ceph之rados设计原理与实现第六章:移动的对象载体——PG
PG相关重要概念

Log有一个队列,顺序记录了该PG接受的所有客户端写请求,Info则记录了该PG的Log队列最新和最旧的日志指针。
Info是PG的元数据
PG有几个副本,就有几个实例,其中有一个Primary,每个实例都有Info,Log队列。
 关于Acting、Up、PG Temp:Up包含的是由Crush计算出来的OSD序列,如果计算出的OSD不合理,比如新加入的OSD没有PG的历史副本,那么就会选择合理的OSD加入PG Temp,显示指定Acting。这样就造成了Acting与Up不一致的Remapped状态。
关于Acting、Up、PG Temp:Up包含的是由Crush计算出来的OSD序列,如果计算出的OSD不合理,比如新加入的OSD没有PG的历史副本,那么就会选择合理的OSD加入PG Temp,显示指定Acting。这样就造成了Acting与Up不一致的Remapped状态。
又比如OSD故障,那么CRUSH会重新计算新的OSD作为Up的元素,此时PG存在降级对象,PG状态为降级状态Degraded。如果此时Acting再与Up不一致,则是Remapped+Degraded状态。
关于Peering、Recovery、Backfill:Peering确保PG的所有对象副本在OSD间的一致性,但为了尽快恢复业务(Peering时无法接受客户端读写请求,所以Peering时间要尽可能短),Peering过程标记出降级的PG(比如OSD故障导致PG降级)即可算完成,之后这些故障的OSD上面的数据需要通过增量日志或者全量同步的方式恢复到由CRUSH或者PG Temp计算出的新OSD上,会触发Recovery或Backfill,数据恢复的过程就是Recovery或Backfill。
关于Interval:单个Interval用于指示一个相对稳定的PG映射周期,在此期间,PG的Up与Acting、关联的存储池副本数、最小副本数以及PG数量等也没有发生变化。生成Interval的规则也比较简单,每次PG从OSD获取当前待更新的新OSDMap时,我们取其中PG关联存储池的副本数、最小副本数和PG数目,并基于CRUSH重新计算PG的Acting、Acting Primary、Up、Up Primary,然后与前一个相邻的OSDMap进行比较(epoch小一),如果上述参数中任意一个发生变化,则说明老的Interval结束,新的Interval开始,此时可以完善老的Interval中诸如first、last、acting、primary、up、up_primary、maybe_went_rw等信息。
1 PG的读写流程
每个对象对应唯一一个PG,一个PG包含多个对象,一个存储池包含多个PG,一个PG对应多个OSD(多副本,一个Primary OSD)。
第五章提到了,read、write这类BlueStore提供的API他们的粒度都是PG,PG是连接客户端与BlueStore的桥梁,PG负责将所有来自客户端的请求转换为能够被ObjectStore理解的事务,并在OSD之间分发与同步。
在第五章中提到,对于BlueStore,通过queue_transactions接口向BlueStore提交事务组完成一系列写请求。
以上跟事务相关只涉及写操作,因为只有修改操作才会改变状态导致状态不一致。
PG读写流程分一下几个阶段:
1)客户端基于对象标识中32位哈希值,通过stable_mod找到存储池中承载该对象的PGID,然后使用该PGID作为CRUSH的输入,找到对应PG当前Primary所在的OSD并发送读写请求。
2)OSD收到客户端发送的读写请求,将其封装为一个op,并基于其携带的PGID将其转发至对应的PG
3)PG收到op后,完成一系列检查,所有条件均满足后,开始真正执行op。
4)如果op只包含读操作,那么直接执行同步读(对应多副本)或者异步读(对应纠删码),见第五章read,等待读操作完成后由Primary向客户端应答。
5)如果op包含写操作,则由Primary基于op生成一个针对原始对象操作的PG事务,然后将其提交至PGBackend,由后者按照备份策略转化为每个副本真正需要执行的本地事务(应该指的是调用queue_transactions),并进行分发。当Primary收到所有副本的写入完成应答之后,对应op执行完成,由Primary向客户端回应写入完成。
其中,执行op又可以分为:
1.获取对象上下文,创建内存结构OpContext。
2.事务准备
3.事务分发与同步
其中事务准备又可以分为:
1.校验
2.更新OpContext的OI、SS(读写请求会导致对象元数据OI、SS产生变化)、将op操作转化生成存储后端可以认识的本地事务write、create、read事务,将op操作的日志添加至OpContext的Log。
而事务的同步则是第五章,以BlueStore为例,执行上述生成的已经分发到本地的本地事务write、read等事务,同步OpContext中的对象元数据OI、SS以及对象元数据Onode于数据库,完成用户数据落盘等。
与第五章的联系:
PGTransaction(op携带的write操作被do_osd_op转化为PGTransaction)PGTransaction拥有一个safe_create_traverse接口可以方便转化为存储后端认识的本地事务,比如第五章的queue_transactions会将这些BlueStore本地事务进行提交成事务组,由事务上下文TransContext异步批量处理
1.1 重要属性op、Log、OI、SS
1.1.1 对象属性OI、SS(磁盘结构)


