HCIE-2204-BGP
路由协议的类型
- 直连路由
- 非直连路由
- 静态路由
- 动态路由
- IGP-- 内部网关协议 :以最快的速度,计算一个无环、最短的路由条目
- 距离矢量协议:邻居之间传递的是链路状态信息
- RIP( V1/V2/ng )
- IGRP--> EIGRP
- 链路状态路由协议:邻居之间传递的是链路状态信息
- ISIS--最初是为了 CLNP 协议的路由而出现
- OSPF--为了传输 IP 协议路由而出现
- 距离矢量协议:邻居之间传递的是链路状态信息
- EGP--外部网关协议:以最稳定的方式,传输大量路由,计算一个无环的路由条目, 并且能够实现路由的灵活控制
- BGP( border gateway protocol )
- IGP-- 内部网关协议 :以最快的速度,计算一个无环、最短的路由条目
BGP协议概述
BGPE协议虽然是用于在大型规模的网络环境下,在各个路由器之间,动态的传递路由条目信息的,但是 BGP 协议时属于 OSI 模型的“ 第 7 层 ” ---应用层
所以,BGP 协议报文在发送的时候,都是包含在传输层协议的后面的,并且有对应的端口号。使用的端口号: TCP 179,并且该端口号是属于 BGP 报文的 “ 目标端口号 ”,源端口号是随机的
BGP的工作原理
- 建立邻居表:包含的是与自己建立邻居关系的 BGP 路由
- 同步数据库:包含的是自己宣告的路由条目以及邻居传递过来的路由条目
- 计算路由表:包含的是从数据库中“ 精挑细选 ”出来的最好的路由条目
BGP的报文类型
- open :该报文用于邻居表的建立
- update:更新,该报文用于路由条目的发送
- notification:通知,该报文用于 BGP 的报错信息的提示
- keep-alive :存活报文,该报文用于 BGP 邻居关系的维护和拆除
- route-refresh:路由刷新报文,该报文用于路由策略的快速更新
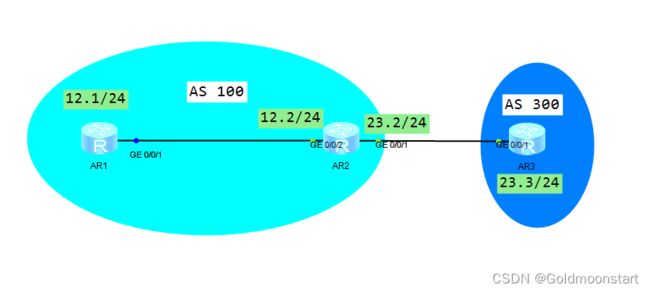
BGP 的邻居表( 基本配置 )
拓扑:

因为 BGP 工作的时候,使用的底层传输协议是 TCP 。所以 BGP 的整个工作‘过程非常稳定。
并且,BGP 的所有的报文的转发方式,都是“ 单播 ”!
在路由协议中,想要实现单播传输数据,命令都是统一的: peer x.x.x.x ( 邻居的 IP 地址 ),所以,在 BGP 邻居中,如果两个设备出现了问题:要么是我的问题,要么是你的问题,比如邻居设备之间传递路由出现了问题,要么是自己没发路由,要么是对方没收路由;
基本配置( R1 和 R2 在同一个 AS ,建立内部 BGP 邻居 )
R1
undo terminal moniter
system-view
sysname R1
interface gi0/0/1
ip address 192.168.12.1 24
quit
bgp 100
router-id 1.1.1.1
peer 192.168.12.2 as-number 100
quit
R2
undo terminal moniter
system-view
sysname R2
interface gi0/0/2
ip address 192.168.12.2 24
quit
bgp 100
router-id 2.2.2.2
peer 192.168.12.1 as-number 100
quit
BGP 100---> 其中的 100 表示的是 AS 号,在 BGP 协议中,任何一个路由器运行 BGP ,都必须 须拥有 1分 AS 号。 AS 号也叫自治系统,此时表示的是一个企业/ 公司
在表示的时候, AS 有两种格式
老格式:2个字节;( AS 的取值是 1--65535 )
新格式: 4个字节; ( AS 的取值是 1- - 4294967295 )
因为 AS 的好买取值空间,很有限,所以为了防止 AS 号被用完,所以 AS 也借鉴了 IP 的方法,将 AS 号分为:
公有 AS : 1-64511, 收费的,随便使用
私有 AS : 64512-65535,免费的,随便使用
在一个路由器上,运行 BGP 的时候,同一个时刻只能运行一个 AS
基于邻居设备之间所使用的 AS 号是否相同,我们将 BGP 邻居分为:
IBGP 邻居 :内部 BGP 邻居,即两个设备的 BGP AS 号相同
EBGP 邻居: 外部 BGP 邻居,即两个设备的 BGP AS号不相同
Router-id -----》 在 BGP 中的 router-id 的作用,和 OSPF 中的完全相同;确定的方式也是分为:
手动指定:通过router-id 命令确定,优先级高于 “ 自动选举 ”
自动选举: 首先 IP 地址的回环接口的 IP 地址,其次选择 IP 地址打的物理 接口的IP 地址
peer 192.168.12.1 as-number 100 ,该命令包含了 3 含义
自己本地设备想 192.168.12.1 发起一个 TCP 连接
期望对方向自己发送BGP 报文的时候,源 IP 地址是 192.168.12.1
期望对方向自己发送 BGP 报文的时候,包含的 AS 号是 100
为了稳定,我们在建立 IBGP 邻居关系的时候,通常都是使用非常稳定的回环接口链接里邻居
R1
bgp 100
peer 10.10.2.2 as-number 100
# R1 向 10.10.2.2 发起一个 BGP 连接。R1 的源 IP ( 随机端口 )---》 10.10.2.2 179. tcp
# R1 期望对方使用 10.10.2.2 给自己发送报文
# R1 期望对方使用的 AS 号是 100
R2
bgp 100
peer 10.10.1.1 as-number 100
# R2 向 10.10.2.2 发起一个 BGP 连接。R1 的源 IP ( 随机端口 )---》 10.10.1.1 179. tcp
# R2 期望对方使用 10.10.1.1 给自己发送报文
# R2 期望对方使用的 AS 号是 100
同时我们在 R2 上,为了满足" R1 堆返回得 BGP 报文得源 IP 地址 " 得要求。我们在 R2 上,修改 R2 得BGP报文得源 IP 地址:
BGP 100
peer 10.10.1.1 connect-interface loopback 0
# 向 10.10.1.1 发送 BGP 报文得时候,源 IP 地址 是 loopback 0 的地址 即 10.10.2.2
所欲,此时的 R2 向 R1 发起的 BGP 连接,应该是 :
10.10.2.2 ( 随机端口 )——————————》 10.10.1.1 , 179 ,TCP
该链接发送到 R1 后,满足了 R1 的“ 更新源监测机制 ”,所以,R2 和 R1 之间的 BGP 邻居关系建立了
通常情况下,我们在配置 BGP 邻居关系的时候,都会修改自己的源 IP 地址,满足对方设备的“ 更新源检测机制 ”。所以R1 的配置应该是:
bgp 100
peer 10.10.2.2 connect-interface loopback 0
但是,如果这样配置的话,理论上来说:
R1 向 R2 建立的 BGP 连接,成功了: 10.10.1.1( 随机端口 ) ---》10.10.2.2:179,TCP
R2 向 R1 建立的 BGP 连接,成功了: 10.10.2.2( 随机端口 ) ---》10.10.1.1:179,TCP
最终 R1 和 R2 之间,因为仅仅存在一个 BGP 邻居关系,所以 最终只能使用其中一个 BGP 连接,就可以了:
选择哪个 “ TCP 连接建立延迟 ” 小的
如何判断一个 TCP 连接是由谁发起的? 看哪个 地址使用的是“ 随机端口 ”
最终,R1 和 R2 之间通过稳定的 回环口建立 IBGP 邻居关系的配置是:
R1
bgp 100
peer 10.10.2.2 as-number 100
peer 10.10.2.2 connect-interface loopback 0
quit
R2
bgp 100
peer 10.10.1.1 as-number 100
peer 10.10.1.1 connect-interface loopback 0
quit
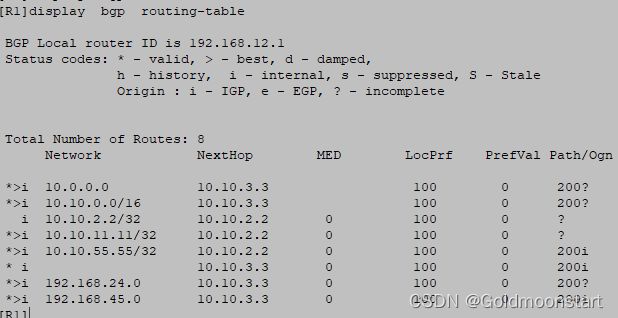
[R1]display bgp peer # 查看 BGP 邻居表
BGP local router ID : 1.1.1.1 》表示的是自己的 router-id
Local AS number : 100 》 表示的是自己的 AS 号
Total number of peers : 1 Peers in established state : 0
Peer V AS MsgRcvd MsgSent OutQ Up/Down State PrefRcv
10.10.2.2 4 100 0 0 0 00:00:46 Established 0
[R1]
# Total number of peers : 表示的是本地一个存在几个邻居
# Peers in established state :表示的是本地一共有多少个“ 建立 ” 状态的邻居
# peer :表示的是;injection舍不得 “ 接口 IP 地址 ”
# V :表示的是邻居设备所运行的 BGP 版本,默认是 4
# AS: 表示的是邻居设备所在的 AS
# MsgRcvd : 表示的是从邻居设备收到的报文数量
# MsgSent : 表示从邻居设备发送的报文数量
# OutQ:表示的是针对该邻居的“ 出现列队 ” 中包含的报文数量,这些报文都是需要重传的,所 以,该字段最好的情况就是 0 。
# Up/Down: 表示邻居设备的状态,最好的状态就是 : Established ,建立的意思。
# PrefRcv: 表示的是从邻居“ 接收 ” 到 “ 前缀 ” 的数量,即从邻居学习到的路由条目的数量
BGP 邻居建立影响因素:
- 3 层 IP 地址必须互通
- 4层的 TCP 报文中 179 端口连接必须建立
- Open 报文中包含的 AS 号必须和对方期望的相同
- open 报文中包含的 router-id 不能与自己相同
- BGP 的认证必须成功
- 邻居之间的 “ 更新源检测机制 ” 必须检查通过
- 邻居之间的 “ 直连检测机制 ” 必须检查通过
所谓的直连检测机制,指的是:
与对方建立邻居关系的时候,去往对方的 IP 地址时,必须使用自己本地的直连路由
直连检测机制,仅仅存在于 EBGP 邻居之间,为的就是 : 确保 EBGP 邻居使用的直连接口 建立邻居的
EBGP 邻居之间,虽然是存在这个“ 直连检测机制 ”的,但是,如果想要执行“ 检查 ” 这个机制
其实,是需要另外一个前提条件的: EBGP 之间发送的 BGP 报文的 TTL 值,必须是 1.
所以我们想要在 EBGP 邻居之间,建立一个“ 非直连接口 ” 的 EBGP 邻居关系,只要:修改 EBGP 邻居之间的报文的 TTL 不是 1 就可以了
此时,就不会“ 检查 ” 直连检测机制了
例如在 : 在 R2 和 R3 之间,通过回环口建立 邻居关系;
R2
interface gi0/0/1
ip address 192.168.23.2 24
quit
interface loopbacke 0
ip address 10.10.2.2 32
quit
ip route-static 10.10.3.3 32 192.168.23.3
R3
undo terminal moniter
system-view
sysname R3
interface gi0/0/1
ip address 192.168.23.3 24
quit
interface loopback 0
ip address 10.10.3.3 32
quit
bgp 300
router-id 3.3.3.3
peer 10.10.2.2 as-number 100
peer 10.10.2.2 connect-interface loopback 0
quit
ip route-static 10.10.2.2 32 192.168.23.2
quit
此时 R2 和 R3 之间,专门用于建立 EBGP 邻居关系的 loopback 0 就互通了,接下来,在 R2 和 R3 直接,建立 EBGP 邻居关系
R2
bgp 100
peer 10.10.3.3 as-number 300
peer 10.10.3.3 connect-interface loopback 0
peer 10.10.3.3 ebgp-max-hop # 如果不指定最大的跳数,则指的是将TTL值修改为了255
quit
R3
bgp 300
peer 10.10.2.2 as-number 100
peer 10.10.2.2 connect-interface loopback 0
peer 10.10.2.2 ebgp-max-hop # 如果不指定最大的跳数,则指的是将TTL值修改为了255
quit

