Hive3.1.3基础学习
文章目录
- 一、Hive入门与安装
-
- 1、Hive入门
-
- 1.1 简介
- 1.2 Hive架构原理
- 2、Hive安装
-
- 2.1 安装地址
- 2.2 Hive最小化安装(测试用)
- 2.3 MySQL安装
- 2.4 配置Hive元数据存储到MySQL
- 2.5 Hive服务部署
- 2.6 Hive服务启动脚本(了解)
- 3、Hive使用技巧
-
- 3.1 Hive常用交互命令
- 3.2 Hive参数配置方式
- 3.3 Hive常见属性配置
- 二、DDL\&DML语句
-
- 1、DDL(Data Definition Language)数据定义
-
- 1.1 数据库
- 1.2 表(table)创建
- 1.3 表的增删查改
- 2、DML(Data Manipulation Language)数据操作
-
- 2.1 Load
- 2.2 Insert
- 2.3 Export\&Import
- 三、查询
-
- 1、基础语法
- 2、基本查询(Select…From)
-
- 2.1 数据准备
- 2.2 基本查询操作
- 2.3 关系运算函数
- 2.4 逻辑运算函数
- 2.5 聚合函数
- 3、分组
-
- 3.1 Group By语句
- 3.2 Having语句
- 4、Join语句
- 5、排序
-
- 5.1 全局排序(Order By)
- 5.2 每个Reduce内部排序(Sort By)
- 5.3 分区(Distribute By)
- 5.4 分区排序(Cluster By)
- 6、函数
-
- 6.1 简介
- 6.2 单行函数
- 6.3 高级聚合函数
- 6.4 炸裂函数
- 6.5 窗口函数(开窗函数)
- 7、自定义函数
-
- 7.1 介绍
- 7.2 自定义UDF函数
- 四、分区、分桶表和文件
-
- 1、分区表
-
- 1.1 分区表基本语法
- 1.2 二级分区表
- 1.3 动态分区
- 2、分桶表
-
- 2.1 概述
- 2.2 分桶表基本语法
- 2.3 分桶排序表
- 3、Hive文件格式
-
- 3.1 Text File
- 3.2 ORC
- 3.3 parquet
- 4、压缩
-
- 4.1 Hive表数据进行压缩
- 4.2 计算过程中使用压缩
- 五、企业级调优
-
- 1、计算资源配置
-
- 1.1 Yarn资源配置
- 1.2 MapReduce资源配置
- 2、测试用表
- 3、Explain查看执行计划(重点)
-
- 3.1 Explain执行计划概述
- 3.2 基本用法
- 4、 HQL之分组聚合优化
-
- 4.1 优化说明
- 5、HQL之Join优化
-
- 5.1 Join算法概述
- 5.2 Map Join
- 5.3 Bucket Map Join
- 5.4 Sort Merge Bucket Map Join
- 6、HQL之数据倾斜
-
- 6.1 数据倾斜概述
- 6.2 分组聚合导致的数据倾斜
- 6.3 Join导致的数据倾斜
- 7、HQL之任务并行度
-
- 7.1 Map端并行度
- 7.2 Reduce端并行度
- 8、HQL之小文件合并
-
- 8.1 Map端输入文件合并
- 8.2 Reduce输出文件合并
- 9、其他优化
-
- 9.1 CBO优化
- 9.2 谓词下推
- 9.3 矢量化查询
- 9.4 Fetch抓取
- 9.5 本地模式
- 9.6 并行执行
- 9.7 严格模式
- 六、实战案例
-
- 1、同时在线人数问题
- 2、会话划分问题
- 3、间断连续登录用户问题
- 4、日期交叉问题
一、Hive入门与安装
1、Hive入门
1.1 简介
Hive是由Facebook开源,基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能
Hive是一个Hadoop客户端,用于将HQL(Hive SQL)转化成MapReduce程序
- Hive中每张表的数据存储在HDFS
- Hive分析数据底层的实现是MapReduce(也可配置为Spark或者Tez)
- 执行程序运行在Yarn上
1.2 Hive架构原理
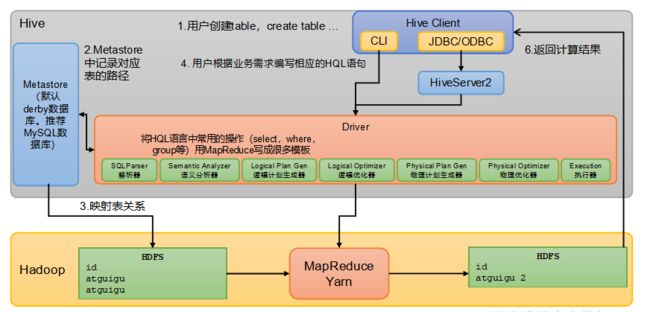
用户接口:Client
JDBC的移植性比ODBC好;(通常情况下,安装完ODBC驱动程序之后,还需要经过确定的配置才能够应用。而不相同的配置在不相同数据库服务器之间不能够通用。所以,安装一次就需要再配置一次。JDBC只需要选取适当的JDBC数据库驱动程序,就不需要额外的配置。在安装过程中,JDBC数据库驱动程序会自己完成有关的配置。)两者使用的语言不同,JDBC在Java编程时使用,ODBC一般在C/C++编程时使用
元数据:Metastore
元数据包括:数据库(默认是default)、表名、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等。默认存储在自带的derby数据库中,由于derby数据库只支持单客户端访问,生产环境中为了多人开发,推荐使用MySQL存储Metastore
驱动器:Driver
- 解析器(SQLParser):将SQL字符串转换成抽象语法树(AST)
- 语义分析(Semantic Analyzer):将AST进一步划分为QeuryBlock
- 逻辑计划生成器(Logical Plan Gen):将语法树生成逻辑计划
- 逻辑优化器(Logical Optimizer):对逻辑计划进行优化
- 物理计划生成器(Physical Plan Gen):根据优化后的逻辑计划生成物理计划
- 物理优化器(Physical Optimizer):对物理计划进行优化
- 执行器(Execution):执行该计划,得到查询结果并返回给客户端
2、Hive安装
2.1 安装地址
Hive官网地址:http://hive.apache.org/
文档查看地址:https://cwiki.apache.org/confluence/display/Hive/GettingStarted
下载地址:http://archive.apache.org/dist/hive/
github地址:https://github.com/apache/hive
2.2 Hive最小化安装(测试用)
# 本文章前请先学习hadoop
# myhadoop.sh start 首先开启集群hadoop
# jpsall
wget http://archive.apache.org/dist/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
# 解压apache-hive-3.1.3-bin.tar.gz到/opt/module/目录下面
tar -zxvf apache-hive-3.1.3-bin.tar.gz -C /opt/module/
cd /opt/module/
mv /opt/module/apache-hive-3.1.3-bin/ /opt/module/hive
# 修改/etc/profile.d/my_env.sh,添加环境变量
sudo vim /etc/profile.d/my_env.sh
#HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin
source /etc/profile.d/my_env.sh
# 初始化元数据库(默认是derby数据库)
bin/schematool -dbType derby -initSchema
# 这里启动可能会报错这是因为hadoop和hive的两个guava.jar版本不一致
# 需要将hadoop的高版本guava来代替hive中的jar包
mv lib/guava-19.0.jar lib/guava-19.0.jar.bak
cp /opt/ha/hadoop-3.1.3/share/hadoop/common/lib/guava-27.0-jre.jar /opt/module/hive/lib/guava-27.0-jre.jar
# 启动Hive,只能使用命令行
bin/hive
# 使用Hive
hive> show databases;
hive> show tables;
hive> create table stu(id int, name string);
hive> insert into stu values(1,"ss");
hive> select * from stu;
# Hive中的表在Hadoop中是目录;Hive中的数据在Hadoop中是文件
# 在Xshell窗口中开启另一个窗口开启Hive,在/tmp/atguigu目录下监控hive.log文件
tail -f hive.log
# 原因在于Hive默认使用的元数据库为derby。derby数据库的特点是同一时间只允许一个客户端访问。如果多个Hive客户端同时访问,就会报错
# 我们可以将Hive的元数据改为用MySQL存储,MySQL支持多客户端同时访问
# 首先退出hive客户端。然后在Hive的安装目录下将derby.log和metastore_db删除,顺便将HDFS上目录删除
hive> quit;
rm -rf derby.log metastore_db
# 删除HDFS中/user/hive/warehouse/stu中数据
hadoop fs -rm -r /user
2.3 MySQL安装
# 下载mysql,离线安装
wget https://downloads.mysql.com/archives/get/p/23/file/mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar
# 解压MySQL安装包
mkdir /opt/software/mysql_lib
tar -xf mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar -C /opt/software/mysql_lib
# 卸载系统自带的mariadb
sudo rpm -qa | grep mariadb | xargs sudo rpm -e --nodeps
# 安装MySQL依赖
cd mysql_lib
sudo rpm -ivh mysql-community-common-5.7.28-1.el7.x86_64.rpm
sudo rpm -ivh mysql-community-libs-5.7.28-1.el7.x86_64.rpm
sudo rpm -ivh mysql-community-libs-compat-5.7.28-1.el7.x86_64.rpm
# 安装mysql-client
sudo rpm -ivh mysql-community-client-5.7.28-1.el7.x86_64.rpm
# 安装mysql-server
sudo rpm -ivh mysql-community-server-5.7.28-1.el7.x86_64.rpm
# 若出现以下错误sudo yum -y install libaio
# 启动MySQL
sudo systemctl start mysqld
# 查看MySQL密码
sudo cat /var/log/mysqld.log | grep password
# =====================配置MySQL=======================
# 配置主要是root用户 + 密码,在任何主机上都能登录MySQL数据库
mysql -uroot -p'password'
# 设置复杂密码(由于MySQL密码策略,此密码必须足够复杂)
mysql> set password=password("Qs23=zs32");
# 更改MySQL密码策略
mysql> set global validate_password_policy=0;
mysql> set global validate_password_length=4;
# 设置简单好记的密码
set password=password("123456");
# 进入MySQL库
use mysql
# 查询user表
select user, host from user;
# 修改user表,把Host表内容修改为%
update user set host="%" where user="root";
flush privileges;
quit;
# 这里有个数据库建模软件很好用:http://www.ezdml.com/
# ========================卸载MySQL说明===================
# 若因为安装失败或者其他原因,MySQL需要卸载重装
# 通过/etc/my.cnf查看MySQL数据的存储位置
sudo cat /etc/my.cnf
# 去往/var/lib/mysql路径需要root权限
cd /var/lib/mysql
rm -rf *
# 卸载MySQL相关包
sudo rpm -qa | grep -i -E mysql
rpm -qa | grep -i -E mysql\|mariadb | xargs -n1 sudo rpm -e --nodeps
2.4 配置Hive元数据存储到MySQL
# 新建Hive元数据库
mysql -uroot -p123456
mysql> create database metastore;
mysql> quit;
# 将MySQL的JDBC驱动拷贝到Hive的lib目录下,驱动自行下载
cp /opt/software/mysql-connector-java-5.1.37.jar $HIVE_HOME/lib
# 解决日志Jar包冲突,进入/opt/module/hive/lib目录
mv log4j-slf4j-impl-2.10.0.jar log4j-slf4j-impl-2.10.0.jar.bak
# 在$HIVE_HOME/conf目录下新建hive-site.xml文件
vim $HIVE_HOME/conf/hive-site.xml
# 修改元数据库字符集
# Hive元数据库的字符集默认为Latin1,由于其不支持中文字符,故若建表语句中包含中文注释,会出现乱码现象
# 修改Hive元数据库中存储注释的字段的字符集为utf-8,进入metastore库,jdbc也要变成utf-8
# 字段注释
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
# 表注释
alter table TABLE_PARAMS modify column PARAM_VALUE mediumtext character set utf8;
添加如下内容:
<configuration>
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=falsevalue>
property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.jdbc.Drivervalue>
property>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>rootvalue>
property>
<property>
<name>javax.jdo.option.ConnectionPasswordname>
<value>123456value>
property>
<property>
<name>hive.metastore.warehouse.dirname>
<value>/user/hive/warehousevalue>
property>
<property>
<name>hive.metastore.schema.verificationname>
<value>falsevalue>
property>
<property>
<name>hive.metastore.event.db.notification.api.authname>
<value>falsevalue>
property>
<property>
<name>hive.cli.print.headername>
<value>truevalue>
property>
<property>
<name>hive.cli.print.current.dbname>
<value>truevalue>
property>
configuration>
# 初始化Hive元数据库(修改为采用MySQL存储元数据)
bin/schematool -dbType mysql -initSchema -verbose
# 启动Hive
bin/hive
hive> show databases;
hive> show tables;
hive> create table stu(id int, name string);
hive> insert into stu values(1,"ss");
hive> select * from stu;
# 看MySQL中的元数据
mysql -uroot -p123456
mysql> show databases;
mysql> use metastore;
mysql> show tables;
# 查看元数据库中存储的库信息
select * from DBS;
# 查看元数据库中存储的表信息
select * from TBLS;
# 查看元数据库中存储的表中列相关信息
select * from COLUMNS_V2;
2.5 Hive服务部署
Hive的hiveserver2服务的作用是提供jdbc/odbc接口,为用户提供远程访问Hive数据的功能,例如用户期望在个人电脑中访问远程服务中的Hive数据,就需要用到Hiveserver2
在远程访问Hive数据时,客户端并未直接访问Hadoop集群,而是由Hivesever2代理访问。由于Hadoop集群中的数据具备访问权限控制,所以此时需考虑一个问题:那就是访问Hadoop集群的用户身份是谁?是Hiveserver2的启动用户?还是客户端的登录用户?