上图结构是对象OI的磁盘结构,保存对象除快照之外的元数据。
如果该对象是克隆对象,snaps记录了其关联的快照集合,也就是这些快照回滚会回滚到该克隆对象。

上图是对象的SS属性的磁盘结构,保存对象快照及克隆信息。
clones记录了克隆对象以及与之关联的快照集合

当提到元数据,就应该回想起第五章,Ceph中BlueStore的对象元数据Onode等以及WAL日志都是利用BlueFS提供的基本API(read、write)存储在RocksDB中,同时也一定有一个对应的内存副本以支持同步至数据库。
虽然关于对象OI、SS属性的元数据并不局限于一种特定的存储后端,但是以BlueStore为例,它和Onode一样仍然是对象的元数据,所以也会有对应的内存结构用于同步于数据库RocksDB。
由于PG的读写会导致对象的元数据OI、SS变化,需要将这部分变化更新至数据库。
后面关于事务准备的描述可以看到,事务准备主要做的工作,就是将对象的OI、SS属性的内存副本更新至最新,再由第五章介绍的write函数,将内存副本的同步至数据库。
1.1.2 对象属性OI、SS(内存版本)


后面PG读写流程很大一部分都是为了更新由于读写造成对象元数据OI、SS变化的OI、SS内存版本,而他们的内存版本,存储在内存结构OpContext中。
1.1.3 OpContext
为方便起见,PG将所有来自客户端的请求和集群内部诸如执行数据恢复、Scrub等任务产生的请求都统称为op。
而OpContext是对op进一步的封装,驻留与内存。
所以op不是OpContext。
OpContext中保存了执行前后对象的属性(OI)和对象的快照和克隆信息(SS)、日志Log的集合
引入op的意义:
1)单个op可能操作多个对象(同一个对象的head对象、克隆对象),需要分别记录对应对象上下文的变化
2)如果op涉及写操作,那么会产生一条或多条新的日志(创建克隆对象)
3)如果op设计异步操作,那么需要注册一个或者多个回调函数
4)收集op相关的统计,例如读写次数、读写涉及的字节数等,并周期性地上报给Monitor,用于监控集群IOPS、带宽等。
PG处理op,即可完成一次读写I/O
1.1.4 Log
Log存储在对象的元数据omap中,每个PG的log条目由队列顺序存储指针,归属于对象的log条目存储在对象的元数据omap中。
Log基于Eversion顺序记录了所有客户端写请求的概要信息,作为故障恢复时副本之间实施增量同步(即Recovery)的依据
Log顺序记录了客户端写请求的概要信息,使用PG元数据对象的omap保存。上图是单个日志条目。
日志条目:op有五种类型的修改操作,soid为修改的对象标识,version为此次修改操作生效后的版本号。
修改操作LOST_DELETE是修复pg命令触发的,revert表示回滚到最新版本,reverting_to保存该最新版本,delete表示直接删除
Log保存的是PGTransaction(op携带的write操作被do_osd_op转化为PGTransaction)PGTransaction拥有一个safe_create_traverse接口可以方便转化为存储后端认识的本地事务,比如第五章的queue_transactions会将这些BlueStore本地事务进行提交成事务组,由事务上下文TransContext异步批量处理
1.2 消息接收与分发
每个客户端的读写请求首先被OSD封装成一个op,然后按其携带的PGID投递至某个op_shardedwq队列进行处理。
假定op_sharededwq中实际工作队列数目为s,每个工作队列需要安排t个服务线程,则简单将PGID针对队列个数s取模,即可实现PG与某个io_sharededwq队列间接绑定,使得归属同一个PG的op都进入同一个工作队列排队,这样一方面可以避免乱序,一方面也可以便于实施优先级控制。
每个工作队列内部按优先级被划分为多个优先级队列,按阈值分为严格优先级队友和普通优先级队列,每个优先级队列按照op携带的客户端地址再次划分为若干个会话子队列