BGP的数据库( 主讲路由属性)
拓扑
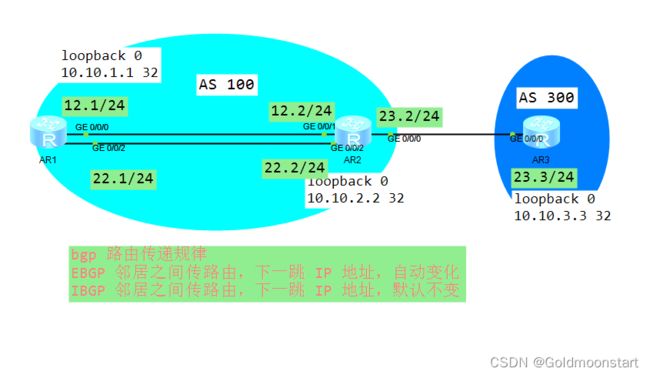
需求
- 在 R 1上创建 loopback 11 ,并通过 network 的方式宣告进 BGP
- 在 R3 上创建 loopback 33,并通过 import-route 的放肆宣告进入 BGP
- 确保 R1 和 R3 的上述两个接口,互通
配置
R1
undo terminal moniter
system-view
sysname R1
interface gi0/0/0
ip address 192.168.12.1 24
quit
interface gi0/0/2
ip address 192.168.22.1 24
interface loopback 11
ip address 10.10.11.11 32
quit
interface loopback 0
ip address 10.10.1.1 32
quit
ospf 1 router-id 1.1.1.1
area 0
network 192.168.12.0 0.0.0.255
network 192.168.22.0 0.0.0.255
quit
bgp 100
router-id 1.1.1.1
peer 192.168.12.2 as-number 100
quit
R2
undo terminal moniter
system-view
sysname R2
interface gi0/0/1
ip address 192.168.12.2 24
quit
interface gi0/0/0
ip address 192.168.23.2 24
quit
interface gi0/0/2
ip address 192.168.22.2 24
quit
interface loopback 0
ip address 10.10.2.2 32
quit
ospf 1 router-id 2.2.2.2
area 0
network 192.168.12.0 0.0.0.255
network 192.168.22.0 0.0.0.255
quit
ip route-static 10.10.3.3 32 192.168.23.3
bgp 100
router-id 2.2.2.2
peer 192.168.12.1 as-number 100
peer 10.10.3.3 as-number 300
peer 10.10.3.3 connect-interface loopback 0
peer 10.10.3.3 ebgp-max-hop
R3
undo terminal moniter
system-view
sysname R3
interface gi0/0/0
ip address 192.168.23.3 24
quit
interface loopback 33
ip address 10.10.33.33 32
quit
interface loopback 0
ip address 10.10.3.3 32
quit
ip route-static 10.10.2.2 32 192.168.23.2
bgp 300
router-id 3.3.3.3
peer 10.10.2.2 as-number 100
peer 10.10.2.2 connect-interface loopback 0
peer 10.10.2.2 ebgp-max-hop
quit
R1
bgp 100
network 10.10.11.11 32 此时,network 后面写的必须是路由表中存在的精确路由
quit
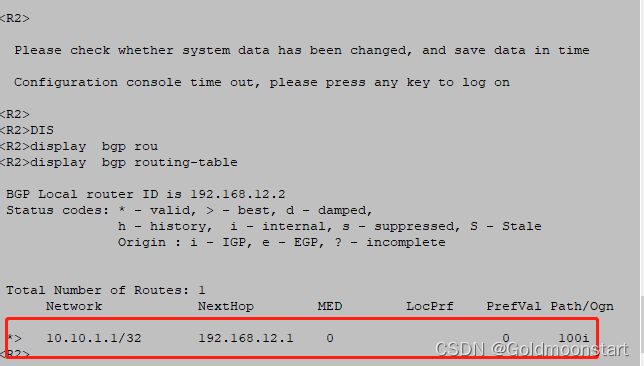
查看 R 1 的路由表

此时,该路由条目千亩有一个符号 > ,表示该路由是 “ 最好的 ”
如果 BGP 路由器认为一个路由是最好的,那么接下来就要做两件事:
自己用:尝试着将该路由放入到自己的路由表中;
给邻居用 :尝试着发送给自己的 BGP 邻居设备;
所以,该路由就发送给了 R2 ,随后就发送给了 R3
R3
bgp 300
import-route direct 此时,使用过 import-route 方式宣告路由
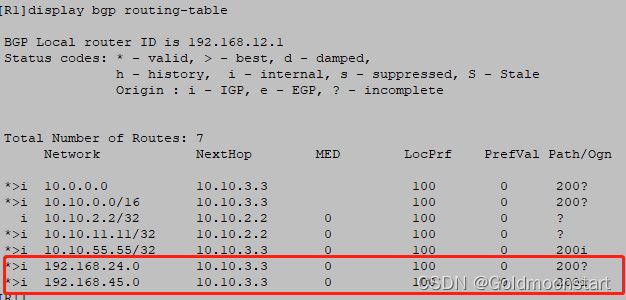
该路由会进入到自己的数据库,并且是“ 最优的 ”,然后发送给了自己的外部邻居 R2 ,在 R2 的BGP 数据库也是最优的;所以 ,R2 就发送给了 R1 ,但是在 R1 的数据库中,该路由不是“ 最优的 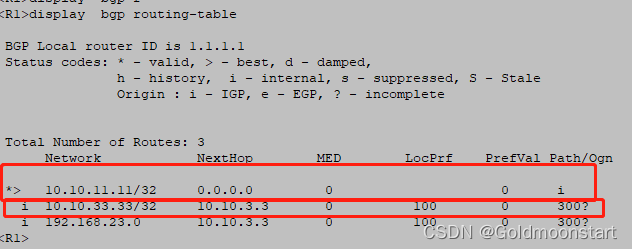
原因是 :R1 根本不知道这两个路由的下一跳 IP 地址---10.10.3.3,怎么通
所以,R1 不能使用这两个路由条目,我们需要想办法:让 R1 可以去网站合规下一跳 IP 地址;或者 修改 R1 的这两个路由的下一跳 IP 地址。接下来,我们选择第二种方法:在 R2 上,针对自己的内部邻居。修改外部邻居学习过来的路由的下一跳 IP 地址。
R2 :
bgp 100
peer 10.10.1.1 next-hop-loacl
# 即向 10.10.1.1 发送路由的时候,将下一跳 IP 地址都设置为 local ,所谓的 local地址,指的就是该设备 与 R1 建立邻居时候所使用的 IP 地址,也就是 peer 10.10.1.1 connect-interface loopback 0 中的loopback 地址
此时,在 R1 上看到的 BGP 数据库是这样的:

此时,R1 可以从10.10.2.2 中获得去往10.10.33.33 的路由

R1 的 loopback 11 与 R3 的 loopback 33互通
BGP路由选路( 选路原则 )
在上面的实验总结中,我们实现了“ 通过 BGP ” 在不同的 AS 之间实现了路由的传递,但是就算是 BGP 成功实现路由传递,但是数据包,不一定互通,因为,有可能中间传输运营商 ( AS 200 ) 的内部路由器有可能是没有 BGP 路由的,导致业务数据无法互通,如下图所示
拓扑

