HBase高可用架构涉及常用功能整理
文章目录
- 1. hbase的高可用系统架构和相关组件
- 2. hbase的核心参数
-
- 2.1 常规配置
- 2.2 HA配置
- 2.3 特殊优化配置
- 3. hbase常用命令
-
- 3.2 常用运维命令
- 4. 事务性
-
- 4.1 事务原子性的保证
- 4.2 写写并发控制
- 4.3 读写并发控制
- 5. 疑问和思考
-
- 5.1. hbase是如何实现故障容错的?
- 5.2 hbase不擅长处理哪些场景?
- 6. 参考文档
探讨hbase的系统架构以及以及整体常用的命令和系统分析,本文主要探讨高可用版本的hbase集群,并基于日常工作中的沉淀进行思考和整理。
1. hbase的高可用系统架构和相关组件
在hbase进行分布式系统架构选型时,使用了中心型的架构模式,整体架构跟hdfs类似,通过master节点来记录整体集群的元数据。 具体这种类型的数据结构,整体上可以参考hdfs
hbase的系统架构如下
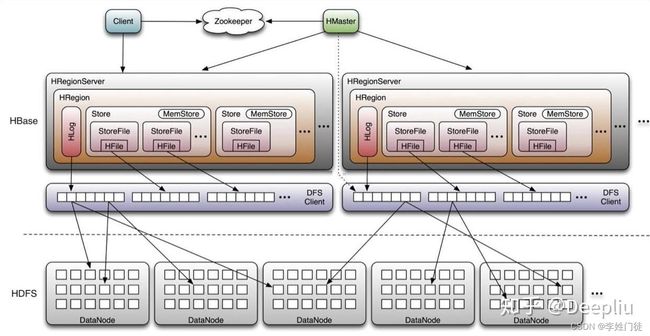

相关核心的组件和角色作用如下
| 组件 | 部署模式 | 组件作用 | 备注 |
|---|---|---|---|
| master(active) | 单机部署 | 存储集群的元数据,具体集群数据的全局视角 | 给客户端提供请求服务等,和standby节点进行形成主备 |
| master(standby) | 单机部署 | 存储集群的元数据,和active节点进行形成主备 | |
| zk | 多节点部署 | zk提供hbase的nn选主锁和消息通知,zkfc接受相关zk进行主从切换 | 通过Zab 协议来保证分布式事务的最终一致性 |
| region-server | 单机部署 | 数据的存储节点,会定期上报心跳和当前节点的block信息给master | 保存当前节点的region信息 |
2. hbase的核心参数
2.1 常规配置
hbase-site.xml配置
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed ...
-->
<configuration>
<!-- 配置HBASE临时目录 -->
<property>
<name>hbase.tmp.dir</name>
<value>/data/hbase</value>
</property>
<!-- HBase集群中所有RegionServer共享目录,用来持久化HBase的数据,一般设置的是hdfs的文件目录 -->
<!-- 将hdfs-site.xml和core-site.xml拷贝到hbase的配置文件目录,配合hdfs的hdfs-site.xml和core-site.xml一起使用 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://mycluster/hbase</value>
</property>
<!-- 定义hbase集群模式,true集群模式,false,单机模式 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 定义hbase的HMaster RPC端口,该端口用于HBase客户端连接到HMaster,默认16000,参数同 hbase.master -->
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<!-- 定义hbase的HMaster HTTPS端口。该端口用于远程Web客户端连接到HMaster UI,默认 16010 -->
<property>
<name>hbase.master.info.port</name>
<value>16010</value>
</property>
<!-- 定义hbase的RS (RegoinServer) RPC端口,该端口用于HBase客户端连接到RegionServer,默认 16020 -->
<property>
<name>hbase.regionserver.port</name>
<value>16020</value>
</property>
<!-- 定义hbase的Region server HTTPS端口。该端口用于远程Web客户端连接到RegionServer UI,默认 16030 -->
<property>
