k8s-调度
调度

从上面的架构图我们可以看到,调度是工作在Master,负责调度Pod,为POD分配Node。
调度的工作原理
#查看所有的Node
kubectl get nodes

我们可以看到节点有一个Name,这就是调度的关键。
调度的步骤:
1 创建POD的时候每一个POD都会有一个叫NodeName的字段,默认情况下是不进行设置的。
2 调度器开始扫描POD,找到没有设置NodeName的POD,代表这它没有进行调度。
3 调度器通过运行调度算法为pod分配正确的节点。一旦确定节点,调度器会创建一个绑定对象binding,将NodeName设置为分配节点的名称,从而在该节点上调度pod。
如果没有调度器,我们可以在创建Pod的时候进行节点的指定:
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- image: nginx
name: nginx
nodeName: node01
#替换原有的资源,也就是会重新创建
kubectl replace --force -f nginx.yaml
那如果我们POD已经创建了,Kubernetes不允许修改pod的NodeName属性,这个时候我们可以通过下面这个方法进行修改:
1 创建一个Binding绑定对象,并向pod的绑定API发送一个POST请求,从而模仿实际调度程序的做法。
apiVersion: v1
kind: Binding
metadata:
name: nginx
target:
apiVersion: v1
kind: Node
name: ……
2 在绑定对象中,用NodeName指定一个目标节点,然后向pod的绑定API发送一个POST请求,将数据以JSON格式设置到绑定对象中(必须将YAML文件转换为等效的JSON形式)。也是就是说name这个字段需要填一个json数据。
上面这个方式比较复杂,所以工作中一般不使用,而使用下面这个方法,而是结合后面的元信息调度来控制.
元信息调度
Label & Selector
对Kubernetes来说,pod、 service、 replicaset、 deployment都是不同的对象。集群中可能会有成百上千个这样的对象。需要按不同类别筛选和查看对象的方法,例如按对象类型进行分组,或者按应用程序或功能查看,这样的操作都是通过Label来实现的。
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myapp-rs
labels: #ReplicaSet本身的Label
app: myapp
type: myservice
spec:
replicas: 3
selector:
matchLabels:
type: myservice #选择器匹配的Label,通过这个Label取选择对应的Pod
template:
metadata:
name: myapp-pod
labels:
app: myapp
type: myservice #模板的label 这个label要和上面选择器的label保持一致这样就可以选择到这个POD
spec:
containers:
- name: nginx
image: nginx
#查标签上有type=nginxservice 的pod
kubectl get po --selector type=nginxservice

我们查询到的结果如下:

#可以统计数量 看这个标签选中了多少pod
kubectl get po --selector type=nginxservice --no-headers | wc -l
kubectl get po --selector type=nginxservice | wc -l
#这些标签是and的关系
kubectl get po --selector type=nginxservice,app=nginxapp