配置如下
R1
undo terminal monitor
system-view
sysname R1
interface g0/0/0
ip address 192.168.12.1 24
quit
interface loopback 0
ip address 10.10.1.1 32
quit
bgp 100
router-id 1.1.1.1
peer 192.168.12.2 as-number 200
network 10.10.1.1 32
quit
display bgp peer
R2
undo terminal monitor
system-view
sysname R2
interface g0/0/1
ip address 192.168.12.2 24
quit
interface g0/0/0
ip address 192.168.23.2 24
quit
interface loopback 0
ip address 10.10.2.2 32
quit
ospf 1 router-id 2.2.2.2
area 0
network 192.168.12.0 0.0.0.0
network 192.168.23.0 0.0.0.0
network 10.10.2.2 0.0.0.0
quit
quit
bgp 200
peer 192.168.12.1 as-number 100
peer 10.10.6.6 as-number 200
peer 1010.6.6 connect-interface loopback 0
quit
display ospf peer brief
R3
undo terminal moniter
system-view
sysname R3
interface g0/0/01
ip address 192.168.23.3 24
quit
interface g0/0/0
ip address 192.168.34.3 24
quit
interface loopback 0
ip address 10.10.3.3 32
quit
ospf 1 router-id 3.3.3.3
area 0
network 192.168.23.0 0.0.0.255
network 192.168.34.0 0.0.0.255
network 10.10.3.3 0.0.0.0
quit
quit
display ospf peer brief
R4
undo teriminal monitor
system-view
sysname R4
interface g0/0/01
ip address 192.168.34.4 24
quit
interface g0/0/0
ip address 192.168.45.4 24
quit
interface loopback 0
ip address 10.10.4.4 24
quit
ospf 1 router-id 4.4.4.4
area 0
network 192.168.34.0 0.0.0.255
network 192.168.45.0 0.0.0.255
network 10.10.4.4 0.0.0.0
quit
quit
R5
undo terminal monitor
system-view
sysname R5
interface g0/0/01
ip address 192.168.45.5 24
quit
interface g0/0/0
ip address 192.168.56.5 24
quit
interface loopback 0
ip address 10.10.5.5 32
quit
ospf 1 router-id 5.5.5.5
area 0
network 192.168.45.0 0.0.0.255
network 192.168.56.0 0.0.0.255
network 10.10.5.5 0.0.0.0
quit
quit
display ospf peer brief
R6
undo terminal monital
system-view
sysname R6
interface g0/0/1
ip address 192.168.56.6 24
quit
interface g0/0/0
ip address 192.168.67.6 24
quit
interface loopback 0
ip address 10.10.6.6 32
quit
ospf 1 router-id 6.6.6.6
area 0
network 192.168.56.0 0.0.0.255
network 10.10.6.6 0.0.0.0
quit
quit
bgp 200
peer 192.168.67.7 as-number 300
peer 10.10.2.2 as-number 200
peer 10.10.2.2 connect-interface loopback 0
quit
display ospf peer brief
R7
undo terninal monitor
system-view
sysname R7
interface g0/0/1
ip address 192.168.67.7 24
quit
bgp 300
router-id 7.7.7.7
peer 192.168.67,6 as-number 200
quit
display bgp peer
在上述拓扑中:
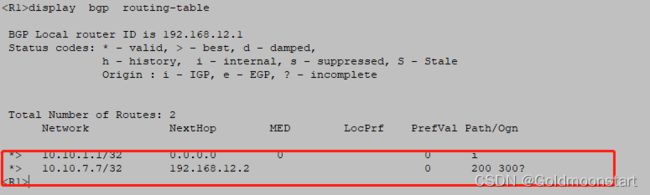
R1 和 R2 ,建立 EBGP 邻居关系,通过network 宣告了 10.10.1.1/32
R2 和 R6 ,建立了IBGP 邻居关系,并且互相修改了next-hop-local ,实现路由的正常传输
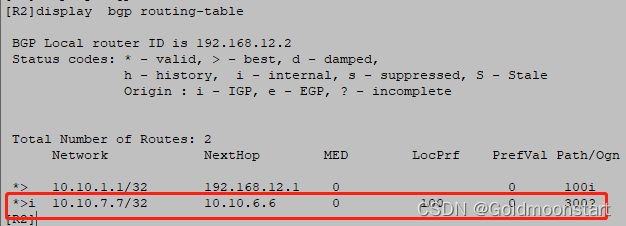
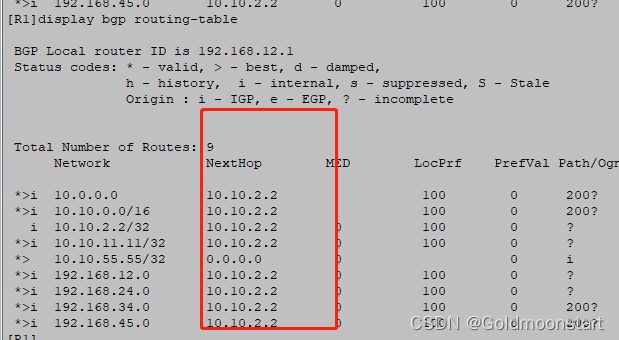
此时我们可以看到
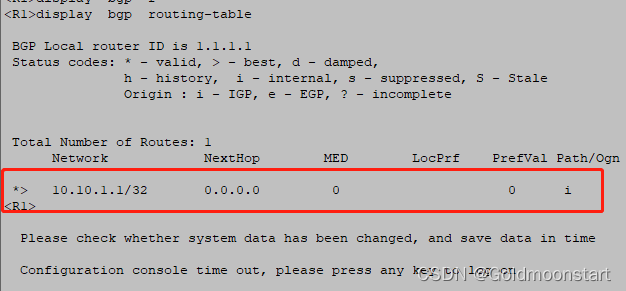
在R1 上是最优的,所以会传递给 R2,R2传给 R6,R6传给 R7
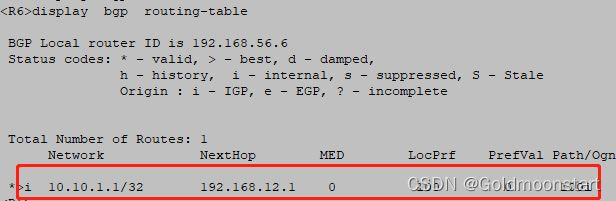

我们看下 R2到 10.10.6.6 的详细信息:
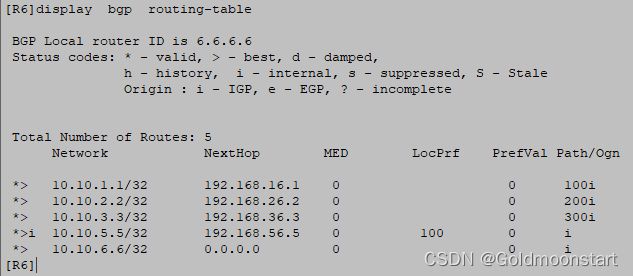
BGP Peer is 10.10.6.6, remote AS 200 # 邻居是 10.10.6.6 区域是 AS 200
Type: IBGP link # 链路类型是 IBGP
BGP version 4, Remote router ID 192.168.56.6 # 版本是 4 ,是 192.168.56.6 告诉我的
Update-group ID: 0
BGP current state: Established, Up for 00h59m09s # BGP 显示的状态是 Established。
开启时时间的长度为
BGP current event: RecvKeepalive # BGP 当前状态为收到 keepalive 报文
BGP last state: OpenConfirm # BGP 上一个报文为 OpenConfirm
BGP Peer Up count: 1 # 邻居 UP 了几次 越小越好
Received total routes: 1 # 接收了几个路由
Received active routes total: 0 # 收到了几个活动的路由
Advertised total routes: 1 # 向邻居发送了几个路由
Port: Local - 179 Remote - 50983 # 本地端口用的 179 R6 用的随机端口 所以是 6发起的
Configured: Connect-retry Time: 32 sec # 建立不成功的时候多久重新建立一次 32 S
Configured: Active Hold Time: 180 sec Keepalive Time:60 sec # 多久发送一次 keepalive 报文 60S一次,如果 180 S 后还没收到,就表示已断开连接
Received : Active Hold Time: 180 sec # R2向 R6 发送回复报文的时间规则
Negotiated: Active Hold Time: 180 sec Keepalive Time:60 sec # R2与 R6协商后,为 60S 发送一次 keepalive 报文,超过 180 S 后表示超时
Peer optional capabilities: # 当前邻居选项的能力
Peer supports bgp multi-protocol extension # 多协议能力
Peer supports bgp route refresh capability # 路由刷新能力
Peer supports bgp 4-byte-as capability # 4 个字节的 AS 号能力
Address family IPv4 Unicast: advertised and received # IPV4 组播能力已开启可以收发
Received: Total 62 messages # 收到了 62个
Update messages 1
Open messages 1
KeepAlive messages 60
Notification messages 0
Refresh messages 0
Sent: Total 62 messages # 发了 62 个
Update messages 1
Open messages 1
KeepAlive messages 60
Notification messages 0
Refresh messages 0
Authentication type configured: None # 当前的认证,没有做
Last keepalive received: 2022/06/21 09:56:38 UTC-08:00 # 最后一次收到报文的时间
Last keepalive sent : 2022/06/21 09:56:37 UTC-08:00 # 最后一次发报文的时间
Last update received: 2022/06/21 09:52:39 UTC-08:00 #最后一次收到报文的时间
Last update sent : 2022/06/21 08:57:37 UTC-08:00 # 最后一次发报文的时间
Minimum route advertisement interval is 15 seconds # 最小的路由通过 15 S 修改命令后
15 内生效
Optional capabilities:
Route refresh capability has been enabled # 路由刷新能力已开启
4-byte-as capability has been enabled # 4个 AS 字节能力已开启
Peer Preferred Value: 0 # Peer Preferred Value属性未更改
Routing policy configured: # 路由策略做了吗
No routing policy is configured # 路由没做 策略
R6 和 R7 ,建立 EBGP 邻居关系,通过 import-route direct 宣告了 10.10.7.7/32
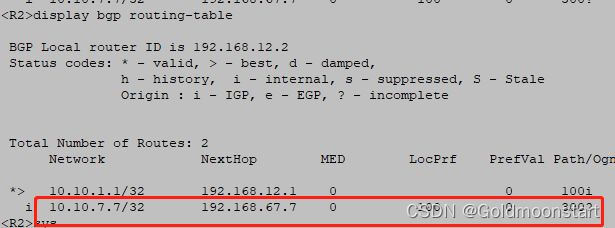
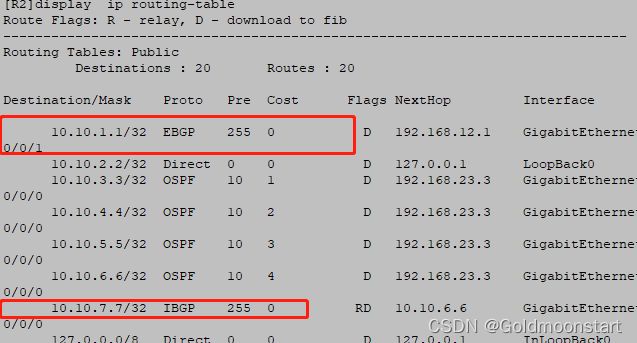
我们在 R2 上已经可以看到 10.10.7.7 的路由了,但是不是最优的,因为他的下一跳不是 10.10.6.6,这个时候我们就要在 R6 上告诉 去往10.10.2.2 的走 next-hop-local
![]()
15s后我们再看

我们再来看下 R1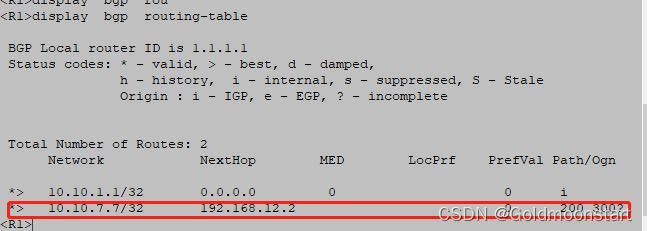
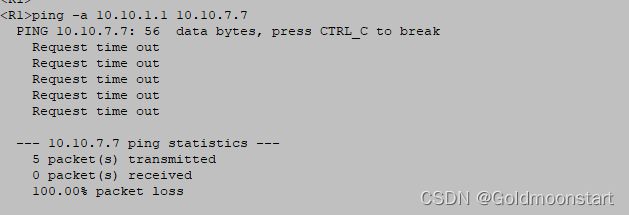
最终,R1 和 R7 都学习到了彼此的路由。但是 R1 ping -a 10.10.1.1 10.10.7.7 依然无法互通。因为中间运营商 AS 200 的内部 路由 R3/R4/R5 没有 AS 100/700 的路由
所以,为了实现 R1 和 R7 的互通,我们必须想办法让: AS 200 的内部路由器得有 AS 100/700 D的路由:
此时我们将 BGP 路由导入到 OSPF 中看看
[R2]ospf 1
[R2-ospf-1]import-route bgp

