Gold-YOLO(NeurIPS 2023)论文与代码解析
paper:Gold-YOLO: Efficient Object Detector via Gather-and-Distribute Mechanism
official implementation:https://github.com/huawei-noah/Efficient-Computing/tree/master/Detection/Gold-YOLO
存在的问题
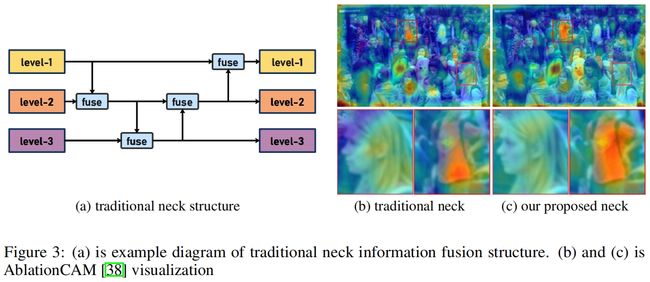
在过去几年里,YOLO系列已经成为了实时目标检测领域最先进以及最常用的方法。许多研究通过修改模型架构、数据增强、设计新的损失函数将baseline提升到了一个更高的水平。但现有的模型仍然存在信息融合的问题,尽管FPN和PANet在一定程度上缓解了该问题。
传统的neck如FPN以及相关变体的结构如图3(a)所示,但是这种信息融合的方法存在一个明显的缺陷:当需要跨层融合信息时(如level-1和level-3),FPN式的结构无法无损的传输信息,这阻碍了YOLO系列更好的进行信息融合。
本文的创新点
针对FPN式结构存在的问题,本文在TopFormer理论的基础上,提出了一种新的聚合-分发(GD)机制,它通过融合多层特征并将全局信息注入到更高层,在YOLO中实现高效的信息交换。这显著增加了neck的信息融合能力,同时没有显著增加延迟。
基于此提出了一个新的模型Gold-YOLO,它提高了多尺度特征融合的能力,并在所有尺度上实现了延迟和精度之间的理想平衡。
此外,本文首次在YOLO系列中实现了MAE-style的预训练,使得YOLO系列可以从无监督预训练中受益。
方法介绍
如图3所示,在FPN的结构中,只能完全融合相邻层的信息,对于其它层的信息,只能间接的“递归”获得。这种传输模式可能导致计算过程中信息的丢失。为了避免这种情况,本文放弃了递归方法,构建了一种新的聚合-分发机制。通过使用一个统一的模块从各层收集和融合信息,然后将其分发到不同的层。
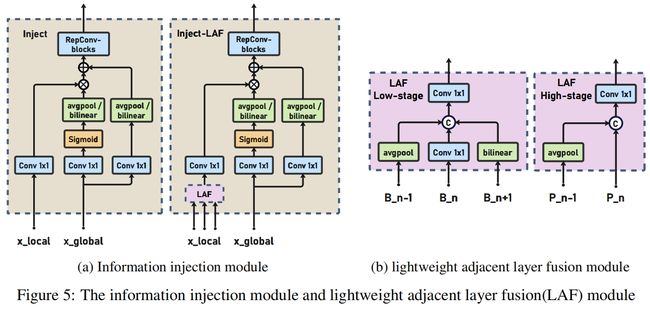
具体实现中,聚合与分发的过程对应三个模块:特征对齐模块(Feature Alignment Module, FAM)、信息融合模块(Information Fusion Module, IFM)、信息注入模块(Information Injection Module, Inject)。完整结构如图2所示
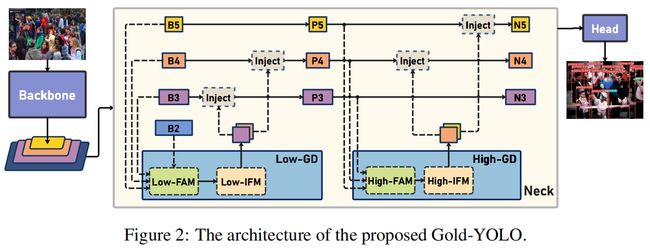
- gather过程包括两步。首先,FAM从不同层收集和对齐特征。然后,IFM通过融合对齐的特征得到全局信息。
- 在获得全局信息后,inject模块将这些信息distribute到每个level中,并使用简单的注意力操作进行注入,从而提高分支的检测能力。
为了增加模型检测不同大小对象的能力,提出了两个分支,low-stage GD和high-stage GD。如图2所示,neck的输入包括backbone提取的特征图B2,B3,B4,B5,其中 \(B_{i}\in \mathbb{R}^{N\times C_{Bi}\times R_{Bi}}\),N是batch size,C是通道数,R=HxW。
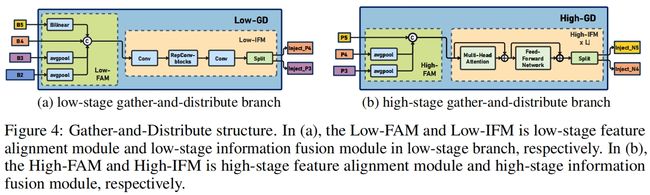
Low GD
结构如图4(a)所示
Low-FAM
在Low-FAM中,用average pooling下采样得到一个统一大小的 \(F_{align}\)。这里选择 \(R_{B4}=\frac{1}{4}R\) 作为目标大小。
Low-IFM
Low-IFM包括多层重参数化卷积Block (RepBlock) 和一个split操作。具体来说,RepBlock取 \(F_{align}\)(\(channel=sum(C_{B2},C_{B3},C_{B4},C_{B5})\))作为输入得到 \(F_{fuse}\)(\(channel=C_{B4}+C_{B5}\)),然后沿通道维度split成 \(F_{inj\_P3}\) 和 \(F_{inj\_P4}\)。如下
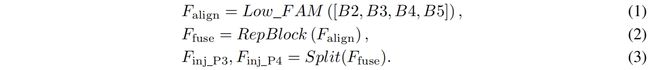
Information injection module
为了更有效的将全局信息注入到不同的层,作者采用注意力机制来融合信息,如图5所示。具体来说,同时输入局部信息(当前层)和全局信息(IFM生成的)并分别记为 \(F_{local}\) 和 \(F_{inj}\),\(F_{inj}\) 通过两个不同的卷积层分别得到 \(F_{global\_embed}\) 和 \(F_{act}\)。\(F_{local}\) 通过卷积得到 \(F_{local\_embed}\)。然后通过注意力计算得到融合特征 \(F_{out}\)。其中 \(F_{local}\) 等于 \(Bi\),具体如下
