{N}_i\}))\in\mathbb{R}^d hik=fk(hik−1,AGG({hjk−1:j∈Ni}))∈Rd
其中, h i k ∈ R d h_i^k\in \mathcal{R}^d hik∈Rd是第 k k k层结点 i i i的表征, N ⊆ V \mathcal{N}\subseteq \mathcal{V} N⊆V是结点 i i i的邻居集合,函数 f k f^k fk是根据节点的前一层表示和来自其邻居的聚合信息来更新节点的表示的函数。 A G G \mathrm{AGG} AGG聚合节点邻居表征和自身表征。最终的表示输入到一个全连接层和一个softmax函数中进行类别预测。
4、方法论
4.1、生成基于LLM的预测和解释
本文提出的方法是指导LLM做出多个预测,并为其决策提供解释。有效地提取其推理能力和常识的文本格式。然后使用LLM-to-LM解释器处理这些基于文本的输出,转化为嵌入的想来给你,为下游GNN创建节点特征。
为此,对于每个节点 i ∈ V i \in \mathcal{V} i∈V,我们生成一个提示,其中包括论文的标题和摘要,还有一个关于论文主题的问题。提示的问题具体内容根据任务和数据集制定,如表7所示。提示词的一般结构如下:

LLM返回排序后的预测结果的列表和每篇论文的文本解释:

这些预测和解释作为下游LM和GNN模型的补充文本属性。

4.2、LM解释器的微调与节点特征提取
4.2.1、原始文本和特征解释
首先,将原始文本(标题和摘要)和LLM的解释转换成适合下游GNN任务需求的固定长度节点特征。
采用的方法是微调一个较小的LM,充当LLM的文本解释的“解释器”。这一步骤背后的基本原理是,LLM和LM都具有明显的优势:LLM具有更强大的能力和更多的知识,但灵活性较低,而LM尽管能力不强大,但可以根据特定任务进行微调。因此,LM用于为GNN解释LLM的输出,文本解释充当有效的通信的中间媒介。然后,对LM进行微调,使其能够从解释中提取最有价值和任务相关的特征。
具体来说,首先对预训练的LM进行如下微调:让 L M o r i g \mathrm{LM_{orig}} LMorig和 l M e x p l \mathrm{lM_{expl}} lMexpl分别作为原始文本序列 s o r i g s^{orig} sorig和解释文本序列 s e x p l s^{expl} sexpl的输入。为每个源获取文本嵌入:
h o r i g = L M o r i g ( s o r i g ) ∈ R N × d , h e x p l = L M e x p l ( s e x p l ) ∈ R N × d h_{\mathrm{orig}}=\mathrm{LM}_{\mathrm{orig}}(s^{\mathrm{orig}})\in\mathbb{R}^{N\times d},\quad h_{\mathrm{expl}}=\mathrm{LM}_{\mathrm{expl}}(s^{\mathrm{expl}})\in\mathbb{R}^{N\times d} horig=LMorig(sorig)∈RN×d,hexpl=LMexpl(sexpl)∈RN×d
然后,上述结果作为MLP输入,以获得表示LM对每个节点的预测的 N × C N \times C N×C维预测矩阵:
y orig = MLP orig ( h orig ) ∈ R N × C , y expl = MLP expl ( h expl ) ∈ R N × C y_{\text{orig}}=\text{MLP}_{\text{orig}}(h_{\text{orig}})\in\mathbb{R}^{N\times C},\quad y_{\text{expl}}=\text{MLP}_{\text{expl}}(h_{\text{expl}})\in\mathbb{R}^{N\times C} yorig=MLPorig(horig)∈RN×C,yexpl=MLPexpl(hexpl)∈RN×C
