Java中的redis介绍以及运用场景
目标:了解redis并能学会在实际项目中怎么用redis
文章目录
前言
一、Reids基础(安装、基本的数据结构以及数据结构的使用)
1. Redis入门
1.1 Redis简介
1.2 Redis下载与安装
1.2.1 Redis下载
1.2.2 Redis安装
1.3 Redis服务启动与停止
1.4 Redis配置文件
2. Redis数据类型
2.1 介绍
2.2 Redis 5种常用数据类型
3. Redis常用命令
3.1 字符串string操作命令
3.2 哈希hash操作命令
3.3 列表list操作命令
3.4 集合set操作命令
3.5 有序集合sorted set操作命令
3.6 通用命令
4. 在Java中操作Redis
4.1 介绍
4.2 Jedis
4.3 Spring Data Redis
4.3.1 介绍
4.3.2 使用方式
4.3.2.1 环境搭建
4.3.2.2 操作字符串类型数据
4.3.2.3 操作哈希类型数据
5.3.2.4 操作列表类型数据
5.3.2.5 操作集合类型数据
4.3.2.6 操作有序集合类型数据
4.3.2.7 通用操作
二、Redis 为什么这么快
1.基于内存操作
2.高效的数据结构
3.合理的线程模型
三、 什么是缓存击穿、缓存穿透、缓存雪崩?
1.缓存穿透:
2.缓存雪崩
3.缓存击穿
四、Redis 过期策略和内存淘汰策略
五、 Redis 的常用应用场景(运用)
总结
前言
NoSQL的全称是Not-Only SQL,指的是非关系型数据库,它是关系型数据库的补充,没有表与表之间的关系,主要用于海量数据的处理问题。
Redis 是 C 语言开发的一个开源的(遵从 BSD 协议)高性能非关系型(NoSQL)的(key-value)键值对数据库。可以用作数据库、缓存、消息中间件等。
一、Reids基础(安装、基本的数据结构以及数据结构的使用)
-
Redis入门
-
Redis数据类型
-
Redis常用命令
-
在Java中操作Redis
1. Redis入门
1.1 Redis简介
Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache, and message broker. 翻译为:Redis是一个开源的内存中的数据结构存储系统,它可以用作:数据库、缓存和消息中间件。
官网:https://redis.io
Redis是用C语言开发的一个开源的高性能键值对(key-value)数据库,官方提供的数据是可以达到100000+的QPS(每秒内查询次数)。它存储的value类型比较丰富,也被称为结构化的NoSql数据库。
NoSql(Not Only SQL),不仅仅是SQL,泛指非关系型数据库。NoSql数据库并不是要取代关系型数据库,而是关系型数据库的补充。
关系型数据库(RDBMS):
-
Mysql
-
Oracle
-
DB2
-
SQLServer
非关系型数据库(NoSql):
-
Redis
-
Mongo db
-
MemCached
1.2 Redis下载与安装
1.2.1 Redis下载
Redis安装包分为windows版和Linux版:
-
Windows版下载地址:Releases · microsoftarchive/redis · GitHub
-
Linux版下载地址: Index of /releases/
下载后得到下面安装包:
1.2.2 Redis安装
1)在Linux中安装Redis
在Linux系统安装Redis步骤:
-
将Redis安装包上传到Linux
-
解压安装包,命令:==tar -zxvf redis-4.0.0.tar.gz -C /usr/local==
-
安装Redis的依赖环境gcc,命令:==yum install gcc-c++==
-
进入/usr/local/redis-4.0.0,进行编译,命令:==make==
-
进入redis的src目录进行安装,命令:==make install==
安装后重点文件说明:
/usr/local/redis-4.0.0/src/redis-server:Redis服务启动脚本
/usr/local/redis-4.0.0/src/redis-cli:Redis客户端脚本
/usr/local/redis-4.0.0/redis.conf:Redis配置文件
2)在Windows中安装Redis