比如上图,有五个工作队列,s=5,阈值为7,严格优先级队列有7、8、9、10,普通优先级队列有1、2、3。优先级1队列按客户端地址升序排列了三个会话子队列。会话子队列成员是相应客户端发送来的op。
只有严格优先级队列为空时,才能继续出队普通优先级队列中的op,
对于严格优先级队列,总是从优先级最高开始出队;
对于普通优先级队列,从哪个普通优先级队列出队完全随机,但优先级越高,概率越大
op从队列出队后,相应的服务线程被唤醒,op被转发给PG,PG开始真正处理op,处理op是一段复杂的函数调用链。
1.3 do_request
do_request作为PG处理op的第一步,主要完成一些PG级别的检查

1.4 do_op
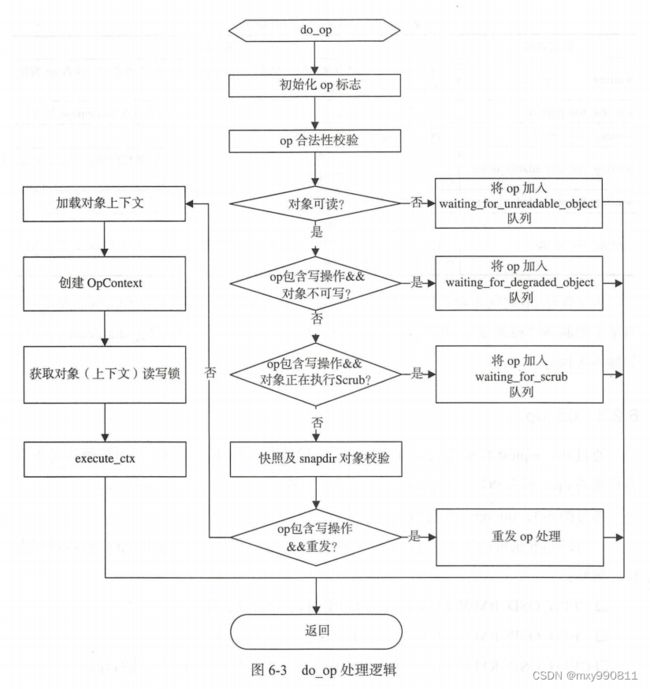
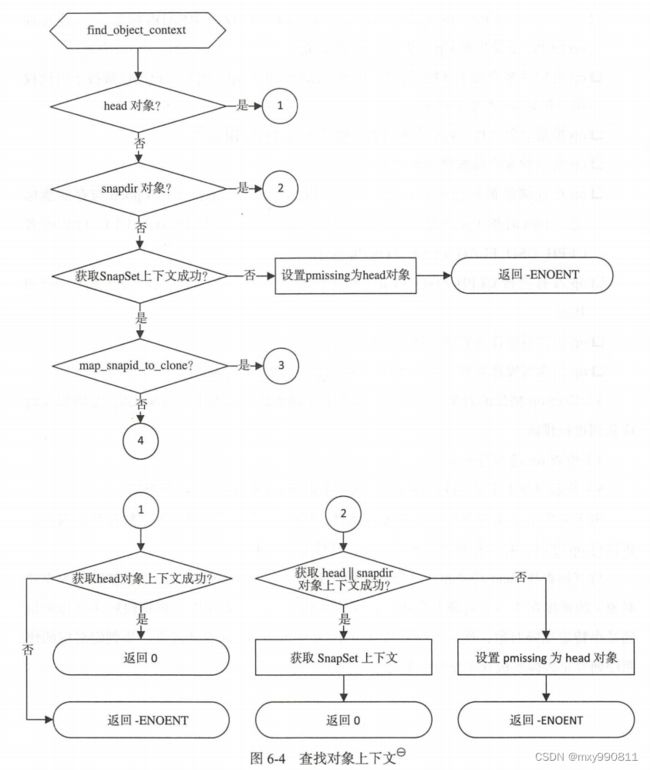
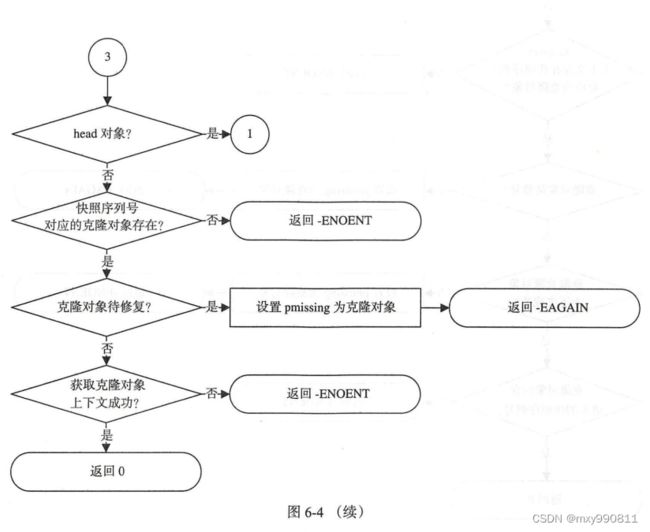
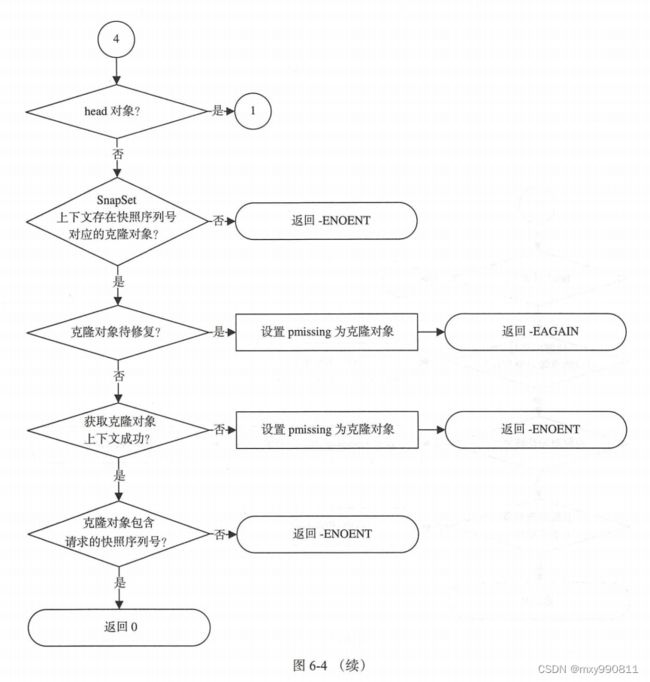
do_op创建了OpContext,由于OpContext保存了OI和SS,所以需要先获取对象上下文(OI和SS)才能创建,这个OI可以是head对象(原始对象)属性也可以是克隆对象属性。SS则是对象的快照和克隆信息。
1.5 execute_ctx
成功获取对象上下文后,可以通过execute_ctx正式执行OpContext。