使用交叉熵损失函数来微调LM和MLP。最后,来自 h o r i g h_{orig} horig和 h e x p l h_{expl} hexpl两个源的文本嵌入作为特征来训练下游GNN。
4.2.2、排序后的预测特征
除了解释,LLM还为每个节点提供了top-k排名的预测列表,这增加了有价值的信息。为了结合该知识,节点 i i i的top-k个预测首先被独热编码为向量 p i , 1 , . . . , p i , k ∈ R C p_{i,1},...,p_{i,k}\in \mathbb{R}^C pi,1,...,pi,k∈RC。这些向量随后被连接成 k C kC kC维向量,随后进行线性变换以产生长度为 d P d_P dP的固定大小的向量。这个过程产生了所有结点的一个预测特征矩阵 h p r e d ∈ R N × d P h_{pred} \in \mathbb{R}^{N \times d_P} hpred∈RN×dP。
综上所述,特征定义为 h T A P E = { h o r i g , h e x p l , h p r e d } h_{TAPE}=\{h_{orig},h_{expl},h_{pred}\} hTAPE={horig,hexpl,hpred},其中“TAPE”代表每个节点的标题、摘要、预测和解释。并且,要求这些特征在下游GNN训练期间保持冻结,确保LM和LLM不参与GNN训练过程。
4.3、GNN在语义丰富的特征上训练
最后一步是使用 h T A P E h_{TAPE} hTAPE特征训练GNN,目标是在不增加GNN的内存需求或对其架构进行任何更改的情况下实现。
本文使用集成的方法,作为一个简单而有效结合特征的方式。具体来说,我们分别在特征 h o r i g h_{orig} horig、 h e x p l h_{expl} hexpl和 h p r e d h_{pred} hpred上独立地训练GNN模型 f o r i g f_{orig} forig、 f e x p l f_{expl} fexpl和 f p r e d f_{pred} fpred,预测真实节点标签:
y ^ o r i g / e x p l / p r e d = f o r i g / e x p l / p r e d ( h o r i g / e x p l / p r e d , A ) ∈ R N × C \hat{y}_{\mathrm{orig/expl/pred}}=f_{\mathrm{orig/expl/pred}}(h_{\mathrm{orig/expl/pred}},A)\in\mathbb{R}^{N\times C} y^orig/expl/pred=forig/expl/pred(horig/expl/pred,A)∈RN×C
然后,我们对这些预测取平均值:
y ^ = m e a n ( y ^ o r i g , y ^ e x p l , y ^ p r e d ) ∈ R N × C \hat{y}=\mathrm{mean}(\hat{y}_{\mathrm{orig}},\hat{y}_{\mathrm{expl}},\hat{y}_{\mathrm{pred}})\in\mathbb{R}^{N\times C} y^=mean(y^orig,y^expl,y^pred)∈RN×C
如表3所示,三个模型中的每一个都表现良好,这验证了简单平均的有效性。这种策略使我们能够从不同的输入源中捕获互补信息,最终提高整体模型的性能。

4.4、理论分析
证明——LLM生成的解释对于较小的LM来说可能是有价值的功能
具体地说,如果解释 E E E在描述LLM的推理时具有保真度,那么它们是有帮助的;并且LLM是非冗余的,利用了较小LM不使用的信息。