<name>hbase.regionserver.info.port</name>
<value>16030</value>
</property>
<!-- 定义hbase的zk链接ip -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>Master,Slave1,Slave2</value>
</property>
<!-- 定义hbase的zk链接端口 -->
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<!-- 定义hbase的zk存储位置,要与上述zookeeper安装过程中在zoo.cfg中配置的dataDir保持一致 -->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/yourname/zoodata</value>
</property>
<!-- 定义hbase使用本地文件系统设置为false,使用hdfs设置为true -->
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>true</value>
</property>
</configuration>
常用端口配置
| 配置参数 | 开源默认端口 | 端口说明 |
|---|---|---|
| hbase.master.port | 16000 | HMaster RPC端口。该端口用于HBase客户端连接到HMaster。说明:端口的取值范围为一个建议值,由产品自己指定。在代码中未做端口范围限制。安装时是否缺省启用:是安全加固后是否启用:是 |
| hbase.master.info.port | 16010 | HMaster HTTPS端口。该端口用于远程Web客户端连接到HMaster UI。说明:端口的取值范围为一个建议值,由产品自己指定。在代码中未做端口范围限制。安装时是否缺省启用:是安全加固后是否启用:是 |
| hbase.regionserver.port | 16020 | RS (RegoinServer) RPC端口。该端口用于HBase客户端连接到RegionServer。说明:端口的取值范围为一个建议值,由产品自己指定。在代码中未做端口范围限制。安装时是否缺省启用:是安全加固后是否启用:是 |
| hbase.regionserver.info.port | 16030 | Region server HTTPS端口。该端口用于远程Web客户端连接到RegionServer UI。说明:端口的取值范围为一个建议值,由产品自己指定。在代码中未做端口范围限制。安装时是否缺省启用:是安全加固后是否启用:是 |
| hbase.thrift.info.port | 9095 | Thrift Server的Thrift Server侦听端口。该端口用于:客户端链接时使用该端口侦听。说明:端口的取值范围为一个建议值,由产品自己指定。在代码中未做端口范围限制。安装时是否缺省启用:是安全加固后是否启用:是 |
| hbase.regionserver.thrift.port | 9090 | RegionServer的Thrift Server侦听端口 。该端口用于:客户端链接RegionServer时使用该端口侦听。说明:端口的取值范围为一个建议值,由产品自己指定。在代码中未做端口范围限制。安装时是否缺省启用:是安全加固后是否启用:是 |
| hbase.rest.info.port | 8085 | RegionServer RESTServer原生Web界面的端口 |
| - | 21309 | RegionServer RESTServer的REST端口 |
2.2 HA配置
zk中保存的路径,由于master进行ha切换
# master路径
get /hbase/master
# backup-masters路径
ls /hbase/backup-masters

hdfs中保存的hbase路径
hadoop fs -ls /hbase

2.3 特殊优化配置
文章已经做了比较详尽的解释,可以参考 文章
3. hbase常用命令
# 连接hbase,形成类似sql的控制台
hbase-shell
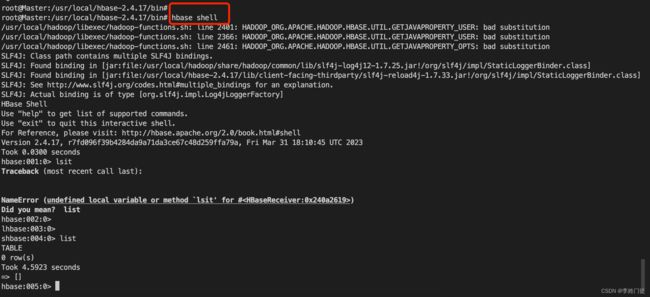
1)查看有哪些表
hbase(main)> list
