【面试深度解析】滴滴Java后端一面:JDK源码、RocketMQ分布式事务、布隆过滤器
欢迎关注公众号(通过文章导读关注:【11来了】),及时收到 AI 前沿项目工具及新技术的推送!在我后台回复 「资料」 可领取
编程高频电子书!
在我后台回复「面试」可领取硬核面试笔记!文章导读地址:点击查看文章导读!
感谢你的关注!
前言:
春招季即将来临,你准备好迎接挑战了吗?
【30天面试冲刺计划】 —— 专为大厂面试量身定制!
跟随学习,一起解锁面试新高度!

文章目录
- 滴滴后端一面分析:
-
- 题目分析
-
- 1、ArrayList 和 LinkedList 区别
- 2、为什么 LinkedList 的插入会比 ArrayList 插入效率高
- 3、HashMap 存在并发安全问题码?
- 4、说说头插法和尾插法
- 5、HashTable 怎么保证线程安全?
- 6、ConcurrentHashMap 如何保证线程安全?
- 7、RocketMQ 分布式事务怎么保证?
- 8、项目中使用 MQ 做了什么?
- 9、布隆过滤器了解吗?
- 10、布隆过滤器的元素能否删除
- 11、了解布谷鸟过滤器?
滴滴后端一面分析:
题目分析
1、ArrayList 和 LinkedList 区别
ArrayList 底层是基于 数组 实现的,而 LinkedList 底层是基于 双向链表 实现的 ,这里主要说一下数组和链表的一些区别即可,区别主要表现在访问、插入、删除这三个操作上:
- 对于插入元素和删除元素的性能来说
- LinkedList 要好一些,如果在头尾插入元素时间复杂度为 O(1),如果在指定位置插入元素,那么时间复杂度是 O(n)
- 而向 ArrayList 中间插入元素时,需要将后边的元素都向后移动一位,时间复杂度为 O(n)
- 是否支持快速访问
- ArrayList 可以根据下标快速访问元素,时间复杂度 O(1)
- LinkedList 不可以快速访问元素,需要遍历链表,时间复杂度 O(n)
综上,可以发现 LinkedList 和 ArrayList 相比,没有太大优势,一般在项目中不会使用 LinkedList
这里再说一下 ArrayList 的扩容机制:
ArrayList 底层是基于数组实现的,是动态数组,那么它的大小也是动态变化的,这里我说一下扩容的流程:
当添加元素时,发现容量不足,则对数组进行扩容,大小扩容为原来的 1.5 倍,int newCapacity = oldCapacity + (oldCapacity >> 1),通过位运算进行扩容后容量的计算(位运算比较快)
2、为什么 LinkedList 的插入会比 ArrayList 插入效率高
对于 LinkedList 来说,在头部和尾部插入的效率是比较高的,因为可以直接找到头尾节点
但是如果在中间插入的话,也是需要遍历链表找到中间位置的,因此插入的效率和 ArrayList 是差不多的,时间复杂度都是 O(n)
3、HashMap 存在并发安全问题码?
这里是直接考察 HashMap 存在的并发安全问题了,除此之外,你还要了解 HashMap 插入元素的流程,什么时候会扩容,什么时候链表会转为红黑树,这里主要说一下线程安全的问题:
HashMap 的问题就是存在并发安全的问题,这里就说 JDK1.8 的了,我觉得再去看 JDK1.7 的没有太大的意义,多个线程修改同一个 HashMap 所导致的线程不安全,在 put() 操作中,会造成线程不安全,那么我们看下边 putVal() 方法,来分析一下在哪里会造成线程不安全:
假如初始时,HashMap 为空,此时线程 A 进到 630 行的 if 判断,为 true,当线程 A 准备执行 631 行时,此时线程 B 进入在 630 行 if 判断发现也为 true,于是也进来了,在 631 行插入了节点,此时线程 B 执行完毕,线程 A 继续执行 631 行,就会出现线程 A 插入节点将线程 B 插入的节点覆盖的情况

那么简单说一下就是,HashMap 插入元素时,如果计算出来在数组中的下标,在该位置上没有发生哈希冲突,如果两个线程同时进来了,那么后边的线程就会把前边线程插入的元素给覆盖掉:

4、说说头插法和尾插法
头插法和尾插法指的是,在元素插入 HashMap 时,计算出来在数组中的下标,发现在这个下标的位置上已经有元素了,发生了哈希冲突,那么就会在冲突的元素给转成链表存储起来,用来解决哈希冲突
那么向链表中插入元素时,可以使用头插法和尾插法,JDK1.8 之前就是头插法,JDK1.8 的时候改为了尾插法
为什么 JDK1.8 之前要采用头插法呢?