设 E E E是由LLM生成的文本解释; Z L Z_L ZL和 Z Z Z分别是来自LLM和较小LM的嵌入, y y y是目标, H ( ⋅ ∣ ⋅ ) H(·|·) H(⋅∣⋅)是条件熵。
理论:给定以下条件:1)保真度: E E E是 Z L Z_L ZL的良好代理,使得 H ( Z l ∣ E ) = ϵ H(Z_l| E)=\epsilon H(Zl∣E)=ϵ,且 ϵ > 0 \epsilon >0 ϵ>0;非冗余: Z L Z_L ZL包含不存在于 Z Z Z中的信息,表示为 H ( y ∣ Z , Z L ) = H ( y ∣ Z ) − ϵ H(y| Z,Z_L)= H(y| Z)-\epsilon H(y∣Z,ZL)=H(y∣Z)−ϵ′,其中 ϵ \epsilon ϵ′> ϵ \epsilon ϵ,则 H ( y ∣ Z , E ) < H ( y ∣ Z ) H(y| Z,E)< H(y| Z) H(y∣Z,E)<H(y∣Z)。
5、实验
5.1、数据集
五个TAG数据集:Cora ,PubMed ,ogbn-arxiv,ogbn-products 和tape-arxiv 。鉴于这些数据集的流行,其TAG版本将公开发布,以供重复性和新的研究项目使用。
5.2、主要结果
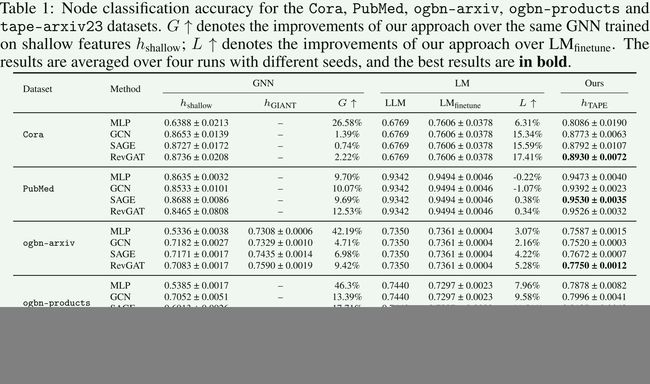
对比模型,GCN,GraphSAGE和RevGAT,以及MLP。
三种类型的节点特征:1)浅特征,表示为 h s h a l l o w h_{shallow} hshallow,2)GIANT特征 h G I A N T h_{GIANT} hGIANT,以及3)我们提出的特征 h T A P E h_{TAPE} hTAPE,包括 h o r i g h_{orig} horig、 h e x p l h_{expl} hexpl和 h p r e d h_pred hpred。
对于基于LM的方法,我们研究了两种方法:1)在标记节点上微调DeBERTa,表示为LMfinetune,2)使用与我们的方法相同的提示的zero-shot ChatGPT(gpt-3.5-turbo),表示为LLM。
我们提出的方法不仅超越了纯LM和浅嵌入方法,而且超越了ogbn-arxiv数据集上基于LM的流水线,实现了准确性和训练时间之间的上级平衡,如图2所示。
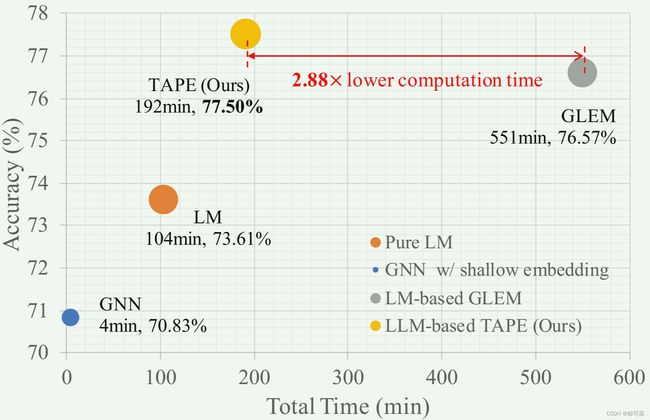
具体来说,我们的方法在使用相同的LM和GNN模型时,实现了比SOTA GLEM 方法更高的准确性。此外,我们的方法只需要2.88倍的计算时间。这些效率的提高归功于我们对LM和GNN的解耦训练方法,避免了迭代方法中使用GLEM。此外,与迭代方法不同,我们的模型允许并行训练 L M o r i g LM_{orig} LMorig和 L M e x p l LM_{expl} LMexpl,同时执行时进一步减少了整体训练时间。
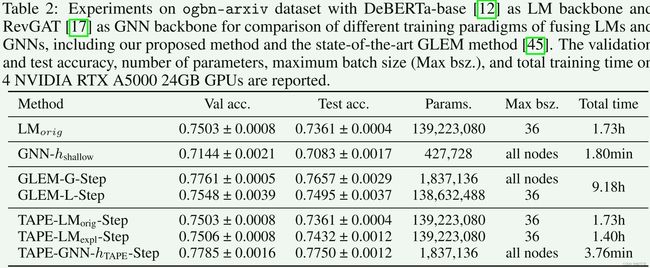
5.3、消融实验
对ogbn-arxiv数据集进行了消融实验研究,以评估我们框架内每个模块的相关性。表-2和表-3。
表明,这种改进可以归因于LLM生成的解释的简洁和集中的性质,以及他们的推理能力和对外部知识的利用。
6、结论
6.1、TAG未来的前景
鉴于整合文本和关系的重要性日益增加,再加上LLM的出现,预计TAG任务将在未来几年吸引更多的关注。LLM和GNN的融合为研究和工业应用提供了新的机会。作为这一领域的开创性工作,相信我们的贡献将成为这一领域未来研究的有力基线
6.2、局限性和今后的工作
我们的方法的一个固有限制在于需要为每个数据集定制提示。目前,我们依赖于手工制作的提示,这可能不是每个数据集的节点分类任务的最佳选择。这些提示的有效性可能会根据数据集的特定特征和手头的特定任务而波动。未来的工作可以集中在自动化的提示生成过程中,探索替代提示设计,并解决动态和不断发展的TAG的挑战。