2)创建表
语法: create <table>, {NAME => <family>, VERSIONS => <VERSIONS>}
例如:创建表t1,有两个family name:f1,f2,且版本数均为2
hbase(main)> create 't1',{NAME => 'f1', VERSIONS => 2},{NAME => 'f2', VERSIONS => 2}
3)删除表
分两步:1. disable,2. drop
例如:删除表t1
hbase(main)> disable 't1'
hbase(main)> drop 't1'
4)查看表的结构
语法:describe <table>
例如:查看表t1的结构
hbase(main)> describe 't1'
5)修改表结构
修改表结构必须先disable
语法:alter 't1', {NAME => 'f1'}, {NAME => 'f2', METHOD => 'delete'}
例如:修改表test1的cf的TTL为180天
hbase(main)> disable 'test1'
hbase(main)> alter 'test1',{NAME=>'body',TTL=>'15552000'},{NAME=>'meta', TTL=>'15552000'}
hbase(main)> enable 'test1'
3.2 常用运维命令
用于日常运维命令,便于进行服务运维,提升系统稳定性。
1, 集群启停
# 启动整个集群
./start-hbase.sh
# 关闭整个集群
./stop-hbase.sh
2, 启停单个节点
# 启停单个Master
./hbase-daemon.sh start master
./hbase-daemon.sh stop master
# 启停单个region-server
./hbase-daemon.sh start regionserver
./hbase-daemon.sh stop regionserver
3, 扩容增加regionserver
请根据安装hbase的步骤,安装一台节点,然后在所有的节点上的/etc/hosts中增加新增节点的ip与域名的映射。拷贝相关的安装包,并调整相关配置hbase-site.yml,然后启动region-server即可编辑/hbase所在目录/conf/regionservers 文件,增加新增节点,保持所有节点的同步更新。
# 启停单个regionserver
./hbase-daemon.sh start regionserver
./hbase-daemon.sh stop regionserver
4,下线单个region-server
下线某个region-server需要分2个步骤
4.1 停止对应的regionserver服务
编辑/hbase所在目录/conf/regionservers文件,删除要删除的节点。
# 在master 服务器上运行
./graceful_stop.sh xx.xx.xx.xx
进入要删除的节点,确认regionserver是否已经被关闭,如果没有关闭,请等待几分钟,如果还是没有关闭,请重新执行上述操作。或者再进行其他形式的删除。
4.2 执行数据重新平衡(在业务低峰期操作)
# 在master 服务器上运行
hbase shell
# 开启数据平衡
balance_switch true
4. 事务性
4.1 事务原子性的保证
HBase数据会首先写入WAL,再写入MemStore。写入MemStore出现异常时,很容易回滚,因此保证写入/更新原子性,只需要保证写入WAL的原子性即可。
当前版本WAL结构(之前的版本有区别,这里不讨论):
<logseq#-for-entire-txn>:, , >
每个事务只会产生一个WAL单元,以此来保证WAL写入的原子性。
WAL持久化策略:
- SKIP_WAL:表示不写WAL,这样写入更新性能最好,但在RegionServer宕机的时候有可能会丢失部分数据;
- ASYNC_WAL:表示异步将WAL持久化到硬盘,因为是异步操作所以在异常的情况下也有可能丢失少量数据;
- SYNC_WAL:表示同步将WAL持久化到操作系统缓存,再由操作系统将数据异步持久化到磁盘,这种场景下RS宕掉并不会丢失数据,当操作系统宕掉会导致部分数据丢失;
- FSYNC_WAL:表示WAL写入之后立马落盘,性能相对最差。