答案是都有可能,具体是谁,由Hiveserver2的hive.server2.enable.doAs参数决定,该参数的含义是是否启用Hiveserver2用户模拟的功能。若启用,则Hiveserver2会模拟成客户端的登录用户去访问Hadoop集群的数据,不启用,则Hivesever2会直接使用启动用户访问Hadoop集群数据。模拟用户的功能,默认是开启的。生产环境,推荐开启用户模拟功能,因为开启后才能保证各用户之间的权限隔离
# hivesever2的模拟用户功能,依赖于Hadoop提供的proxy user(代理用户功能),只有Hadoop中的代理用户才能模拟其他用户的身份访问Hadoop集群。
# 因此,需要将hiveserver2的启动用户设置为Hadoop的代理用户
# 修改配置文件core-site.xml,然后记得分发三台机器
cd $HADOOP_HOME/etc/hadoop
vim core-site.xml
# 增加配置
<!--配置所有节点的atguigu用户都可作为代理用户-->
<property>
<name>hadoop.proxyuser.atguigu.hosts</name>
<value>*</value>
</property>
<!--配置atguigu用户能够代理的用户组为任意组-->
<property>
<name>hadoop.proxyuser.atguigu.groups</name>
<value>*</value>
</property>
<!--配置atguigu用户能够代理的用户为任意用户-->
<property>
<name>hadoop.proxyuser.atguigu.users</name>
<value>*</value>
</property>
# 分发
xsync core-site.xml
# 重启hadoop
myhadoop.sh stop/start
# Hive端配置
# 在hive-site.xml文件中添加如下配置信息,在conf目录下
vim hive-site.xml
<!-- 指定hiveserver2连接的host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop102</value>
</property>
<!-- 指定hiveserver2连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
# 启动hiveserver2
bin/hive --service hiveserver2
nohup bin/hive --service hiveserver2 >/dev/null 2>&1 &
# 使用命令行客户端beeline进行远程访问
./bin/beeline
bin/beeline -u jdbc:hive2://hadoop102:10000 -n atguigu
# 另一种使用Datagrip图形化客户端进行远程访问
# 若datagrip查询发现列的元数据信息不显示,需要在hive-site.xml添加以下配置
<property>
<name>metastore.storage.schema.reader.impl</name>
<value>org.apache.hadoop.hive.metastore.SerDeStorageSchemaReader</value>
</property>
接下来进行metastore部署
Hive的metastore服务的作用是为Hive CLI或者Hiveserver2提供元数据访问接口,metastore有两种运行模式,分别为嵌入式模式(之前默认就是嵌入式启动)和独立服务模式。
生产环境中,不推荐使用嵌入式模式。因为其存在以下两个问题:嵌入式模式下,每个Hive CLI都需要直接连接元数据库,当Hive CLI较多时,数据库压力会比较大;每个客户端都需要用户元数据库的读写权限,元数据库的安全得不到很好的保证。
# ==========================嵌入式模式=======================
# 嵌入式模式下,只需保证Hiveserver2和每个Hive CLI的配置文件hive-site.xml中包含连接元数据库所需要的以下参数即可
<!-- jdbc连接的URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value>
</property>
<!-- jdbc连接的Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc连接的username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc连接的password(选) -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
# ==========================独立服务模式=========================
scp -r /opt/module/hive/ hadoop103:/opt/module/
# 然后在hadoop102启动metastore服务
nohup hive --service metastore >/dev/null 2>&1 &
jps -ml
# 然后来到103节点,配置参数,即使配置了嵌入式的,也是访问这个,没有就报错
<!-- 指定metastore服务的地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop102:9083</value>
</property>
# 注意:主机名需要改为metastore服务所在节点,端口号无需修改,metastore服务的默认端口就是9083
# 测试,发现可以正常访问
bin/hive
2.6 Hive服务启动脚本(了解)
- nohup:放在命令开头,表示不挂起,也就是关闭终端进程也继续保持运行状态
- /dev/null:是Linux文件系统中的一个文件,被称为黑洞,所有写入该文件的内容都会被自动丢弃
- 2>&1:表示将错误重定向到标准输出上
- &:放在命令结尾,表示后台运行
一般会组合使用:nohup [xxx命令操作]> file 2>&1 &,表示将xxx命令运行的结果输出到file中,并保持命令启动的进程在后台运行。
# 直接编写脚本来管理服务的启动和关闭
vim $HIVE_HOME/bin/hiveservices.sh
#!/bin/bash
HIVE_LOG_DIR=$HIVE_HOME/logs
if [ ! -d $HIVE_LOG_DIR ]
then
mkdir -p $HIVE_LOG_DIR
fi
#检查进程是否运行正常,参数1为进程名,参数2为进程端口
function check_process()
{
pid=$(ps -ef 2>/dev/null | grep -v grep | grep -i $1 | awk '{print $2}')
ppid=$(netstat -nltp 2>/dev/null | grep $2 | awk '{print $7}' | cut -d '/' -f 1)
echo $pid
[[ "$pid" =~ "$ppid" ]] && [ "$ppid" ] && return 0 || return 1
}
function hive_start()
{
metapid=$(check_process HiveMetastore 9083)
cmd="nohup hive --service metastore >$HIVE_LOG_DIR/metastore.log 2>&1 &"
[ -z "$metapid" ] && eval $cmd || echo "Metastroe服务已启动"
server2pid=$(check_process HiveServer2 10000)
cmd="nohup hive --service hiveserver2 >$HIVE_LOG_DIR/hiveServer2.log 2>&1 &"
[ -z "$server2pid" ] && eval $cmd || echo "HiveServer2服务已启动"
}
function hive_stop()
{
metapid=$(check_process HiveMetastore 9083)
[ "$metapid" ] && kill $metapid || echo "Metastore服务未启动"
server2pid=$(check_process HiveServer2 10000)
[ "$server2pid" ] && kill $server2pid || echo "HiveServer2服务未启动"
}
case $1 in
"start")
hive_start
;;
"stop")
hive_stop
;;
"restart")
hive_stop
sleep 2
hive_start
;;
"status")
check_process HiveMetastore 9083 >/dev/null && echo "Metastore服务运行正常" || echo "Metastore服务运行异常"
check_process HiveServer2 10000 >/dev/null && echo "HiveServer2服务运行正常" || echo "HiveServer2服务运行异常"
;;
*)
echo Invalid Args!
echo 'Usage: '$(basename $0)' start|stop|restart|status'
;;
esac
# 添加执行权限
chmod +x $HIVE_HOME/bin/hiveservices.sh
# 启动Hive后台服务
hiveservices.sh start
3、Hive使用技巧
3.1 Hive常用交互命令
hive -help
# “-e”不进入hive的交互窗口执行hql语句
hive -e "select id from stu;"
# “-f”执行脚本中的hql语句
# 在/opt/module/hive/下创建datas目录并在datas目录下创建hivef.sql文件
mkdir datas
vim hivef.sql
# 文件中写入正确的hql语句
select * from stu;
bin/hive -f /opt/module/hive/datas/hivef.sql
# 执行文件中的hql语句并将结果写入文件中
bin/hive -f /opt/module/hive/datas/hivef.sql > /opt/module/hive/datas/hive_result.txt
3.2 Hive参数配置方式
# 查看当前所有的配置信息
hive>set;
# 参数的配置三种方式
# 1、默认配置文件:hive-default.xml
# 用户自定义配置文件:hive-site.xml
# 注意:用户自定义配置会覆盖默认配置。另外,Hive也会读入Hadoop的配置,因为Hive是作为Hadoop的客户端启动的,Hive的配置会覆盖Hadoop的配置。配置文件的设定对本机启动的所有Hive进程都有效
# 2、命令行参数方式
# 启动Hive时,可以在命令行添加-hiveconf param=value来设定参数
# 注意:仅对本次Hive启动有效
bin/hive -hiveconf mapreduce.job.reduces=10;
# 查看参数设置
hive (default)> set mapreduce.job.reduces;
# 3、参数声明方式
# 以在HQL中使用SET关键字设定参数,例如
hive(default)> set mapreduce.job.reduces;
# 上述三种设定方式的优先级依次递增。即配置文件 < 命令行参数 < 参数声明。
# 注意某些系统级的参数,例如log4j相关的设定,必须用前两种方式设定,因为那些参数的读取在会话建立以前已经完成了
3.3 Hive常见属性配置
Hive客户端显示当前库和表头,vim hive-site.xml
<property>
<name>hive.cli.print.headername>
<value>truevalue>
<description>Whether to print the names of the columns in query output.description>
property>
<property>
<name>hive.cli.print.current.dbname>
<value>truevalue>
<description>Whether to include the current database in the Hive prompt.description>
property>
Hive运行日志路径配置,Hive的log默认存放在/tmp/atguigu/hive.log目录下(当前用户名下),修改Hive的log存放日志到/opt/module/hive/logs
# 修改$HIVE_HOME/conf/hive-log4j2.properties.template文件名称为hive-log4j2.properties
mv hive-log4j2.properties.template hive-log4j2.properties
# 在hive-log4j2.properties文件中修改log存放位置
property.hive.log.dir=/opt/module/hive/logs
Hive的JVM堆内存设置,新版本的Hive启动的时候,默认申请的JVM堆内存大小为256M,JVM堆内存申请的太小,导致后期开启本地模式,执行复杂的SQL时经常会报错:java.lang.OutOfMemoryError: Java heap space,因此最好提前调整一下HADOOP_HEAPSIZE这个参数
# 修改$HIVE_HOME/conf下的hive-env.sh.template为hive-env.sh
mv hive-env.sh.template hive-env.sh
# 将hive-env.sh其中的参数 export HADOOP_HEAPSIZE修改为2048,重启Hive。
# The heap size of the jvm stared by hive shell script can be controlled via:
export HADOOP_HEAPSIZE=2048
关闭Hadoop虚拟内存检查,在yarn-site.xml中关闭虚拟内存检查(虚拟内存校验,如果已经关闭了,就不需要配了),修改完后记得分发yarn-site.xml,并重启yarn。vim /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml
<property>
<name>yarn.nodemanager.vmem-check-enabledname>
<value>falsevalue>
property>
二、DDL&DML语句
1、DDL(Data Definition Language)数据定义
1.1 数据库
# 创建数据库
CREATE DATABASE [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];
# 创建一个数据库,不指定路径
# 注:若不指定路径,其默认路径为${hive.metastore.warehouse.dir}/database_name.db
hive (default)> create database db_hive1;
hive (default)> create database db_hive2 location '/db_hive2';
hive (default)> create database db_hive3 with dbproperties('create_date'='2022-11-18');
# ==============查询数据库==================
# 注:like通配表达式说明:*表示任意个任意字符,|表示或的关系
SHOW DATABASES [LIKE 'identifier_with_wildcards'];
hive> show databases like 'db_hive*';
# 查看数据库信息
DESCRIBE DATABASE [EXTENDED] db_name;
hive> desc database db_hive3;
# 查看更多信息
hive> desc database extended db_hive3;
# ==============修改数据库======================
# 用户可以使用alter database命令修改数据库某些信息,其中能够修改的信息包括dbproperties、location、owner user。
# 需要注意的是:修改数据库location,不会改变当前已有表的路径信息,而只是改变后续创建的新表的默认的父目录
# 修改dbproperties
ALTER DATABASE database_name SET DBPROPERTIES (property_name=property_value, ...);
# 修改location
ALTER DATABASE database_name SET LOCATION hdfs_path;
# 修改owner user
ALTER DATABASE database_name SET OWNER USER user_name;
hive> ALTER DATABASE db_hive3 SET DBPROPERTIES ('create_date'='2022-11-20');
# ======================删除数据库====================
# 注:RESTRICT:严格模式,若数据库不为空,则会删除失败,默认为该模式。
# CASCADE:级联模式,若数据库不为空,则会将库中的表一并删除
DROP DATABASE [IF EXISTS] database_name [RESTRICT|CASCADE];
hive> drop database db_hive2;
hive> drop database db_hive3 cascade;
# ====================切换当前数据库=======================
USE database_name;
1.2 表(table)创建
普通建表
# 创建表
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
# 可以预查看一些基本默认设置
show create table + 表名
- TEMPORARY,临时表,该表只在当前会话可见,会话结束,表会被删除
- EXTERNAL(重点),外部表,与之相对应的是内部表(管理表)。管理表意味着Hive会完全接管该表,包括元数据和HDFS中的数据。而外部表则意味着Hive只接管元数据,而不完全接管HDFS中的数据
- data_type(重点),Hive中的字段类型可分为基本数据类型和复杂数据类型
Hive 说明 定义 t****inyint 1byte有符号整数 s****mallint 2byte有符号整数 i****nt 4byte有符号整数 b****igint 8byte有符号整数 b****oolean 布尔类型,true或者false f****loat 单精度浮点数 d****ouble 双精度浮点数 decimal 十进制精准数字类型 decimal(16,2) varchar 字符序列,需指定最大长度,最大长度的范围是[1,65535] varchar(32) string 字符串,无需指定最大长度 t****imestamp 时间类型 b****inary 二进制数据 复杂数据类型如下 类型 说明 定义 ------ ---------------------------- ---------------------------- array 数组是一组相同类型的值的集合 array map map是一组相同类型的键-值对集合 map struct 结构体由多个属性组成,每个属性都有自己的属性名和数据类型 struct Hive的基本数据类型可以做类型转换,转换的方式包括隐式转换以及显示转换,详情可参考Hive官方说明:Allowed Implicit Conversions - 任何整数类型都可以隐式地转换为一个范围更广的类型,如tinyint可以转换成int,int可以转换成bigint
- 所有整数类型、float和string类型都可以隐式地转换成double。
- tinyint、smallint、int都可以转换为float
- boolean类型不可以转换为任何其它的类型
# 显示转换可以借助cast函数完成显示的类型转换 # cast(expr as) hive (default)> select '1' + 2, cast('1' as int) + 2; - PARTITIONED BY(重点),创建分区表
- CLUSTERED BY … SORTED BY…INTO … BUCKETS(重点),创建分桶表
- ROW FORMAT(重点),指定SERDE,SERDE是Serializer and Deserializer的简写。Hive使用SERDE序列化和反序列化每行数据。详情可参考 Hive-Serde
# 语法一:DELIMITED关键字表示对文件中的每个字段按照特定分割符进行分割,其会使用默认的SERDE对每行数据进行序列化和反序列化 ROW FORAMT DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char] [MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char] [NULL DEFINED AS char] # fields terminated by :列分隔符 # collection items terminated by : map、struct和array中每个元素之间的分隔符 # map keys terminated by :map中的key与value的分隔符 # lines terminated by :行分隔符 # [TBLPROPERTIES (property_name=property_value, ...)] # [AS select_statement] # null 一般在hdfs用/N表示 # 语法二:SERDE关键字可用于指定其他内置的SERDE或者用户自定义的SERDE。例如JSON SERDE,可用于处理JSON字符串 ROW FORMAT SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value,property_name=property_value, ...)] - STORED AS(重点),指定文件格式,常用的文件格式有,textfile(默认值),sequence file,orc file、parquet file等等
- xxxxxxxxxx # 进入解压后的Hadoop源码目录下#开始编译mvn clean package -DskipTests -Pdist,native -Dtar# 注意:第一次编译需要下载很多依赖jar包,编译时间会很久,预计1小时左右,最终成功是全部SUCCESS# 成功的64位hadoop包在/opt/module/hadoop_source/hadoop-3.1.3-src/hadoop-dist/target下bash
- TBLPROPERTIES,用于配置表的一些KV键值对参数
Create Table As Select(CTAS)建表
# 该语法允许用户利用select查询语句返回的结果,直接建表,表的结构和查询语句的结构保持一致,且保证包含select查询语句放回的内容。
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] table_name
[COMMENT table_comment]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
[AS select_statement]
Create Table Like语法
# 该语法允许用户复刻一张已经存在的表结构,与上述的CTAS语法不同,该语法创建出来的表中不包含数据
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
[LIKE exist_table_name]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
案例说明
# =====================内部表与外部表====================
# ===================内部表=============================
# Hive中默认创建的表都是的内部表,有时也被称为管理表。对于内部表,Hive会完全管理表的元数据和数据文件
create table if not exists student(
id int,
name string
)
row format delimited fields terminated by '\t'
location '/user/hive/warehouse/student';
# vim /opt/module/datas/student.txt插入数据
1001 student1
1002 student2
1003 student3
1004 student4
1005 student5
1006 student6
1007 student7
1008 student8
hadoop fs -put student.txt /user/hive/warehouse/student
# 删除表,发现数据也没了
hive (default)> drop table student;
# ======================外部表===========================
# 外部表通常可用于处理其他工具上传的数据文件,对于外部表,Hive只负责管理元数据,不负责管理HDFS中的数据文件
create external table if not exists student(
id int,
name string
)
row format delimited fields terminated by '\t'
location '/user/hive/warehouse/student';