引入快照机制后,如果修改的对象存在快照,为了支持快照回滚操作,一般需要先针对原始对象执行克隆,然后才真正改写原始对象。
所以如果是写操作,需要更新op中记录的对象关联快照的信息。
execute_ctx最关键的步骤是prepare_transcation,事务准备。
事务是用于保证数据一致性最常用的手段(修改操作要么全部执行,要么全不执行,All Or Nothing),与单个OSD由ObjectStore这类事务型4本地对象存储系统负责保护数据一致性不同(单节点的All Or Noting)不同,为了保证多节点间的数据一致性即分布式一致性(多节点的All Or Nothing),则必须依赖依赖PG实现分布式的事务语义。因此客户端针对原始对象的读写请求,首先将被转化为一个PG事务,用于保证分布式一致性,然后再由Primary统一转化为各个副本的本地事务,用于保证副本的本地一致性。
其中对于读事务,同步读(多副本)在事务准备阶段就完成,直接向客户端应答,异步读(纠删码)读事务完成后再向客户端应答。
对于写事务,则由Primary负责执行副本间的本地事务分发与同步。在PG事务被转化为本地事务后,由Primary牵头,将op对应的OpContext升级为RepGather,并通过issue_repop在副本间进行分发,之后由每个副本的本地事务完成应答消息驱动,Primary不断通过eval_repop评估RepGather的当前进展,直至事务在副本之间的同步最终完成。
每个op通过如下3个步骤被转化为一个完整的PG事务:
1)do_osd_ops负责将op携带的每个操作转化为PGTransaction中的操作;
2)make_writable负责处理快照相关逻辑
3)finish_ctx则检查是否需要创建或者删除snapdir对象,生成日志,并刷新对象的OI与SS属性