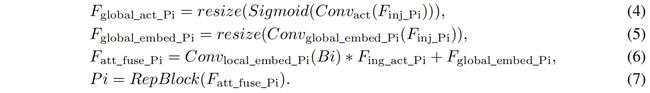
High GD
High-GD融合Low-GD得到的特征 {P3, P4, P5},如图4(b)所示
High-FAM
High-FAM和Low-FAM的操作一样,通过全局平均池化下采样来对齐大小,目标大小为 \(R_{P5}=\frac{1}{8}R\)。
Hign-IFM
High-IFM包括多个transformer block和一个split操作。具体包括三步
- High-FAM的输出 \(F_{align}\) 通过transformer block融合得到 \(F_{fuse}\)
- \(F_{fuse}\) 通过1x1卷积通道降维到 \(sum(C_{P4},C_{P5})\)
-
沿通道进行split操作得到 \(F_{inj\_N4}\) 和 \(F_{inj\_N5}\)
具体如下
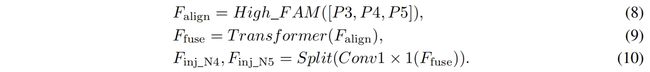
式(8)中的transformer融合模块包括多个堆叠的transformer block,每个block包含一个multi-head attention block、一个ffn、一个residual connection。具体配置和LeViT一样,K,Q的维度设为D(例如16),V的维度为2D(例如32)。考虑到推理速度,替换掉了一些速度不友好的操作,每个卷积的LN换成了BN,所有的GELU激活换成了ReLU。为了增强transformer block中的局部连接,两个1x1卷积中间增加了一层深度卷积。FFN的expansion factor设为2。
Information injection module
这里和Low-GD中的结构一样,其中 \(F_{local}\) 等于 \(Pi\),具体如下

Enhanced cross-layer information flow
为了进一步提升性能,作者借鉴YOLOv6里的PAFPN提出了一个Inject-LAF模块。这个模块是注入模块的增加,其中在注入模块的输入位置新加了一个轻量的相邻层融合模块(lightweight adjacent layer fusion, LAF)。为了实现速度和精度的平衡,设计了两种LAF:low-level LAF和high-level LAF,分别用于低层注入(合并相邻两层的特征)和高层注入(合并相邻一层的特征),具体结构如图5(b)所示。
代码解析
官方的实现是基于YOLOv6的实现,其中n,s的neck是"RepGDNeck",m的neck是"GDNeck",l的neck是"GDNeck2",因为从实验结果看,提升比较明显的事nano和small版本,因此这里只解析一下RepGDNeck的实现。具体实现代码在Efficient-Computing/Detection/Gold-YOLO/gold_yolo/reppan.py中,forward实现如下
def forward(self, input):
(c2, c3, c4, c5) = input # [(16,32,160,160),(16,64,80,80),(16,128,40,40),(16,256,20,20)]
# Low-GD
## use conv fusion global info
low_align_feat = self.low_FAM(input) # (16,480,40,40)
low_fuse_feat = self.low_IFM(low_align_feat) # (16,96,40,40)
low_global_info = low_fuse_feat.split(self.trans_channels[0:2], dim=1) # [(16,64,40,40),(16,32,40,40)]
## inject low-level global info to p4
c5_half = self.reduce_layer_c5(c5) # (16,64,20,20)
p4_adjacent_info = self.LAF_p4([c3, c4, c5_half]) # (16,64,40,40)
p4 = self.Inject_p4(p4_adjacent_info, low_global_info[0]) # (16,64,40,40)
p4 = self.Rep_p4(p4) # (16,64,40,40), 式(7)
## inject low-level global info to p3
p4_half = self.reduce_layer_p4(p4) # (16,32,40,40)
