Kube Queue:Kubernetes 任务排队的利器
作者:吴昆
批处理作业(Batch Job)常应用于数据处理、仿真计算、科学计算和人工智能等领域,主要用于执行一次数据处理或模型训练任务。由于这类任务往往需要消耗大量计算资源,因此必须根据任务的优先级和提交者的可用资源情况进行合理排队,才能最大化集群资源的利用效率。
Scheduler 在任务调度领域水土不服
当前 Kubernetes 的调度器提供了完善的 Pod 通用调度功能,但是在面对大量任务排队时,依然暴露出了局限性:
-
缺少自动化的排队机制
默认情况下,批处理任务会直接创建作业 Pod,当集群可用资源不足时,大量 Pending Pod 会严重拖慢 Kubernetes 调度器的处理速度,影响在线业务扩容和调度。因此,迫切需要能够自动根据集群资源控制作业启停的自动化排队机制。
-
缺少多样化的排队策略
为提升任务排队效率,需要根据集群资源和任务规模,采取阻塞队列、优先级队列、回填调度等不同的排队策略。然而,Kubernetes 调度器的默认调度策略主要根据优先级和 Pod 创建顺序进行排队,难以应对多样化的任务排队需求。
-
缺少多队列能力
为隔离不同用户或租户的任务,避免资源被单一用户的大量任务占满,导致其它用户“饿死”,任务排队系统需要支持多队列管理,将不同用户提交的任务分配到不同队列中排队。目前,Kubernetes 调度器仅支持单一队列,无法有效避免此类问题。
-
大量任务类型难以统一在机器学习、高性能计算、大数据计算和离线工作流等不同应用场景下,用户会提交不同类型的任务,每类任务对资源和优先级的计算方法都有所不同,将这些计算逻辑都集成到调度器中,必然大幅增加维护复杂性和运维成本。
因此,在处理复杂的任务调度场景时,云服务提供商通常不将原生 Kubernetes 调度器作为首选方案。
Queue 在 Kubernetes 中的定位与职责
在 Kubernetes 集群中,Queue 与 Scheduler 共同协作以确保任务的高效调度。为了避免“脑裂”等典型的分布式系统问题,必须清晰划分它们的职责。目前,Kubernetes 中的 Queue 可以分为两类:
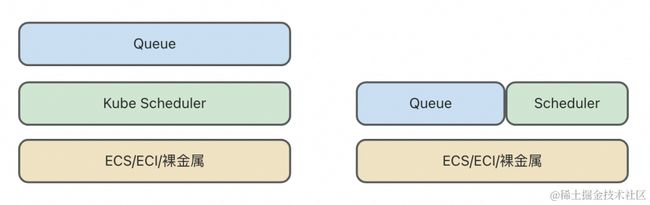
第一类 Queue 与 Kubernetes 的 Scheduler 属于不同分层。 Queue 负责任务的排序和按顺序出队,专注于任务的生命周期管理和实现更公平的用户间出队策略;Scheduler 负责任务 Pod 的合理编排,找到最优的放置策略,专注于节点亲和性、拓扑感知等方面。这类 Queue 不直接感知底层的物理信息,任务出队后可能会因为节点亲和性、资源碎片化等因素无法调度,导致队头阻塞。因此,这类队列通常需要引入“任务在无法调度时重新入队”的机制。本文将介绍的 Kube Queue 和开源社区中的 Kueue 都是这类 Queue 的代表。
第二类 Queue 与 Scheduler 相互耦合,任务只有在确保能够调度的情况下才会出队。 这种设计避免了第一类 Queue 的队头阻塞问题,但是依然存在难以完全兼容调度器全部调度语法的问题。而且,使用这类 Queue 意味着需要替换默认调度器,对集群而言是较大的变更。这类 Queue 的典型代表有 Volcano 和 YuniKorn。
Kube Queue 概述
Kube Queue 是阿里云容器服务 ACK 的云原生 AI 套件中的一个关键组件,旨在解决以上 Kubernetes 调度器在任务调度场景中存在的问题。Kube Queue 通过与云原生 AI 套件的 Arena 组件以及 ACK 集群的弹性 Quota 特性相结合,能够高效支持多种 AI 任务自动排队和多租户 Quota 管理。
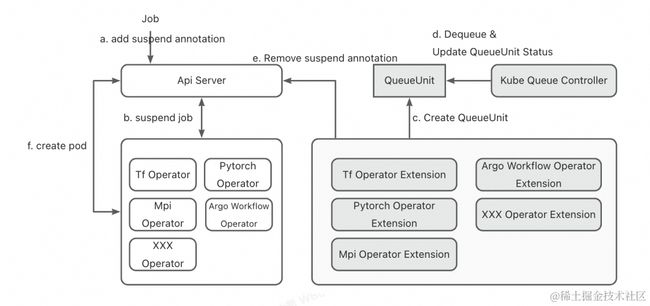
Kube Queue 的架构如下图所示,由以下主要部分构成:
1. Kube Queue Controller: 负责任务排队的核心控制器,如下图左侧所示。
2. Operator Extension: 为不同任务类型提供定制化支持的扩展组件,如下图右侧所示。
