python 全量同步和增量同步实践
目录
全量同步
定时增量同步
解析binlog 增量同步
全量同步
如果我们要做整库数据迁移和同步,我们可以先同步库表结构等元数据,再去同步表数据。写两个 for 循环遍历多个数据库里的多个表,每个表使用阿里的 DataX 做单表同步就可以得到全量同步。代码如下:
import os
import subprocess
databases = ["demo"]
database_table_dict = {}
sql = """SELECT table_name FROM information_schema.tables WHERE table_schema = '{}' """
for database in databases:
tables = []
# 数据库ip,用户名,密码
output = subprocess.check_output(
["mysql", "-h", "localhost", "-uroot", "-p123456",
"-P3306", "-e", '{}'.format(sql.format(database))])
ele_arr = output.split()
for ele in ele_arr:
if ele.decode('utf-8') != 'table_name':
tables.append(ele.decode('utf-8'))
database_table_dict.update({database: tables})
for database in database_table_dict:
for table in database_table_dict[database]:
print("当前同步的表是 {}".format(database + "." + table))
os.system(
"python C:\\datax\\bin\\datax.py syncJob.json -p \"-Ddb_name={} -Dtable_name={}\"".format(database, database + '.' + table))syncJob.json 是DataX的任务描述, 的内容如下:
{
"job": {
"setting": {
"speed": {
"channel": 10
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
// 同步所有字段
"column": ["*"],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://ip1:3306/${db_name}"],
"table": ["${table_name}"]
}
],
"username": "xxx",
"password": "xxx"
}
},
"writer": {
"name": "rdbmswriter",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://ip2:3306/${db_name}",
"table": ["${table_name}"]
}
],
"username": "xxx",
"password": "xxx"
}
}
}
]
}
}
定时增量同步
简单的增量同步可以使用定时断点同步,即使用定时任务获取从库的上次备份的最后一条数据,从最大的id处开始定时同步数据,同时多传递一个 id 参数,我们的id是long类型,是有序递增的,如果id 不是有序递增的,如果 create_time 是有序递增的也可以。
import os
import subprocess
for database in database_table_dict:
for table in database_table_dict[database]: #database + "." + table
# 记得修改 数据库主机ip,用户名和密码
output = subprocess.check_output(
["mysql", "-h", "xxx", "-uroot", "-p123456",
"-P3306", "-e", '{}'.format("select id from " + database + "." + table + " order by id desc limit 1")])
output = output.decode('utf-8').strip()
max_id = -1
if not output:
# 执行全量同步
print('没有值')
else:
# 执行增量同步
max_id = int(output.split()[1])
print('max sync id is {}'.format(max_id))
# 传递 max_id
os.system("python C:\\datax\\bin\\datax.py syncJob2.json -p \"-Ddb_name={} -Dtable_name={} -Did={} \"".format(database, database + '.' + table, max_id))syncJob2.json 就是在 syncJob.json 的 reader 基础上多了一个 where 参数。
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"*"
],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://ip1:3306/test"
],
"table": [
"xxx"
]
}
],
"username": "xxx",
"password": "xxx",
"where": "id > ${id}"
}
}在linux 使用 crontab 去定时执行即可。
# 执行 crontab -e 编辑
# 每分钟执行一次
*/1 * * * * python3 /opt/dataxJob3.py >> /opt/crontab_test.log 2>&1解析binlog 增量同步
定时增量同步无法监听到主库里已同步的数据里哪些数据被修改和删除了,所以可能会导致数据不一致。我们可以监听主库的binlog,然后把 insert,update,delete 语句解析出来,到从库重新执行一遍。
我们使用 python 的 pymysqlreplication 库去做,它可以读取 MySQL 的 binlog。它要求数据库开启 binlog,且数据格式为 row。
# C:\ProgramData\MySQL\MySQL Server 8.0\my.ini
binlog-format=Row
# 如果是比较高的 mysql8 版本要加下面两个参数,它会提示你加
# binlog_row_image=full
# binlog_row_metadata=full即使已读取完binlog文件,但该程序还是不会停止,它是持续阻塞的。
#!/usr/bin/env python3
# _*_ coding:utf8 _*_
import traceback
from threading import Thread
from queue import Queue
from time import strptime, mktime, localtime, strftime
from pymysqlreplication import BinLogStreamReader # pip3 install mysql-replication==0.21
from pymysqlreplication.row_event import DeleteRowsEvent, UpdateRowsEvent, WriteRowsEvent
# pip install mysql-replication pymysql ,mysql binlog 的格式是 row
# 从主库读取binlog,然后将event解析,将解析结果放队列中
class BinlogStream(Thread):
def __init__(self,
queue_logs,
master_host, master_port, master_user, master_pswd, # 主库配置
start_time, stop_time, # 开始结束时间,格式:YYYY-mm-dd HH:MM:SS
log_file, log_pos=0, # 开始binlog文件位置
only_schemas=None, only_tables=None # 只监听指定的库和表,格式:['db1','db2']
):
self._Queue = queue_logs
self.connect = {'host': master_host, 'port': master_port, 'user': master_user, 'passwd': master_pswd}
self.log_file, self.log_pos = log_file, log_pos
self.start_time = int(mktime(strptime(start_time, "%Y-%m-%d %H:%M:%S")))
self.stop_time = int(mktime(strptime(stop_time, "%Y-%m-%d %H:%M:%S")))
self.only_schemas, self.only_tables = only_schemas, only_tables
self.only_events = [DeleteRowsEvent, WriteRowsEvent, UpdateRowsEvent]
super(BinlogStream, self).__init__()
def insert(self, event):
table = event.schema + '.' + event.table
for row in event.rows:
ele_list = []
for key in row['values']:
if not isinstance(row['values'][key], (int, float)):