我们可以看到 只有 10.10.1.1 产生了 5 类的 LSA,没有 10.10.7.7 产生的 LSA
- 在 AS 200 的内部路由器上,通过静态路由的方式,确保拥有 AS 100/700 的路由
- 在 AS 200 的内部路由器上,通过动态路由的方式 -IGP ( ospf /isis ) 确保路由,此时,需要在 R2 和 R6 上,将 BGP 路由宣告进入到 IGP ( OSPF / ISIS ) 中,但是,IGP 协议无法一次性的处理 BGP 的海量路由,所以不建议这么做
- 并且需要注意:
- 默认情况下,BGP 导入进 IGP 的时候,只有 EBGP 路由才可以导入成功,并且,强烈建议:不要将 IBGP 路由宣告进入到 IGP 协议中,有可能会造成环路
- 并且需要注意:
- 在 AS 200 的内部路由器上,通过动态路由的方式 BGP ,确保由 AS 100/700 的路由,如果我们在 AS 200 的所有路由器上,都配置 BGP ,都建立 IBGP 邻居关系,最终发现:IBGP 邻居之间不能正常的传递路由条目。因为,这是
- BGP 为了防止在一个 AS 内部出现环路,而引入的一个“ 防环机制 ”
- 即: OBGP 水平分割--从 IBGP 邻居学习到的路由,不会给另外一个 IBGP 邻居。为了解决“ 因为 IBGP 水平分割 ” 导致的“ IBGP 邻居之间无法正常传递路由 ” 的 问题
我们提出解决方案:
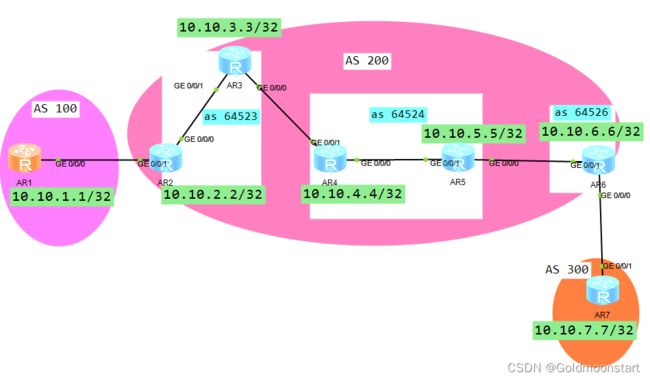
- IBGP 全互联:虽然配置简单,但是配置量很大,非常小号设备系统资源,建立的 TCP 连接太多,随着网络规模的扩展,该方案不具备磕扩展性
- BGP 联盟: 该方案的本质是将 AS 内的所有路由器,划分为很多个 小的 AS ( 私有 AS ), 并且每个 小的 AS 内的 BGP 邻居关系的数量不能超过 2 个;否则在每个小 AS 内依然存在 IBGP 水平分割原则。所以,仅仅使用这个方案来解决 IBGP 水平分割问题,也不具备很好的扩展性。
- 联盟拓扑
配置如下:
R2
undo bgp 200
bgp 64523
router-id 2.2.2.2
confederation id 200
confederation peer-as 64524 64526
peer 192.168.12.1 as-number 100
peer 10.10.3.3 as-number 64523
peer 10.10.3.3 connect-interface loopback 0
peer 10.10.3.3 next-hop-loacl
quit
R3
undo bgp 200
bgp 64523
router-id 3.3.3.3
confederation id 200
confederation peer-as 64524 64526
peer 10.10.2.2 as-number 64523
peer 1010.2.2 connect-interface loopback 0
peer 10.10.2.2 next-hop-loacl
peer 10.10.4.4 as-number 64524
peer 10.10.4.4 connect-interface loopback 0
peer 10.10.4.4 next-hop-loacl
peer 10.10.4.4 ebgp-max-hop
quit
R4
undo bgp 200
bgp 64524
router-id 4.4.4.4
confederation id 200
confederation peer-as 64523 64526
peer 10.10.3.3 as-number 64523
peer 10.10.3.3 connect-interface loopback 0
peer 10.10.3.3 next-hop-loacl
peer 10.10.3.3 ebgp-max-hop
peer 10.10.5.5 as-number 64524
peer 10.10.5.5 connect-interface loopback 0
peer 10.10.5.5 next-hop-loacl
quit
R5
undo bgp 200
bgp 64524
router-id 5.5.5.5
confederation id 200
confederation peer-as 64523 64526
peer 10.10.4.4 as-number 64524
peer 10.10.4.4 connect-interface loopback 0
peer 10.10.4.4 next-hop-loacl
peer 10.10.6.6 ebgp-max-hop
peer 10.10.6.6 as-number 64524
peer 10.10.6.6 connect-interface loopback 0
peer 10.10.6.6 next-hop-loacl
quit
R6
undo bgp 200
bgp 64526
router-id 6.6.6.6
confederation id 200
confederation peer-as 64523 64524
peer 10.10.5.5 as-number 64524
peer 10.10.5.5 connect-interface loopback 0
peer 10.10.5.5 next-hop-loacl
peer 10.10.5.5 ebgp-max-hop
peer 192.168.67.7 as-number 300
quit此时我们看R1/R7是可以互相学习到路由的
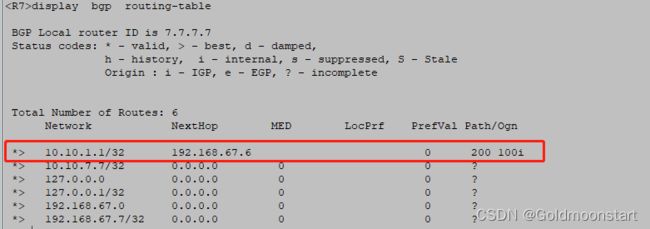
在R1用 10.10.1.1 看下是否与 10.10.7.7 互通

但是还是不具备很强的扩展性,所以我们就有了反射器
- BGP 反射器:在该方案中,那个设备上存在 IBGP 水平分割原则,就将哪个路由器配置为反射器,配置方法非常简单:只要为路由器指定一个每部邻居设备为自己的反射器哭护短,那么该设备就自动变成了 BGP 路由反射器。放该设备称为反射器后,在将 IBGP 邻居传递过来的时候,可以顺利的转发给自己的客户端,从客户端传递个反射器的路由,也可以顺利的转发给非客户端以及其他的客户端。所以路由器的转发路由的原则就是:除了费哭护短和非客户端之间,不能转发路由。其他的情况,反射器都可以转发路由
BGP选路原则
所有的路由协议,都是为了在设备之间传递“ 最好 ”的路由。但是 IGP 协议 和 BGP 协议选择“ 最好路由 ” 的规则,是不一样的
- 在 IGP 协议中,选择最好的路由的原则是:( 比较路由属性----优先级 + 开销值)
- 首先,比较路由优先级,数值越小越好
- 其次,比较路由开销值,数值越小越好
- 如果都相同。则路由都放入路由表中,形成“ 负载均衡 ”
- 在 BGP 协议中,选择最好的路由的原则是:( 比较路由属性---贼多,多达 13 条 )
- 比较路由的优选值 ( preferred-value ),数值越大越好;华为私有属性,默认是 0
- 比较本地优先级 ( local preference ),数值越大越好;默认是 100
- 比较“ 路由是否本地起源 ” ,即该路由是否本地产生
- 本地产生的路由,优先级高于 “ 从邻居学习过来的 ”
- 都是本地产生的时候,根据不同的产生方式,优先级依次降低
- 手动汇总 > 自动汇总 > network > import-route
- 比较 AS-path 属性,长度越短越好
- 比较起源属性,不同的起源类型,优先级依次降低:i > e > ?( incomplete )
- 比较 MEN 属性,数值越小越好
- 比较 BGP 的路由类型, EBGP 优先级,高于 IBGP
- 比较 去往 NGP 路由的下一跳 IP 地址时,所需要的 cost ,路径越小越好
- 判断 BGP 协议是否开启“ 路由的负载均衡 ” 功能---思科里面的 1 条
- 比较 cluster-list 的长度,越短越好;
- 比较 router-id ,越小越好;如果存在 RR 环境,则不比较 router-id 。比较 Originator-id ,也是越小越好
- 比较邻居的 IP 地址,越小越好
在 BGP 邻居传递路由的时候,存在很多的路由控制需求,为了实现理货的路由属性控制我们需要:
- 通过工具,抓取感兴趣的路由条目
- ACL:在抓取路由条目的时候,不精准,英雌只能赚取路由条目的“ 前缀 ”,不能爪掩码
- 在 ACL 中,最后一个条目,是:拒绝所有
- 在 ACL 中, 允许所有的配置命令是:
- acl 2000
- rule { number } permit source any
- 换种写法就是:
- rule { number } permit source 0.0.0.0 255.255.255.255
- acl 2000
- 前缀列表( prefix-list ):不但可以匹配路由的前缀,还可以匹配路由的掩码;比 ACL精准
- 在前置列表中,最后一个条目是:拒绝所有
- 在前缀列表中,语序所有的配置命令是:
- ip prefix-list { name } permit 0.0.0.0 greater-equal 0 less-equal 32
- 但是,上述的 2 个工具,只能“ 抓 ” 路由,但是不能改路由。
- ACL:在抓取路由条目的时候,不精准,英雌只能赚取路由条目的“ 前缀 ”,不能爪掩码
- 通过工具,修改路由条目的属性,从而影响路由的选路,实现控制目的。
- route-policy:路由策略。改工具可以借助于 ACL/前缀列表,针对特定的路由,修改所有的路由属性
- route-policy 作为一个“ 策略 ” 是可以包含很多很多条目的,不同的策略是通过“ 序号 ” 区分开的。这个序号的专用名词叫做 : node
- 当一个 route-policy 中,存在很多规则的时候,检测一个路由的顺序,是按照 route-policy 中的 node 取值从小到大开始逐个条目检查的
- 一旦,有一个 route-policy 被匹配,则后面的条目,就不检查,不关心了
- 如果所有的 route-policy 条目都没有被匹配,则执行“ 拒绝所有 ”的默认行为
- 在 route-policy 中,如果想要表示 “ 允许所有 ” 配置如下:
- route-policy { name } permit node { 序号 }
- 不写 if-match ,指的是 match 所有
- route-policy { name } permit node { 序号 }
- 在每一个 route-policy 条目中。都可以包含两个语句
- if-match ,后面跟的是“ 匹配条件 ” ,比如 ACL ,比如前缀列表,如果没有这个 if-match 语句,则表示 " 匹配所有 "
- apply ,是修改的意思,后面跟的是 “ 路由属性 ”。即将要修改该参数后面的路由属性。如果没有该参数,则保持该路由所有的属性不变。
BGP选路规则详解
比较 “ preferred-value ”
- 属性介绍
- 该属性是华为设备上的私有属性,并且只有在设备本地起作用,所以以后在邻居之间配置策略,修改属性的话,只能配置“ 入向策略 ”
- 如果使用该属性来控制大量路由器的旋律,非常的麻烦。不具备可扩展性
- 案例 1 :在 R4 上,通修改preferred-value 属性,调整 R4 去往 10.10.10.10/32 的路径。
拓扑

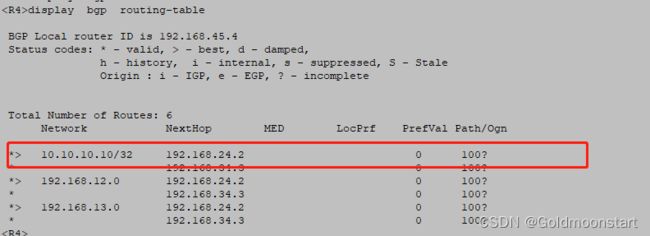 因为该属性是华为的私有属性,并且只在设备本地起作用,即该属性不会随着路由天在 BGP邻居之间互相传递,所以我们需要在 R4上 配置,针对 R3发送过来的路由,将 preferred-value ,属性调大,即可。
因为该属性是华为的私有属性,并且只在设备本地起作用,即该属性不会随着路由天在 BGP邻居之间互相传递,所以我们需要在 R4上 配置,针对 R3发送过来的路由,将 preferred-value ,属性调大,即可。
R4
bgp 64512
peer 192.168.34.3 preferred-value 3636 # 将邻居发送过来的所有的属性,都改为 3636
quit
但是如此以来,BGP 控制路由就不精准了,如果在 R1上同时宣告了 路由 : 10.10.11.11 /32
此时,还是仅仅希望 R4 去往 10.10.10.10/32 时,选择走 R3 ,去往10.10.11.11/32,选择走 R2,所以,我们只能在 R4上,针对 R3 配置入向策略,但是,首选需要通过 ACL 或者前缀列表,将 。10.10.10.10/32挑选出来,然后通过route-policy 工具 ,将该路由的属性调大。
同时,其他的路由,需要放个,不做任何属性的修改。
步骤1:配置 ACL ,抓取路由 10.10.10.10/32
acl 2000 # 取值范围是 2000-2999,匹配路由时,只能使用基本 ACL
rule 10 permit source 10.10.10.10 0.0.0.0
quit
步骤 2;配置 route-policy ,调用 ACL ,修改 属性 preferred-value 变大
route-policy R3-R4-IN permit node 10
if-match acl 2000
apply preferred-value 3636
quit
route-policy R3-R4-IN permit node 20
quit
步骤3:在 R4 上,针对 邻居 R3 的入方向,调用 route-policy
R4
bgp 64512
peer 192.168.34.3 route-policy R4-R3-IN import
此时,在 R4 的路由表中,仅仅是修改 了 R3 发送过来的 10.10.10.10/32 的 preferred-value 属性,其他属性都没改。所以,结果是