Redis的Windows版属于绿色软件,直接解压即可使用,解压后目录结构如下:

1.3 Redis服务启动与停止
1)Linux系统中启动和停止Redis
执行Redis服务启动脚本文件==redis-server==:
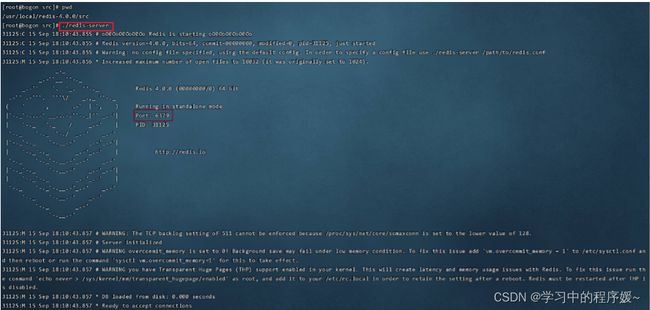
通过启动日志可以看到,Redis默认端口号为==6379==。
==Ctrl + C==停止Redis服务
通过==redis-cli==可以连接到本地的Redis服务,默认情况下不需要认证即可连接成功。
退出客户端可以输入==exit==或者==quit==命令。
2)Windows系统中启动和停止Redis
Windows系统中启动Redis,直接双击redis-server.exe即可启动Redis服务,redis服务默认端口号为6379
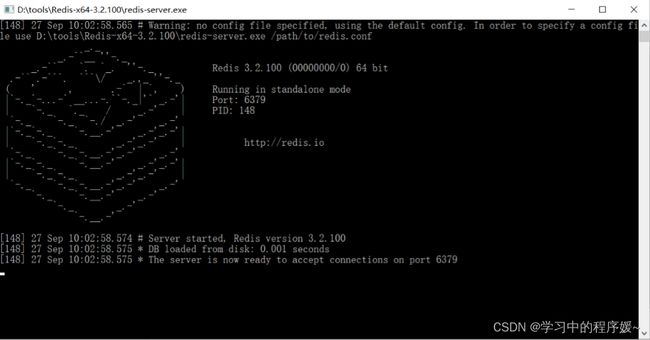
==Ctrl + C==停止Redis服务
双击==redis-cli.exe==即可启动Redis客户端,默认连接的是本地的Redis服务,而且不需要认证即可连接成功。

退出客户端可以输入==exit==或者==quit==命令。
1.4 Redis配置文件
前面我们已经启动了Redis服务,默认情况下Redis启动后是在前台运行,而且客户端不需要密码就可以连接到Redis服务。如果我们希望Redis服务启动后是在后台运行,同时希望客户端认证通过后才能连接到Redis服务,应该如果做呢?
此时就需要修改Redis的配置文件:
-
Linux系统中Redis配置文件:REDIS_HOME/redis.conf
-
Windows系统中Redis配置文件:REDIS_HOME/redis.windows.conf
通过修改Redis配置文件可以进行如下配置:
1)设置Redis服务后台运行
将配置文件中的==daemonize==配置项改为yes,默认值为no。
注意:Windows版的Redis不支持后台运行。
2)设置Redis服务密码
将配置文件中的 ==# requirepass foobared== 配置项取消注释,默认为注释状态。foobared为密码,可以根据情况自己指定。
3)设置允许客户端远程连接Redis服务
Redis服务默认只能客户端本地连接,不允许客户端远程连接。将配置文件中的 ==bind 127.0.0.1== 配置项注释掉。
解释说明:
Redis配置文件中 ==#== 表示注释
Redis配置文件中的配置项前面不能有空格,需要顶格写
daemonize:用来指定redis是否要用守护线程的方式启动,设置成yes时,代表开启守护进程模式。在该模式下,redis会在后台运行
requirepass:设置Redis的连接密码
bind:如果指定了bind,则说明只允许来自指定网卡的Redis请求。如果没有指定,就说明可以接受来自任意一个网卡的Redis请求。
注意:修改配置文件后需要重启Redis服务配置才能生效,并且启动Redis服务时需要显示的指定配置文件:
1)Linux中启动Redis服务
# 进入Redis安装目录 cd /usr/local/redis-4.0.0 # 启动Redis服务,指定使用的配置文件 ./src/redis-server ./redis.conf
2)Windows中启动Redis服务

由于Redis配置文件中开启了认证校验,即客户端连接时需要提供密码,此时客户端连接方式变为:
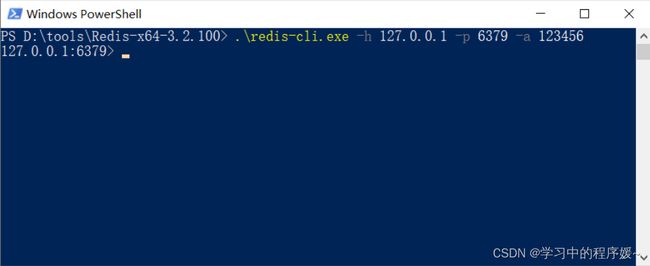
解释说明:
-h:指定连接的Redis服务的ip地址
-p:指定连接的Redis服务的端口号
-a:指定连接的Redis服务的密码
2. Redis数据类型
2.1 介绍
Redis存储的是key-value结构的数据,其中key是字符串类型,value有5种常用的数据类型:
-
字符串 string
-
哈希 hash
-
列表 list
-
集合 set
-
有序集合 sorted set / zset
2.2 Redis 5种常用数据类型
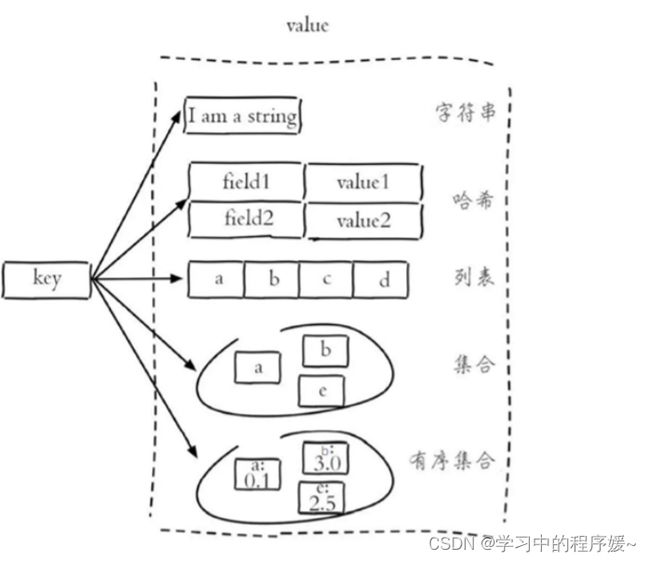
解释说明:
字符串(string):普通字符串,常用
哈希(hash):适合存储对象
列表(list):按照插入顺序排序,可以有重复元素
集合(set):无序集合,没有重复元素
有序集合(sorted set / zset):集合中每个元素关联一个分数(score),根据分数升序排序,没有重复元素