p3_adjacent_info = self.LAF_p3([c2, c3, p4_half]) # (16,32,80,80)
p3 = self.Inject_p3(p3_adjacent_info, low_global_info[1]) # (16,32,80,80)
p3 = self.Rep_p3(p3) # (16,32,80,80)
# High-GD
## use transformer fusion global info
high_align_feat = self.high_FAM([p3, p4, c5]) # (16,352,10,10)
high_fuse_feat = self.high_IFM(high_align_feat) # (16,352,10,10)
high_fuse_feat = self.conv_1x1_n(high_fuse_feat) # (16,192,10,10)
high_global_info = high_fuse_feat.split(self.trans_channels[2:4], dim=1) # [(16,64,10,10),(16,128,10,10)]
## inject low-level global info to n4
n4_adjacent_info = self.LAF_n4(p3, p4_half) # (16,64,40,40)
n4 = self.Inject_n4(n4_adjacent_info, high_global_info[0]) # (16,64,40,40)
n4 = self.Rep_n4(n4) # (16,64,40,40)
## inject low-level global info to n5
n5_adjacent_info = self.LAF_n5(n4, c5_half) # (16,128,20,20)
n5 = self.Inject_n5(n5_adjacent_info, high_global_info[1]) # (16,128,20,20)
n5 = self.Rep_n5(n5) # (16,128,20,20)
outputs = [p3, n4, n5] # [(16,32,80,80),(16,64,40,40),(16,128,20,20)]
return outputs首先是Low-GD,self.low_FAM的实现如下
def forward(self, x):
x_l, x_m, x_s, x_n = x
# [(16,32,160,160),(16,64,80,80),(16,128,40,40),(16,256,20,20)]
B, C, H, W = x_s.shape
output_size = np.array([H, W])
if torch.onnx.is_in_onnx_export():
self.avg_pool = onnx_AdaptiveAvgPool2d
x_l = self.avg_pool(x_l, output_size)
x_m = self.avg_pool(x_m, output_size)
x_n = F.interpolate(x_n, size=(H, W), mode='bilinear', align_corners=False)
out = torch.cat([x_l, x_m, x_s, x_n], 1) # (16,480,40,40)
return outself.low_IFM的实现如下,其中的block是RepVGGBlock
self.low_IFM = nn.Sequential(
Conv(extra_cfg.fusion_in, extra_cfg.embed_dim_p, kernel_size=1, stride=1, padding=0), # 480,96
*[block(extra_cfg.embed_dim_p, extra_cfg.embed_dim_p) for _ in range(extra_cfg.fuse_block_num)], # 3
Conv(extra_cfg.embed_dim_p, sum(extra_cfg.trans_channels[0:2]), kernel_size=1, stride=1, padding=0),
)接着通过split操作得到low_global_info,即inject模块的输入 \(F_{inj\_P3}\) 和 \(F_{inj\_P4}\)。
以上分别对应式(1)~式(3)
接下来是inject模块,self.LAF_p4的实现如下
def forward(self, x):