JDK1.7 使用头插法的一种说法是,利用到了缓存的时间局部性,即最近访问过的数据,下次大概率还会进行访问,因此把刚刚访问的数据放在链表头,可以减少查询链表的次数
JDK1.7 中的头插法是存在问题的,在并发的情况下,插入元素导致扩容,在扩容时,会改变链表中元素原本的顺序,因此会导致链表成环的问题
那么 JDK1.8 之后改为了尾插法,保留了元素的插入顺序,在并发情况下就不会导致链表成环了,但是 HashMap 本来就不是线程安全的,如果需要保证线程安全,使用 ConcurrentHashMap 就好了!
5、HashTable 怎么保证线程安全?
上边说完了 HashMap 是线程不安全的,那么接下来深入问的话,一定会问拿些集合是线程安全的:HashTable 和 ConcurrentHashMap,而这位面试官也正是这么问的,一步一步深入,那么对于其他的一些面试问题也是类似,面试官不可能问完一个东西,立马转到另一个不相关的问题上去,而是针对一个东西,一点一点深入的去引导你,看你对他的理解程度
HashTable 通过 synchronized 关键字保证线程安全,但是在 HashTable 中,加锁的 粒度 是方法,那么就会导致并发度太低,有没有办法提升一下并发度呢?
接下来就要说 ConcurrentHashMap 了
6、ConcurrentHashMap 如何保证线程安全?
这里最重要的就是,了解 ConcurrentHashMap 在插入元素的时候,在哪里通过 CAS 和 synchronized 进行加锁了,是对什么进行加锁
对于 ConcurrentHashMap 来说:
- 在 JDK1.7 中,通过
分段锁来实现线程安全,将整个数组分成了多段(多个 Segment),在插入元素时,根据 hash 定位元素属于哪个段,对该段上锁即可 - 在 JDK1.8 中,通过
CAS + synchronized来实现线程安全,相比于分段锁,锁的粒度进一步降低,提高了并发度
这里说一下在 插入元素 的时候,如何做了线程安全的处理(JDK1.8):
在将节点往数组中存放的时候(没有哈希冲突),通过 CAS 操作进行存放
如果节点在数组中存放的位置有元素了,发生哈希冲突,则通过 synchronized 锁住这个位置上的第一个元素
那么面试官可能会问 ConcurrentHashMap 向数组中存放元素的流程,这里我给写一下(主要看一下插入元素时,在什么时候加锁了):
- 根据 key 计算出在数组中存放的索引
- 判断数组是否初始化过了
- 如果没有初始化,先对数组进行初始化操作,通过 CAS 操作设置数组的长度,如果设置成功,说明当前线程抢到了锁,当前线程对数组进行初始化
- 如果已经初始化过了,判断当前 key 在数组中的位置上是否已经存在元素了(是否哈希冲突)
- 如果当前位置上没有元素,则通过 CAS 将要插入的节点放到当前位置上
- 如果当前位置上有元素,则对已经存在的这个元素通过 synchronized 加锁,再去遍历链表,通过将元素插到链表尾
7、RocketMQ 分布式事务怎么保证?
一般问中间件相关的内容,一定是你简历中出现过的中间件,如果你简历中没有写,一般不会问的
但是对于 RocketMQ 来说,是比较常用的中间件,基本上默认都要掌握的,就算你不写,面试官也可能去问
接下来说一下 RocketMQ 如何实现了分布式事务:
分布式事务表示有两个服务 A 和 B,他们都有自己的数据库,A 和 B 通过 RocketMQ 进行通信,通信流程为 A 先操作自己的数据库,再发送消息给 MQ,B 去 MQ 监听消息,之后再操作自己的数据库
分布式事务就是保证 A 操作自己数据库和 B 操作自己数据库这两个操作要么同时成功,要么同时失败
RocketMQ 实现分布式事务中,有两个核心概念:半消息 和 消息回查
- 半消息(Half Message):表示暂存在 MQ 中,还不能投递给消费者的消息。发送方将消息先成功发送到 MQ 中,但是 MQ 没有收到生产者对这条消息的二次确认,此时这条消息被标记为 Half Message 状态
- 消息回查:如果因为网络原因,导致生产者发送给 MQ 的二次确认丢失,当 MQ 发现某条消息长期处理半消息(Half Message)的状态时,需要主动向生产者询问该消息的最终状态,要么 Commit,要么 Rollback
RocketMQ 实现分布式事务的流程:
- 生产者给 MQ 发送半消息
- MQ 持久化半消息成功后,向生产者发送确认
- 生产者执行本地事务
- 发送方根据本地事务执行结果,向 MQ 发送 Commit 或 Rollback 消息,如果本地事务执行成功,发送 Commit 消息,MQ 收到 Commit 消息后,将
半消息投递给消费者 - 如果因为网络原因,Commit 或 Rollback 消息丢失,MQ 会主动询问生产者半消息的状态
- 生产者收到 MQ 的询问后,查询本地事务状态,并发送给 MQ
- MQ 根据本地事务状态再次发送 Commit/Rollback 给 MQ

8、项目中使用 MQ 做了什么?