3. Redis常用命令
3.1 字符串string操作命令
Redis 中字符串类型常用命令:
-
SET key value 设置指定key的值
-
有key改值 无key新增
-
GET key 获取指定key的值
-
SETEX key seconds value 设置指定key的值,并将 key 的过期时间设为 seconds 秒
-
SETNX key value 只有在 key 不存在时设置 key 的值
-
有key不改值 无key新增
更多命令可以参考Redis中文网:Redis中文网
3.2 哈希hash操作命令
Redis hash 是一个string类型的 field 和 value 的映射表,hash特别适合用于存储对象,常用命令:
-
HSET key field value 将哈希表 key 中的字段 field 的值设为 value
-
HGET key field 获取存储在哈希表中指定字段的值
-
HDEL key field 删除存储在哈希表中的指定字段
-
HKEYS key 获取哈希表中所有字段
-
HVALS key 获取哈希表中所有值
-
HGETALL key 获取在哈希表中指定 key 的所有字段和值

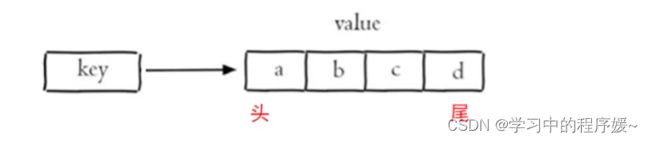
3.3 列表list操作命令
Redis 列表是简单的字符串列表,按照插入顺序排序,常用命令:
-
LPUSH key value1 [value2] 将一个或多个值插入到列表头部
-
LRANGE key start stop 获取列表指定范围内的元素
-
RPOP key 移除并获取列表最后一个元素
-
LLEN key 获取列表长度
-
BRPOP key1 [key2 ] timeout 移出并获取列表的最后一个元素, 如果列表没有元素会阻塞列表直到等待超 时或发现可弹出元素为止
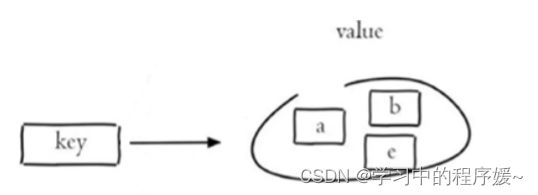
3.4 集合set操作命令
Redis set 是string类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据,常用命令:
-
SADD key member1 [member2] 向集合添加一个或多个成员
-
SMEMBERS key 返回集合中的所有成员
-
SCARD key 获取集合的成员数
-
SINTER key1 [key2] 返回给定所有集合的交集
-
SUNION key1 [key2] 返回所有给定集合的并集
-
SDIFF key1 [key2] 返回给定所有集合的差集
-
SREM key member1 [member2] 移除集合中一个或多个成员
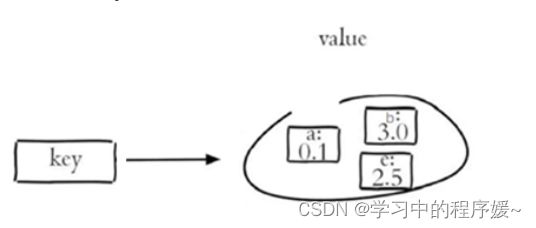
3.5 有序集合sorted set操作命令
Redis sorted set 有序集合是 string 类型元素的集合,且不允许重复的成员。每个元素都会关联一个double类型的分数(score) 。redis正是通过分数来为集合中的成员进行从小到大排序。有序集合的成员是唯一的,但分数却可以重复。
常用命令:
-
ZADD key score1 member1 [score2 member2] 向有序集合添加一个或多个成员,或者更新已存在成员的 分数
-
ZRANGE key start stop [WITHSCORES] 通过索引区间返回有序集合中指定区间内的成员
-
ZINCRBY key increment member 有序集合中对指定成员的分数加上增量 increment
-
ZREM key member [member ...] 移除有序集合中的一个或多个成员
3.6 通用命令
Redis中的通用命令,主要是针对key进行操作的相关命令:
-
KEYS pattern 查找所有符合给定模式( pattern)的 key
-
EXISTS key 检查给定 key 是否存在
-
TYPE key 返回 key 所储存的值的类型
-
TTL key 返回给定 key 的剩余生存时间(TTL, time to live),以秒为单位
-
DEL key 该命令用于在 key 存在是删除 key
4. 在Java中操作Redis
4.1 介绍
前面我们讲解了Redis的常用命令,这些命令是我们操作Redis的基础,那么我们在java程序中应该如何操作Redis呢?这就需要使用Redis的Java客户端,就如同我们使用JDBC操作MySQL数据库一样。
