Python爬虫爬取热门电影及其购票链接和简介
安装BeautifulSoup以及requests
打开window 的cmd窗口输入命令pip install requests 执行安装,等待他安装完成就可以了
BeautifulSoup库也是同样的方法
BeautifulSoup库的具体使用方法:https://cuiqingcai.com/1319.html
requests库的具体使用方法:https://blog.csdn.net/weixin_36279318/article/details/79442629
其他工具: Chrome浏览器
Python版本: Python3.6
运行平台: Windows
1、首先我们搜索猫眼电影打开热门电影:https://maoyan.com/films

获取网页的代码:
def getHTMLText(url,k):
try:
if(k==0):
a={}
else:
a={'offset':k}
r = requests.get(url,params=a,headers={'User-Agent': 'Mozilla/4.0'})
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print("Failed!")经过观察其中因为每一页的网址其offset都不相同,故只要改变offset=k便可获取每一页的信息

获取网页每一张的海报,我采用了正则匹配获取了每一张图片的链接,通过urlretrieve函数把图片下载到指定的目录并编号:
def getImg(html):
reg = r'data-src="(.*)"'
imgre = re.compile(reg)
imglist2 = re.findall(imgre,html)
#print(imglist2)
global x
imgurl=[]
namelist=[]
path = 'E:\\test'
if not os.path.isdir(path):
os.makedirs(path)
paths = path+'\\'
for imgurls in imglist2:
urllib.request.urlretrieve(imgurls,'{0}{1}.jpg'.format(paths,x))
x=x+1
return imgurl用Beautifulsoup获取标签,把特惠选座的以及电影简介的链接获取后通过字符串拼接成完整的链接后,存入字典中
def getname(html):
global page #通过global把字典定义成全局
global jianjie
soup = BeautifulSoup(html, "html.parser")
movname = soup.find_all(class_='channel-detail movie-item-title')
movitem = soup.find_all(class_='movie-item')
#print(type(movitem))
#print(movitem)
for i in movitem:
for i1 in i.find_all('a'):
try:
ac.append('http://maoyan.com'+i1['href'])
except Exception as e:
continue
lenth = len(movname)
for j in movitem:
for i2 in j.find_all('a'):
try:
c=i2['data-val'].replace('{','').replace('}','').replace('movieid:','movieId=')
ai.append('http://maoyan.com/cinemas?'+c)
except Exception as e:
continue
for i in range(lenth):
mov.append(movname[i].attrs['title'])
file= open('F:/Python/dianying/dianying.doc', 'a')
for i,j in zip(mov,ac):
file.writelines(mode.format(i,j,chr(12288)))
file.writelines('\n')
file.close
jianjie=dict(zip(mov,ac))
page=dict(zip(mov,ai))
for key,v in page.items():
print(mode.format(key,v,chr(12288)))最后采用input,可以通过输入想看的电影名称来获取特惠选座的链接。
若需要查看简介,即会输出电影简介的链接并自动打开该网页
def main():
basicurl='http://maoyan.com/films'
k=0
print(mode.format('电影名称','特惠选座链接'))
while k<=100:
html=getHTMLText(basicurl,k)
#getImg(html)
getname(html)
k+=30
n1=input('请输入电影名称:')
for key,v in page.items():
if(n1==key):
print(v)
n2=input('是否查看简介:')
if(n2=='是'):
print(jianjie[n1])
webbrowser.open(jianjie[n1])
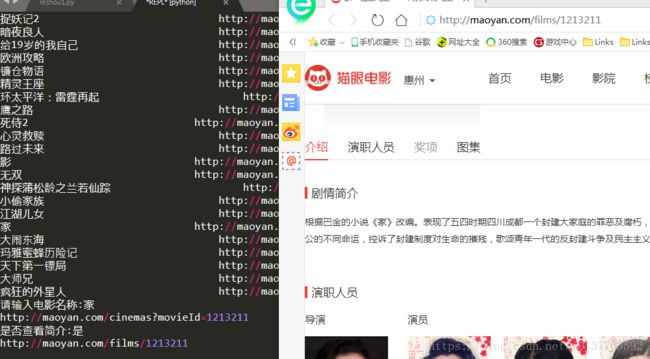
main()代码运行的结果如下图:
因输出的内容较多,所以截取一部分(可改变main()中的k值来改变输出电影的部数)


输入电影名称:
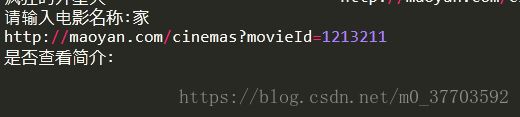
输入“是”查看简介:
以下为完整代码:
#coding:utf-8
import requests
from bs4 import BeautifulSoup
import re
import urllib.request
import os
import webbrowser
def getHTMLText(url,k):
try:
if(k==0):
a={}
else:
a={'offset':k}
r = requests.get(url,params=a,headers={'User-Agent': 'Mozilla/4.0'})
r.encoding = r.apparent_encoding
return r.text
except:
print("Failed!")
ac=[]
mov=[]
ai=[]
x=0
mode= "{0:<30}\t{1:^30}"
def getname(html):
global page
global jianjie
soup = BeautifulSoup(html, "html.parser")
movname = soup.find_all(class_='channel-detail movie-item-title')
movitem = soup.find_all(class_='movie-item')
#print(type(movitem))
#print(movitem)
for i in movitem:
for i1 in i.find_all('a'):
try:
ac.append('http://maoyan.com'+i1['href'])
except Exception as e:
continue
lenth = len(movname)
for j in movitem:
for i2 in j.find_all('a'):
try:
c=i2['data-val'].replace('{','').replace('}','').replace('movieid:','movieId=')
ai.append('http://maoyan.com/cinemas?'+c)
except Exception as e:
continue
for i in range(lenth):
mov.append(movname[i].attrs['title'])
file= open('F:/Python/dianying/dianying.doc', 'a')
for i,j in zip(mov,ac):
file.writelines(mode.format(i,j,chr(12288)))
file.writelines('\n')
file.close
jianjie=dict(zip(mov,ac))
page=dict(zip(mov,ai))
for key,v in page.items():
print(mode.format(key,v,chr(12288)))
def getImg(html):
reg = r'data-src="(.*)"'
imgre = re.compile(reg)
imglist2 = re.findall(imgre,html)
#print(imglist2)
global x
imgurl=[]
namelist=[]
path = 'E:\\test'
if not os.path.isdir(path):
os.makedirs(path)
paths = path+'\\'
for imgurls in imglist2:
urllib.request.urlretrieve(imgurls,'{0}{1}.jpg'.format(paths,x))
x=x+1
return imgurl
def main():
basicurl='http://maoyan.com/films'
k=0
print(mode.format('电影名称','特惠选座链接'))
while k<=100:
html=getHTMLText(basicurl,k)
#getImg(html)
getname(html)
k+=30
n1=input('请输入电影名称:')
for key,v in page.items():
if(n1==key):
print(v)
n2=input('是否查看简介:')
if(n2=='是'):
print(jianjie[n1])
webbrowser.open(jianjie[n1])
main()