ASCII、GBK与UTF-8的联系
背景
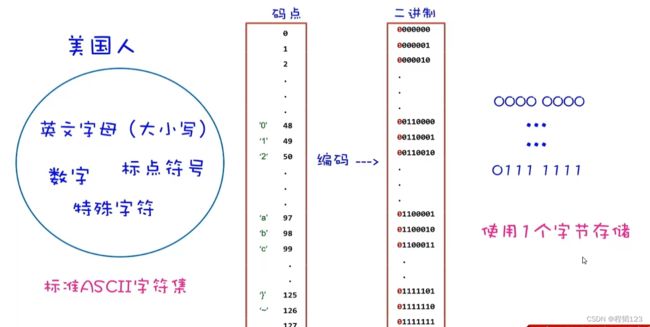
计算机是美国人发明的,美国人最初要往计算机存储数据的时候,那些数据往往只由英文字母(大小写)、数字、标点符号、特殊字符构成,总量被凑到128个。于是美国人就为这些字符编制了码点,一个字符对应一个码点,码点的范围是0~127。
于是计算机要存储的字符,会先转换为码点,码点存储在计算机中就以二进制的形式存在。由于码点用7个bit就可表示完整,于是首位bit统一设为0,一共占据了8个bit,也就是一个字节。
字符、码点、二进制数据的对应关系,也被叫做ASCII(American Standard Code for Information Interchange),美国信息交换标准代码。对于美国人来说完全够用了。
GBK
GBK,guojia biaozhun kuozhan。计算机传入中国之后,对于中国人来说,128个字符是完全不够用的,于是国家规定了汉字字符集,GBK便是其中一种。
GBK兼容了ASCII字符集的同时,还兼容了2万多个汉字,因此GBK的汉字字符集部分用2个字节存储码点。
GBK的汉字字符集对应的二进制数据除了占据2个字节,还以1开头。ascii码下的字符则保持原样。
举例:
我a你。在计算机中对应的二进制数据是:1xxxxxxx xxxxxxxx 0xxxxxxx 1xxxxxxx xxxxxxxx。
当把二进制数据转换为中文字符的之后,碰到1开头的数据,就知道要连着包括1在内的16个bit(2个字节)的数据一起转换为中文。
Unicode
Unicode,Universal Coded Character Set。是国际组织制定的,可以容纳全世界所有文字、符号的字符集。用32个bit(4个字节)表示一个字符,能完整覆盖全世界的文字与符号。
UTF-8
Unicode字符集的出发点是好的,但是太过奢侈,比如对于中文来说,用unicode的形式存储字符,每存储一个中文就比GBK多消耗2个字节。
为了解决存储空间开销过大的问题,国际组织基于unicode字符集,又推出了UTF-8字符集。·UTF-8字符集是unicode字符集分支而出的一种编码方案,采取可变长编码方案,共分四个长度区:1个字节,2个字节,3个字节,4个字节,按需而定。
英文字符、数字等,只占1个字节,汉字字符占用3个字节。
Utf-8的编码规则:

只占1个字节的字符,必须要以0开头。
占据2个字节的字符,第一个字节开头必须是110,第二个字节开头必须是10。
占据3个字节的字符,第一个字节开头必须是1110,第二、三个字节开头必须是10。
占据4个字节的字符,第一个字节开头必须是11110,第二、三、四个字节开头必须是10。
举例:
A我m,用utf-8编码,二进制数据如下:

乱码
以“a我m”字符串为例,存储的时候以utf-8编码,
存储为:01100001 1110xxxx 10xxxxxx 10xxxxxx 01101101
解码的时候以gbk解码:
1、计算机先分别把01100001、01101101解码为a和m,无错。
2、然后把1开头的字节解码为汉字,无法识别,无法匹配规则,产生乱码。
编码注意事项
开发人员尽量以utf-8编码。
数字和英文字符几乎不会乱码。
存储时的编码方式,和解码时候的编码方式,必须一致。
Utf-8和gbk字符串互相转码
思路:如果想把一个字符串从一种编码方式转为另一种编码方式,先转码为unicode,然后再从unicode转为另一种编码。
用python实现gbk字符转utf-8字符串:
# 定义一个以GBK编码的字符串
gbk_string = "中文字符串".encode('gbk')
# 将以GBK编码的字符串解码为Unicode字符串
unicode_string = gbk_string.decode('gbk')
# 将Unicode字符串编码为UTF-8
utf8_string = unicode_string.encode('utf-8')
# 输出UTF-8编码的字符串
print(utf8_string.decode('utf-8'))用python实现utf-8字符转gbk字符串:
# 定义一个以utf-8编码的字符串
utf8_string = "中文字符串".encode('utf-8')
# 将以utf-8编码的字符串解码为Unicode字符串
unicode_string = utf8_string.decode('utf-8')
# 将Unicode字符串编码为GBK
gbk_string = unicode_string.encode('gbk')
# 输出gbk编码的字符串
print(gbk_string.decode('gbk'))Utf-8和gbk的buf互相转码
字符串是以\0为结尾的,buf则是不以\0结尾,但是会告知有效长度。
比如【hello\0】这个字符串,替换成buf就是【hello】和5;
此处我们基于C语言完成。
首先创建一个gbk编码的文件:
echo "a中文内容b" | iconv -f UTF-8 -t GBK -o gbk.txt其次我们将这个文件读取并转为utf-8格式输出。思路是读取gbk文件之后,存储成一个字符串,但是我们给convertGBKtoUTF8传入的gbk字符串的buf和buf长度。在convertGBKtoUTF8函数内部对gbk字符串完成的转换存入了utf8字符串中。
#include
#include
#include
#include
char* readGBKFile(const char* filename) {
FILE* file = fopen(filename, "rb");
if (file == NULL) {
printf("无法打开文件 %s\n", filename);
return NULL;
}
// 获取文件大小
fseek(file, 0, SEEK_END);
long file_size = ftell(file);
rewind(file);
// 分配内存用于存储文件内容
char* buffer = (char*)malloc(file_size+1);
if (buffer == NULL) {
printf("内存分配失败\n");
fclose(file);
return NULL;
}
// 读取文件内容
size_t bytes_read = fread(buffer, 1, file_size, file);
buffer[bytes_read] = '\0';
if(buffer[bytes_read-1] == '\n' )buffer[bytes_read-1] = '\0';