# =======================SERDE和复杂数据类型=======================
# 若现有如下格式的JSON文件需要由Hive进行分析处理,请考虑如何设计表?
# 注:以下内容为格式化之后的结果,文件中每行数据为一个完整的JSON字符串
{
"name": "dasongsong",
"friends": [
"bingbing",
"lili"
],
"students": {
"xiaohaihai": 18,
"xiaoyangyang": 16
},
"address": {
"street": "hui long guan",
"city": "beijing",
"postal_code": 10010
}
}
# 设计表
create table teacher
(
name string,
friends array<string>,
students map<string,int>,
address struct<city:string,street:string,postal_code:int>
)
row format serde 'org.apache.hadoop.hive.serde2.JsonSerDe'
location '/user/hive/warehouse/teacher';
# 创建json,然后上传,注意不能有空格
vim /opt/module/datas/teacher.txt
{"name":"dasongsong","friends":["bingbing","lili"],"students":{"xiaohaihai":18,"xiaoyangyang":16},"address":{"street":"hui long guan","city":"beijing","postal_code":10010}}
# 上传
hadoop fs -put teacher.txt /user/hive/warehouse/teacher
# 尝试从复杂数据类型的字段中取值
select friends[0],students['xiaohaihai'],address.city from teacher
# ===================create table as select和create table like=========
create table teacher1 as select * from teacher;
create table teacher2 like teacher;
1.3 表的增删查改
# ====================查看表=====================
# 展示所有表
SHOW TABLES [IN database_name] LIKE ['identifier_with_wildcards'];
show tables like 'stu*';
# 查看表信息
DESCRIBE [EXTENDED | FORMATTED] [db_name.]table_name
# EXTENDED:展示详细信息
# FORMATTED:对详细信息进行格式化的展示
desc stu;
desc formatted stu;
# =====================修改表=======================
# 重命名表
ALTER TABLE table_name RENAME TO new_table_name
alter table stu rename to stu1;
# 修改列信息
# 增加列,该语句允许用户增加新的列,新增列的位置位于末尾
ALTER TABLE table_name ADD COLUMNS (col_name data_type [COMMENT col_comment], ...)
# 更新列,该语句允许用户修改指定列的列名、数据类型、注释信息以及在表中的位置
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name]
# 替换列,该语句允许用户用新的列集替换表中原有的全部列
ALTER TABLE table_name REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...)
# 案例
desc stu;
alter table stu add columns(age int);
desc stu;
alter table stu change column age ages double;
alter table stu replace columns(id int, name string);
# ======================删除表==================
DROP TABLE [IF EXISTS] table_name;
drop table stu;
# =====================清空表======================
# 注意:truncate只能清空管理表,不能删除外部表中数据
TRUNCATE [TABLE] table_name
truncate table student;
2、DML(Data Manipulation Language)数据操作
2.1 Load
Load语句可将文件导入到Hive表中,关键字说明:
- local:表示从本地加载数据到Hive表;否则从HDFS加载数据到Hive表
- overwrite:表示覆盖表中已有数据,否则表示追加
- partition:表示上传到指定分区,若目标是分区表,需指定分区
# 语法
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)];
# 实操案例
# 创建表
create table student(
id int,
name string
)
row format delimited fields terminated by '\t';
# 加载本地文件到hive
load data local inpath '/opt/module/datas/student.txt' into table student;
# 加载HDFS文件到hive中,上传文件到HDFS
hadoop fs -put /opt/module/datas/student.txt /user/atguigu
# 加载HDFS上数据,导入完成后去HDFS上查看文件是否还存在?答案是不在了,说明hdfs里面是元数据的修改
load data inpath '/user/atguigu/student.txt' into table student;
# 加载数据覆盖表中已有的数据
dfs -put /opt/module/datas/student.txt /user/atguigu;
load data inpath '/user/atguigu/student.txt' overwrite into table student;
2.2 Insert
LOAD DATA用于将外部数据直接加载到Hive表中,而INSERT INTO用于将数据从一个表插入到另一个表中或将查询结果插入到表中,并可以进行数据转换、过滤或聚合操作
# ====================将查询结果插入表中=====
INSERT (INTO | OVERWRITE) TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement;
# INTO:将结果追加到目标表
# OVERWRITE:用结果覆盖原有数据
# 案例
create table student1(
id int,
name string
)
row format delimited fields terminated by '\t';
# 要跑MP
insert overwrite table student1
select
id,
name
from student;
# ===================将给定Values插入表中====
INSERT (INTO | OVERWRITE) TABLE tablename [PARTITION (partcol1[=val1], partcol2[=val2] ...)] VALUES values_row [, values_row ...]
insert into table student1 values(1,'wangwu'),(2,'zhaoliu');
# 将查询结果写入目标路径
INSERT OVERWRITE [LOCAL] DIRECTORY directory [ROW FORMAT row_format] [STORED AS file_format] select_statement;
# 案例
insert overwrite local directory '/opt/module/datas/student' ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe' select id,name from student;
2.3 Export&Import
Export导出语句可将表的数据和元数据信息一并到处的HDFS路径,Import可将Export导出的内容导入Hive,表的数据和元数据信息都会恢复。Export和Import可用于两个Hive实例之间的数据迁移
--导出
EXPORT TABLE tablename TO 'export_target_path'
--导入
IMPORT [EXTERNAL] TABLE new_or_original_tablename FROM 'source_path' [LOCATION 'import_target_path']
# 案例
--导出
export table default.student to '/user/hive/warehouse/export/student';
--导入
import table student2 from '/user/hive/warehouse/export/student';
三、查询
1、基础语法
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Select
基本语法
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference -- 从什么表查
[WHERE where_condition] -- 过滤
[GROUP BY col_list] -- 分组查询
[HAVING col_list] -- 分组后过滤
[ORDER BY col_list] -- 排序
[CLUSTER BY col_list]
[DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT number] -- 限制输出的行数
2、基本查询(Select…From)
2.1 数据准备
# 在/opt/module/hive/datas/路径上创建dept.txt文件,并赋值如下内容:
# 部门编号 部门名称 部门位置id
vim dept.txt
10 行政部 1700
20 财务部 1800
30 教学部 1900
40 销售部 1700
# 在/opt/module/hive/datas/路径上创建emp.txt文件
# hive中,如果不指定,默认null为/N
vim emp.txt
7369 张三 研发 800.00 30
7499 李四 财务 1600.00 20
7521 王五 行政 1250.00 10
7566 赵六 销售 2975.00 40
7654 侯七 研发 1250.00 30
7698 马八 研发 2850.00 30
7782 金九 \N 2450.0 30
7788 银十 行政 3000.00 10
7839 小芳 销售 5000.00 40
7844 小明 销售 1500.00 40
7876 小李 行政 1100.00 10
7900 小元 讲师 950.00 30
7902 小海 行政 3000.00 10
7934 小红明 讲师 1300.00 30
# 创建部门表
create table if not exists dept(
deptno int, -- 部门编号
dname string, -- 部门名称
loc int -- 部门位置
)
row format delimited fields terminated by '\t';
# 创建员工表
create table if not exists emp(
empno int, -- 员工编号
ename string, -- 员工姓名
job string, -- 员工岗位(大数据工程师、前端工程师、java工程师)
sal double, -- 员工薪资
deptno int -- 部门编号
)
row format delimited fields terminated by '\t';
# 导入数据
load data local inpath '/opt/module/hive/datas/dept.txt' into table dept;
load data local inpath '/opt/module/hive/datas/emp.txt' into table emp;
2.2 基本查询操作
# SQL 语言大小写不敏感
# 全表查询
select * from emp;
# 选择特定列查询
select empno, ename from emp;
# 列别名
select
ename AS name,
deptno dn
from emp;
# Limit语句
# 典型的查询会返回多行数据。limit子句用于限制返回的行数
select * from emp limit 5;
select * from emp limit 2,3;
# Where语句,where子句中不能使用字段别名
select * from emp where sal > 1000;
2.3 关系运算函数
| 操作符 | 支持的数据类型 | 描述 |
|---|---|---|
| A=B | 基本数据类型 | 如果A等于B则返回true,反之返回false |
| A<=>B | 基本数据类型 | 如果A和B都为null或者都不为null,则返回true,如果只有一边为null,返回false |
| A<>B, A!=B | 基本数据类型 | A或者B为null则返回null;如果A不等于B,则返回true,反之返回false |
A| 基本数据类型 |
A或者B为null,则返回null;如果A小于B,则返回true,反之返回false |
|
| A<=B | 基本数据类型 | A或者B为null,则返回null;如果A小于等于B,则返回true,反之返回false |
| A>B | 基本数据类型 | A或者B为null,则返回null;如果A大于B,则返回true,反之返回false |
| A>=B | 基本数据类型 | A或者B为null,则返回null;如果A大于等于B,则返回true,反之返回false |
| A [not] between B and C | 基本数据类型 | 如果A,B或者C任一为null,则结果为null。如果A的值大于等于B而且小于或等于C,则结果为true,反之为false。如果使用not关键字则可达到相反的效果。 |
| A is null | 所有数据类型 | 如果A等于null,则返回true,反之返回false |
| A is not null | 所有数据类型 | 如果A不等于null,则返回true,反之返回false |
| in(数值1,数值2) | 所有数据类型 | 使用 in运算显示列表中的值 |
| A [not] like B | string 类型 | B是一个SQL下的简单正则表达式,也叫通配符模式,如果A与其匹配的话,则返回true;反之返回false。B的表达式说明如下:‘x%’表示A必须以字母‘x’开头,‘%x’表示A必须以字母‘x’结尾,而‘%x%’表示A包含有字母‘x’,可以位于开头,结尾或者字符串中间。如果使用not关键字则可达到相反的效果。 |
| A rlike B, A regexp B | string 类型 | B是基于java的正则表达式,如果A与其匹配,则返回true;反之返回false。匹配使用的是JDK中的正则表达式接口实现的,因为正则也依据其中的规则。例如,正则表达式必须和整个字符串A相匹配,而不是只需与其字符串匹配。 |
2.4 逻辑运算函数
# 基本语法(and/or/not)
select * from emp
where sal > 1000 and deptno = 30;
select * from emp
where sal>1000 or deptno=30;
select * from emp
where deptno not in(30, 20);
2.5 聚合函数
- count(*),表示统计所有行数,包含null值
- count(某列),表示该列一共有多少行,不包含null值
- max(),求最大值,不包含null,除非所有值都是null
- min(),求最小值,不包含null,除非所有值都是null
- sum(),求和,不包含null
- avg(),求平均值,不包含null
# 本地模式mapreduce都运行在一个进程内,里面各个线程,之前配的是yarn
# tail -500 /tmp/atguigu/hive.log 查看错误信息发现堆内存报错,需要调大堆内存
# mv hive-env.sh.template hive-env.sh
# 然后重启
set mapreduce.framework.name = local
# 求总行数(count)
# count(某字段),null值不会统计
select count(*) cnt from emp;
# MP执行流程如下图
3、分组
3.1 Group By语句
Group By语句通常会和聚合函数一起使用,按照一个或者多个列队结果进行分组,然后对每个组执行聚合操作
# 计算emp表每个部门的平均工资
select
t.deptno,
avg(t.sal) avg_sal
from emp t
group by t.deptno;
# 计算emp每个部门中每个岗位的最高薪水
select
t.deptno,
t.job,
max(t.sal) max_sal
from emp t
group by t.deptno, t.job;
3.2 Having语句
having与where不同点
- where后面不能写分组聚合函数,而having后面可以使用分组聚合函数
- having只用于group by分组统计语句
# 求每个部门的平均工资
select
deptno,
avg(sal)
from emp
group by deptno;
# 求每个部门的平均薪水大于2000的部门
select
deptno,
avg(sal) avg_sal
from emp
group by deptno
having avg_sal > 2000;
4、Join语句