Redis 的 Java 客户端很多,官方推荐的有三种:
-
Jedis
-
Lettuce
-
Redisson
Spring 对 Redis 客户端进行了整合,提供了 Spring Data Redis,在Spring Boot项目中还提供了对应的Starter,即 spring-boot-starter-data-redis。
4.2 Jedis
Jedis 是 Redis 的 Java 版本的客户端实现。
maven坐标:
redis.clients jedis 2.8.0
使用 Jedis 操作 Redis 的步骤:
-
获取连接
-
执行操作
-
关闭连接
示例代码:
package com.itheima.test;
import org.junit.Test;
import redis.clients.jedis.Jedis;
import java.util.Set;
/**
* 使用Jedis操作Redis
*/
public class JedisTest {
@Test
public void testRedis(){
//1 获取连接
Jedis jedis = new Jedis("localhost",6379);
//2 执行具体的操作
jedis.set("username","xiaoming");
String value = jedis.get("username");
System.out.println(value);
//jedis.del("username");
jedis.hset("myhash","addr","bj");
String hValue = jedis.hget("myhash", "addr");
System.out.println(hValue);
Set keys = jedis.keys("*");
for (String key : keys) {
System.out.println(key);
}
//3 关闭连接
jedis.close();
}
} 4.3 Spring Data Redis
4.3.1 介绍
Spring Data Redis 是 Spring 的一部分,提供了在 Spring 应用中通过简单的配置就可以访问 Redis 服务,对 Redis 底层开发包进行了高度封装。在 Spring 项目中,可以使用Spring Data Redis来简化 Redis 操作。
网址:Spring Data Redis
maven坐标:
org.springframework.data spring-data-redis 2.4.8
Spring Boot提供了对应的Starter,maven坐标:
org.springframework.boot spring-boot-starter-data-redis
Spring Data Redis中提供了一个高度封装的类:RedisTemplate,针对 Jedis 客户端中大量api进行了归类封装,将同一类型操作封装为operation接口,具体分类如下:
-
ValueOperations:简单K-V操作
-
SetOperations:set类型数据操作
-
ZSetOperations:zset类型数据操作
-
HashOperations:针对hash类型的数据操作
-
ListOperations:针对list类型的数据操作
4.3.2 使用方式
4.3.2.1 环境搭建
第一步:创建maven项目springdataredis_demo,配置pom.xml文件
4.0.0
org.springframework.boot
spring-boot-starter-parent
2.4.5
com.itheima
springdataredis_demo
1.0-SNAPSHOT
1.8
org.springframework.boot
spring-boot-starter-test
test
junit
junit
org.springframework.boot
spring-boot-starter-data-redis
org.springframework.boot
spring-boot-maven-plugin
2.4.5
第二步:编写启动类
package com.itheima;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class App {