Annotation
label与选择器用于编组与选择对象,而注释用于记录其他详细信息以提供信息。例如,如名称、 版本、 构建信息等
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myapp-rs
labels:
app: myapp
type: myservice
annotations:
buildVersion: 1.0
spec:
replicas: 3
selector:
matchLabels:
type: myservice
template:
metadata:
name: myapp-pod
labels:
app: myapp
type: myservice
spec:
containers:
- name: nginx
image: nginx
Taints污点 & Tolerations容忍度
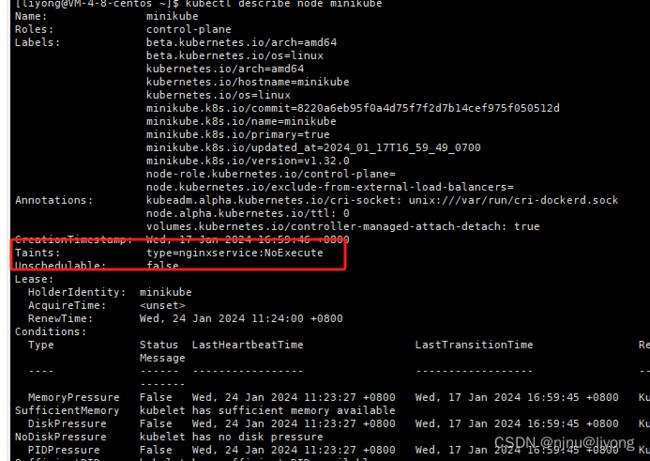
Taints污点和Tolerations容忍度的概念运用在如何限制将哪些Pod放置在哪些节点上,用于设置节点上可调度的pod的限制。
创建pod后,Kubernetes调度程序会尝试将这些pod放置在可用的工作节点上。一开始调度程序将pod放置在所有节点上,达到负载均衡。
现在,假设我们在node1上为特定用例或应用程序提供了专用资源(比如只有Node1安装了GPU 或者Node1有第三方依赖)。因此,我们希望仅将属于此应用程序的那些pod放置在node1上。
总结一下:
Taints污点 :这个是为Node 打上一个污点,打好了这个污点,如果POD上设置可以容忍这个污点,才能在这个Node上进行调度。
Node污点有三个策略:
- NoSchedule 无调度,这意味着node上不会调度Pod。
- PreferNoSchedule,这意味着系统将尝试避免在node上放置Pod,但并不保证。
- NoExecute不执行,这意味着新的pod将不会在node上调度,并且如果node上的现有pod(如果有的话)不能容忍taint,则将被逐出。
Tolerations容忍度:设置这个POD可以容忍某个污点,那么这个时候POD依然可以在污点的Node上进行调度。
实践
1 污点设置
#这个时候不会影响pod的运行 因为无调度
kubectl taint nodes minikube type=nginxservice:NoSchedule
#我们指定minikube 节点上 label中有type=nginxservice 的pod不能再这个节点运行
kubectl taint nodes minikube type=nginxservice:NoExecute
NoExecute的时候会发现所有的节点都被挂起了,这里myapp-deployment没有被驱逐使用为这个myapp-deployment是Deployment,它要保证有三个节点,两个策略产生了冲突,所以最终被挂起。

为了证明上面这一点,我们单独起一个Nginx Pod 并打上标签type=nginxservice
1)创建一个nginx pod
apiVersion: v1
kind: Pod
metadata:
name: testTaint
labels:
app: myapp
type: nginxservice
spec:
containers:
- name: nginx
image: nginx
2)依次执行命令
#创建一个pod
kubectl apply -f pod-ngix.yml
#打上污点
kubectl taint nodes minikube type=nginxservice:NoExecute
kubectl get pods
我们发现testtaint被驱逐了
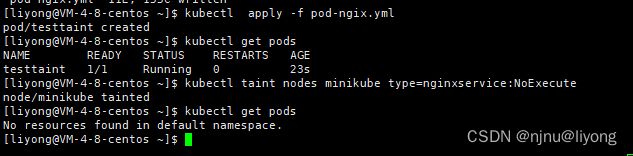
这里要注意单独的pod和deployment不同,单读的pod被驱即使后面这个污点去除了,这个pod也不一定马上就会回来继续运行
#移除这个污点
kubectl taint nodes minikube type=nginxservice:NoExecute-
我们发现这些节点又恢复了运行

2 容忍度设置
apiVersion: v1
kind: Pod
metadata:
name: terapp
spec:
containers:
- name: nginx
image: nginx
tolerations:
- key: "type"
operator: "Equal" #这些字段必须都是双引号
value: "nginxservice"
effect: "NoSchedule"
我们可以看到虽然节点上有污点,但是我们设置了可以容忍,所以这个节点仍然部署成功了

注意:生产中就算设置了这个容忍度也不一定会在这个节点上,因为调度算法不一定会把这个节点调度到这里,如果调度到了这里那么会按照容忍污点部署成功
Node Selector
#给Node 打一个size=Large的标签
kubectl label nodes node1 size=Large
在创建的时候使用NodeSelector进行选择
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
type: myservice
spec:
containers:
- name: nginx
image: nginx
nodeSelector:
size: Large
Node Affinity 节点亲和性