Kube Queue 的工作机制
任务排队系统围绕两个核心抽象——Queue 和 QueueUnit:
Queue: 代表一个队列实体,是队列进行排队的容器,它包含队列的策略、Quota、排队参数等信息。目前 Kube Queue 能够自动感知不同种类的资源配额,如 Resource Quota、Elastic Quota 和 ElasticQuotaTree。Kube Queue Controller 会根据这些 Quota 的配置自动创建对应的 Queue 对象。用户仅需要配置上层的 Quota,无需额外配置底层队列。
QueueUnit: 代表一个任务实体,它会忽略原任务中与排队策略无关的参数信息,从而减少 Kube Queue Controller 需要监听的对象类型以及与 Api Server 建立的连接数。并且,由于 QueueUnit 屏蔽了实际 Job 的类型,任何需要接入排队系统的任务,仅需实现 Extension 的排队接口即可,有效实现了任务类型的可扩展。
工作流程如下:
任务提交和入队: 当一个可被 Kube Queue 识别的任务被提交到 Api Server,对应的 Job Operator 和 Operator Extension 会收到任务创建事件。它们会根据任务提交时是否为挂起状态,决定是否接管任务排队。若任务提交时处于挂起状态,Extension 会评估任务所需资源和确定优先级等关键排队参数,并创建 QueueUnit(这是在 Kube Queue 排队的统一对象,其初始状态为 Enqueued)。
任务排队和等待调度: Kube Queue Controller 接收到 QueueUnit 的创建后,会根据内部队列归属策略确定 QueueUnit 所属队列,并在队列内根据优先级与创建时间进行排序。Kube Queue Controller 通过一个调度循环处理所有队列,每轮循环会从每个队列中抽取出队头的任务尝试调度,以此确保不同队列中的任务数量和优先级不会互相干扰。
任务出队和执行调度: 任务出队后,QueueUnit 状态更新为 Dequeued,Extension 接收到此状态后会移除该任务的挂起状态。Operator 监听到任务解除挂起后,会开始创建任务 Pod,此后任务进入正常的调度流程。若任务在一个可配置的超时时段内未完成调度,Extension 会将对应的 QueueUnit 重置为 Enqueued 状态,代表任务启动超时,需要重新排队,这样做是为了防止队列出现队头阻塞。若任务成功执行,QueueUnit 的状态则会被更新为 Running。

Kube Queue 的排队策略
排队策略是排队系统不可缺少的部分。目前,Kube Queue 提供了三种灵活的排队策略以满足企业客户的多样化需求,且每个队列都可配置独立的排队策略。
轮转策略(默认策略)
ack-kube-queue 默认采用与 kube-scheduler 相同的任务轮转机制处理任务,即所有任务在队列中依次请求资源,请求失败则进入 Unschedulable 队列退避,等待下次调度。该策略确保每个任务均有机会调度,最大效率利用 Quota,但对于出队的任务可能无法严格保证优先级。推荐在希望保证集群资源利用率的情况下使用该策略。
阻塞策略
当集群中存在大量资源需求量小的任务时,由于小任务会占用大量队列轮转时间,资源需求量大的任务将难以获得资源执行,存在长时间 Pending 的风险。为了避免此类情况,ack-kube-queue 提供阻塞队列功能,开启后,队列将只调度队列最前端的任务,使得大任务能够有机会执行。推荐在希望保证任务优先级的情况下使用该策略。
严格优先级策略
为了保证高优先级任务能够在集群获得空闲资源时被优先尝试调度,即便它们仍处于退避阶段,ack-kube-queue 提供严格优先级调度功能。开启后,队列将在运行中的任务结束后,从最早提交的高优先级任务开始尝试执行,使其优先获得集群空闲资源,避免资源被低优先级任务占用。该策略是轮转策略和阻塞策略的折中策略。
快速上手 Kube Queue