public static void main(String[] args) {
SpringApplication.run(App.class,args);
}
}
第三步:配置application.yml
spring:
application:
name: springdataredis_demo
#Redis相关配置
redis:
host: localhost
port: 6379
#password: 123456
database: 0 #操作的是0号数据库
jedis:
#Redis连接池配置
pool:
max-active: 8 #最大连接数
max-wait: 1ms #连接池最大阻塞等待时间
max-idle: 4 #连接池中的最大空闲连接
min-idle: 0 #连接池中的最小空闲连接
解释说明:
spring.redis.database:指定使用Redis的哪个数据库,Redis服务启动后默认有16个数据库,编号分别是从0到15。
可以通过修改Redis配置文件来指定数据库的数量。
第四步:提供配置类
package com.itheima.config;
import org.springframework.cache.annotation.CachingConfigurerSupport;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.StringRedisSerializer;
/**
* Redis配置类
*/
@Configuration
public class RedisConfi
g extends CachingConfigurerSupport {
@Bean
public RedisTemplate redisTemplate(RedisConnectionFactory connectionFactory) {
RedisTemplate redisTemplate = new RedisTemplate<>();
//默认的Key序列化器为:JdkSerializationRedisSerializer
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setConnectionFactory(connectionFactory);
return redisTemplate;
}
} 解释说明:
当前配置类不是必须的,因为 Spring Boot 框架会自动装配 RedisTemplate 对象,但是默认的key序列化器为JdkSerializationRedisSerializer,导致我们存到Redis中后的数据和原始数据有差别
第五步:提供测试类
package com.itheima.test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
@SpringBootTest
@RunWith(SpringRunner.class)
public class SpringDataRedisTest {
@Autowired
private RedisTemplate redisTemplate;
}4.3.2.2 操作字符串类型数据
/**
* 操作String类型数据
*/
@Test
public void testString(){
//存值
redisTemplate.opsForValue().set("city123","beijing");
//取值
String value = (String) redisTemplate.opsForValue().get("city123");
System.out.println(value);
//存值,同时设置过期时间
redisTemplate.opsForValue().set("key1","value1",10l, TimeUnit.SECONDS);
//存值,如果存在则不执行任何操作
Boolean aBoolean = redisTemplate.opsForValue().setIfAbsent("city1234", "nanjing");
System.out.println(aBoolean);
}4.3.2.3 操作哈希类型数据
/**
* 操作Hash类型数据
*/
@Test
public void testHash(){