比较 “ local-reference ”
属性介绍
该属性,可以在一个 AS 内部随意传输,但是不可以在 AS之间传输,该属性在设备上的默认取值是 100,但是这个默认值是可以修改的。
那么,什么类型的路由,才会使用 BGP 的 默认的“ 本地优先级 ” 数值呢?
- 本地设备宣告的路由
- 从 EBGP 邻居学习到的 路由,因为本身不携带“ 本地优先级 ”属性,所以到了一个 BG呸设备上以后,就得使用该设备上配置 “ 默认本地优先级 ”
- 修改 BGP 路由器的“ 本地优先级 ”,命令是:
- R3
- bgp 100
- default local-preference 3030 # 将 BGP 本地优先级修改为 3030
- bgp 100
- R3
那么什么情况下,才会调整路由的“ 本地优先级”?
即我们想要控制一个数据包离开自己的 AS 的时候使用的数据转发路径,就可以通过调整该属性来实现。
案例配置: 要求 AS 100 内部所有设备访问 R4 ,默认都选择出口设备 R3
因为 R4 将路由发送给 R2/R3 的时候,他们之间是 EBGP 邻居。所以 R4 发送的这个 BGP 路由中,是不携带属性 -loca-perference ,所以默认情况下,R4 传递给 R2/R3 的路由,带了 R2/R3 本地默认的本地优先级,即100
如果我们在 R3 上,针对 R4 这个外部邻居,配置一个入向策略;
将R4 的路由 10.10.40.40/32 抓取
将该路由的本地优先级,掉政委大于 1000,比如 333
所以,我们在 R3 的本地数据库中看到的 R4 的路由就是 333.,同时,默认情况下IBGP 邻居之间传递路由的时候,属性本地优先级是不会变化的。所以,AS 100 的内部路由器,与 R2 /R3 建立 BGP 邻居关系的时候,学习到:
10.10.40.40/32 --R2 本地优先级是 100
10.10.40.40/32 --R3 本地优先级是 333
所以,都将 R3 作为 访问 R4 是,首选的 “ 主出口 ” 设备。
我们之所以不选择在 R2 或者 R3 上,针对每个 IBGP 邻居设备配置一个出向策略,就是因为,太麻烦,即该技术方案不具备可扩展性。所以,上述的方案正确的配置方法是:
R3:
acl 2040
rule 10 permit source 10.10.40.40 0.0.0.0
quit
route-policy R3-R4-IN permit node 10
if-match acl 2040
apply local-preference 333
quit
bgp 100
peer 192.168.34.4 route-policy R3-R4-IN import
quit
比较“ 是否本地起源 ”
属性介绍
该属性描述的是:当前的 BGP 路由条目,在 BGP 数据库中,是不是自己本地产生的:
- 自己本地产生的路由,优先级要高于从邻居学习过来的路由
- 自己本地产生的方式有多种:手动汇总 > 自动汇总 > network > import-route
- 自动汇总:对于华为设备而言,默认是关闭的;仅仅针对本地通过 import-route 方式引入的路由起作用。并且汇总结果:只能是明细路由所属于的“ 主类 ” 网络( 即 A、B、C),掩码都是默认的 /8/16/24
- 手动汇总:可以在任何路由器上配置,可以针对任何一种 BGP 的路由类型,只要存在于 BGP 的数据库中,就可以进行“ 手动汇总 ”。并且可以汇总成任何长度掩码的网络。
- 自动汇总和手动汇总,可以同时配置,两者互不影响。但是手动汇总的路由被优先选择!
案例配置
在 R4 上,进行测试:
interface loopback 4
ip address 10.10.44.44 32
quit
bgp 64512
impor-route direct # 将上诉的直连路由,导入进 BGP 数据库,会出现 10.10.44.44/32 的路由
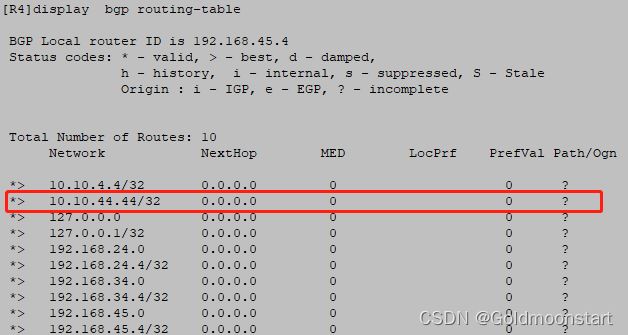
summary automatic # 开启自动汇总,所以数据库中就会出现 10.0.0.0/8 的路由
自动汇总显示字样


aggregate 10.10.0.0 255.255.0.0 # 配置手动汇总,所以数据库中会出现
10.10.0.0/16的路由
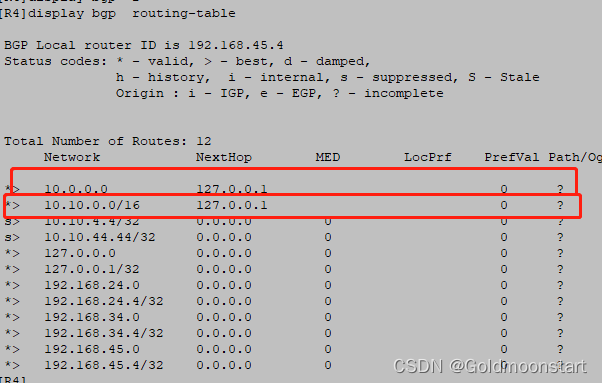
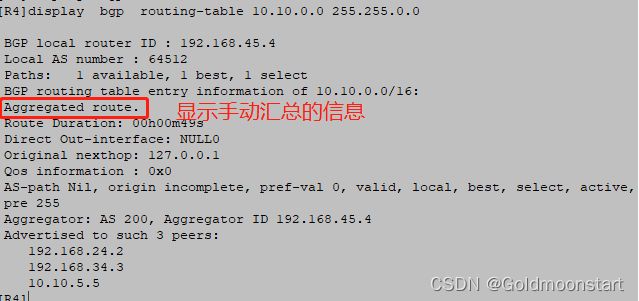
[R4]display bgp routing-table 10.10.0.0 255.255.0.0
BGP local router ID : 192.168.45.4 # BGP本地的router-id
Local AS number : 64512 #本地 AS 的号码
Paths: 1 available, 1 best, 1 select
BGP routing table entry information of 10.10.0.0/16:
Aggregated route. 手动汇总
Route Duration: 00h00m49s
Direct Out-interface: NULL0
Original nexthop: 127.0.0.1
Qos information : 0x0
AS-path Nil, origin incomplete, pref-val 0, valid, local, best, select, active,
pre 255
Aggregator: AS 200, Aggregator ID 192.168.45.4
Advertised to such 3 peers:
192.168.24.2
192.168.34.3
10.10.5.5
在 BGP 数据中的每个条目的详细信息中,如果显示 “ local ”,则表示该路由是本地产生的!
比较 as-path
属性介绍
该属性包含的 是 : BGP 路由在传递的过程中,前后依次“ 经过 /穿越 ” 的 AS 的有序组合,比较该属性的时候,比较的是该属性的长度,即:该属性中包含的 AS 号得数量。
as-path 的长度,越短越好,该属性的变化,仅仅发生在 ENGP 邻居之间,
as-path 的形成过程:
- 最先穿越的 AS ,放在 ak-path 的最右边,
- 随后每经过 1 个 AS ,都会将所经过的 AS 号,放在原有的 as-path 属性的最左边
- 所以,㡰 as-path 的属性,又有这样的说法
- 最左边的 AS,也叫做:BGP 条目的“ 起源 AS ” ,也叫做第一个 AS ( first AS )
- 最右边的 AS ,也叫作: BGP 路由条目的 “ 邻居 AS ”,也叫做最后一个 AS ( last AS)
- as-path 的 属性,中间的哪些 AS ,我们叫做:BGP 路由传递过程中,所经过的 AS
- 注意:
- 如果 as-path 是空的,说明 该 BGP 路由属于当前的 AS 的内部路由
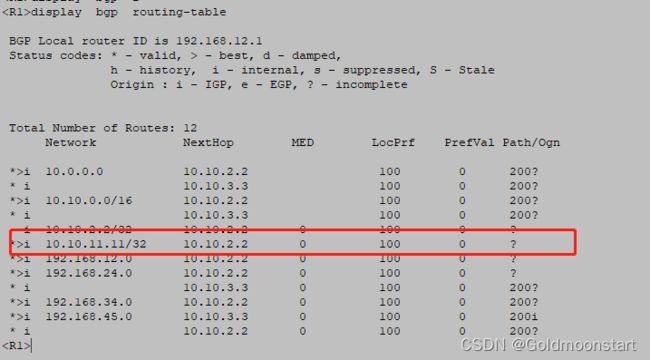
案例配置:希望通过比较 as-path 属性,让 R4 去往 10.10.11.11 /32 选择 R3作为下一跳
默认情况下,R4去往 10.10.11.11/32 的时候,无论是经过R2,还是 R3 ,这两个 路径的 as-path 都是 100,所以长度相同,都是:1
所以,为了满足要求,我们可以想尽办法,让:下一跳为 R2 的路由,as-path 长度增加
因此,我们可以选择在 R2 配置;针对邻居 R4 的出方向,抓取 10.10.11.11/32 ,增加 as-path
我们可以选在在 R4 配置;针对邻居 R2 的入方向,抓取 10.10.11.11/32 , 增加 as-path
方法一:在 R2 上,针对 R4 ,配置出向策略,增加 as-path 长度
interface loopback 11
ip address 10.10.11.11 32
quit
acl 2011
rule 10 permit source 10.10.11.11 0.0.0.0
quit
route-policy R2-R4-OUT permit node 10
if-match acl 2011
apply as-path 222 additive # 将原来的 as-path 的基础上,额外添加 as 222
quit
bgp 100
peer 192.168.24.4 routr-policy R2-R4-OUT export
quit
验证结果
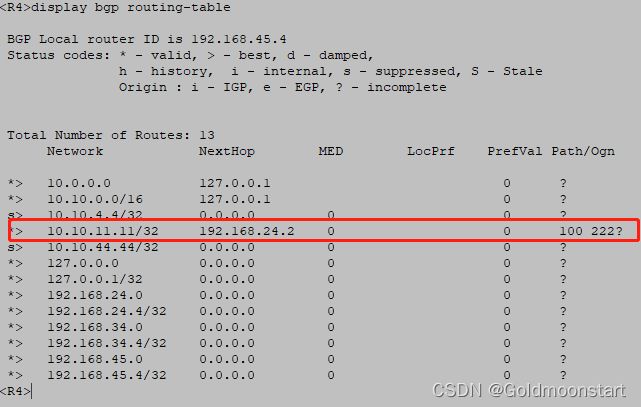
首先执行的 route-policy ,添加了 222
然后离开 R2 的时候,添加 了 R2 所属于的 AS 100
方法二:在 R4 上,针对 R2 ,配置入向策略,增加 as-path 长度
acl 2011
rule 10 permit source 10.10.11.11 0.0.0.0
quit
route-policy R4-R2-IN permit node 10
if-match acl 2011
apply as-path 444 additive
quit
bgp 64512
peer 192.168.24.2 route-policy R4-R2-IN import
quit
验证结果
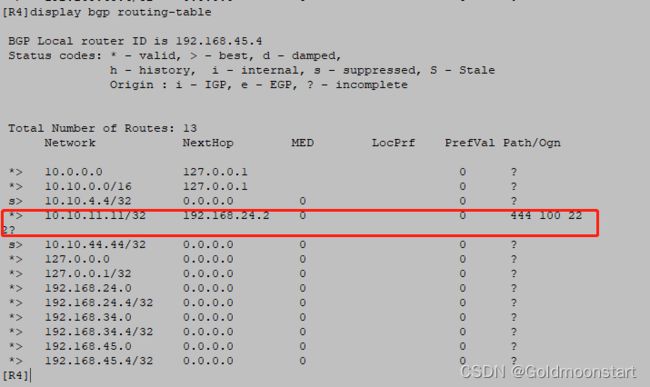
另外,需要注意的是:
as-path 的另外一个作用:在 EBGP邻居之间防止路由环路的发送,即: 从 EBGP 邻居学习过来的路由,要检查改路由的 as-path 属性,如果在其中发现了自己的 as-path ,则拒绝接收该路由。因为一旦接收了,就形成了 BGP 环路
如果想要在 BGP 邻居之间 ,添加 as-path 的属性,所添加的 AS 号,不能随便写。应该写
- 公有 AS 号 { 因为 as-path 属性包含的都是公有 AS 号 }
- 只能添加“ 自己的 AS 号 ”
- 比如,在 R2 上配置策略,添加的 AS 号,应该是 AS 100
- 比如,在 R4上配置策略,添加的 AS 号,应该是 AS 200
重要 :路由策略和数据库的关系