# 等值Join
# Hive支持通常的sql join语句,但是只支持等值连接,不支持非等值连接
# 根据员工表和部门表中的部门编号相等,查询员工编号、员工名称和部门名称
select
e.empno,
e.ename,
d.dname
from emp e
join dept d
on e.deptno = d.deptno;
# 内连接:只有进行连接的两个表中都存在与连接条件相匹配的数据才会被保留下来
# 左外连接:join操作符左边表中符合where子句的所有记录将会被返回
# 右外连接:join操作符右边表中符合where子句的所有记录将会被返回
# 满外连接:将会返回所有表中符合where语句条件的所有记录。如果任一表的指定字段没有符合条件的值的话,那么就使用null值替代
select
e.empno,
e.ename,
d.deptno
from emp e
full join dept d
on e.deptno = d.deptno;
# 多表连接
# 大多数情况下,Hive会对每对join连接对象启动一个MapReduce任务。本例中会首先启动一个MapReduce job对表e和表d进行连接操作,然后会再启动一个MapReduce job将第一个MapReduce job的输出和表l进行连接操作。
# 注意:为什么不是表d和表l先进行连接操作呢?这是因为Hive总是按照从左到右的顺序执行的。
# 笛卡尔集
# 笛卡尔集会在下面条件下产生:省略连接条件;连接条件无效;所有表中的所有行互相连接
# 联合(union & union all)
# union和union all都是上下拼接sql的结果,这点是和join有区别的,join是左右关联,union和union all是上下拼接。union去重,union all不去重。
# union和union all在上下拼接sql结果时有两个要求:两个sql的结果,列的个数必须相同;两个sql的结果,上下所对应列的类型必须一致
5、排序
5.1 全局排序(Order By)
Order By:全局排序,只有一个Reduce
- asc(ascend):升序(默认)
- desc(descend):降序
# 通常和limit配合使用
# 按照部门和工资升序排序
select
ename,
deptno,
sal
from emp
order by deptno, sal;
5.2 每个Reduce内部排序(Sort By)
Sort By:对于大规模的数据集order by的效率非常低。在很多情况下,并不需要全局排序,此时可以使用Sort by。Sort by为每个reduce产生一个排序文件。每个Reduce内部进行排序,对全局结果集来说不是排序。
# 设置reduce个数
set mapreduce.job.reduces=3;
# 查看设置reduce个数
set mapreduce.job.reduces;
# 根据部门编号降序查看员工信息
select
*
from emp
sort by deptno desc;
# 将查询结果导入到文件中(按照部门编号降序排序),可以查看每个文件按照顺序排序
insert overwrite local directory '/opt/module/hive/datas/sortby-result' select * from emp sort by deptno desc;
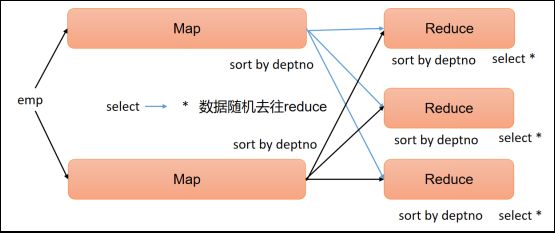
5.3 分区(Distribute By)
Distribute By:在有些情况下,我们需要控制某个特定行应该到哪个Reducer,通常是为了进行后续的聚集操作。distribute by子句可以做这件事。distribute by类似MapReduce中partition(自定义分区),进行分区,结合sort by使用。
对于distribute by进行测试,一定要分配多reduce进行处理,否则无法看到distribute by的效果
set mapreduce.job.reduces=3;
# 先按照部门编号分区,再按照员工编号薪资排序
insert overwrite local directory
'/opt/module/hive/datas/distribute-result'
select
*
from emp
distribute by deptno
sort by sal desc;
- distribute by的分区规则是根据分区字段的hash码与reduce的个数进行相除后,余数相同的分到一个区
- Hive要求distribute by语句要写在sort by语句之前
注意:演示完以后mapreduce.job.reduces的值要设置回-1,否则下面分区or分桶表load跑MapReduce的时候会报错
5.4 分区排序(Cluster By)
当distribute by和sort by字段相同时,可以使用cluster by方式。cluster by除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是升序排序,不能指定排序规则为asc或者desc
# 注意:按照部门编号分区,不一定就是固定死的数值,可以是20号和30号部门分到一个分区里面去
select
*
from emp
cluster by deptno;
select
*
from emp
distribute by deptno
sort by deptno;
6、函数
6.1 简介
Hive会将常用的逻辑封装成函数给用户进行使用,类似于Java中的函数,文档参考:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
# 查看系统内置函数
show functions;
# 查看内置函数用法
desc function upper;
# 查看内置函数详细信息
desc function extended upper;
6.2 单行函数
单行函数按照功能可分为如下几类: 日期函数、字符串函数、集合函数、数学函数、流程控制函数等
# =======数值函数
# round:四舍五入
# ceil:向上取整
# floor:向下取整
select round(3.3); 3
# ======字符串函数
# substring:截取字符串,返回字符串A从start位置到结尾的字符串
substring(string A, int start)
# substring(string A, int start, int len) ,返回字符串A从start位置开始,长度为len的字符串
# replace :替换
# replace(string A, string B, string C),将字符串A中的子字符串B替换为C
# regexp_replace:正则替换
# regexp_replace(string A, string B, string C),将字符串A中的符合java正则表达式B的部分替换为C。注意,在有些情况下要使用转义字符
select regexp_replace('100-200', '(\\d+)', 'num')
# regexp:正则匹配,若字符串符合正则表达式,则返回true,否则返回false。
select 'dfsaaaa' regexp 'dfsa+'
# repeat:重复字符串
# repeat(string A, int n),将字符串A重复n遍
select repeat('123', 3);
# split :字符串切割
# split(string str, string pat),按照正则表达式pat匹配到的内容分割str,分割后的字符串,以数组的形式返回
select split('a-b-c-d','-');
# nvl :替换null值
# nvl(A,B) ,若A的值不为null,则返回A,否则返回B
select nvl(null,1);
# concat :拼接字符串
# concat(string A, string B, string C, ……) 将A,B,C……等字符拼接为一个字符串
select concat('beijing','-','shanghai','-','shenzhen');
# concat_ws:以指定分隔符拼接字符串或者字符串数组
# concat_ws(string A, string…| array(string)) 使用分隔符A拼接多个字符串,或者一个数组的所有元素
select concat_ws('-','beijing','shanghai','shenzhen');
# get_json_object:解析json字符串
# get_json_object(string json_string, string path) 解析json的字符串json_string,返回path指定的内容。如果输入的json字符串无效,那么返回NULL
select get_json_object('[{"name":"大海海","sex":"男","age":"25"},{"name":"小宋宋","sex":"男","age":"47"}]','$.[0].name');
# 获取json数组里面的数据
select get_json_object('[{"name":"大海海","sex":"男","age":"25"},{"name":"小宋宋","sex":"男","age":"47"}]','$.[0]');
# ==日期函数
# unix_timestamp:返回当前或指定时间的时间戳,前面是日期后面是指,日期传进来的具体格式
select unix_timestamp('2022/08/08 08-08-08','yyyy/MM/dd HH-mm-ss');
# from_unixtime:转化UNIX时间戳(从 1970-01-01 00:00:00 UTC 到指定时间的秒数)到当前时区的时间格式
select from_unixtime(1659946088);
# current_date:当前日期
select current_date;
# current_timestamp:当前的日期加时间,并且精确的毫秒
select current_timestamp;
# month:获取日期中的月
select month('2022-08-08 08:08:08');
# day:获取日期中的日
select day('2022-08-08 08:08:08')
# hour:获取日期中的小时
# datediff:两个日期相差的天数(结束日期减去开始日期的天数)
select datediff('2021-08-08','2022-10-09');
# date_add:日期加天数;date_sub:日期减天数
select date_add('2022-08-08',2);
# date_format:将标准日期解析成指定格式字符串
select date_format('2022-08-08','yyyy年-MM月-dd日')
# ========流程控制函数
# case when:条件判断函数
# 语法一:case when a then b [when c then d] * [else e] end
# 说明:如果a为true,则返回b;如果c为true,则返回d;否则返回 e
select case when 1=2 then 'tom' when 2=2 then 'mary' else 'tim' end from tableName;
# 语法二: case a when b then c [when d then e]* [else f] end
select case 100 when 50 then 'tom' when 100 then 'mary' else 'tim' end from tableName;
# if: 条件判断,类似于Java中三元运算符
# 语法:if(boolean testCondition, T valueTrue, T valueFalseOrNull)
select if(10 > 5,'正确','错误');
# =========集合函数
# size:集合中元素的个数
select size(friends) from test;
# map:创建map集合
# 语法:map (key1, value1, key2, value2, …)
select map('xiaohai',1,'dahai',2);
# map_keys: 返回map中的key
select map_keys(map('xiaohai',1,'dahai',2));
# map_values: 返回map中的value
select map_values(map('xiaohai',1,'dahai',2));
# array_contains: 判断array中是否包含某个元素
select array_contains(array('a','b','c','d'),'a');
# sort_array:将array中的元素排序
select sort_array(array('a','d','c'));
# struct声明struct中的各属性
select struct('name','age','weight');
# named_struct声明struct的属性和值
select named_struct('name','xiaosong','age',18,'weight',80);
6.3 高级聚合函数
# 普通聚合 count/sum
# collect_list 收集并形成list集合,结果不去重
select
sex,
collect_list(job)
from
employee
group by
sex
# collect_list不去重
# collect_set 收集并形成set集合,结果去重
select
sex,
collect_set(job)
from
employee
group by
sex
6.4 炸裂函数
UDTF (Table-GeneratingFunctions),接收一行数据,输出一行或多行数据
# 使用语法
select explode(array("a","b","c")) as item;
select explode(map("a",1,"b' ',2,"c",3)) as (key,value);
# 还会返回索引
select posexplode(array("a","b","c")) as (pos,item);
# 返回特定的
select inline(array(named_struct("id",1, "name", "zs"),named_struct("id",2, "name", "Is"),named_struct("id",3, "name", "ww"))) as (id, name);
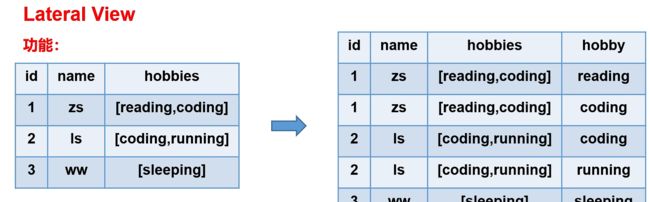
# Latera View通常与UDTF配合使用。
# Lateral View可以将UDTF应用到源表的每行数据,将每行数据转换为一行或多行,并将源表中每行的输出结果与该行连接起来,形成一个虚拟表。
# 把其中一个列表分别输出
select id,name,hobbies,hobby from person lateral view explode(hobbies) tmp as hobby;
6.5 窗口函数(开窗函数)
窗口函数,能为每行数据划分—个窗口,然后对窗口范围内的数据进行计算,最后将计算结果返回给该行数据。https://cwiki.apache.org/confluence/display/Hive/LanguageManual+WindowingAndAnalytics
窗口函数的语法中主要包括“窗口”和“函数”两部分。其中“窗口”用于定义计算范围,“函数”用于定义计算逻辑。
select order_id,order_date,amount,函数(amount) over(窗口范围) total_amount from order_info;
# 按照功能,常用窗口可划分为如下几类:聚合函数、跨行取值函数、排名函数
# 绝大多数的聚合函数都可以配合窗口使用,例如max(),min(),sum(),count(),avg()等。
# 需要确定order by,因为MP会分成很多小任务
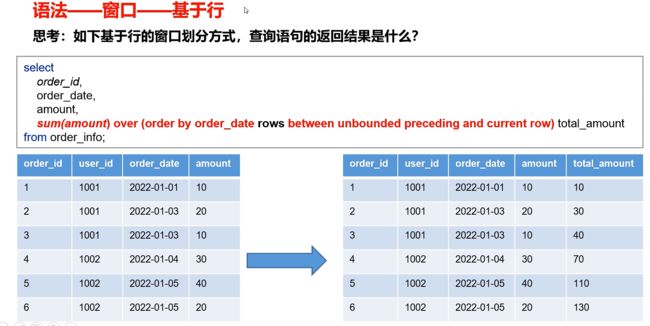
窗口范围的定义分为两种类型,一种是基于行的,一种是基于值的
- 基于行示例:要求每行数据的窗口为上一行到当前行

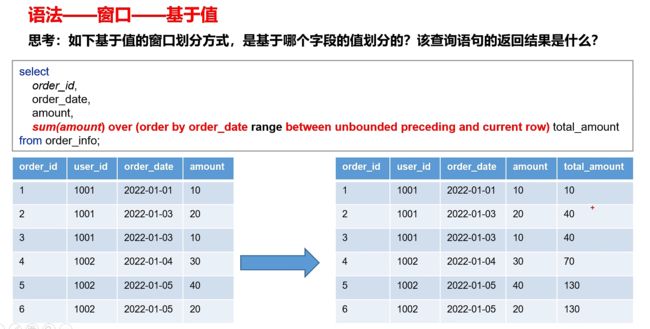
- 基于值示例:要求每行数据的窗口为,值位于当前值-1,到当前值(关键词range)
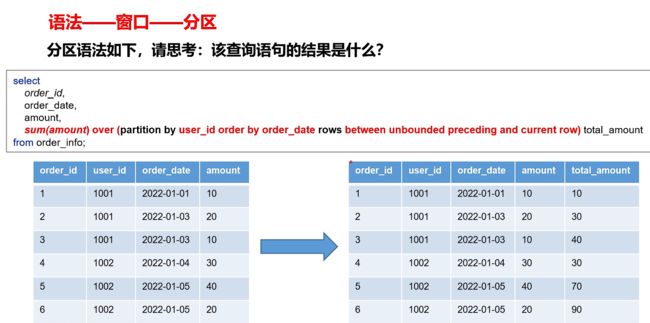
窗口分区,定义窗口范围时,可以指定分区字段,每个分区单独划分窗口
对于窗口缺省函数
- partition by省略不写,表示不分区
- order by 省略不写,表示不排序
- (rows|range) between … and …省略不写,则使用其默认值,默认值如下:若over()中包含order by,则默认值为
range between unbounded preceding and current row;若over()中不包含order by,则默认值为rows between unbounded preceding and unbounded following
下面举例其他常用的窗口函数,lead和lag,first_value和last_value,排名函数,注:lag和lead,rank 、dense_rank、row_number函数不支持自定义窗口

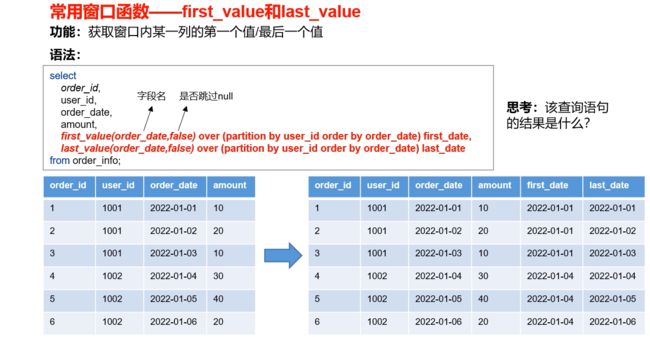
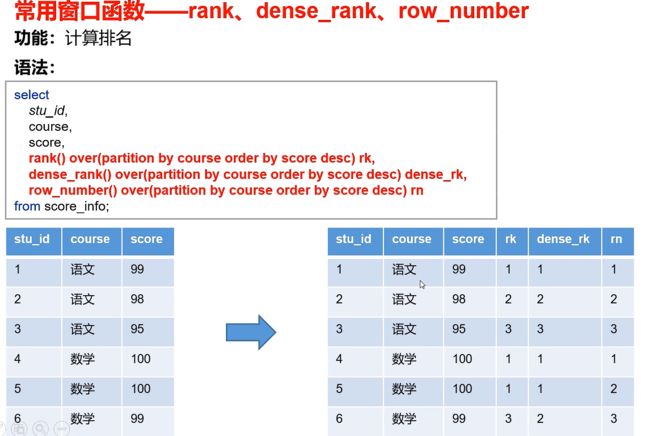
# 案例实操
create table order_info
(
order_id string, --订单id
user_id string, -- 用户id
user_name string, -- 用户姓名
order_date string, -- 下单日期
order_amount int -- 订单金额
);
insert overwrite table order_info
values ('1', '1001', '小元', '2022-01-01', '10'),
('2', '1002', '小海', '2022-01-02', '15'),
('3', '1001', '小元', '2022-02-03', '23'),
('4', '1002', '小海', '2022-01-04', '29'),
('5', '1001', '小元', '2022-01-05', '46'),
('6', '1001', '小元', '2022-04-06', '42'),
('7', '1002', '小海', '2022-01-07', '50'),
('8', '1001', '小元', '2022-01-08', '50'),
('9', '1003', '小辉', '2022-04-08', '62'),