HashOperations hashOperations = redisTemplate.opsForHash();
//存值
hashOperations.put("002","name","xiaoming");
hashOperations.put("002","age","20");
hashOperations.put("002","address","bj");
//取值
String age = (String) hashOperations.get("002", "age");
System.out.println(age);
//获得hash结构中的所有字段
Set keys = hashOperations.keys("002");
for (Object key : keys) {
System.out.println(key);
}
//获得hash结构中的所有值
List values = hashOperations.values("002");
for (Object value : values) {
System.out.println(value);
}
}5.3.2.4 操作列表类型数据
/**
* 操作List类型的数据
*/
@Test
public void testList(){
ListOperations listOperations = redisTemplate.opsForList();
//存值
listOperations.leftPush("mylist","a");
listOperations.leftPushAll("mylist","b","c","d");
//取值
List mylist = listOperations.range("mylist", 0, -1);
for (String value : mylist) {
System.out.println(value);
}
//获得列表长度 llen
Long size = listOperations.size("mylist");
int lSize = size.intValue();
for (int i = 0; i < lSize; i++) {
//出队列
String element = (String) listOperations.rightPop("mylist");
System.out.println(element);
}
}
5.3.2.5 操作集合类型数据
/**
* 操作Set类型的数据
*/
@Test
public void testSet(){
SetOperations setOperations = redisTemplate.opsForSet();
//存值
setOperations.add("myset","a","b","c","a");
//取值
Set myset = setOperations.members("myset");
for (String o : myset) {
System.out.println(o);
}
//删除成员
setOperations.remove("myset","a","b");
//取值
myset = setOperations.members("myset");
for (String o : myset) {
System.out.println(o);
}
}
4.3.2.6 操作有序集合类型数据
/**
* 操作ZSet类型的数据
*/
@Test
public void testZset(){
ZSetOperations zSetOperations = redisTemplate.opsForZSet();
//存值
zSetOperations.add("myZset","a",10.0);
zSetOperations.add("myZset","b",11.0);
zSetOperations.add("myZset","c",12.0);
zSetOperations.add("myZset","a",13.0);
//取值
Set myZset = zSetOperations.range("myZset", 0, -1);
for (String s : myZset) {
System.out.println(s);
}
//修改分数
zSetOperations.incrementScore("myZset","b",20.0);
//取值