在本节中,我们将通过一个实际案例演示如何使用 Kube Queue 执行一个基本的任务排队操作。
首先,需要安装 kube-queue 组件,在阿里云容器服务 ACK 产品的云原生 AI 套件页面中即可一键安装。可参考:如何安装及使用任务队列 ack-kube-queue [ 1]
安装了 Kube Queue 之后,在集群的 kube-queue 命名空间下会存在 Kube Queue Controller 和多个针对不同 Job 类型提供扩展支持的 Controller。每个 Controller 会负责 Kube Queue 与一种类型任务的对接。
默认情况下,kube-queue-controller 中会通过 oversellrate 参数设置超卖比为 2,此时队列会能够出队配置资源两倍资源量的任务,可以在 Deployment 的编辑页面中将超卖比设置为 1。
若需实现两个 Job 之间的排队,首先需要提交一个申明队列的 ElasticQuotaTree。该 ElasticQuotaTree 申明了一个最多可以使用 1 核 CPU 和 1Gi 内存资源的队列,并将 default 命名空间挂载在该队列下。
apiVersion: scheduling.sigs.k8s.io/v1beta1
kind: ElasticQuotaTree
metadata:
name: elasticquotatree
namespace: kube-system # 只有kube-system下才会生效
spec:
root:
name: root # Root节点的Max等于Min
max:
cpu: 1
memory: 1Gi
min:
cpu: 1
memory: 1Gi
children:
- name: child-1
max:
cpu: 1
memory: 1Gi
namespaces: # 配置对应的Namespace
- default
之后,我们提交两个 Kubernetes Job,提交时需要将 Job 设置为 Suspend 状态,即将 Job 的 .spec.suspend 字段设置为 true。
apiVersion: batch/v1
kind: Job
metadata:
generateName: pi-
spec:
suspend: true
completions: 1
parallelism: 1
template:
spec:
containers:
- name: pi
image: perl:5.34.0
command: ["sleep", "1m"]
resources:
requests:
cpu: 1
limits:
cpu: 1
restartPolicy: Never
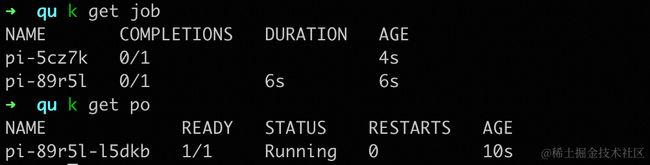
提交之后,查看任务状态,可以看到两个任务中仅有一个任务开始执行,另一个任务进入等待状态。
在前一个任务执行完成后,后续任务自动开始执行,完成任务执行的自动控制。

What’s Next
在本篇文章中,我们探讨了云原生时代下,任务队列系统的重要性以及必要性,并详细介绍了阿里云容器服务 ACK 的 Kube Queue 如何在当前的 Kubernetes 生态中,明确自身的角色定位与价值贡献。在后续的文章中,我们将进一步讨论,如何利用容器服务 ACK 的 Kube Queue 以及高效的调度机制,快速构建一个能够满足企业需求、基于 ElasticQuotaTree 的任务管理系统。
欢迎扫码添加阿里云 ACK 云原生 AI 套件微信小助手邀您进入云原生 AI 套件微信交流群。(钉钉群号:33214567)
相关链接:
[1] 如何安装及使用任务队列 ack-kube-queue
https://help.aliyun.com/zh/ack/ack-managed-and-ack-dedicated/user-guide/use-ack-kube-queue-to-manage-job-queues?spm=a2c4g.11186623.0.i2#task-2295877