('10', '1003', '小辉', '2022-04-09', '62'),
('11', '1004', '小猛', '2022-05-10', '12'),
('12', '1003', '小辉', '2022-04-11', '75'),
('13', '1004', '小猛', '2022-06-12', '80'),
('14', '1003', '小辉', '2022-04-13', '94');
# 统计每个用户截至每次下单的累积下单总额
select
order_id,
user_id,
user_name,
order_date,
order_amount,
sum(order_amount) over(partition by user_id order by order_date rows between unbounded preceding and current row) sum_so_far
from order_info;
# 统计每个用户截至每次下单的当月累积下单总额
select
order_id,
user_id,
user_name,
order_date,
order_amount,
sum(order_amount) over(partition by user_id,substring(order_date,1,7) order by order_date rows between unbounded preceding and current row) sum_so_far
from order_info;
# 统计每个用户每次下单距离上次下单相隔的天数(首次下单按0天算)
select
order_id,
user_id,
user_name,
order_date,
order_amount,
nvl(datediff(order_date,last_order_date),0) diff
from
(
select
order_id,
user_id,
user_name,
order_date,
order_amount,
lag(order_date,1,null) over(partition by user_id order by order_date) last_order_date
from order_info
)t1
# 查询所有下单记录以及每个用户的每个下单记录所在月份的首/末次下单日期
select
order_id,
user_id,
user_name,
order_date,
order_amount,
first_value(order_date) over(partition by user_id,substring(order_date,1,7) order by order_date) first_date,
last_value(order_date) over(partition by user_id,substring(order_date,1,7) order by order_date rows between unbounded preceding and unbounded following) last_date
from order_info;
# 为每个用户的所有下单记录按照订单金额进行排名
select
order_id,
user_id,
user_name,
order_date,
order_amount,
rank() over(partition by user_id order by order_amount desc) rk,
dense_rank() over(partition by user_id order by order_amount desc) drk,
row_number() over(partition by user_id order by order_amount desc) rn
from order_info;
7、自定义函数
7.1 介绍
官网文档地址:https://cwiki.apache.org/confluence/display/Hive/HivePlugins
Hive自带了一些函数,比如:max/min等,但是数量有限,自己可以通过自定义UDF来方便的扩展,当Hive提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数(UDF:user-defined function)
根据用户自定义函数类别分为以下三种
- UDF(User-Defined-Function)一进一出
- UDAF(User-Defined Aggregation Function),用户自定义聚合函数,多进一出。类似于:count/max/min
- UDTF(User-Defined Table-Generating Functions),用户自定义表生成函数,一进多出。如lateral view explode()
# 编程步骤如下
#(1)继承Hive提供的类
#org.apache.hadoop.hive.ql.udf.generic.GenericUDF
#org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
#(2)实现类中的抽象方法
#(3)在hive的命令行窗口创建函数
# 添加jar
add jar linux_jar_path
# 创建function。
create [temporary] function [dbname.]function_name AS class_name;
#(4)在hive的命令行窗口删除函数
drop [temporary] function [if exists] [dbname.]function_name;
7.2 自定义UDF函数
需求:自定义一个UDF实现计算给定基本数据类型的长度,例如select my_len("abcd");首先创建一个Maven工程Hive导入依赖(自定义UDTF也是同理)
<dependencies>
<dependency>
<groupId>org.apache.hivegroupId>
<artifactId>hive-execartifactId>
<version>3.1.3version>
dependency>
dependencies>
创建类
/**
* 我们需计算一个要给定基本数据类型的长度
*/
public class MyUDF extends GenericUDF {
/**
* 判断传进来的参数的类型和长度
* 约定返回的数据类型
*/
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
if (arguments.length !=1) {
throw new UDFArgumentLengthException("please give me only one arg");
}
if (!arguments[0].getCategory().equals(ObjectInspector.Category.PRIMITIVE)){
throw new UDFArgumentTypeException(1, "i need primitive type arg");
}
return PrimitiveObjectInspectorFactory.javaIntObjectInspector;
}
/**
* 解决具体逻辑的
*/
@Override
public Object evaluate(DeferredObject[] arguments) throws HiveException {
Object o = arguments[0].get();
if(o==null){
return 0;
}
return o.toString().length();
}
@Override
// 用于获取解释的字符串
public String getDisplayString(String[] children) {
return "";
}
}
# ==================创建临时函数=======================
# 打成jar包上传到服务器/opt/module/hive/datas/myudf.jar
# 将jar包添加到hive的classpath,临时生效
add jar /opt/module/hive/datas/myudf.jar;
# 创建临时函数与开发好的java class关联
create temporary function my_len as "com.atguigu.hive.udf.MyUDF";
# 即可在hql中使用自定义的临时函数
select
ename,
my_len(ename) ename_len
from emp;
# 删除临时函数
drop temporary function my_len;
# 注意:临时函数只跟会话有关系,跟库没有关系。只要创建临时函数的会话不断,在当前会话下,任意一个库都可以使用,其他会话全都不能使用
# ====================创建永久函数=====================
# 注意:因为add jar本身也是临时生效,所以在创建永久函数的时候,需要制定路径(并且因为元数据的原因,这个路径还得是HDFS上的路径)
create function my_len2 as "com.atguigu.hive.udf.MyUDF" using jar "hdfs://hadoop102:8020/udf/myudf.jar";
# 即可在hql中使用自定义的永久函数
select
ename,
my_len2(ename) ename_len
from emp;
# 删除永久函数
drop function my_len2;
# 注意:永久函数跟会话没有关系,创建函数的会话断了以后,其他会话也可以使用。
# 永久函数创建的时候,在函数名之前需要自己加上库名,如果不指定库名的话,会默认把当前库的库名给加上。
# 永久函数使用的时候,需要在指定的库里面操作,或者在其他库里面使用的话加上,库名.函数名。
四、分区、分桶表和文件
1、分区表
Hive中的分区就是把一张大表的数据按照业务需要分散的存储到多个目录,每个目录就称为该表的一个分区。在查询时通过where子句中的表达式选择查询所需要的分区,这样的查询效率会提高很多
1.1 分区表基本语法
create table dept_partition
(
deptno int, --部门编号
dname string, --部门名称
loc string --部门位置
)partitioned by (day string)
row format delimited fields terminated by '\t';
# ======================= 写入数据 =================
# load写法
# 在/opt/module/hive/datas/路径上创建文件dept_20220401.log
vim dept_20220401.log
10 行政部 1700
20 财务部 1800
# 装载语句
load data local inpath '/opt/module/hive/datas/dept_20220401.log' into table dept_partition partition(day='20220401');
# insert写法
# 将day='20220401'分区的数据插入到day='20220402'分区
insert overwrite table dept_partition partition (day = '20220402')
select deptno, dname, loc
from dept_partition
where day = '20220401';
# ========================== 读数据========================
# 查询分区表数据时,可以将分区字段看作表的伪列,可像使用其他字段一样使用分区字段
select deptno, dname, loc ,day
from dept_partition
where day = '20220401';
# ========================分区表基本操作======================
# 查看所有分区信息
show partitions dept_partition;
# 增加分区
alter table dept_partition add partition(day='20220403');
# 同时创建多个分区(分区之间不能有逗号)
alter table dept_partition add partition(day='20220404') partition(day='20220405');
# 删除分区,单个分区
alter table dept_partition drop partition (day='20220403');
# 同时删除多个分区(分区之间必须有逗号)
alter table dept_partition drop partition (day='20220404'), partition(day='20220405');
修复分区
Hive将分区表的所有分区信息都保存在了元数据中,只有元数据与HDFS上的分区路径一致时,分区表才能正常读写数据。若用户手动创建/删除分区路径,Hive都是感知不到的,这样就会导致Hive的元数据和HDFS的分区路径不一致。再比如,若分区表为外部表,用户执行drop partition命令后,分区元数据会被删除,而HDFS的分区路径不会被删除,同样会导致Hive的元数据和HDFS的分区路径不一致。
若出现元数据和HDFS路径不一致的情况,可通过如下几种手段进行修复
- add partition,若手动创建HDFS的分区路径,Hive无法识别,可通过add partition命令增加分区元数据信息,从而使元数据和分区路径保持一致
- drop partition,若手动删除HDFS的分区路径,Hive无法识别,可通过drop partition命令删除分区元数据信息,从而使元数据和分区路径保持一致
- msck,若分区元数据和HDFS的分区路径不一致,还可使用msck命令进行修复
msck repair table table_name [add/drop/sync partitions];
# msck repair table table_name add partitions:该命令会增加HDFS路径存在但元数据缺失的分区信息
# msck repair table table_name drop partitions:该命令会删除HDFS路径已经删除但元数据仍然存在的分区信息
# msck repair table table_name sync partitions:该命令会同步HDFS路径和元数据分区信息,相当于同时执行上述的两个命令
# msck repair table table_name:等价于msck repair table table_name add partitions命令
1.2 二级分区表
# 如果一天内的日志数据量也很大,如何再将数据拆分?答案是二级分区表,例如可以在按天分区的基础上,再对每天的数据按小时进行分区
# 二级分区表建表语句
create table dept_partition2(
deptno int, -- 部门编号
dname string, -- 部门名称
loc string -- 部门位置
)
partitioned by (day string, hour string)
row format delimited fields terminated by '\t';
# 数据装载语句
load data local inpath '/opt/module/hive/datas/dept_20220401.log'
into table dept_partition2
partition(day='20220401', hour='12');
# 查询分区数据
select
*
from dept_partition2
where day='20220401' and hour='12';
1.3 动态分区
动态分区是指向分区表insert数据时,被写往的分区不由用户指定,而是由每行数据的最后一个字段的值来动态的决定。使用动态分区,可只用一个insert语句将数据写入多个分区
# 动态分区功能总开关(默认true,开启)
set hive.exec.dynamic.partition=true
# 严格模式和非严格模式
# 动态分区的模式,默认strict(严格模式),要求必须指定至少一个分区为静态分区,nonstrict(非严格模式)允许所有的分区字段都使用动态分区
set hive.exec.dynamic.partition.mode=nonstrict
# 一条insert语句可同时创建的最大的分区个数,默认为1000
set hive.exec.max.dynamic.partitions=1000
# 单个Mapper或者Reducer可同时创建的最大的分区个数,默认为100
set hive.exec.max.dynamic.partitions.pernode=100
# 一条insert语句可以创建的最大的文件个数,默认100000
hive.exec.max.created.files=100000
# 当查询结果为空时且进行动态分区时,是否抛出异常,默认false
hive.error.on.empty.partition=false
# ========================案例======================
# 需求:将dept表中的数据按照地区(loc字段),插入到目标表dept_partition_dynamic的相应分区中
# 创建目标分区表
create table dept_partition_dynamic(
id int,
name string
)
partitioned by (loc int)
row format delimited fields terminated by '\t';
# 设置动态分区
set hive.exec.dynamic.partition.mode = nonstrict;
insert into table dept_partition_dynamic
partition(loc)
select
deptno,
dname,
loc
from dept;
# 查看目标分区表的分区情况
show partitions dept_partition_dynamic;
2、分桶表
2.1 概述
分区提供一个隔离数据和优化查询的便利方式。不过,并非所有的数据集都可形成合理的分区。对于一张表或者分区,Hive 可以进一步组织成桶,也就是更为细粒度的数据范围划分,分区针对的是数据的存储路径,分桶针对的是数据文件。
分桶表的基本原理是,首先为每行数据计算一个指定字段的数据的hash值,然后模以一个指定的分桶数,最后将取模运算结果相同的行,写入同一个文件中,这个文件就称为一个分桶(bucket)
2.2 分桶表基本语法
# 建表语句
create table stu_buck(