myZset = zSetOperations.range("myZset", 0, -1);
for (String s : myZset) {
System.out.println(s);
}
//删除成员
zSetOperations.remove("myZset","a","b");
//取值
myZset = zSetOperations.range("myZset", 0, -1);
for (String s : myZset) {
System.out.println(s);
}
}
4.3.2.7 通用操作
/**
* 通用操作,针对不同的数据类型都可以操作
*/
@Test
public void testCommon(){
//获取Redis中所有的key
Set keys = redisTemplate.keys("*");
for (String key : keys) {
System.out.println(key);
}
//判断某个key是否存在
Boolean itcast = redisTemplate.hasKey("itcast");
System.out.println(itcast);
//删除指定key
redisTemplate.delete("myZset");
//获取指定key对应的value的数据类型
DataType dataType = redisTemplate.type("myset");
System.out.println(dataType.name());
} 二、Redis 为什么这么快
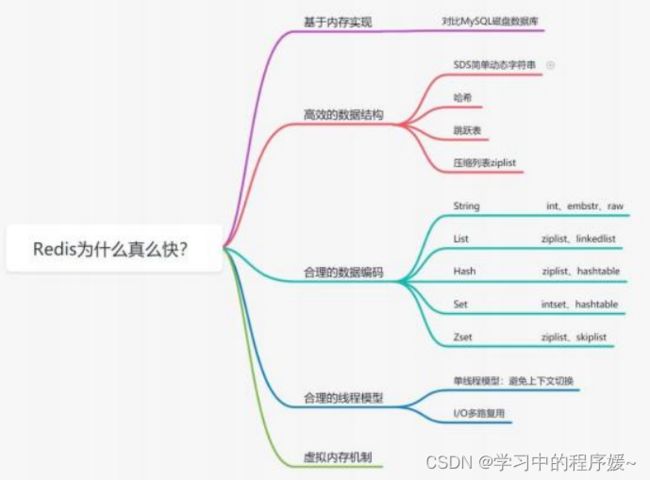
1.基于内存操作
我们都知道内存读写是比在磁盘快很多 , Redis 基于内存存储实现数据库,
相对于数据存在磁盘 MySQL 数据库 ,省去磁盘 I/O 消耗。
2.高效的数据结构
1).SDS 简单动态字符串:二进制安全 :Redis 可以存储一些二进制数据 ,在 C 语言中字符串遇到'\0'会 结束 ,而 SDS 中标志字符串结束是 len 属性。
2)字典:Redis 作为 K-V 型内存数据库 ,所有的键值就是用字典来存储。字典就是哈希 表, 比如 HashMap, 通过key 就可以直接获取到对应 value。而哈希表的特性,在 O( 1)时间复杂度就可以获得对应的值。
3).跳跃表:
. 字符串长度处理:Redis 获取字符串长度 ,时间复杂度为 O(1) ,而 C 语言中, 需要从头开始遍历,复杂度为 O( n);
. 空间预分配:字符串修改越频繁的话, 内存分配越频繁 ,就会消耗性能 ,而 SDS 修改和空间扩充,会额外分配未使用的空间 ,减少性能损耗。
. 惰性空间释放 :SDS 缩短时 ,不是回收多余的内存空间 ,而是 free 记录下多 余的空间 ,后续有变更 ,直接使用 free 中记录的空间 ,减少分配。
3.合理的线程模型

多路 I/O 复用技术可以让单个线程高效的处理多个连接请求 ,而 Redis 使用用
epoll 作为 I/O 多路复用技术的实现。并且 ,Redis 自身的事件处理模型将
epoll 中的连接、读写、关闭都转换为事件 ,不在网络 I/O 上浪费过多的时间。
单线程模型
. Redis 是单线程模型 , 而单线程避免了 CPU 不必要的上下文切换和竞争锁的消耗。也正因为是单线程 ,如果某个命令执行过长(如 hgetall 命令) ,会造成阻塞。
Redis 是面向快速执行场景的数据库。 ,所以要慎用如 smembers 和 l range 、 hgetall 等命令。
. Redis 6.0 引入了多线程提速 ,它的执行命令操作内存的仍然是个单线程只是在io方面是多线程。
三、 什么是缓存击穿、缓存穿透、缓存雪崩?
1.缓存穿透:
指查询一个一定不存在的数据, 由于缓存是不命中时需要从数据库 查询 ,查不到数据则不写入缓存 ,这将导致这个不存在的数据每次请求都要到数据库去查询 ,进而给数据库带来压力
如何避免缓存穿透呢? 一般有三种方法。
. 1.如果是非法请求 ,我们在 API 入口 ,对参数进行校验 ,过滤非法值。
. 2.如果查询数据库为空 ,我们可以给缓存设置个空值 ,或者默认值。但是如有有写 请求进来的话 ,需要更新缓存哈 ,以保证缓存一致性 , 同时 ,最后给缓存设置适当 的过期时间。(业务上比较常用 ,简单有效)
. 3.使用布隆过滤器快速判断数据是否存在。 即一个查询请求过来时 ,先通过布隆过 滤器判断值是否存在 ,存在才继续往下查。