fclose(file);
return buffer;
}
char* convertGBKtoUTF8(const char* gbkBuf,size_t gbkBuflen) {
size_t utf8Buflen = gbkBuflen * 3; // UTF-8最多需要3个字节表示一个字符
char* utf8Buf = (char*)malloc(utf8Buflen + 1);
if (utf8Buf == NULL) {
printf("内存分配失败\n");
return NULL;
}
memset(utf8Buf, 0, utf8Buflen + 1);
iconv_t cd = iconv_open("UTF-8", "GBK");
if (cd == (iconv_t)-1) {
printf("字符集转换初始化失败\n");
free(utf8Buf);
return NULL;
}
const char* inbuf = gbkBuf;
char* outbuf = utf8Buf;
size_t inbytesleft = gbkBuflen;
size_t outbytesleft = utf8Buflen;
if (iconv(cd, (char**)&inbuf, &inbytesleft, &outbuf, &outbytesleft) == (size_t)-1) {
printf("字符集转换失败\n");
free(utf8Buf);
iconv_close(cd);
return NULL;
}
iconv_close(cd);
return utf8Buf;
}
int main() {
const char* filename = "gbk.txt";
char* gbkString = readGBKFile(filename);
int gbkLength = 0;
if (gbkString != NULL) {
printf("gbkString:%s,gbkLength:%ld\n", gbkString,strlen(gbkString));
gbkLength = strlen(gbkString);
}
//
char* utf8String = convertGBKtoUTF8(gbkString,gbkLength);
if (utf8String != NULL) {
printf("UTF-8buf:%s,UTF-8buflen:%ld\n", utf8String,strlen(utf8String));
free(utf8String);
}
free(gbkString);
return 0;
} 最后我们查看输出结果
gbk编码输出的时候是乱码,utf-8编码输出的时候能正常显示,并且长度相应地增加了。
![]()
UTF8转GBK同理
#include
#include
#include
#include
#include
#include
#include
char* convertUTF8toGBK(const char* utf8Buf,size_t utf8Buflen) {
size_t gbkBuflen = (int)(utf8Buflen *2/3 + 1); // UTF-8最多需要3个字节表示一个字符
char* gbkBuf = (char*)malloc(gbkBuflen + 1);
if (gbkBuf == NULL) {
printf("内存分配失败\n");
return NULL;
}
memset(gbkBuf, 0, gbkBuflen + 1);
iconv_t cd = iconv_open("GBK","UTF-8");
if (cd == (iconv_t)-1) {
printf("字符集转换初始化失败\n");
free(gbkBuf);
return NULL;
}
const char* inbuf = utf8Buf;
char* outbuf = gbkBuf;
size_t inbytesleft = utf8Buflen;
size_t outbytesleft = gbkBuflen;
if (iconv(cd, (char**)&inbuf, &inbytesleft, &outbuf, &outbytesleft) == (size_t)-1) {
printf("字符集转换失败\n");
free(gbkBuf);
iconv_close(cd);
return NULL;
}
iconv_close(cd);
return gbkBuf;
}
int writeGBKStringToFile(const char* filename, const char* gbkString,int gbkBuflen) {
int file = open(filename, O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (file == -1) {
printf("无法打开文件\n");
return -1;
}
ssize_t bytesWritten = write(file, gbkString,gbkBuflen);
if (bytesWritten == -1) {
printf("写入文件失败: %s\n", strerror(errno));
close(file);
return -1;
}
close(file);
return 0;
}
int main() {
char* utf8String = "a字符集b";
int utf8Length = strlen(utf8String);
printf("utf8buf:%s,utf8buflen:%ld\n",utf8String,strlen(utf8String));
char* gbkString = convertUTF8toGBK(utf8String,utf8Length);
if (gbkString != NULL) {
printf("gbk8buf:%s,gbk8buflen:%ld\n",gbkString,strlen(gbkString));
int result = writeGBKStringToFile("gbk.txt", gbkString,strlen(gbkString));
if (result == 0) {
printf("GBK 字符串已成功写入文件\n");
}
free(gbkString);
}
return 0;
}