id int,
name string
)
clustered by(id)
into 4 buckets
row format delimited fields terminated by '\t';
# 数据装载
# 在/opt/module/hive/datas/路径上创建student.txt文件
# 说明:Hive新版本load数据可以直接跑MapReduce,老版的Hive需要将数据传到一张表里,再通过查询的方式导入到分桶表里面
load data local inpath '/opt/module/hive/datas/student.txt' into table stu_buck;
# 查看创建的分桶表中是否分成4个桶,即hdfs生成四个文件
2.3 分桶排序表
# 排序是指在分桶的基础上,对每个桶中的数据按照某一列或多列进行排序。排序可以优化查询性能,因为查询可以通过更有效地利用数据的有序性来加速执行。排序可以在创建表格时进行定义,指定排序的列和排序顺序
# 建表语句
create table stu_buck_sort(
id int,
name string
)
clustered by(id) sorted by(id)
into 4 buckets
row format delimited fields terminated by '\t';
load data local inpath '/opt/module/hive/datas/student.txt' into table stu_buck_sort;
3、Hive文件格式
为Hive表中的数据选择一个合适的文件格式,对提高查询性能的提高是十分有益的。Hive表数据的存储格式,可以选择text file、orc、parquet、sequence file等
3.1 Text File
文本文件是Hive默认使用的文件格式,文本文件中的一行内容,就对应Hive表中的一行记录。可通过以下建表语句指定文件格式为文本文件:
create table textfile_table(column_specs) stored as textfile;
3.2 ORC
ORC(Optimized Row Columnar)file format是Hive 0.11版里引入的一种列式存储的文件格式。ORC文件能够提高Hive读写数据和处理数据的性能。与列式存储相对的是行式存
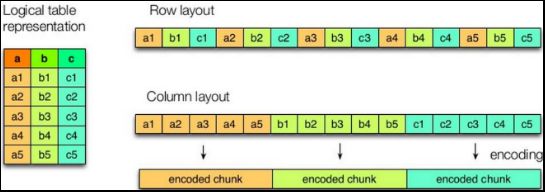
-
行存储的特点
查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。
-
列存储的特点
因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法
前文提到的text file和sequence file都是基于行存储的,orc和parquet是基于列式存储的。orc文件的具体结构如下图所示

每个ORC文件由Header、Body和Tail三部分组成,其中Header内容为ORC,用于表示文件类型。Body由1个或多个stripe组成,每个stripe一般为HDFS的块大小,每一个stripe包含多条记录,这些记录按照列进行独立存储,每个stripe里有三部分组成,分别是Index Data,Row Data,Stripe Footer。
- **Index Data:**一个轻量级的index,默认是为各列每隔1W行做一个索引。每个索引会记录第n万行的位置,和最近一万行的最大值和最小值等信息
- **Row Data:**存的是具体的数据,按列进行存储,并对每个列进行编码,分成多个Stream来存储
- **Stripe Footer:**存放的是各个Stream的位置以及各column的编码信息
Tail由File Footer和PostScript组成。File Footer中保存了各Stripe的其实位置、索引长度、数据长度等信息,各Column的统计信息等;PostScript记录了整个文件的压缩类型以及File Footer的长度信息等。
在读取ORC文件时,会先从最后一个字节读取PostScript长度,进而读取到PostScript,从里面解析到File Footer长度,进而读取FileFooter,从中解析到各个Stripe信息,再读各个Stripe,即从后往前读。
# 建表语句
create table orc_table
(column_specs)
stored as orc
tblproperties (property_name=property_value, ...);
# ORC文件格式支持的参数如下
| 参数 | 默认值 | 说明 |
|---|---|---|
| orc.compress | ZLIB | 压缩格式,可选项:NONE、ZLIB,、SNAPPY,一般和SNAPPY配合 |
| orc.compress.size | 262,144 | 每个压缩块的大小(ORC文件是分块压缩的) |
| orc.stripe.size | 67,108,864 | 每个stripe的大小 |
| orc.row.index.stride | 10,000 | 索引步长(每隔多少行数据建一条索引) |
3.3 parquet
Parquet文件是Hadoop生态中的一个通用的文件格式,它也是一个列式存储的文件格式。Parquet文件的格式如下图所示
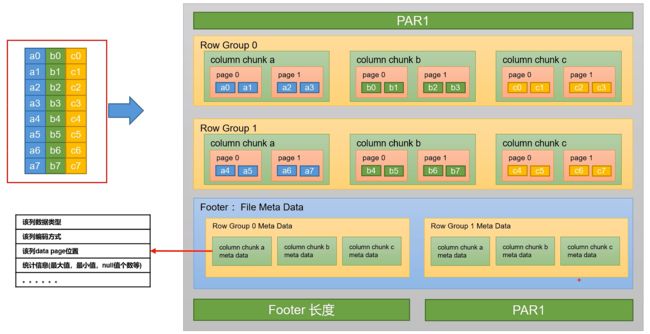
上图展示了一个Parquet文件的基本结构,文件的首尾都是该文件的Magic Code,用于校验它是否是一个Parquet文件。首尾中间由若干个Row Group和一个Footer(File Meta Data)组成。每个Row Group包含多个Column Chunk,每个Column Chunk包含多个Page。以下是Row Group、Column,Chunk和Page三个概念的说明:
- 行组(Row Group):一个行组对应逻辑表中的若干行
- 列块(Column Chunk):一个行组中的一列保存在一个列块中
- 页(Page):一个列块的数据会划分为若干个页
- Footer(File Meta Data)中存储了每个行组(Row Group)中的每个列快(Column Chunk)的元数据信息,元数据信息包含了该列的数据类型、该列的编码方式、该类的Data Page位置等信息。
Create table parquet_table
(column_specs)
stored as parquet
tblproperties (property_name=property_value, ...);
| 参数 | 默认值 | 说明 |
|---|---|---|
| parquet.compression | uncompressed | 压缩格式,可选项:uncompressed,snappy,gzip,lzo,brotli,lz4 |
| parquet.block.size | 134217728 | 行组大小,通常与HDFS块大小保持一致 |
| parquet.page.size | 1048576 | 页大小 |
4、压缩
hive的压缩和hadoop保持一致,详情参考hadoop
| 压缩格式 | 算法 | 文件扩展名 | 是否可切分 |
|---|---|---|---|
| DEFLATE | DEFLATE | .deflate | 否 |
| Gzip | DEFLATE | .gz | 否 |
| bzip2 | bzip2 | .bz2 | 是 |
| LZO | LZO | .lzo | 是 |
| Snappy | Snappy | .snappy | 否 |
4.1 Hive表数据进行压缩
在Hive中,不同文件类型的表,声明数据压缩的方式是不同的
TextFile
若一张表的文件类型为TextFile,若需要对该表中的数据进行压缩,多数情况下,无需在建表语句做出声明。直接将压缩后的文件导入到该表即可,Hive在查询表中数据时,可自动识别其压缩格式,进行解压。需要注意的是,在执行往表中导入数据的SQL语句时,用户需设置以下参数,来保证写入表中的数据是被压缩的
--SQL语句的最终输出结果是否压缩
set hive.exec.compress.output=true;
--输出结果的压缩格式(以下示例为snappy)
set mapreduce.output.fileoutputformat.compress.codec =org.apache.hadoop.io.compress.SnappyCodec;
ORC
若一张表的文件类型为ORC,若需要对该表数据进行压缩,需在建表语句中声明压缩
create table orc_table
(column_specs)
stored as orc
tblproperties ("orc.compress"="snappy");
Parquet
若一张表的文件类型为Parquet,若需要对该表数据进行压缩
create table orc_table
(column_specs)
stored as parquet
tblproperties ("parquet.compression"="snappy");
4.2 计算过程中使用压缩
# 单个MR的中间结果进行压缩
# 单个MR的中间结果是指Mapper输出的数据,对其进行压缩可降低shuffle阶段的网络IO
--开启MapReduce中间数据压缩功能
set mapreduce.map.output.compress=true;
--设置MapReduce中间数据数据的压缩方式(以下示例为snappy)
set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
# 单条SQL语句的中间结果进行压缩
# 单条SQL语句的中间结果是指,两个MR(一条SQL语句可能需要通过MR进行计算)之间的临时数据
--是否对两个MR之间的临时数据进行压缩
set hive.exec.compress.intermediate=true;
--压缩格式(以下示例为snappy)
set hive.intermediate.compression.codec= org.apache.hadoop.io.compress.SnappyCodec;
五、企业级调优
1、计算资源配置
1.1 Yarn资源配置
yarn.nodemanager.resource.memory-mb该参数的含义是,一个NodeManager节点分配给Container使用的内存。该参数的配置,取决于NodeManager所在节点的总内存容量和该节点运行的其他服务的数量,默认8Gyarn.nodemanager.resource.cpu-vcores该参数的含义是,一个NodeManager节点分配给Container使用的CPU核数。该参数的配置,同样取决于NodeManager所在节点的总CPU核数和该节点运行的其他服务,默认8核,一般一个核心对于4gyarn.scheduler.maximum-allocation-mb该参数的含义是,单个Container能够使用的最大内存yarn.scheduler.minimum-allocation-mb该参数的含义是,单个Container能够使用的最小内存
修改$HADOOP_HOME/etc/hadoop/yarn-site.xml文件
<property>
<name>yarn.nodemanager.resource.memory-mbname>
<value>65536value>
property>
<property>
<name>yarn.nodemanager.resource.cpu-vcoresname>
<value>16value>
property>
<property>
<name>yarn.scheduler.maximum-allocation-mbname>
<value>16384value>
property>
<property>
<name>yarn.scheduler.minimum-allocation-mbname>
<value>512value>
property>
1.2 MapReduce资源配置
MapReduce资源配置主要包括Map Task的内存和CPU核数,以及Reduce Task的内存和CPU核数。核心配置参数如下:
mapreduce.map.memory.mb该参数的含义是,单个Map Task申请的container容器内存大小,其默认值为1024。该值不能超出yarn.scheduler.maximum-allocation-mb和yarn.scheduler.minimum-allocation-mb规定的范围。该参数需要根据不同的计算任务单独进行配置,在hive中,可直接使用如下方式为每个SQL语句单独进行配置:
set mapreduce.map.memory.mb=2048;
mapreduce.map.cpu.vcores该参数的含义是,单个Map Task申请的container容器cpu核数,其默认值为1。该值一般无需调整mapreduce.reduce.memory.mb该参数的含义是,单个Reduce Task申请的container容器内存大小,其默认值为1024。该值同样不能超出yarn.scheduler.maximum-allocation-mb和yarn.scheduler.minimum-allocation-mb规定的范围。该参数需要根据不同的计算任务单独进行配置,在hive中,可直接使用如下方式为每个SQL语句单独进行配置:
set mapreduce.reduce.memory.mb=2048;
mapreduce.reduce.cpu.vcores该参数的含义是,单个Reduce Task申请的container容器cpu核数,其默认值为1。该值一般无需调整
2、测试用表
# 资料包自行领取,https://download.csdn.net/download/lemon_TT/87685013
# 订单表(2000w条数据)
drop table if exists order_detail;
create table order_detail(
id string comment '订单id',
user_id string comment '用户id',
product_id string comment '商品id',
province_id string comment '省份id',
create_time string comment '下单时间',
product_num int comment '商品件数',
total_amount decimal(16, 2) comment '下单金额'
)
partitioned by (dt string)
row format delimited fields terminated by '\t';
# 装载
load data local inpath '/opt/module/hive/datas/order_detail.txt' overwrite into table order_detail partition(dt='2020-06-14');
# 支付表(600w条数据)
drop table if exists payment_detail;
create table payment_detail(
id string comment '支付id',
order_detail_id string comment '订单明细id',
user_id string comment '用户id',
payment_time string comment '支付时间',
total_amount decimal(16, 2) comment '支付金额'
)
partitioned by (dt string)
row format delimited fields terminated by '\t';
# 装载
load data local inpath '/opt/module/hive/datas/payment_detail.txt' overwrite into table payment_detail partition(dt='2020-06-14');
# 商品信息表(100w条数据)
drop table if exists product_info;
create table product_info(
id string comment '商品id',
product_name string comment '商品名称',
price decimal(16, 2) comment '价格',
category_id string comment '分类id'
)
row format delimited fields terminated by '\t';
load data local inpath '/opt/module/hive/datas/product_info.txt' overwrite into table product_info;
# 省份信息表(34条数据)
drop table if exists province_info;
create table province_info(
id string comment '省份id',
province_name string comment '省份名称'
)
row format delimited fields terminated by '\t';
load data local inpath '/opt/module/hive/datas/province_info.txt' overwrite into table province_info;
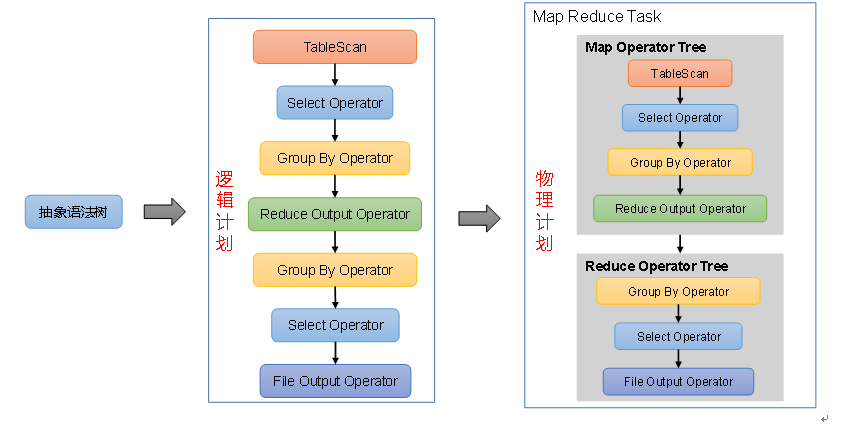
3、Explain查看执行计划(重点)
3.1 Explain执行计划概述
Explain呈现的执行计划,由一系列Stage组成,这一系列Stage具有依赖关系,每个Stage对应一个MapReduce Job,或者一个文件系统操作等。
若某个Stage对应的一个MapReduce Job,其Map端和Reduce端的计算逻辑分别由Map Operator Tree和Reduce Operator Tree进行描述,Operator Tree由一系列的Operator组成,一个Operator代表在Map或Reduce阶段的一个单一的逻辑操作,例如TableScan Operator,Select Operator,Join Operator等
- TableScan:表扫描操作,通常map端第一个操作肯定是表扫描操作
- Select Operator:选取操作
- Group By Operator:分组聚合操作
- Reduce Output Operator:输出到 reduce 操作
- Filter Operator:过滤操作
- Join Operator:join 操作
- File Output Operator:文件输出操作
- Fetch Operator 客户端获取数据操作
3.2 基本用法