这两种策略都是如果容器在运行中忽略,也就是如果在运行中发生了节点关联性的修改则不会影响这个pod的运行,它会和以前一样继续运行
提供了更灵活的方式,来选择节点。
pod的生命周期中有两种状态:Scheduling调度期和Execution执行期
Scheduling调度期是指pod不存在,且是首次创建的状态。在首次创建pod时,kubernetes会考虑节点亲和规则
- required:调度程序将强制将pod放置在具有给定关联性规则的节点上。
- preferred:调度程序将尽力将pod放置在匹配的节点上。如果未找到匹配的节点,则调度程序将忽略节点关联性规则,并将单元放置在任何可用节点上
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
type: myservice
spec:
containers:
- name: nginx
image: nginx
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: size #节点标签
operator: In #代表节点标签在 下面这些values里面
values:
- Large
- MoreLarge
key: size
operator: NotIn #和上面等价 假如我们有三种标签 Large MoreLarge Small
values:
- Small
#针对只存在key 不存在值的标签
key: controlplane
operator: Exists
资源限制
前面我们学过命令空间的资源限制
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-quota
namespace: dev #指定限制的namespace
spec:
hard: #这里有两种模式 一种是硬性限制 另一种是软限制(可以超)
pods: "10" #限制pod数量最多是10个
requests.cpu: "4" #限制cpu申请的时候为4个
requests.memory: 5Gi #限制内存
limits.cpu: 10 #使用限制
limits.memory: 10Gi #使用限制
Pod的资源限制
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
type: myservice
spec:
containers:
- name: nginx
image: nginx
resources:
requests:
memory: "1Gi"
cpu: 1
limits:
memory: "2Gi"
cpu: 2
limit和request是为pod内的每个container设置的。
- requests:容器要申请的资源,要求Kubernetes在创建Pod的时候必须分配这里列出的资源,否则容器就无法运行。
- limits:容器使用资源的上限,不能超过设定值,否则就有可能被强制停止运行。
在调度的时候,scheduler 只会按照 requests 的值进行计算。而执行期间,在真正设置 Cgroups 限制的时候,kubelet 则会按照 limits 的值来进行设置。
DaemonSet 守护进程集
Deployment会创建多个POD实例,但是这些实例会被分配到不同的节点,有些Node可能存在多个POD实例。就比如下面图中绿色的节应用。