生成的PGTransaction会依靠接口safe_create_traverse转化为本地事务。

make_writable:创建克隆对象,更新内存结构OpContext中的SS、Log,生成对克隆对象操作的事务

更新内存结构OpContext中的OI、对象上下文ObjectContext、Log
2.PG状态迁移
Peering
Peering有五个重要的概念
分别是past_intervals、getinfo、getlog、getmissing、activate。
他们的逻辑分别是:
past_intervals解释了什么时候peering、
GetInfo:Primary向PriorSet(参与peering的副本集合)各个副本发送Query收集Info
GetLog:Primary根据收集的Info选出权威日志
GetMissing:Primary根据权威日志与每个副本本地日志合并,来获取每个副本的missing(记录了该副本所有需要Recovery的对象信息)
Activate:固化更新后的Info(比如last_epoch_started,记录了该副本上次完成Peering的Epoch)、日志(权威日志和本地日志合并的结果、missing)于本地磁盘
Activate之后,对应的PG就可以接受读写请求或Recovery或Backfill。
1. past_intervals
此概念可以引出什么时候进行PG的Peering
判断是否需要重启Peering的法则比较简单,只要检查本次OSDMap更新之后是否会触发PG进入一个新的Interval即可。
单个Interval用于指示一个相对稳定的PG映射周期,在此期间,PG的Up与Acting、关联的存储池副本数、最小副本数以及PG数量等也没有发生变化。生成Interval的规则也比较简单,每次PG从OSD获取当前待更新的新OSDMap时,我们取其中PG关联存储池的副本数、最小副本数和PG数目,并基于CRUSH重新计算PG的Acting、Acting Primary、Up、Up Primary,然后与前一个相邻的OSDMap进行比较(epoch小一),如果上述参数中任意一个发生变化,则说明老的Interval结束,新的Interval开始,此时可以完善老的Interval中诸如first、last、acting、primary、up、up_primary、maybe_went_rw等信息。
由于客户端接受读写请求是异步执行的,所以在执行Peering时,存在一种可能即past_intervals中部分intervals期间,peering成功后客户端接收了读写请求但未完成,所以Peering期间就要获取past_intervals中的读写请求,这也是maybe_went_rw参数的意义,当新Intervals产生后,就需要设置旧Intervals的参数包括maybe_went_rw。
一旦maybe_went_rw为True,这表明该Interval期间可能接受过读写请求,需要Peering期间询问对应OSD以确认这些读写请求。
maybe_went_rw为False则可以跳过该Intervals,加速Peering,但可能会错过读写请求造成数据丢失
以Acting Primary存在,Acting中的副本个数不小于存储池最小副本数这两个规则来设置maybe_went_rw为True存在一个问题,那就是Mointer检测OSD宕掉有滞后,Acting可能会记录已经宕掉的OSD导致Peering卡住。
为了解决这个问题,OSDMap新增加了参数每个OSD的up_thru,并规定PG在切换至新的Intervals之后,成功完成Peering并重新开始接受客户端读写请求之前,必须先通知Mointor设置其归属OSD的up_thru。因此,一旦检测到Intervals期间OSD的up_thru改变,那么maybe_went_rw可以设置为True。
这样通过引入与OSD状态相关的参数up_thru,设置某个Intervals的maybe_went_rw为True的条件为:
Acting Primary存在,Acting中的副本个数不小于存储池最小副本数,该Intervals内,Acting Primary所在OSD成功更新了up_thru。
2. GetInfo
当开始Peering时,需要收集参与本次Peering的全部副本的Info,根据它们的Info中日志相关信息,选出一个拥有最完整日志(即权威日志)的副本,就可以完成副本数据间的同步。
这些参与本次Peering的全部副本的集合称作PriorSet。
构建PriorSet的过程就是逆序遍历past_intervals的过程,其中Intervals不能发生在当前Primary的last_epoch_started之前、并且maybe_went_rw不能为False,last_epoch_started记录了上次处理完Peering的OSDMap的Epoch。