EXPLAIN [FORMATTED | EXTENDED | DEPENDENCY] query-sql
# FORMATTED、EXTENDED、DEPENDENCY关键字为可选项,各自作用如下。
# FORMATTED:将执行计划以JSON字符串的形式输出
# EXTENDED:输出执行计划中的额外信息,通常是读写的文件名等信息
# DEPENDENCY:输出执行计划读取的表及分区
explain
select
user_id,
count(*)
from order_detail
group by user_id;
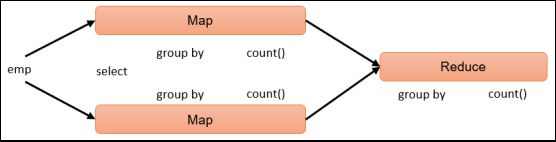
4、 HQL之分组聚合优化
4.1 优化说明
Hive中未经优化的分组聚合,是通过一个MapReduce Job实现的。Map端负责读取数据,并按照分组字段分区,通过Shuffle,将数据发往Reduce端,各组数据在Reduce端完成最终的聚合运算。
Hive对分组聚合的优化主要围绕着减少Shuffle数据量进行,具体做法是map-side聚合。所谓map-side聚合,就是在map端维护一个hash table,利用其完成部分的聚合,然后将部分聚合的结果,按照分组字段分区,发送至reduce端,完成最终的聚合。map-side聚合能有效减少shuffle的数据量,提高分组聚合运算的效率
--启用map-side聚合
set hive.map.aggr=true;
--用于检测源表数据是否适合进行map-side聚合。检测的方法是:先对若干条数据进行map-side聚合,
# 若聚合后的条数和聚合前的条数比值小于该值,则认为该表适合进行map-side聚合;否则,认为该表数据不适合进行map-side聚合,后续数据便不再进行map-side聚合。
set hive.map.aggr.hash.min.reduction=0.5;
--用于检测源表是否适合map-side聚合的条数。
set hive.groupby.mapaggr.checkinterval=100000;
--map-side聚合所用的hash table,占用map task堆内存的最大比例,若超出该值,则会对hash table进行一次flush。
set hive.map.aggr.hash.force.flush.memory.threshold=0.9;
-- 举例
select
product_id,
count(*)
from order_detail
group by product_id;
5、HQL之Join优化
5.1 Join算法概述
Hive拥有多种join算法,包括Common Join,Map Join,Bucket Map Join,Sort Merge Buckt Map Join等
Common Join
Common Join是Hive中最稳定的join算法,其通过一个MapReduce Job完成一个join操作。Map端负责读取join操作所需表的数据,并按照关联字段进行分区,通过Shuffle,将其发送到Reduce端,相同key的数据在Reduce端完成最终的Join操作
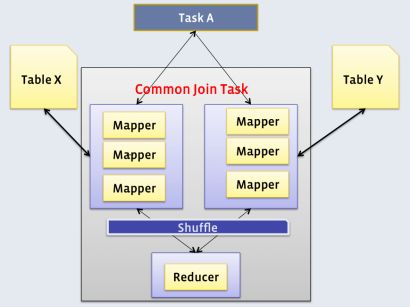
需要注意的是,sql语句中的join操作和执行计划中的Common Join任务并非一对一的关系,一个sql语句中的相邻的且关联字段相同的多个join操作可以合并为一个Common Join任务
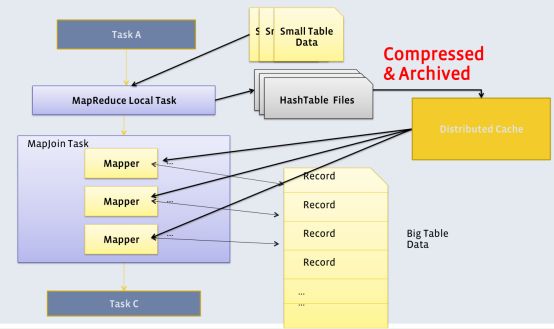
Map Join
Map Join算法可以通过两个只有map阶段的Job完成一个join操作。其适用场景为大表join小表。若某join操作满足要求,则第一个Job会读取小表数据,将其制作为hash table,并上传至Hadoop分布式缓存(本质上是上传至HDFS)。第二个Job会先从分布式缓存中读取小表数据,并缓存在Map Task的内存中,然后扫描大表数据,这样在map端即可完成关联操作
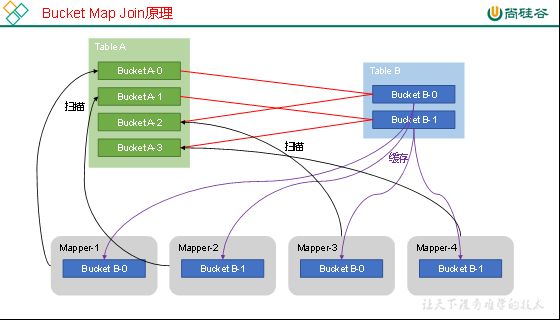
Bucket Map Join
Bucket Map Join是对Map Join算法的改进,其打破了Map Join只适用于大表join小表的限制,可用于大表join大表的场景。Bucket Map Join的核心思想是:若能保证参与join的表均为分桶表,且关联字段为分桶字段,且其中一张表的分桶数量是另外一张表分桶数量的整数倍,就能保证参与join的两张表的分桶之间具有明确的关联关系,所以就可以在两表的分桶间进行Map Join操作了。这样一来,第二个Job的Map端就无需再缓存小表的全表数据了,而只需缓存其所需的分桶即可。
Sort Merge Bucket Map Join
Sort Merge Bucket Map Join(简称SMB Map Join)基于Bucket Map Join。SMB Map Join要求,参与join的表均为分桶表,且需保证分桶内的数据是有序的,且分桶字段、排序字段和关联字段为相同字段,且其中一张表的分桶数量是另外一张表分桶数量的整数倍。
SMB Map Join同Bucket Join一样,同样是利用两表各分桶之间的关联关系,在分桶之间进行join操作,不同的是,分桶之间的join操作的实现原理。Bucket Map Join,两个分桶之间的join实现原理为Hash Join算法;而SMB Map Join,两个分桶之间的join实现原理为Sort Merge Join算法。Hash Join和Sort Merge Join均为关系型数据库中常见的Join实现算法。Hash Join的原理相对简单,就是对参与join的一张表构建hash table,然后扫描另外一张表,然后进行逐行匹配。Sort Merge Join需要在两张按照关联字段排好序的表中进行

Hive中的SMB Map Join就是对两个分桶的数据按照上述思路进行Join操作。可以看出,SMB Map Join与Bucket Map Join相比,在进行Join操作时,Map端是无需对整个Bucket构建hash table,也无需在Map端缓存整个Bucket数据的,每个Mapper只需按顺序逐个key读取两个分桶的数据进行join即可
5.2 Map Join
Map Join有两种触发方式,一种是用户在SQL语句中增加hint提示,另外一种是Hive优化器根据参与join表的数据量大小,自动触发
**Hint提示,**用户可通过如下方式,指定通过map join算法,并且ta将作为map join中的小表。这种方式已经过时,不推荐使用。
select /*+ mapjoin(ta) */
ta.id,
tb.id
from table_a ta
join table_b tb
on ta.id=tb.id;
自动触发
Hive在编译SQL语句阶段,起初所有的join操作均采用Common Join算法实现。之后在物理优化阶段,Hive会根据每个Common Join任务所需表的大小判断该Common Join任务是否能够转换为Map Join任务,若满足要求,便将Common Join任务自动转换为Map Join任务。
但有些Common Join任务所需的表大小,在SQL的编译阶段是未知的(例如对子查询进行join操作),所以这种Common Join任务是否能转换成Map Join任务在编译阶是无法确定的。针对这种情况,Hive会在编译阶段生成一个条件任务(Conditional Task),其下会包含一个计划列表,计划列表中包含转换后的Map Join任务以及原有的Common Join任务。最终具体采用哪个计划,是在运行时决定的
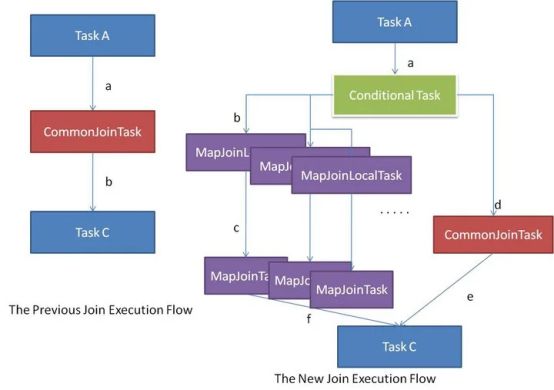

--启动Map Join自动转换
set hive.auto.convert.join=true;
--一个Common Join operator转为Map Join operator的判断条件,若该Common Join相关的表中,存在n-1张表的已知大小总和<=该值,则生成一个Map Join计划,此时可能存在多种n-1张表的组合均满足该条件,
# 则hive会为每种满足条件的组合均生成一个Map Join计划,同时还会保留原有的Common Join计划作为后备(back up)计划,实际运行时,优先执行Map Join计划,若不能执行成功,则启动Common Join后备计划。
set hive.mapjoin.smalltable.filesize=250000;
--开启无条件转Map Join
set hive.auto.convert.join.noconditionaltask=true;
--无条件转Map Join时的小表之和阈值,若一个Common Join operator相关的表中,存在n-1张表的大小总和<=该值,此时hive便不会再为每种n-1张表的组合均生成Map Join计划,同时也不会保留Common Join作为后备计划。而是只生成一个最优的Map Join计划。
set hive.auto.convert.join.noconditionaltask.size=10000000;
优化案例
# 示例
select
*
from order_detail od
join product_info product on od.product_id = product.id
join province_info province on od.province_id = province.id;
# 有三张表进行两次join操作,且两次join操作的关联字段不同。故优化前的执行计划应该包含两个Common Join operator,也就是由两个MapReduce任务实现
# 优化思路
# 可使用如下语句获取表/分区的大小信息
desc formatted table_name partition(partition_col='partition');
# 三张表中,product_info和province_info数据量较小,可考虑将其作为小表,进行Map Join优化
# =====方案一======
# 启用Map Join自动转换
set hive.auto.convert.join=true;
# 不使用无条件转Map Join
set hive.auto.convert.join.noconditionaltask=false;
# 调整hive.mapjoin.smalltable.filesize参数,使其大于等于product_info,会生成多种可能的mapjoin
set hive.mapjoin.smalltable.filesize=25285707;
# =======方案二======
set hive.auto.convert.join=true;
# 使用无条件转Map Join
set hive.auto.convert.join.noconditionaltask=true;
# 调整hive.auto.convert.join.noconditionaltask.size参数,使其大于等于product_info和province_info之和
set hive.auto.convert.join.noconditionaltask.size=25286076;
# 这样可直接将两个Common Join operator转为两个Map Join operator,并且由于两个Map Join operator的小表大小之和小于等于hive.auto.convert.join.noconditionaltask.size,
# 故两个Map Join operator任务可合并为同一个。这个方案计算效率最高,但需要的内存也是最多的
# ========方案三=======
set hive.auto.convert.join=true;
set hive.auto.convert.join.noconditionaltask=true;
# 调整hive.auto.convert.join.noconditionaltask.size参数,使其等于product_info
set hive.auto.convert.join.noconditionaltask.size=25285707;
# 这样可直接将两个Common Join operator转为Map Join operator,但不会将两个Map Join的任务合并。该方案计算效率比方案二低,但需要的内存也更少
5.3 Bucket Map Join
Bucket Map Join不支持自动转换,发须通过用户在SQL语句中提供如下Hint提示,并配置如下相关参数,方可使用
select /*+ mapjoin(ta) */
ta.id,
tb.id
from table_a ta
join table_b tb on ta.id=tb.id;
# 相关参数
--关闭cbo优化,cbo会导致hint信息被忽略
set hive.cbo.enable=false;
--map join hint默认会被忽略(因为已经过时),需将如下参数设置为false
set hive.ignore.mapjoin.hint=false;
--启用bucket map join优化功能
set hive.optimize.bucketmapjoin = true;
两张表都相对较大,若采用普通的Map Join算法,则Map端需要较多的内存来缓存数据,当然可以选择为Map段分配更多的内存,来保证任务运行成功。但是,Map端的内存不可能无上限的分配,所以当参与Join的表数据量均过大时,就可以考虑采用Bucket Map Join算法
5.4 Sort Merge Bucket Map Join
Sort Merge Bucket Map Join有两种触发方式,包括Hint提示和自动转换。Hint提示已过时,不推荐使用
--启动Sort Merge Bucket Map Join优化
set hive.optimize.bucketmapjoin.sortedmerge=true;
--使用自动转换SMB Join
set hive.auto.convert.sortmerge.join=true;
6、HQL之数据倾斜
6.1 数据倾斜概述
数据倾斜问题,通常是指参与计算的数据分布不均,即某个key或者某些key的数据量远超其他key,导致在shuffle阶段,大量相同key的数据被发往同一个Reduce,进而导致该Reduce所需的时间远超其他Reduce,成为整个任务的瓶颈。
6.2 分组聚合导致的数据倾斜
Hive中未经优化的分组聚合,是通过一个MapReduce Job实现的。Map端负责读取数据,并按照分组字段分区,通过Shuffle,将数据发往Reduce端,各组数据在Reduce端完成最终的聚合运算。如果group by分组字段的值分布不均,就可能导致大量相同的key进入同一Reduce,从而导致数据倾斜问题,由分组聚合导致的数据倾斜问题,有以下两种解决思路:Map-Side聚合和Skew-GroupBy优化
Map-Side聚合
开启Map-Side聚合后,数据会现在Map端完成部分聚合工作。这样一来即便原始数据是倾斜的,经过Map端的初步聚合后,发往Reduce的数据也就不再倾斜了。最佳状态下,Map-端聚合能完全屏蔽数据倾斜问题
--启用map-side聚合,默认开启的,若想看到数据倾斜的现象,需要先将hive.map.aggr参数设置为false
set hive.map.aggr=true;
--用于检测源表数据是否适合进行map-side聚合。检测的方法是:先对若干条数据进行map-side聚合,若聚合后的条数和聚合前的条数比值小于该值,则认为该表适合进行map-side聚合;否则,认为该表数据不适合进行map-side聚合,后续数据便不再进行map-side聚合。
set hive.map.aggr.hash.min.reduction=0.5;
--用于检测源表是否适合map-side聚合的条数。
set hive.groupby.mapaggr.checkinterval=100000;
--map-side聚合所用的hash table,占用map task堆内存的最大比例,若超出该值,则会对hash table进行一次flush。
set hive.map.aggr.hash.force.flush.memory.threshold=0.9;
Skew-GroupBy优化
Skew-GroupBy的原理是启动两个MR任务,第一个MR按照随机数分区,将数据分散发送到Reduce,完成部分聚合,第二个MR按照分组字段分区,完成最终聚合
--启用分组聚合数据倾斜优化
set hive.groupby.skewindata=true;
6.3 Join导致的数据倾斜
未经优化的join操作,默认是使用common join算法,也就是通过一个MapReduce Job完成计算。Map端负责读取join操作所需表的数据,并按照关联字段进行分区,通过Shuffle,将其发送到Reduce端,相同key的数据在Reduce端完成最终的Join操作。如果关联字段的值分布不均,就可能导致大量相同的key进入同一Reduce,从而导致数据倾斜问题。由join导致的数据倾斜问题,有如下几种解决方案
map join
使用map join算法,join操作仅在map端就能完成,没有shuffle操作,没有reduce阶段,自然不会产生reduce端的数据倾斜。该方案适用于大表join小表时发生数据倾斜的场景
--启动Map Join自动转换
set hive.auto.convert.join=true;
--一个Common Join operator转为Map Join operator的判断条件,若该Common Join相关的表中,存在n-1张表的大小总和<=该值,则生成一个Map Join计划,此时可能存在多种n-1张表的组合均满足该条件,则hive会为每种满足条件的组合均生成一个Map Join计划,同时还会保留原有的Common Join计划作为后备(back up)计划,实际运行时,优先执行Map Join计划,若不能执行成功,则启动Common Join后备计划。
set hive.mapjoin.smalltable.filesize=250000;
--开启无条件转Map Join
set hive.auto.convert.join.noconditionaltask=true;
--无条件转Map Join时的小表之和阈值,若一个Common Join operator相关的表中,存在n-1张表的大小总和<=该值,此时hive便不会再为每种n-1张表的组合均生成Map Join计划,同时也不会保留Common Join作为后备计划。而是只生成一个最优的Map Join计划。
set hive.auto.convert.join.noconditionaltask.size=10000000;
skew join
skew join的原理是,为倾斜的大key单独启动一个map join任务进行计算,其余key进行正常的common join

--启用skew join优化
set hive.optimize.skewjoin=true;
--触发skew join的阈值,若某个key的行数超过该参数值,则触发