N, C, H, W = x[1].shape
output_size = (H, W)
if torch.onnx.is_in_onnx_export():
self.downsample = onnx_AdaptiveAvgPool2d
output_size = np.array([H, W])
x0 = self.downsample(x[0], output_size)
x1 = self.cv1(x[1])
x2 = F.interpolate(x[2], size=(H, W), mode='bilinear', align_corners=False)
return self.cv_fuse(torch.cat((x0, x1, x2), dim=1))self.Inject_p4的实现如下
def forward(self, x_l, x_g):
'''
x_g: global features
x_l: local features
'''
B, C, H, W = x_l.shape
g_B, g_C, g_H, g_W = x_g.shape
use_pool = H < g_H
local_feat = self.local_embedding(x_l)
global_act = self.global_act(x_g) # 式(4)
global_feat = self.global_embedding(x_g) # 式(5)
if use_pool:
avg_pool = get_avg_pool()
output_size = np.array([H, W])
sig_act = avg_pool(global_act, output_size)
global_feat = avg_pool(global_feat, output_size)
else:
sig_act = F.interpolate(self.act(global_act), size=(H, W), mode='bilinear', align_corners=False)
global_feat = F.interpolate(global_feat, size=(H, W), mode='bilinear', align_corners=False)
out = local_feat * sig_act + global_feat # 式(6)
return out然后self.Rep_p4对应式(7)。接下来inject to p3和p4的操作是一致的。
接下来是Hign-GD,输入是C5以及Low-GD的输出P3、P4。
self.high_FAM的实现如下
def forward(self, inputs):
B, C, H, W = get_shape(inputs[-1])
H = (H - 1) // self.stride + 1
W = (W - 1) // self.stride + 1
output_size = np.array([H, W])
if not hasattr(self, 'pool'):
self.pool = nn.functional.adaptive_avg_pool2d
if torch.onnx.is_in_onnx_export():
self.pool = onnx_AdaptiveAvgPool2d
out = [self.pool(inp, output_size) for inp in inputs]
return torch.cat(out, dim=1)self.high_IFM采用transformer block,这里具体实现就不贴了。然后是1x1卷积接split操作。上面对应式(8)~式(10)
然后是inject模块,首先self.LAF_n4只融合相邻一层的特征
def forward(self, x1, x2):
if torch.onnx.is_in_onnx_export():
self.pool = onnx_AdaptiveAvgPool2d
else:
self.pool = nn.functional.adaptive_avg_pool2d
N, C, H, W = x2.shape
output_size = np.array([H, W])
x1 = self.pool(x1, output_size)
return torch.cat([x1, x2], 1)接下来的self.Inject_n4和self.Rep_n4与low-GD中的self.Inject_p4和self.Rep_p4是一样的。
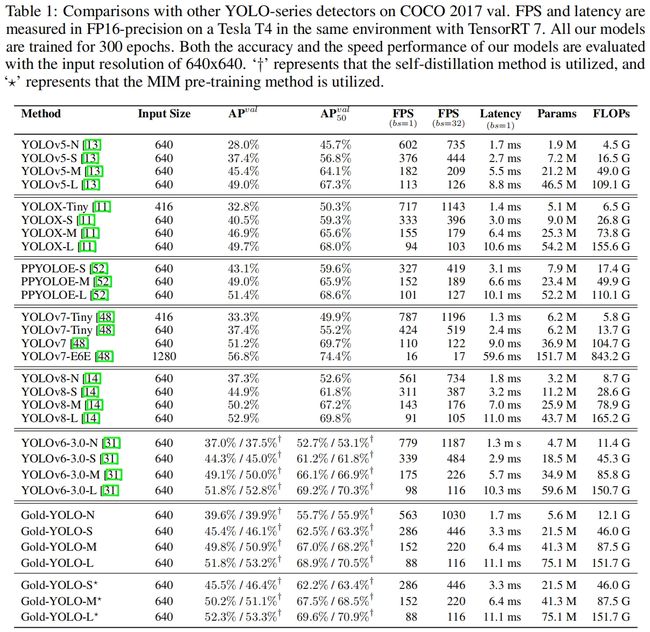
实验结果
GOLD-YOLO和其他YOLO的效果对比如下,可以看出主要提升在nano和small版本上。