Primary将首先向所有PriorSet中的副本发送Query消息,用于收集Info
3.GetLog
收集完参与本次Peering的所有副本的Info后,Primary需要在其中某个OSD选取一份权威日志(权威日志可能位于Primary上也可以位于其他副本OSD上)。
获取了权威日志后,可以依据此权威日志进行副本间的在线数据恢复,但由于CRUSH选取的Up具有随机性,所以存在Up中某些OSD因为没有PG任何历史副本或者承载的副本内容过于落后,导致它们无法通过日志以增量的方式同步(Recovery),所以需要通过在OSDMap中设置PG Temp,并显式替换CRUSH计算结果(成为Acting)
Acting中的副本必然可以通过Recovery恢复,而不在Acting中的Up副本只能通过Backfill恢复。
当PG Temp生效之后或者Acting本身就与Up一致,Primary接下来将进行日志同步(Recovery)
Primary需要拉取权威日志再与本地日志合并并解决两日志之间的分歧。
Recovery恢复对象副本间的数据需要构建每个副本的对象信息列表missing,missing是后续执行Recovery的依据。missing的构建具体如下:
与权威日志合并过程中,如果Primary发现本地有对象需要修复,则将其加入自身的missing列表。完成合并之后,开始向所有仍然能够通过Recovery恢复的副本(即Acting中的副本)发送Query消息,以获取他们的日志,收到每个副本的日志后,通过与本地日志对比(此时Primary已经完成了本地日志与权威日志的合并),Primary可以构建这些副本的missing列表,作为后续执行Recovery的依据。
4.GetMissing
每个副本的missing列表记录了所有需要通过Recovery进行修复的对象信息。missing的每个条目只需要记录如下两个重要参数:
need。指对象需要被同步至此版本号,即对象的权威版本号。
have。指对象在归属副本(或者Primary)的本地版本号
当Primary收到每个副本的本地日志后,可以通过日志合并的方式得到每个副本missing列表,也可能需要解决分歧日志。
为了解决分歧日志,我们首先将所有分歧日志按对象进行分类,即所有针对同一个对象操作的分歧日志都使用一个队列进行管理,然后逐个队列(对象)进行处理。
生成完整的missing列表之后,Primary将向状态机投递一个Activate事件,进入Started/Primary/Active/Activating状态,准备激活PG。
5.Activate
随着PG接近尾声,在PG变为Active可接受客户端读写请求之前,必须先固化本次Peering的成果,防止因为系统掉电等意外因素导致前功尽弃。同时还必须收集后续用于执行在线数据恢复所依赖的关键信息。上述过程称为激活PG
通过向状态机投递一个Activate事件,副本可以切换至Started/ReplicaActive状态,开始执行Activate操作,固化更新后的Info(包含last_epoch_started)、日志(包含missing列表)等关键元数据(比如MissingLoc)至本地磁盘。
随着PG进入Active状态,Peering正式宣告完成,此后PG可以正常处理来自客户端的请求,Recovery或者Backfill可以切换后台进行。
分布式调参思考
1.分层调参
ceph读写I/O会经历多个部分,这些部分是有顺序的,
比如写一个对象,先crush计算副本,然后monitor同步OSDMap、然后Peering,最后根据Peering结果执行BlueStore的write或者Recovery或者Backfill。
这其中有全局的比如Monitor,运行于各个时间。
也有顺序的,比如先crush计算副本、同步OSDMap、Peering、write。
归纳出每一层关联的参数,(进行参数重要性选择),单独的小模型训练调参。
上一层模型训练好的参数结果用于下一层模型训练
这样大模型化成若干个小模型分层训练,采样同样数量的样本,训练时间下降一个数量级。
在工作负载的基础上扩展训练集输入
工作负载不仅仅I/O的混合程度,还有流量大小。
如果仅仅依靠工作负载作为输入条件,那么当ceph状态不再是active+clean时,参数将不是最优,无法适应PG状态机。
比如:当ceph状态为需要Recovery时,则会出现PG接受客户端读写与PG进行Recovery数据恢复两种情况的线程争用,调整Recovery相关约束的参数会使Recovery在争用中劣势,从而使得客户端I/O响应受影响减弱。当客户端工作负载流量下降甚至为0时,让Recovery恢复优势,可以更大程度利用资源从而增加全局I/O。