set hive.skewjoin.key=100000;
-- 这种方案对参与join的源表大小没有要求,但是对两表中倾斜的key的数据量有要求,要求一张表中的倾斜key的数据量比较小(方便走mapjoin)
调整SQL语句
若参与join的两表均为大表,其中一张表的数据是倾斜的,此时也可通过以下方式对SQL语句进行相应的调整
-- 相同的id的进入同一个reducer进行后序操作
select
*
from A
join B
on A.id=B.id;
-- 调整sql
select
*
from(
select --打散操作
concat(id,'_',cast(rand()*2 as int)) id,
value
from A
)ta
join(
select --扩容操作
concat(id,'_',0) id,
value
from B
union all
select
concat(id,'_',1) id,
value
from B
)tb
on ta.id=tb.id;
7、HQL之任务并行度
对于一个分布式的计算任务而言,设置一个合适的并行度十分重要。Hive的计算任务由MapReduce完成,故并行度的调整需要分为Map端和Reduce端
7.1 Map端并行度
Map端的并行度,也就是Map的个数。是由输入文件的切片数决定的。一般情况下,Map端的并行度无需手动调整。以下特殊情况可考虑调整map端并行度
- 查询的表中存在大量小文件
按照Hadoop默认的切片策略,一个小文件会单独启动一个map task负责计算。若查询的表中存在大量小文件,则会启动大量map task,造成计算资源的浪费。这种情况下,可以使用Hive提供的CombineHiveInputFormat,多个小文件合并为一个切片,从而控制map task个数,默认开启
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
- map端有复杂的查询逻辑
若SQL语句中有正则替换、json解析等复杂耗时的查询逻辑时,map端的计算会相对慢一些。若想加快计算速度,在计算资源充足的情况下,可考虑增大map端的并行度,令map task多一些,每个map task计算的数据少一些
--一个切片的最大值,默认256M
set mapreduce.input.fileinputformat.split.maxsize=256000000;
7.2 Reduce端并行度
Reduce端的并行度,也就是Reduce个数。相对来说,更需要关注。Reduce端的并行度,可由用户自己指定,也可由Hive自行根据该MR Job输入的文件大小进行估算
--指定Reduce端并行度,默认值为-1,表示用户未指定
set mapreduce.job.reduces;
--Reduce端并行度最大值
set hive.exec.reducers.max;
--单个Reduce Task计算的数据量,用于估算Reduce并行度
set hive.exec.reducers.bytes.per.reducer;

8、HQL之小文件合并
小文件合并优化,分为两个方面,分别是Map端输入的小文件合并,和Reduce端输出的小文件合并
8.1 Map端输入文件合并
合并Map端输入的小文件,是指将多个小文件划分到一个切片中,进而由一个Map Task去处理。目的是防止为单个小文件启动一个Map Task,浪费计算资源
--可将多个小文件切片,合并为一个切片,进而由一个map任务处理
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
8.2 Reduce输出文件合并
合并Reduce端输出的小文件,是指将多个小文件合并成大文件。目的是减少HDFS小文件数量。其原理是根据计算任务输出文件的平均大小进行判断,若符合条件,则单独启动一个额外的任务进行合并
--开启合并map only任务输出的小文件,默认false
set hive.merge.mapfiles=true;
--开启合并map reduce任务输出的小文件,默认false
set hive.merge.mapredfiles=true;
--合并后的文件大小
set hive.merge.size.per.task=256000000;
--触发小文件合并任务的阈值,若某计算任务输出的文件平均大小低于该值,则触发合并
set hive.merge.smallfiles.avgsize=16000000;
9、其他优化
9.1 CBO优化
CBO是指Cost based Optimizer,即基于计算成本的优化。在Hive中,计算成本模型考虑到了:数据的行数、CPU、本地IO、HDFS IO、网络IO等方面。Hive会计算同一SQL语句的不同执行计划的计算成本,并选出成本最低的执行计划。目前CBO在hive的MR引擎下主要用于join的优化,例如多表join的join顺序
--是否启用cbo优化,默认开启
set hive.cbo.enable=true;
-- 示例演示
select
*
from order_detail od
join product_info product on od.product_id=product.id
join province_info province on od.province_id=province.id;
--关闭cbo优化
set hive.cbo.enable=false;
--为了测试效果更加直观,关闭map join自动转换
set hive.auto.convert.join=false;
--开启cbo优化
set hive.cbo.enable=true;
--为了测试效果更加直观,关闭map join自动转换
set hive.auto.convert.join=false;
-- CBO优化对于执行计划中join顺序是有影响的,其之所以会将province_info的join顺序提前,是因为province info的数据量较小,
-- 将其提前,会有更大的概率使得中间结果的数据量变小,从而使整个计算任务的数据量减小,也就是使计算成本变小
9.2 谓词下推
谓词下推(predicate pushdown)是指,尽量将过滤操作前移,以减少后续计算步骤的数据量
--是否启动谓词下推(predicate pushdown)优化
set hive.optimize.ppd = true;
-- CBO优化也会完成一部分的谓词下推优化工作,因为在执行计划中,谓词越靠前,整个计划的计算成本就会越低
-- 测试实例
--是否启动谓词下推(predicate pushdown)优化
set hive.optimize.ppd = false;
--为了测试效果更加直观,关闭cbo优化
set hive.cbo.enable=false;
9.3 矢量化查询
Hive的矢量化查询优化,依赖于CPU的矢量化计算。Hive的矢量化查询,可以极大的提高一些典型查询场景(例如scans, filters, aggregates, and joins)下的CPU使用效率。参考:https://cwiki.apache.org/confluence/display/Hive/Vectorized+Query+Execution#VectorizedQueryExecution-Limitations
-- 若执行计划中,出现“Execution mode: vectorized”字样,即表明使用了矢量化计算
set hive.vectorized.execution.enabled=true;
9.4 Fetch抓取
Fetch抓取是指,Hive中对某些情况的查询可以不必使用MapReduce计算。例如:select * from emp;在这种情况下,Hive可以简单地读取emp对应的存储目录下的文件,然后输出查询结果到控制台
--是否在特定场景转换为fetch 任务
--设置为none表示不转换
--设置为minimal表示支持select *,分区字段过滤,Limit等
--设置为more表示支持select 任意字段,包括函数,过滤,和limit等
set hive.fetch.task.conversion=more;
9.5 本地模式
大多数的Hadoop Job是需要Hadoop提供的完整的可扩展性来处理大数据集的。不过,有时Hive的输入数据量是非常小的。在这种情况下,为查询触发执行任务消耗的时间可能会比实际job的执行时间要多的多。对于大多数这种情况,Hive可以通过本地模式在单台机器上处理所有的任务。对于小数据集,执行时间可以明显被缩短
--开启自动转换为本地模式
set hive.exec.mode.local.auto=true;
--设置local MapReduce的最大输入数据量,当输入数据量小于这个值时采用local MapReduce的方式,默认为134217728,即128M
set hive.exec.mode.local.auto.inputbytes.max=50000000;
--设置local MapReduce的最大输入文件个数,当输入文件个数小于这个值时采用local MapReduce的方式,默认为4
set hive.exec.mode.local.auto.input.files.max=10;
9.6 并行执行
Hive会将一个SQL语句转化成一个或者多个Stage,每个Stage对应一个MR Job。默认情况下,Hive同时只会执行一个Stage。但是某SQL语句可能会包含多个Stage,但这多个Stage可能并非完全互相依赖,也就是说有些Stage是可以并行执行的。此处提到的并行执行就是指这些Stage的并行执行
--启用并行执行优化
set hive.exec.parallel=true;
--同一个sql允许最大并行度,默认为8
set hive.exec.parallel.thread.number=8;
9.7 严格模式
Hive可以通过设置某些参数防止危险操作
- 分区表不使用分区过滤
将hive.strict.checks.no.partition.filter设置为true时,对于分区表,除非where语句中含有分区字段过滤条件来限制范围,否则不允许执行。换句话说,就是用户不允许扫描所有分区。进行这个限制的原因是,通常分区表都拥有非常大的数据集,而且数据增加迅速。没有进行分区限制的查询可能会消耗令人不可接受的巨大资源来处理这个表。
- 使用order by没有limit过滤
将hive.strict.checks.orderby.no.limit设置为true时,对于使用了order by语句的查询,要求必须使用limit语句。因为order by为了执行排序过程会将所有的结果数据分发到同一个Reduce中进行处理,强制要求用户增加这个limit语句可以防止Reduce额外执行很长一段时间(开启了limit可以在数据进入到Reduce之前就减少一部分数据)。
- 笛卡尔积
将hive.strict.checks.cartesian.product设置为true时,会限制笛卡尔积的查询。对关系型数据库非常了解的用户可能期望在执行JOIN查询的时候不使用ON语句而是使用where语句,这样关系数据库的执行优化器就可以高效地将WHERE语句转化成那个ON语句。不幸的是,Hive并不会执行这种优化,因此,如果表足够大,那么这个查询就会出现不可控的情况。
# 可以进入hive-site.xml修改
<property>
<name>hive.exec.dynamic.partition.mode</name>
<value>nonstrict</value>
</property>
六、实战案例
详情可以查看:https://download.csdn.net/download/lemon_TT/87685013
1、同时在线人数问题
现有各直播间的用户访问记录表(live_events)如下,表中每行数据表达的信息为,一个用户何时进入了一个直播间,又在何时离开了该直播间,现要求统计各直播间最大同时在线人数
drop table if exists live_events;
create table if not exists live_events
(
user_id int comment '用户id',
live_id int comment '直播id',
in_datetime string comment '进入直播间时间',
out_datetime string comment '离开直播间时间'
)comment '直播间访问记录';
select
live_id,
max(user_count) max_user_count
from
(
select
user_id,
live_id,
sum(user_change) over(partition by live_id order by event_time) user_count
from
(
select user_id,
live_id,
in_datetime event_time,
1 user_change
from live_events
union all
select user_id,
live_id,
out_datetime,
-1
from live_events
)t1
)t2
group by live_id;
2、会话划分问题
现有页面浏览记录表(page_view_events),表中有每个用户的每次页面访问记录,规定若同一用户的相邻两次访问记录时间间隔小于60s,则认为两次浏览记录属于同一会话。现有如下需求,为属于同一会话的访问记录增加一个相同的会话id字段
drop table if exists page_view_events;
create table if not exists page_view_events
(
user_id int comment '用户id',
page_id string comment '页面id',
view_timestamp bigint comment '访问时间戳'
)comment '页面访问记录';
select user_id,
page_id,
view_timestamp,
concat(user_id, '-', sum(session_start_point) over (partition by user_id order by view_timestamp)) session_id
from (
select user_id,
page_id,
view_timestamp,
if(view_timestamp - lagts >= 60, 1, 0) session_start_point
from (
select user_id,
page_id,
view_timestamp,
lag(view_timestamp, 1, 0) over (partition by user_id order by view_timestamp) lagts
from page_view_events
) t1
) t2;
3、间断连续登录用户问题
现有各用户的登录记录表(login_events),表中每行数据表达的信息是一个用户何时登录了平台,现要求统计各用户最长的连续登录天数,间断一天也算作连续,例如:一个用户在1,3,5,6登录,则视为连续6天登录。
drop table if exists login_events;
create table if not exists login_events
(
user_id int comment '用户id',
login_datetime string comment '登录时间'
)comment '直播间访问记录';
select
user_id,
max(recent_days) max_recent_days --求出每个用户最大的连续天数
from
(
select
user_id,
user_flag,
datediff(max(login_date),min(login_date)) + 1 recent_days --按照分组求每个用户每次连续的天数(记得加1)
from
(
select
user_id,
login_date,
lag1_date,
concat(user_id,'_',flag) user_flag --拼接用户和标签分组
from
(
select
user_id,
login_date,
lag1_date,
sum(if(datediff(login_date,lag1_date)>2,1,0)) over(partition by user_id order by login_date) flag --获取大于2的标签
from
(
select
user_id,
login_date,
lag(login_date,1,'1970-01-01') over(partition by user_id order by login_date) lag1_date --获取上一次登录日期
from
(
select
user_id,
date_format(login_datetime,'yyyy-MM-dd') login_date
from login_events
group by user_id,date_format(login_datetime,'yyyy-MM-dd') --按照用户和日期去重
)t1
)t2
)t3
)t4
group by user_id,user_flag
)t5
group by user_id;
4、日期交叉问题
现有各品牌优惠周期表(promotion_info),其记录了每个品牌的每个优惠活动的周期,其中同一品牌的不同优惠活动的周期可能会有交叉,现要求统计每个品牌的优惠总天数,若某个品牌在同一天有多个优惠活动,则只按一天计算
drop table if exists promotion_info;
create table promotion_info
(
promotion_id string comment '优惠活动id',
brand string comment '优惠品牌',
start_date string comment '优惠活动开始日期',
end_date string comment '优惠活动结束日期'
) comment '各品牌活动周期表';
select
brand,
sum(datediff(end_date,start_date)+1) promotion_day_count
from
(
select
brand,
max_end_date,
if(max_end_date is null or start_date>max_end_date,start_date,date_add(max_end_date,1)) start_date,
end_date
from
(
select
brand,
start_date,
end_date,
max(end_date) over(partition by brand order by start_date rows between unbounded preceding and 1 preceding) max_end_date
from promotion_info
)t1
)t2
where end_date>start_date
group by brand;