在面试的时候,讲项目要讲整个业务闭环讲清楚,以及引入中间件的需要和背景
每个人引入 MQ 的项目背景都是不一样的,但是 MQ 在项目中发挥的作用都是一样的
项目中引入 RocketMQ 的优点在于:
- 削峰填谷
- 异步优化
- 高扩展性
首先对于 削峰填谷,在 RocketMQ 中通过减少消费者的线程数或者限制消费者的消费能力来进行削峰,在系统低负载期间,通过增加消费者的线程数量来进行填谷,可以保证系统在运行期间,负载基本上处于一个稳定的状态,不会突然因为极高的负载而出现意外情况
其次是 异步优化,这是很关键的,比如在运营人员创建完促销活动之后,需要对用户进行活动的推送,那么这个推送是很消耗时间的,因此需要将推送的任务在创建促销活动中异步出去,将耗时任务从主流程中剥离出去慢慢执行,不影响主流程的执行时间
对于 高扩展性,在用户创建完订单之后,如果取消订单,在不使用 MQ 的情况下,需要在取消订单的逻辑中去一个一个执行取消订单后需要执行的操作,如下:
- 库存系统释放库存
- 返还用户积分
- 释放用户使用的优惠券
这样会导致取消订单的动作和其他业务耦合度很高,如果使用 MQ 之后,只需要在这三个地方关注订单取消的事件,不需要将取消订单中做很多耦合的操作
如果后续需要对取消订单做出调整,只用在订阅【取消订单】事件的位置修改代码即可
9、布隆过滤器了解吗?
说布隆过滤器之前,肯定要知道 BitMap 到底是什么
BitMap 到底用于解决什么问题?
BitMap 常常用于解决一些数据量比较大的问题,比如说对于1千万个整数,整数的范围在 1~100000000,对于一个整数 x ,我们怎么快速知道 x 在不在这1千万个整数中呢?
使用 BitMap 来解决的话,就把存在的整数的位置给设置为 true,比如 arr[k]=true,那么判断整数 x 是否在这1千万个整数中,只需要判断 arr[x] == true 即可。
那既然这样为什么不使用数组来标记呢?因为数组所占空间过大,会导致内存溢出。比如使用 int[] arr = new int[10];,在 java 中,一个 int 占用 4B,4B = 32bit,那如果使用 BitMap,使用 1 个 bit 来标记一个数,BitMap 的空间占用是数组的 1/32
Java 中 BitMap 如何实现了?
Java 中 hutool 工具包中实现了 BitMap,引入Maven依赖为:
<dependency>
<groupId>cn.hutoolgroupId>
<artifactId>hutool-allartifactId>
<version>5.8.0.M2version>
dependency>
Java 中有两种 bitmap,分别为 IntMap、LongMap,这里以 IntMap 为例:
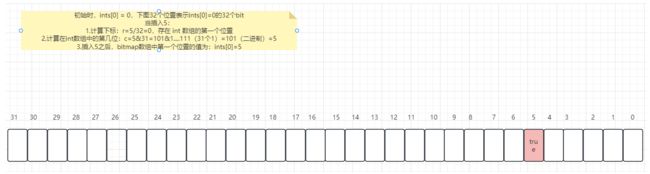
初始时,ints 数组即为 bitmap 数组,如果我们要向数组中添加 5,过程如下:
- 第一步:计算在数组中的下标,数组中一个 int 数有 32 位,可以存储 32 个标记,5 < 32,所以在第一个 int 数中存储,计算公式:
5 / 32 = 0 - 第二部:计算 5 在当前这个 int 数中存储的位置,也就是在当前这个 32 个位置中,处于第几个位置,所以和 31 进行与操作,31 也就是全1,通过和全1进行与操作就可以计算出位置,计算公式:
5 % 32 = 5
上边计算出来了下标为 0,在 0 个 int 数的第 5 个位置存储
图片解释如下:
public class IntMap implements BitMap, Serializable {
private static final long serialVersionUID = 1L;
private final int[] ints;
public IntMap() {
this.ints = new int[93750000];
}
public IntMap(int size) {
this.ints = new int[size];
}
public void add(long i) {
int r = (int)(i / 32L);
int c = (int)(i & 31L);
this.ints[r] |= 1 << c;
}
public boolean contains(long i) {
int r = (int)(i / 32L);
int c = (int)(i & 31L);
return (this.ints[r] >>> c & 1) == 1;
}
public void remove(long i) {
int r = (int)(i / 32L);
int c = (int)(i & 31L);
int[] var10000 = this.ints;
var10000[r] &= ~(1 << c);
}
}
BitMap总结:
- BitMap适合存储数据密集的数据,如果对于稀疏数据会造成空间浪费。
- 相比于其他数组更加节省空间
BitMap的一些适用场景:
- 统计指定用户一年中的登陆天数,哪几天登陆了,哪几天没有登陆?