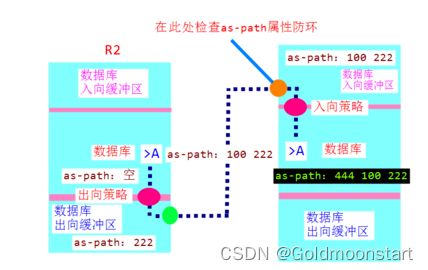
- 当路由表 A 宣告进入到数据库中后,在数据库中会变成 > A ,此时它是最优的路由。
- 当它从路由表向数据缓冲区出来的时候是A as-path( kong ),
- 然后经过出向策略的检测,如果在出向策略中加入的是 apply as-path 222 additiv 那么此时就会变成 A as-path(222)
- .当路由 A在出去数据库离开 R2 的时候,会添加上 R2 的 AS 号,也就是 AS 100, 这个时候,就会变成 A as-path 100 200,
- 然后到达另一个路由器的数据库,在经过数据库之前,会在数据库的边界上接受 as-path 防环路检测,如果该条路由中有自己本地的 AS 号,那么就拒绝这条路由,如果没有,就接收。
- 此时到达另一个路由器的数据库缓冲区的路由是 A as-path 100 200,
- 在经过数据库缓冲区进入到数据库的时候,会有一个入向策略的检测,如果在此时加入apply as-path 444 additive
- 到达 数据库的路由就是 A as-path 444 100 222
比较起源属性
属性介绍
该属性的作用是告知我们 :该路由当年在 BGP 路由器上以怎样的方式宣告进入到 BGP 协议的,起源属性的代码有三种,优先级依次降低:i > e > ?
- i ,通常对应的宣告方式是 network
- ?,通常对应的宣告方式是 import-route
该属性,可以随着 BGP 路由传递到任何地方: IBGP 和 EBGP 之间都可以传递该路由。
所以,针对该属性的策略,我们可以:
- 在宣告路由的时候,配置该策略
- 在发送路由的时候,配置该策略
- 在接收路由的时候,配置该策略
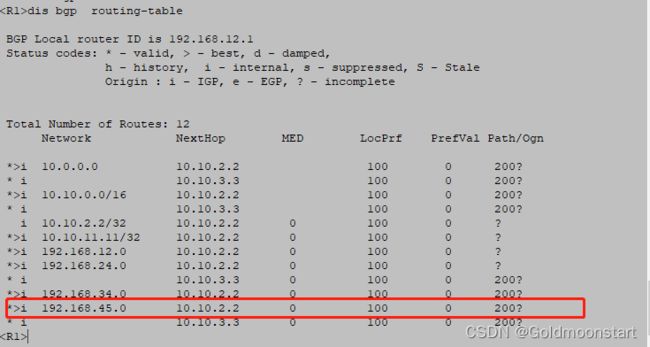
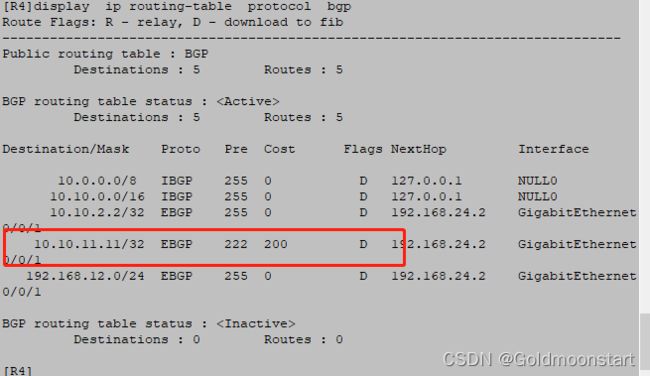
案例配置:在 R1 去往 192.168.45.0/24 ,通过比较起源属性,选择 R3 作为下一跳
R1:针对 R3 配置一个入向策略,将 192.168.45.0/24 的起源属性修改为 i
acl 2045
rule 10 permit source 192.168.45.0 0.0.0.255
quit
route-polciy R1-R3-IN permit node 10
if-match acl 2045
apply origin igp
quit
route-policy R1-R3-IN permit node 20
quit
bgp 100
peer 10.10.3.3 route-policy R1-R3-IN import
quit
 验证
验证
比较 MED
属性介绍
该属性的全称叫做:多出口鉴别器( multi-exit discriminator )
在 BGP 路由条目中,表示的是 cost ( 开销 ) ,但是该参数,默认是 0
该属性进行传输的时候,只能在之间相邻的两个 AS 之间,互相传递,不能跨越 AS 进行传输
该属性既然可以在邻居之间互相传递,所以针对该属性,可以配置一个入向策略,也可以配置出策略,比较该属性的时候,数值越小越好,小了,表示的是去往一个目标网段的距离小
但是,并不是所有的路由条目之间都有资格进行该属性的比较的:
只有当两个 BGP 路由,来自于同一个 邻居 AS 的时候,才可以比较该属性
如果两个路由的 “ 邻居 AS 不同 ” ,则直接越过该属性,比较下一个属性。所谓的“ 邻居 AS ”指的是,“ 一个 as-path ” 最左边的 这个 AS 号
通常情况下,该属性的应用场景是:
- 在一个 AS 的边界设备上,针对 EBGP 邻居,配置出策略,目的是为了影响对方设备的选择,从而让对方的数据,选择一个进入自己的 AS 时,更加合适的入口设备
- local-preference,是为了影响自己数据的 AS 去往其他 AS 时 出口设备的选择
案例配置:在 R2/R3 配置 MED 属性,影响 邻居 AS 200 的数据,选择 R3 进入到 AS 100
因为 MED 属性,默认都是 0。所以,我们只要将 R2 发送给 R4 的 BGP 路由的 MED 属性调大,那么 R4 就自然的会选择“ 去往 R1 的时候,选择 R3 ”
R2
acl 2011
rule 10 permit source 10.10.11.11 0.0.0.0
quit
route-policy R2-R4-OUT permit node 10
if-match acl 2011
apply cost 200
quit
route-policy R2-R4-OUT permit node 20
quit
bgp 100
peer 192.168.24.4 route-policy R2-R4-OUT export
quit
验证
如果 BGP 路由跨越了 AS 进行传递了,那么该属性原有的数值,就会丢失,面临一个丢失了 MED 属性的 BGP 路由,路由器会给该路由条目分配一个默认的 MED,即 0
但是,这样我么也可以通过这样一个命令:
bgp 800
bsetroute med-none-as-maximum # 当 MED 属性丢失时,直接按4292967295来计算
另外,如果在某些场景下,我们特别需要:及时邻居 AS 不相同,也得进行 MED 的比较,那么我们可以配置以下命令:
R4
bgp 64512
compare-different-as-med # 永远比较 MED 属性
比较 BGP 的路由类型 : EBGP > IBGP
- BGP 路由类型分为:内部路由和外部路由,但是优先级都是相同的,默认是 255
- BGP 的内部路由: BGP 内部邻居之间传递的路由,在路由表找那个的类型是 IBGP;
- BGP 的外部路由: BGP 外部邻居之间传递的路由,在路由表中的类型是 EBGP
- 该属性不能通过 route-policy 进行修改
比较去往 BGP 路由的下一跳 IP 地址的 cost 大小
BGP local router ID : 192.168.12.1
Local AS number : 100
Paths: 2 available, 1 best, 1 select
BGP routing table entry information of 10.0.0.0/8:
From: 10.10.2.2 (192.168.24.2)
Route Duration: 00h00m15s
Relay IP Nexthop: 192.168.12.2
Relay IP Out-Interface: GigabitEthernet0/0/0
Original nexthop: 10.10.2.2
Qos information : 0x0
AS-path 200, origin incomplete, localpref 100, pref-val 0, valid, internal, best, select, active, pre 255, IGP cost 1
Aggregator: AS 200, Aggregator ID 192.168.45.4
Not advertised to any peer yet
BGP routing table entry information of 10.0.0.0/8:
From: 10.10.3.3 (192.168.34.3)
Route Duration: 00h00m05s
Relay IP Nexthop: 192.168.13.3
Relay IP Out-Interface: GigabitEthernet0/0/2
Original nexthop: 10.10.3.3
Qos information : 0x0
AS-path 200, origin incomplete, localpref 100, pref-val 0, valid, internal, pre
255, IGP cost 1, not preferred for router ID
Aggregator: AS 200, Aggregator ID 192.168.45.4
Not advertised to any peer yet
比较 cluster-list 的长度
属性介绍
只有当网络中存在路由反射器的情况下,并且当前查看的路由,是被' 反射” 过的。那么这个路由属性中,才会有 “ cluster-list ”属性
该属性中,包含的是路由在发射过程中,所经过的 “ cluster- 簇 ” 的名。那么,所谓的“ 簇 ”指的就是“ 路由反射器和客户端 ” 所组成的一个传输网络的范围。 那么莫仍情况下 簇 的名字就是路由反射器的 router-id ,但是可以人为修改。
该属性除了“ 影响路由选路 ” 以外,另外一个重要的作用就是: 在 簇之间防止环路! 即
当路由反射器收到一个路由的时候,如果发现其中包含了自己的 簇 ID 。则说明该路由在之前的传递过程中已经经过这歌反射器。如果再次接收的话,就会出现环路了。
所以:当发现簇列表中包含了自己的簇 ID 的时候,拒绝接收该路由
[R5]bgp 64512
[R5-bgp]peer 10.10.4.4 reflect-client
案例配置
R1:
interface loopback 9
ip address 192.168.99.99 32
R1:
interface loopback 9
ip address 192.168.99.99 32
如果想要修改 cluster id ,可以使用下面的命令:
R5: bgp 64512
peer 10.10.4.4 reflect-client
reflector cluster-id 55.1.1.1
quit
BGP local router ID : 6.6.6.6
Local AS number : 64512
Paths: 2 available, 1 best, 1 select
BGP routing table entry information of 192.168.99.99/32:
From: 192.168.67.7 (192.168.78.7) # 路由的更新源
Route Duration: 00h33m05s
Relay IP Nexthop: 192.168.67.7 # 经过递归查询后,所确定下来的下一跳 IP 地址
Relay IP Out-Interface: GigabitEthernet0/0/0 # 经过递归查询后,数据出接口
Original nexthop: 192.168.78.8 # 路由条目的下一跳 IP 地址
Qos information : 0x0
AS-path (64517) 800, origin igp, MED 0, localpref 100, pref-val 0, valid, exter
nal-confed, best, select, active, pre 255 # 路由属性
Advertised to such 1 peers:
10.10.5.5
BGP routing table entry information of 192.168.99.99/32:
From: 10.10.5.5 (192.168.56.5)
Route Duration: 00h00m06s
Relay IP Nexthop: 192.168.56.5
Relay IP Out-Interface: GigabitEthernet0/0/1
Original nexthop: 10.10.4.4
Qos information : 0x0
AS-path 100, origin igp, localpref 100, pref-val 0, valid, internal-confed, pre
255, IGP cost 2, not preferred for IGP cost # 没有优选的原因是因为 IGP cost
Originator: 4.4.4.4 # 起源 ID ,用于在一个 簇内,防止路由环路发生
Cluster list: 55.1.1.1 # 簇列表,用于在不同的 簇之间,防止环路
Not advertised to any peer yet
比较 router-id 的大小)( 如果有反射器,就比较 originator id)
当比较路由条目的属性的时候,如果属性中存在 originator ID 那么就直接比较该参数,越小越好,如果没有该参数的话,则比较 router-id ,越小越好
比较 peer 后面的 IP 地址 ,越小越越好
其实,当 BGP 路由前面 8 个属性,都完全相同的时候,BGP 协议就已经认为多个路由是完全相同的了,但是,对于 BGO 而言,所发送出去的路由,永远是“ 只有 1 个 ” ,即在数据库中的那个符号 “ > ”,永远只有 1个。
如果我们对 BGP 协议,开启了路由表的“ 负载均衡 ” 功能,那么,只要前面 8 个原则相同,此时的多个路由条目,都会放入到路由表中。但是,被传输出去的。依然是“ 一个 ”。
BGP 协议,默认情况下没有开启负载均衡,如果想要开启的话,需要通过下面的命令:
BGP 100
maximum loac-balancing 3 # 指的是针对任何一个 BGP 路由,在路由表中下一跳 I呸 地址最多可以 3 个,并且该命令针对 IBGP 路由和 EBGP 路由,都起作用
maximum loac-balancing ibgp 4 # 仅仅对 BGP 的内部路由,开启负载均衡
maximum loac-balancing EBGP 4 # 仅仅对 BGP 的外部路由,开启负载均衡
maximum loac-balancing 1 # 这就是 “ 关闭负载均衡 ”
额外需要注意的是:
形成负载均衡的多个 BGP 路由器,他们的 as-path 属性,不能仅仅是长度相同,其中的 as-path 包含的每个 as-path 的顺序,都是完全相同的。
BGP属性分类
- 公认必须遵循( Well -known mandatory):所有 BGP 设备都可以识别此类属性,且必须存在于 Update 报文中。如果缺少这类属性,路由信息就会出错。
- origin 属性 # ( 起源属性 )
- as-path 属性 #( 经过哪些 AS 的路径 )
- next-hop 属性 #( 下一跳 )
- 公认任意( Well-known discretionary ):所有 BGP 设备都可以识别此类属性,但不要求必须存在于 Update 报文中,即就算缺少这类属性,路由信息也不会出错。
- local-preference
- 可选过渡( Optional transitive ):BGP 设备可以不识别此类属性,如果 BGP 设备不识别此类属性,但是它任然会接收这类属性,并通告给其他对等他.
- MED
- 簇列表
- 起源 ID
BGP的路由表
调整路由属性
在 路由表中,BGP 协议的路由,和其他协议的路由,所关注的属性,都是相同的
- 优先级:表示的是路由的稳定性,数值越小越好;内部和外部的 BGP ,都是 255
- 开销值: 表示的是去往一个路由的距离,越小越好;在 BGP 中,通过 MED 参数表示修改 BGP 路由属性之优先级
R4 :
bgp 64512
preference 199 188 166 # 外部 BGP 优先级调整为 199
内部 BGP 优先级调整为 188
本地产生的 BGP 优先级调整为 166 ( 即汇总的 )
[R4-bgp]preference 199 188 166