那如果现在需要在集群的每个节点部署一个监控或者日志收集器。这个时候就需要用到DaemonSet 。
DaemonSet 很多时候比整个 Kubernetes 集群出现的时机都要早。
apiVersion: apps/v1
kind: DaemonSet
metadata:
labels:
app: elasticsearch
name: elasticsearch
namespace: kube-system
spec:
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
spec:
containers:
- image: registry.k8s.io/fluentd-elasticsearch:1.20
name: fluentd-elasticsearch
tolerations:
- key: node-role.kubernetes.io/controlplane
effect: NoSchedule
operator: Exists
DaemonSet的设计上是每个节点上部署一个,但是control-plane的设计是控制节点不承担常规工作负载。二者存在冲突,Kubernetes使用了污点(taint)和容忍度(toleration)来避免。也就是这段配置
tolerations:
- key: node-role.kubernetes.io/controlplane
effect: NoSchedule
operator: Exists
Static Pod 静态Pod
资料来源
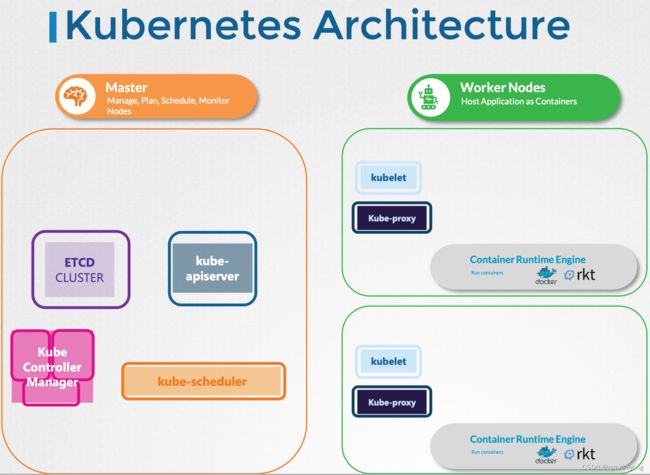
我们可以看到整个Kubernetes集群架构可以分为Master和Worker Master负责调度管理,Worker负责运行实例。
如果没有API-server,scheduler,controller和etcd集群会怎么样?
单独存在的Kubelet可以独立管理一个节点,并且创建Pod。但是没有API-server来提供pod详细信息。
Kubelet可以从所在服务器上指定用于存储Pod信息的目录中读取Pod定义文件。
静态Pod不受 Kubernetes 系统的管控,不与 apiserver、scheduler 发生关系,所以是static静态。
cat /var/lib/kubelet/config.yaml | grep staticPodPath
# staticPodPath: /etc/kubernetes/manifests
静态Pod的YAML文件默认都存放在节点的 /etc/kubernetes/manifests 目录下,它是 Kubernetes 的专用目录。Kubelet会定期检查此目录中的文件,读取这些文件并在主机上创建Pod。并且保持Pod在线;如果程序崩溃,Kubelet会尝试重新启动它。
也就是说我们可以定义pod的yml文件到这个目录下,这些pod就会被识别和创建
对此目录中的任何文件进行更改,Kubelet将重新创建Pod使更改生效。
如果从该目录中删除文件,则Pod将自动删除。
这些由Kubelet自行创建的pod(无需API服务器或其余Kubernetes集群组件的干预)被称为静态pod。
PS,只能以这种方式创建Pod。不能通过将定义文件放在指定目录中来创建replicaset、deployment或service。它们都是整个Kubernetes架构的概念组成部分,需要replica和deployment controller等其他集群组件。
Kubelet在pod级别工作,只能理解pod,只能够以这种方式创建静态pod。
指定的静态Pod文件夹可以是主机上的任何目录,该目录的位置在运行服务时作为一个选项传递kubelet。
/usr/local/bin/kubelet \
--container-runtime=remote \\
--container-runtime-endpoint=unix:///var/run/containerd/containerd.sock \\
--pod-manifest-path=/etc/Kubernetes/manifests \\ #指定静态pod文件所属的目录
--kubeconfig=/var/lib/kubelet/kubeconfig \\
--network-plugin=cni \\
--register-node=true \\
--v=2
另一种配置方法,可以修改config.yaml,并在该文件中将目录路径定义为静态pod路径。
cat /var/lib/kubelet/config.yaml | grep staticPodPath
为什么要使用静态Pod
静态Pod不依赖于Kubernetes控制平面,可以使用静态Pod将控制平面组件本身作为Pod部署在节点上。
在所有主节点上安装kubelet,然后创建pod定义文件,该文件使用各种控制平面组件的Docker镜像。
将定义文件放在指定的manifest文件夹中,Kubelet负责将控制平面组件本身作为pod部署到集群上。
ls -al /etc/kubernetes/manifests/
# -rw------- 1 root root 2376 Feb 19 00:23 etcd.yaml
# -rw------- 1 root root 3854 Feb 19 00:23 kube-apiserver.yaml
# -rw------- 1 root root 3370 Feb 19 00:23 kube-controller-manager.yaml
# -rw------- 1 root root 1440 Feb 19 00:23 kube-scheduler.yaml
Kubernetes 的 4 个核心组件 apiserver、etcd、scheduler、controller-manager 原来都以静态 Pod 的形式存在的,所以能够先于 Kubernetes 集群启动。
如果服务中的任何一个崩溃,kubelet会重新启动它。