日志分析系统部署
由于公司的日志需要分析用户的行为,故做了一套从原始数据的分析,到入库,再到显示的基本动作
涉及组件有:FileBeat+Kafka+Python+InfluxDB+Grafana+Elasticsearch+kibana
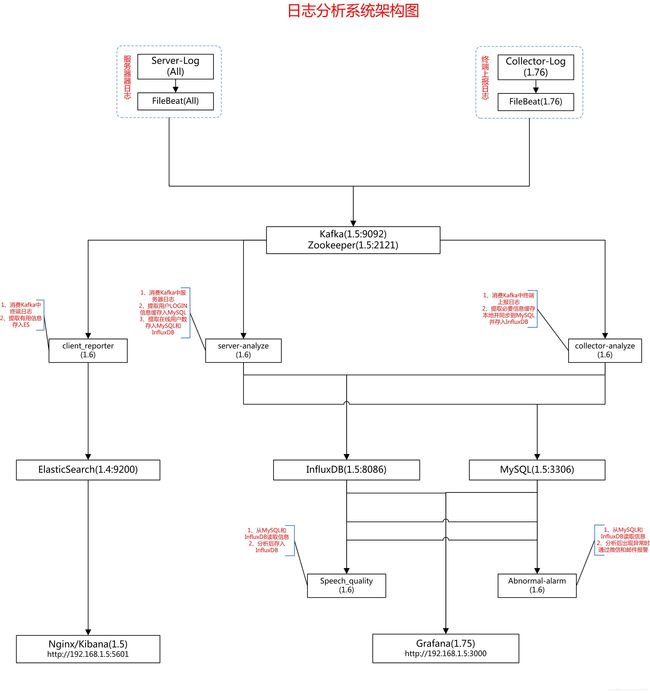
部署架构图
1. influxdb
安装:sudo dpkg -i influxdb_1.7.7_amd64.deb
启动:sudo service influxdb start
重启:sudo service influxdb restart
配置:
sudo vi /etc/influxdb/influxdb.conf
打开并修改:
max-series-per-database = 0
max-values-per-tag = 0
登录:influx
show database
create database db_collector
use db_collector
CREATE USER admin WITH PASSWORD 'admin' ## 创建用户和设置密码
GRANT ALL PRIVILEGES ON db_collector TO admin ## 授权数据库给指定用户
CREATE RETENTION POLICY "cadvisor_retention" ON "db_collector" DURATION 7d REPLICATION 1 DEFAULT
## 创建默认的数据保留策略,设置保存时间10天,副本为1
python依赖:
sudo pip install influxdb
常用语句:
drop measurement NetStat #删除表
select * from NetStat #查询
2. MySQL安装
sudo apt-get update
服务端:sudo apt-get install mysql-server #出现图:设置密码、然后再重新输入密码,确定即可 password: root
客户端:sudo apt-get install mysql-client
MySQL库:sudo apt-get install libmysqlclient-dev
检查:sudo netstat -tap | grep mysql
创建
create database db_collector;
use db_collector;
create table tb_baseinfo (id int(11) unsigned not null auto_increment, uid int(11) not null unique, type varchar(32), addr varchar(32), pocVersion varchar(64), update_time datetime not null default current_timestamp on update current_timestamp, primary key(id));
3. grafana安装
安装:sudo dpkg -i grafana_6.2.5_amd64.deb
启动:sudo /bin/systemctl start grafana-server
注:进入/usr/share/grafana/conf查看相关配置信息
访问:127.0.0.1:3000 user:admin password:admin
4.python其他依赖
sudo pip install arrow
sudo pip install pykafka
sudo pip install mysql
sudo pip install python-daemon
sudo pip install mysql_connector_python
5. JDK安装
sudo tar xvf jdk-8u221-linux-x64.tar.gz -C /usr/local/java
sudo vi ~/.bashrc 最后添加:
export JAVA_HOME=/usr/local/java/jdk1.8.0_221
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$JAVA_HOME/bin:$PATH
sudo source ~/.bashrc
检测:java -version
6. kafka安装
sudo tar -zxf kafka_2.12-2.3.0.tgz -C /usr/local
cd /usr/local
sudo mv kafka_2.12-2.3.0 kafka
启动zookeeper
nohup bin/zookeeper-server-start.sh config/zookeeper.properties 1>/dev/null 2>&1 &
启动Kafka服务端
nohup bin/kafka-server-start.sh config/server.properties 1>/dev/null 2>&1 &
验证:
以上都不要关闭,创建topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
#这个topic叫test,2181是zookeeper默认的端口号,partition是topic里面的分区数,replication-factor是备份的数量,在kafka集群中使用,这里单机版就不用备份了
bin/kafka-topics.sh --alter --zookeeper localhost:2181 --topic test --partitions 2
#修改partitions分区数个数可以供多个个consumer获取数据
#如果2个分区,同时有两个程序消费kafka(topic和consumer_group相同)数据时,kafka会把数据分成2份,分别发送给两个程序
#如果2个分区,同时有三个程序消费kafka(topic和consumer_group相同)数据时,kafka会把数据分成2份,分别发送给两个程序,其中一个程序处于空闲状态
#如果2个分区,只有一个程序消费kafka数据时,kafka会把数据分成2份,同时发送给一个程序
查看创建的主题
bin/kafka-topics.sh --list --zookeeper localhost:2181
删除topic
bin/kafka-topics.sh --delete --zookeeper localhost:2181 --topic test
producer生产数据
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
shell:输入数据