2.缓存雪崩
指缓存中数据大批量到过期时间 ,而查询数据量巨大 ,请求都直接访问数据库 ,引起数据库压力过大甚至 down 机。
缓存雪奔一般是由于大量数据同时过期造成的 , 对于这个原因 ,可通过均匀设置过 期时间解决 , 即让过期时间相对离散一点。如采用一个较大固定值+一个较小的随 机值 , 5 小时+0 到 1800 秒酱紫。
. Redis 故障宕机也可能引起缓存雪奔。这就需要构造 Redis 高可用集群啦。
3.缓存击穿
指热点key 在某个时间点过期的时候 ,而恰好在这个时间点对这个Key 有大量的并发请求过来,从而大量的请求打到 db。
解决方案就有两种:
. 1.使用互斥锁方案。缓存失效时 ,不是立即去加载 db 数据 ,而是先使用某些带成 功返回的原子操作命令 ,如(Redis 的 setnx) 去操作 ,成功的时候 ,再去加载 db 数据库数据和设置缓存。否则就去重试获取缓存。
. 2. “永不过期 ” ,是指没有设置过期时间 ,但是热点数据快要过期时 ,异步线程去 更新和设置过期时间。
四、Redis 过期策略和内存淘汰策略

五、 Redis 的常用应用场景(运用)
1 缓存
我们一提到 redis, 自然而然就想到缓存 ,国内外中大型的网站都离不开缓存。 合理的利用缓存 ,比如缓存热点数据 ,不仅可以提升网站的访问速度 ,还可以 降低数据库 DB 的压力。并且 ,Redis 相比于 memcached ,还提供了丰富的
数据结构 ,并且提供 RDB 和 AOF 等持久化机制 ,强的一批。
2 排行榜
当今互联网应用 ,有各种各样的排行榜 ,如电商网站的月度销量排行榜、社交 APP 的礼物排行榜、小程序的投票排行榜等等。 Redis 提供的 zset 数据类型能
够实现这些复杂的排行榜。
比如 ,用户每天上传视频 ,获得点赞的排行榜可以这样设计
3 计数器应用
各大网站、APP 应用经常需要计数器的功能 ,如短视频的播放数、电商网站的浏览数。这些播放数、浏览数一般要求实时的, 每一次播放和浏览都要做加 1 的操作 ,如果并发量很大对于传统关系型数据的性能是一种挑战。Redis 天然
支持计数功能而且计数的性能也非常好 ,可以说是计数器系统的重要选择。
4 共享Session
如果一个分布式 Web 服务将用户的Session 信息保存在各自服务器 ,用户刷 新一次可能就需要重新登录了 ,这样显然有问题。实际上 ,可以使用 Redis 将 用户的Session 进行集中管理 ,每次用户更新或者查询登录信息都直接从Redis
中集中获取。
5 分布式锁
几乎每个互联网公司中都使用了分布式部署 ,分布式服务下 ,就会遇到对同一
个资源的并发访问的技术难题 ,如秒杀、下单减库存等场景。
. 用 synchronize 或者 reentrantlock 本地锁肯定是不行的。
. 如果是并发量不大话 ,使用数据库的悲观锁、乐观锁来实现没啥问题。
. 但是在并发量高的场合中 ,利用数据库锁来控制资源的并发访问 ,会影响数据库的性能。
. 实际上 ,可以用 Redis 的setnx 来实现分布式的锁。
6 社交网络
赞/踩、粉丝、共同好友/喜好、推送、下拉刷新等是社交网站的必备功能, 由 于社交网站访问量通常比较大 ,而且传统的关系型数据不太适保存 这种类型的
数据 ,Redis 提供的数据结构可以相对比较容易地实现这些功能。
7 消息队列
消息队列是大型网站必用中间件 ,如 ActiveMQ、RabbitMQ、Kafka 等流行 的消息队列中间件 ,主要用于业务解耦、流量削峰及异步处理实时性低的业务。 Redis 提供了发布/订阅及阻塞队列功能 ,能实现一个简单的消息队列系统。另
外 ,这个不能和专业的消息中间件相比。
8 位操作
用于数据量上亿的场景下 ,例如几亿用户系统的签到 ,去重登录次数统计 ,某 用户是否在线状态等等。腾讯 10 亿用户 ,要几个毫秒内查询到某个用户是否 在线 ,能怎么做?千万别说给每个用户的立一个 key ,然后挨个记(你可以算 一下需要的内存会很恐怖 ,而且这种类似的需求很多。这里要用到位操作—— 使用 setbit、getbit、 bitcount 命令。原理是: redis 内构的一个足够长的数 组 ,每个数组元素只能是 0 和 1 两个值 ,然后这个数组的下标 index 用来表示 用户id(必须是数字哈) ,那么很显然 ,这个几亿长的大数组就能通过下标和
元素值(0 和 1)来构的一个记忆系统。
总结
以上是对redis基本知识以及运用的介绍,请各位兄弟们指正