用户可以根据业务对数据丢失的敏感性在客户端配置相应的持久化策略,持久化策略由客户端来决定
4.2 写写并发控制
多个写入/更新同时进行会导致数据不一致的问题,HBase通过获取行锁来实现写写并发,如果获取不到,就需要不断重试等待或者自旋等待,直至其他线程释放该锁。拿到锁之后开始写入数据,写入完成之后释放行锁即可。这种行锁机制是实现写写并发控制最常用的手段,MySQL也使用了行锁来实现写写并发。
HBase支持批量写入/更新,实现批量写入的并发控制也是使用行锁。但这里需要注意的是必须使用两阶段锁协议,步骤如下:
(1) 获取所有待写入/更新行记录的行锁。
(2) 开始执行写入/更新操作。
(3) 写入完成之后再统一释放所有行记录的行锁。
不能更新一行锁定(释放)一行,多个事务之间容易形成死锁。两阶段锁协议就是为了避免死锁,MySQL事务写写并发控制同样使用两阶段锁协议。
4.3 读写并发控制
读写之间也需要一种并发控制来保证读取的数据总能够保持一致性,读写并发不能通过加锁的方式,性能太差,采用的是MVCC机制(Mutil Version Concurrent Control)。HBase中MVCC机制实现主要分为两步:
(1) 为每一个写入/更新事务分配一个Region级别自增的序列号。
(2) 为每一个读请求分配一个已完成的最大写事务序列号。
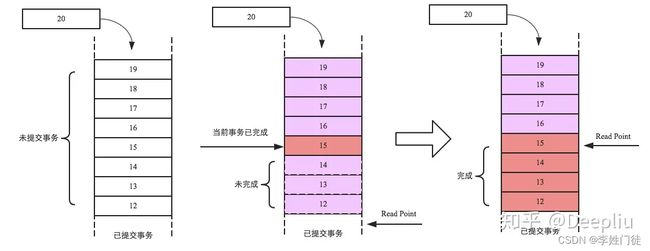
如下图所示:

图中两个写事务分别分配了序列号1和序列号2,读请求进来的时候事务1已经完成,事务2还未完成,因此分配事务1对应的序列号1给读请求。此时序列号1对本次读可见,序列号2对本次读不可见。
所有的事务都会生成一个Region级别的自增序列,并添加到队列中,如下图最左侧队列,其中最底端为已经提交的事务,队列中的事务为未提交事务。现假设当前事务编号为15,并且写入完成(中间队列红色框框),但之前的写入事务还未完成(序列号为12、13、14的事务还未完成),此时当前事务必须等待,而且对读并不可见,直至之前所有事务完成之后才会对读可见(即读请求才能读取到该事务写入的数据)。如最右侧图,15号事务之前的所有事务都成功完成,此时Read Point就会移动到15号事务处,表示15号事务之前的所有改动都可见。
5. 疑问和思考
5.1. hbase是如何实现故障容错的?
hbase是通过块副本机制实现故障容错的。
1, 冗余副本 + 机架感知
通过块打散的方式,提升块冗余能力,避免单机/机架故障导致整个hbase集群出现数据丢失
hbase的文件是通过块来分散在不同的dn节点进行存储,每个块默认设置多副本(一般是3副本),并且每个块会有checksum校验,dn会不断检测保存在当前节点的块的checksum是否跟预期的一致,如果发现不一致则认为当前块的数据完整性,会从其他dn的发起复制块。
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
Hadoop 默认的副本数为3,并且在机架的存放上也有一定的策略。Hadoop 的默认布局策略,即默认的副本存放策略如下:
(1)第 1 个副本存放在 HDFS 客户端所在的节点上。
(2)第 2 个副本存放在与第1个副本不同的机架上,并且是随机选择的节点。
(3)第 3 个副本存放在与第2个副本相同的机架上,并且是不同的节点。
2, 心跳机制 + 块复制
hbase的通过不断的自检测
通过不断的检测块副本情况,发起块复制的方式保证块满足副本要求
检测节点失效使用"心跳机制"。每个Datanode节点周期性地向Namenode发送心跳信号。网络分区可能导致一部分Datanode跟Namenode失去联系。 Namenode通过心跳信号的缺失来检测这一情况,并将这些近期不再发送心跳信号Datanode标记为宕机,不会再将新的IO请求发给它们。任何存储在宕机Datanode上的数据将不再有效。 Datanode的宕机可能会引起一些数据块的副本系数低于指定值,Namenode不断地检测这些需要复制的数据块,一旦发现就启动复制操作。
在下列情况下,可能需要重新复制:
- 某个Datanode节点失效
- 某个副本遭到损坏
- Datanode上的硬盘错误
- 文件的冗余因子增大。
5.2 hbase不擅长处理哪些场景?
hbase不删除处理大列簇,因此在设计上和使用上,建议写入hbase的表,单个列簇,单个列的长度不超过1M。
6. 参考文档
- 联邦-模式搭建指南
- HBase架构与原理详解