consumer来接收数据
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test #--from-beginning #从开始获取数据
shell:可以看到刚才的数据
配置:
sudo vi config/consumer.properties 增加:max.partition.fetch.bytes=200000000
sudo vi server/consumer.properties
修改:log.retention.hours=72
增加:message.max.bytes=100000000
7. flume安装
sudo tar xvf apache-flume-1.9.0-bin.tar.gz -C /usr/local/
cd /usr/local
sudo mv apache-flume-1.9.0-bin flume
cd /usr/local/flume
配置:
sudo vi conf/flume-conf.properties #创建文件并添加如下信息
agent.sources = s1
agent.channels = c1
agent.sinks = k1
agent.sources.s1.type = exec
agent.sources.s1.command = tail -F /home/hanbo/test.json #搜集的文件路径
agent.sources.s1.channels = c1
agent.channels.c1.type = memory
agent.channels.c1.capacity = 10000
agent.channels.c1.transactionCapacity = 100
#设置Kafka接收器
agent.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
#设置Kafka的broker地址和端口号
agent.sinks.k1.brokerList = 127.0.0.1:9092
#设置Kafka的Topic
agent.sinks.k1.topic = test
#设置序列化方式
agent.sinks.k1.serializer.class = kafka.serializer.StringEncoder
agent.sinks.k1.channel = c1
启动:nohup bin/flume-ng agent -n agent -c conf -f conf/flume-conf.properties -Dflume.root.logger=INFO,console 1>/dev/null 2>&1 &
8.filebeat安装
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.2.0-linux-x86_64.tar.gz # 根据自己的需要安装版本
tar xf filebeat-7.2.0-linux-x86_64.tar.gz
cd filebeat-7.2.0-linux-x86_64
修改配置文件 filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /home/hanbo/test.json #搜集的文件路径
include_lines: ['^{"Context"'] #只搜集开头包含 {"Context" 的数据
exclude_lines: ['^{"ERROR"] #去除掉开头 的数据 {"ERROR"
output.kafka:
hosts: ["192.168.1.6:9092"]
topic: "test"
codec.format:
string: '%{[message]}'
required_acks: 1
max_message_bytes: 100000000
注:缩进完全按照本格式,需要解析output.kafka 的地址转换成hostname,即修改/etc/hosts文件。
vi /etc/hosts
192.168.1.6 i-62yanb6v # 为主机名
启动filebeat:
nohup ./filebeat -e -c /root/tools/filebeat-7.1.1-linux-x86_64/filebeat.yml -d test > /dev/null &
9.Elasticsearch
安装:
1. tar xvf elasticsearch-5.0.0.tar.gz -C /usr/local/
2. cd /usr/local
3. chown -R hanbo(用户名):root /usr/local/elasticsearch-5.0.0
4. cd elasticsearch-5.0.0
修改局域网访问:
sudo vi config/elasticsearch.yml
增加:network.host: 0.0.0.0
启动:sudo ./bin/elasticsearch -d(后台启动)
检查启动:netstat -anp | grep 9200
10.Kibana
安装:
1. tar xvf kibana-5.0.0-linux-x86_64.tar.gz -C /usr/local
2. cd /usr/local
3. mv kibana-5.0.0-linux-x86_64 kibana-5.0.0
4. chown -R hanbo(用户名) /usr/local/kibana-5.0.0(不建议root启动)
5. cd kibana-5.0.0
启动:nohup ./bin/kibana 1>/dev/null 2>&1 &
访问:127.0.0.1:5601
附:
redis安装
tar xvf redis-5.0.5.tar.gz
cd redis-5.0.5
make
sudo make install
启动:redis-server
客户端:redis-cli
config set stop-writes-on-bgsave-error no #解决不能硬盘上持久化
python依赖:
sudo pip install redis
注意:
当程序和这些组件之间通讯获取不到数据,ping能通,需要添加解析对方地址转换成hostname,即修改/etc/hosts文件。
vi /etc/hosts
192.168.1.6 i-62yanb6v # 为主机名
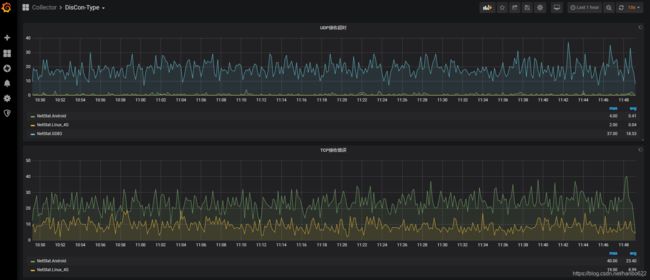
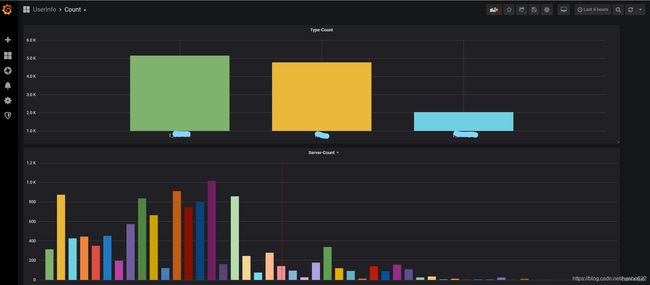
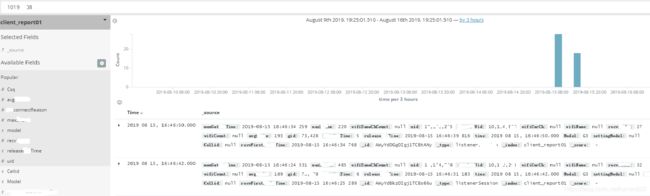
效果图