ele_list.append('\'' + str(row['values'][key]) + '\'')
else:
ele_list.append(str(row['values'][key]))
print(f'insert into {table}(' + ','.join(row['values'].keys()) + ') values (' + ','.join(
ele_list) + ');')
self._Queue.put({
"log_pos": event.packet.log_pos,
"log_time": strftime("%Y-%m-%dT%H:%M:%S", localtime(event.timestamp)),
"schema_table": "%s.%s" % (event.schema, event.table),
"table_pk": event.primary_key,
"op_type": "insert",
"values": row.get("values")
})
def update(self, event):
table = event.schema + '.' + event.table
id_list = [column.name for column in event.columns if column.is_primary]
for row in event.rows:
ele_list = []
update_list = []
for key in row['before_values']:
if row['before_values'][key] != row['after_values'][key]:
if not isinstance(row['before_values'][key], (int, float)):
update_list.append(key + '=' + '\'' + str(row['after_values'][key]) + '\'')
else:
update_list.append(key + '=' + str(row['after_values'][key]))
if not id_list:
for key in row['before_values']:
if not isinstance(row['before_values'][key], (int, float)):
ele_list.append(key + '=' + '\'' + str(row['before_values'][key]) + '\'')
else:
ele_list.append(key + '=' + str(row['before_values'][key]))
print(f'update ' + table + ' set ' + ' '.join(update_list) + ' where ' + ' and '.join(ele_list))
else:
for key in id_list:
if not isinstance(row['before_values'][key], (int, float)):
ele_list.append(key + '=' + '\'' + str(row['before_values'][key]) + '\'')
else:
ele_list.append(key + '=' + str(row['before_values'][key]))
print(f'update ' + table + ' set ' + ' '.join(update_list) + ' where ' + ' and '.join(ele_list))
self._Queue.put({
"log_pos": event.packet.log_pos,
"log_time": strftime("%Y-%m-%dT%H:%M:%S", localtime(event.timestamp)),
"schema_table": "%s.%s" % (event.schema, event.table),
"table_pk": event.primary_key,
"op_type": "update",
"before_values": row.get("before_values"),
"after_values": row.get("after_values")
})
def delete(self, event):
table = event.schema + '.' + event.table
id_list = [column.name for column in event.columns if column.is_primary]
for row in event.rows:
ele_list = []
if not id_list:
for key in row['values']:
if not isinstance(row['values'][key], (int, float)):
ele_list.append(key + '=' + '\'' + str(row['values'][key]) + '\'')
else:
ele_list.append(key + '=' + str(row['values'][key]))
else:
for key in id_list:
if not isinstance(row['values'][key], (int, float)):
ele_list.append(key + '=' + '\'' + str(row['values'][key]) + '\'')
else:
ele_list.append(key + '=' + str(row[key]))
print(f"delete from " + table + " where " + ' and '.join(ele_list))
self._Queue.put({
"log_pos": event.packet.log_pos,
"log_time": strftime("%Y-%m-%dT%H:%M:%S", localtime(event.timestamp)),
"schema_table": "%s.%s" % (event.schema, event.table),
"table_pk": event.primary_key,
"op_type": "delete",
"values": row.get("values")
})
def run(self):
try:
stream = BinLogStreamReader(connection_settings=self.connect, server_id=999, only_events=self.only_events,
log_file=self.log_file, log_pos=self.log_pos, only_schemas=self.only_schemas,
only_tables=self.only_tables, blocking=True)
for event in stream:
if event.timestamp < self.start_time:
continue
elif event.timestamp > self.stop_time:
break
# event.dump()
if isinstance(event, UpdateRowsEvent):
self.update(event)
elif isinstance(event, WriteRowsEvent):
self.insert(event)
elif isinstance(event, DeleteRowsEvent):
self.delete(event)
self._Queue.put("PutEnd.")
except Exception :
traceback.print_exc()
# 读取队列中解析后的日志,然后对日志进行应用
class ReadBinlog(Thread):
def __init__(self, queue_logs):
self._Queue = queue_logs
super(ReadBinlog, self).__init__()
def app(self, log):
print(log)
# pass
def run(self):
while True:
log = self._Queue.get()
if log == "PutEnd.":
break
self.app(log)
if __name__ == '__main__':
master_host = "127.0.0.1"
master_port = 3306
master_user = "root"
master_pswd = "123456"
start_time = "2020-11-06 15:00:00"
stop_time = "2024-11-06 17:00:00"
log_file = "mysql-bin.000115"
log_pos = 0
only_schemas = None
only_tables = None
queue_logs = Queue(maxsize=10000)
BS = BinlogStream(queue_logs, master_host, master_port, master_user, master_pswd, start_time, stop_time, log_file,
log_pos, only_schemas, only_tables)
RB = ReadBinlog(queue_logs)
BS.start()
RB.start()
BS.join()
RB.join()
binlog 解析成功。我们可以解析到10 条数据或间隔3秒就去从库在线执行,或保存下方的 sql 语句为 sql 文件,手动去从库执行。
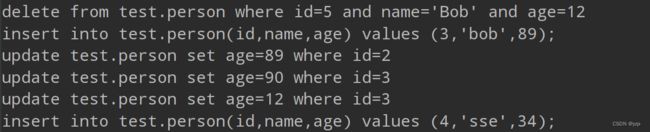
PS : Java 也有库可以解析 binlog,只要能解析 binlog 文件就能还原出之前执行的 sql 。