- 判断用户的在线状态
- 统计活跃用户,使用时间作为缓存的key,用户id值为value中的偏移量,这一时间段如果活跃就设置为1
接下来看一下为什么有了 BitMap 之后,还需要使用布隆过滤器呢?
对于仅仅为整数的判断可以使用 BitMap 来进行实现,那么我们来考虑下边这个场景:
如果网站需要设置一个黑名单,url数量会上亿,我们怎么将不是整数的 url 给存储进 BitMap 中呢?存储在 BitMap 中的下标该如何计算呢?
对于这些复杂情况,就可以使用 Redis 的一种数据结构布隆过滤器,首先布隆过滤器的特点就是判断一个 url 的哈希值的位置,如果是1,则可能在集合中,但是如果不是1,则一定不在集合中。
这是为什么呢?
因为布隆过滤器使用了一组哈希函数,如果仅仅使用一个哈希函数,当 url 数量变多时,计算出来的哈希值冲突概率极高,假设使用的一组哈希函数为h1,h2,...hk,那么布隆过滤器会对一个 url 计算 k 次哈希值,得到 k 个哈希值,将 BitMap 中这 k 个位置都设置为1,那么在判断一个 url 是否存在时,判断这 k 个位置的值是否全部为1,如果有一个位置不为1,则表示该 url 并不在集合中。
布隆过滤器总结:
- 时间、空间效率高
- 误判率低,可以通过调整哈希函数数量和数组大小来控制误判率
- 支持并发
无法确定元素一定集合中!- 常用于作为一层程序拦截
10、布隆过滤器的元素能否删除
布隆过滤器中的元素是不支持删除的,因为布隆过滤器是通过将源数据进行映射到一个位置中,可能多个元素映射到同一个位置,删除 1 个元素的话,会导致其他元素也被删除
11、了解布谷鸟过滤器?
布谷鸟过滤器(Cuckoo Filter)也是是一种数据结构,相比于布隆过滤器来说,添加了可以删除元素的功能
下边说一个简单的例子,假设我们有一个包含四个槽位(桶)的布谷鸟过滤器,以及两个哈希函数 h1 和 h2,如果此时去向布谷鸟过滤器中添加一个元素 “A”,
- 初始化:首先,我们初始化四个槽位,所有槽位都是空的。
- 添加元素:
- 假设我们要添加元素 “A”。我们使用哈希函数 h1 和 h2 对 “A” 进行哈希,得到槽位位置 h1(“A”) 和 h2(“A”)。
- 如果这两个槽位都是空的,我们就将 “A” 放入这些槽位中。
- 如果 h1(“A”) 的槽位已经被占用,我们将原来的元素 “B” 踢出,将元素 “B” 通过 h2 哈希到另一个槽位。如果这个新槽位也是空的,我们就将 “B” 放入;如果不是,我们继续踢出原有的元素并重新哈希,直到找到一个空槽位。
- 查询元素:
- 要检查元素 “A” 是否存在,我们再次使用 h1 和 h2 对 “A” 进行哈希,检查对应的槽位是否有 “A”。
- 如果两个槽位中至少有一个有 “A”,我们认为 “A” 可能存在(因为存在误判的可能性)。
- 删除元素:
- 要删除元素 “A”,我们同样使用 h1 和 h2 对 “A” 进行哈希,找到对应的槽位。
- 如果槽位中有 “A”,我们将其移除,并将槽位标记为空。这个过程不需要踢出其他元素,因为删除操作不会影响其他元素的位置。
- 处理冲突:
- 在添加或删除过程中,如果连续尝试了一定次数(例如,迭代次数)后仍然找不到空槽位,我们认为发生了冲突,可能需要扩展过滤器的大小或者报告添加失败。
布谷鸟过滤器在需要频繁进行元素添加和删除的场景中特别有用,例如在缓存系统中,它可以帮助减少因缓存穿透和缓存击穿导致的数据库