在 R4 上,仅仅修改 10.10.55.55/32 的路由优先级为 222,其他的保持默认
acl 2055
rule 10 permit source10.10.11.11 0.0.0.0
quit
route-policy PRE permit source node 10
if-match acl 2055
apply preferece 222
quit
bgp 64512
preference route-policy PRE
quit
过滤路由
匹配路由
- ACL ( 基本 ACL)
- acl 分为基本 ACL 和 高级 ACL ,但是在匹配路由条目的时候,只能用基本 ACL
- 基本 ACL 匹配路由的弊端在于:不精准
- ip-prefix
- 正式因为 基本 ACL 匹配路由不精准,所以我们才会使用 “ 前缀列表 ”
- 可以同时匹配网段和掩码
- 案例1:在 R1 上,针对 R2 配置入向策略,干掉 10.10.55.55/32
- ip ip-prefix Deny -55 deny 10.10.55.55 32
- ip ip-prefix Deny-55 permit 0.0.0.0 0 greater-equal 0 less-equal 32
- R1
- bgp 100
- peer 10.10.2.2 ip-prefix Deny-55 import
- quit
- 案例1:在 R1 上,针对 R2 配置入向策略,干掉 10.10.55.55/32
- 案例2 :在 R2上,针对 R1 配置出向策略。干掉 34.0/24 和 45.0 /24
- 前缀列表的格式:
- ip ip-prefix ABC deny { 想要干掉的多个路由的公共部分 } { 公共部分的位数 } { 最短的掩码} { 最长的掩码 }
- 想要干掉的多个路由的公共部分:将多个路由的网段列出,找对应的公共部分
- 相同的位,不变,直接写
- 不同的位,变化,写成 0
- 公共部分的位数:表示前面的公共部分中,一共多少个 BIT 是相同的
- 最短的掩码:表示的是被匹配的多个路由条目中,掩码最短的一个
- 最长的掩码:表示被匹配的多个路由条目中,掩码最长的一个
- 所以
- 192.168.24.0/24 ==> 0001 1000
- 192.168.45.0/24 ==> 0010 1101
- 最终公共部分是 192.168.00 ** **** . **** **** -->192.168.32.0
- 公共的部分位数是:18
- 最短掩码:/24
- 最长的掩码是:24
- 所以,最终的前缀列表应该是 :
- ip ip-prefix HAHA deny 192.168.0.0 18 greater-equal 24 less-euqal 24
- ip ip-prefix HAHA deny 0.0.0.0 0 greater-equal 0 less-equal 32
- R2
- bgp 100
- peer 10.10.1.1 ip-prefix HAHA export
- quit
- 前缀列表的格式:
但是,反过来看:上诉的前缀列表 HAHA ,到底匹配了多个个路由呢?
应该是匹配了2 的 4 次方,16 个路由。但是这个 16 个路由,前面的 20 BIT ,都是相同的
但是网络掩码是 24 位,所以中间还是有 4 BIT 。是可以随意变化的,所以,一共有 2 的 4 次方。16个路由。
并且,还是连续的 16 个网段
所以,可以看到
- 虽然前缀列表匹配路由的时候很精准,有网段有掩码
- 但是被匹配的路由,必须得是连续的多个路由,否则就有可能匹配住错误的路由条目
但是,对于 ACL 而言,就是完全可以实现同时匹配那些不连续的路由条目。所以,ACL 匹配多个路由条目的时候,还是比较灵活的。
两者相同的点
- 一个 ACL 和前缀列表,都可以同时包含多个条目
- 为了区分每个条目,在 ACL 中时通过 rule 进行区分的,在前缀列表中,是通过 index 进行区分的
- 在匹配路由的过程中,都是按照条目的变化,从小到大依次匹配,如果有一个条目匹配成功,则后续的条目就不需要关系了
- 在最后都存在一个隐含的,默认的,决绝所有的条目。
- as-path 列表:用于匹配海量路由
- 该工具,主要用用来匹配 BGP 的 as-path 属性的
- 如果想要了解这个工具,必须得了解 as-path 属性的组成:数字、空格
- 如果当前这个工具( as-path 列表 ),就必须得有能力去匹配数字和空格
- 所以,当时就得用到 “ 正则表达式--regular expression ”
- 但是,我们需要知道的是:在很多系统以及很多技术应用中,都是存在正则表达式的,比如:Windows 、Linux 、web 开发都会使用正则表达式。
- 但是,不同系统或者不同应用中的正则表达式中的某些字符的含义,是不同的
- 正则表达式中,包含了两种类型的字符:
- 普通字符
- 转义字符
- ^ ,表示的是一个 as-path 的开始
- ^ 200 ,表示的是以 200 开头 的 as-path
- 左边的 AS 有可能是 200 ,也有可能是 2001,20001,20002
- $ ,表示的是一个 as-path 的结束
- 999$,表示的是以999 结尾的 as-path
- 最右边的 AS 有可能是 999,还有可能是 1999,2999
- _ ,表示的是一个 as-path 中的空格或者逗号
- ^ 200-999_666$ ,表示的是以 200开头的 ,第二个是999,并且以 666纪委的 as-path
- 此时表示的 as-path 就是 :200 999 666
- · ,表示的是一个as-path 中的任意的单个字符
- ^200.- ,表示的是 以 as 2000~ 2009 开头的 as-path
- *,表示的是一个 as-path 中的前面的字符的 0倍或者多倍
- 该字符的通常用法是:
- .* ,所有的是所有类型的 as-path
- 该字符的通常用法是:
- ( ),表示的是将括号中的 as-path 看做一个整体
- 比如 1(29)* ---> 1/ 129 / 12929 12929292929
- [ ], 表示的是中括号中的 所包含的数字的任何一个数字
- 1[ 3-5 ] 0 ————》 130 / 140 /150
- | ,表示的是该符号的前后的两个数字的其中 1 个 ,是或的关系
- 1[ 6 | 9 ]0 ————> 160 或者 190
- +,表示的是该符号的前面的那个数字的1 倍或者是多倍
- 19 + ---> 19 / 199 / 19999
- ^ ,表示的是一个 as-path 的开始
- ^ 匹配一个字符串的开始
- 如 “ ^ 200 ” 表示只匹配 as-path 的第一个值 为 200
- $ 匹配一个字符串的结束
- 如 “ 200$ ”表示只匹配 as-path 的最后一个值为 200
- . 匹配任何单个字符,包括空格
- _ 匹配一个符号。如逗号、括号、空格符号等
- ? 匹配前面的一个字符,可以 0次或者多次出现
- () 匹配的一个范围内的 AS ,通常和 “ _ ” 一起使用
- . 连接符
- ? ip as-path-acl 2 deny 70$ ( 拒绝从 AS 70 始发的路由)
- ? ip as-path-acl 2 permit .* ( 允许其他 AS 的路由 )
- . 连接符
- 常见的案例表示
- 匹配所有从邻居 as 200 发送过来的素有路由
- ip as-path-filter abc permit ^ 200_
- 匹配所有从 as 100 宣告的那些 BGP 路由
- ip as-path-filter abc permit _100$
- 匹配所有本 AS 内产生的那些路由
- ip as-path-filter abc permit ^$
- 匹配那些在传输过程中,经过 as 666 的所有路由
- ip as-path-filter abc permit _666_
- 匹配起源于as 100 ,来自于邻居 as 200,中间经过as 666 的那些路由
- as-path-filter abc permit ^200_.*_666_.*_100$
- 通过 as-path 属性,匹配所有的 BGP 路由
- ip as-path-filter abc permit .*
- 匹配所有从邻居 as 200 发送过来的素有路由
- 团体属性列表:用于匹配海量路由,还能控制路由的传递范围。
- 该属性,类似于 IGP 协议中的 “ tag ” .正式因为 BGP 协议是不支持 TAG 的,所以就搞了一个community ( 团体)属性,实现类似于tag 的作用
- 公有团体属性:仍和一个 BGP 路由器都认识,根据该属性可以判断该路由的传递范围
- internet :表示该 BG 路由条目,可以任意传输
- 任何一个 BGP 路由,默认情况下,都隐含一个 internet 团体属性
- no-export : 表示该 BGP 路由不可以传递给EBGP 邻居
- no-advertise : 表示该 BGP 路由不可以通告给任何邻居
- No-Exoprt_Subconfed :表示该 BGP 路由不可以在联盟内的各个小 AS 之间互相传递
- 当一个 BGP 路由同时配置了多个 “ 公有团体属性 ”之后,那么该路由的传递范围,也遵循“ 最小的传递范围 ”
- internet :表示该 BG 路由条目,可以任意传输
- 私有团体属性:由用户自己定义的,更加类似于一个 TAG ( 标记)
- 关于私有团体属性,就是用户自定义的一组标签数值。但是格式有两种:
- 通过 10 进制数字表示,一共 32 BIT ,所以取值是 2 的 32 次方
- 通过 aa:nn 的格式, aa 的取值是 1-65535,nn 的取值是 1-65535{ 常用的团体属性的格式 }
- 案例:在 R6 上,通过团体属性,干掉 R5 传递过来的路由
- 希望 R4 将路由 10.10.11.11/32 传递 R5 后,R5 可以针对 该路由添加一个团体属性 : 200:11,然后该路由被 R5 反射给 R6,
- 在 R6 上通过“ 团体属性列表 ” 抓取 200:11 ,然后过滤掉该路由。
- 在 R5 上,针对 R4 ,配置入向策略,添加 200:11
- acl 2011
- rule 10 permit source 10.10.11.11 0.0.0.0
- quit
- route-policy R5-R4-IN permit node 10
- if-match acl 2011
- apply community 200:11
- quit
- routr-policy R5-R4-IN permit node 20
- quit
- ip ip-prefix 11.11 permit 10.10.11.11 32
- acl 2011
- bgp 64512
- peer 10.10.4.4 route-policy R5-R4-IN impor
- 在 R5 上,针对 R4 ,配置入向策略,添加 200:11
- 在 R6 上,通过 community-filter 抓取 200:11,然后配置 rout-policy ,调用 community-filter
- ip community-filter 1 permit 200:11
- route-policy R6-R5 -IN deny node 10
- if-match community-filter 1
- quit
- route-policy R6-R5-IN permit node 10
- quit
- bgp 64512
- peer 10.10.5.5 route-policy R6-R5-IN import
- quit
- 注意:
- 一个BGP 路由,可以同时携带多个团体属性
- 多个团体属性之间的关系,是“ 或 ” 的关系,只要其中 1 个属性被匹配,那么该路由就被匹配成功
- 团体属性列表中,多个团体属性的匹配可以这样
- ip community-filter 1 permit 200:11
- ip community-filter 1 permit 200:22
- 查看团体属性的时候,多个条目之间的关系是: 或的关系
- display ip community-filter
- Community filter Number: 1
- permit 200:11
- permit 200:22
- Community filter Number: 1
- display ip community-filter
- 在使用团体属性列表匹配路由的时候,首先匹配 200:11,如果匹配补助的话,则匹配 200:22,如何都匹配不住的话则匹配最后一个“ 拒绝所有 ”
- ip community-filter 1 permit 200:11 200:22 200:33
- [R6]display ip community-filter
Community filter Number: 1
permit 200:11 200:22 200:33
上述列表,表示的是:一个路由条目必须同时含有 200:11 200:22 200:33 三个属性,是与的关系
- 早团体属性列表中,最后依然包含一个隐含的“ 拒绝所有 ”如果想在团体属性列表中,写“ 允许所有, ”我们有两种写法:
- ip community-filter 11 deny 200:11
- ip community-filter 11 permit # 表示允许所有或者
- ip community-filter 11 permit internet # 表示允许所有
- 关于私有团体属性,就是用户自定义的一组标签数值。但是格式有两种:
团体属性,默认情况下,是不会在邻居之间自动传输的,如果想要在邻居之间传输的话,需要使用命令:
bgp ***
peer x.x.x.x advertise-communtiy ---> 向对方“ 发 ” 团体属性!
调用策略
- filter-policy
- R2
- irule 10 deny source 10.10.55.55 0.0.0.0
- rule 20 permit source any
- quit
- bgp 100
- peer 10.10.1.1 filter-policy 2055 export
- R2
- ip-prefix
- R2
- ip ip-prefix 55 permit 10.10.55.55 32
- bgp 100
- peer 10.10.1.1 ip-prefix 55 permit
- quit
- R2
- as-path-filter
- 假如:
- 在 R1 上,针对 R3 配置入向策略,干掉那些属于 AS 200 的路由。允许其他所有类型的路由:
- ip as-path-filter abc deny ^200$
- ip as-path-filter abc permit ^$ # 允许所有
- bgp 100
- peer 10.10.3.3 as-path-filter abc import
- 在 R1 上,针对 R3 配置入向策略,干掉那些属于 AS 200 的路由。允许其他所有类型的路由:
- 假如:

- route-policy
R6-route-policy]if
[R6-route-policy]if-match ?
acl Specify an ACL
as-path-filter BGP AS path list
community-filter Match BGP community filter
cost Match metric of route
extcommunity-filter Match BGP/VPN extended community filter
interface Specify the interface matching the first hop of routes
ip IP information
ip-prefix Specify an address prefix-list
ipv6 IPv6 Information
mpls-label Give the Label
rd-filter Route-distinguisher filter
route-type Match route-type of route
tag Match tag of route
验证结果
在 BGP 协议中的路由过滤,都是针对“ 数据库 ” 的,所以要查看最终的效果,可以直接查看数据库:
- display bgp routing-table
- display ip ip-prefix
- display acl all
- display ip as-path-filter
- display route-policy
默认路由
针对所有邻居产生默认路由
即自己本地必须存在默认路由并且通过 network 的方式,将路由宣告进入到 BGP 的数据库,此时,BGP 协议,就会将该默认路由,发送给所有的 BGP 邻居
针对特定邻居产生默认路由
例如 : 在 R2 上针对 R1 这个特定的邻居产生默认路由:
bgp 100
peer 10.10.1.1 default-route-advertise --> 强制性的产生默认路由或者
peer 10.10.1.1 default-route-advertise
conditional-route-match-all 》》有条件的产生默认路由,并且要求该命令后面跟的 所有的条件路由都同时存在,此时才能向邻居发送默认路由
conditional-route-match-any ...#有条件的产生默认路由,此时的route-policy 匹 配的路由如果存在于本地的路由表中,那么就可以向邻居发送默认路由
汇总路由
- BGP 的汇总与 IGP 协议的汇总的比较
- 相同点
- 汇总的行为,都是发生在“ 发送路由 ” 的时候,而不是“ 接收 ” 时。
- 汇总都可以实现:讲很多路由,变成很少的路由,实现系统资源的节省,以及提高网络的稳定性
- 不同点
- 针对 IGP 协议而言,一旦汇总,那么就只发汇总路由,不发明细路由的
- 针对 BGP 协议而言,一旦汇总,汇总后的路由皆可以发,也可以不发;针对明细路由,也可以都发,也可以都不发,还可以一部分发,一部分不发
- 相同点
- 自动汇总
- BGP 协议的自动汇总,默认是关闭的,如果想要开启的话,也仅仅是针对那些通过 impor-route 命令产生的BGP 路由起作用,
- 并且最终汇总的结果,也只能是:主类网络的路由和掩码
- 手动汇总
可以在任何一个 BGP 路由器上没针对任何类型的 BGP 路由,配置手动汇总;并且汇总之后的结果,也很灵活,想怎么汇总就怎么汇总。
拓扑

配置如下:
基本配置
R1
undo terminal monitor
system-view
sysname R1
interface g0/0/0
ip address 192.168.14.1 24
quit
interface g0/0/1
ip address 192.168.16.1 24
quit
interface loopback 0
ip address 10.10.1.1 32
quit
bgp 100
router-id 1.1.1.1
peer 192.168.14.4 as-number 45
peer 192.168.16.6 as-number 45
network 10.10.1.1 32
quit
R2
undo terminal monitor
system-view
sysname R2
interface g0/0/0
ip address 192.168.24.2 24
quit
interface g0/0/1
ip address 192.168.26.2 24
quit
interface loopback 0
ip address 10.10.2.2 32
quit
bgp 200
router-id 2.2.2.2
network 10.10.2.2 32
peer 192.168.24.4 as-number 45
peer 192.168.26.6 as-number 45
quit
R3
undo terminal monitor
system-view
sysname R3
interface g0/0/0
ip address 192.168.34.3 24
quit
interface g0/0/1
ip address 192.168.36.3 24
quit
interface loopback 0
ip address 10.10.3.3 32
quit
bgp 300
router-id 3.3.3.3
network 10.10.3.3 32
peer 192.168.34.4 as-number 45
peer 192.16836.6 as-number 45
quit
R4
undo terminal monitor
system-view
sysname R4
interface g0/0/0
ip address 192.168.14.4 24
quit
interface g0/0/01
ip address 192.168.24.4 24
quit
interface g0/0/02
ip address 192.168.34.4 24
quit
interface g4/0/0
ip address 192.168.45.4 24
quit
interface loopback 0
ip address 10.10.4.4 32
quit
bgp 45
router-id 4.4.4.4
network 10.10.4.4 32
peer 192.168.14.1 as-number 100
peer 192.168.24.2 as-number 200
peer 192.168.34.3 as-number 300
peer 192.168.45.5 as-number 45
quit
R5
undo terminal monitor
system-view
sysname R5
interface g0/0/1
ip address 192.168.45.5 24
quit
interface g0/0/2
ip address 192.168.56.5 24
quit
interface loopback 0
ip address 10.10.5.5 32
quit
bgp 45
router-id 5.5.5.5
network 10.10.5.5 32
peer 192.168.45.4 as-number 45
peer 192.168.56.6 u tm,as-number 45
quit
R6
undo terminal monitor
system-view
sysname R6
interface g0/0/0
ip address 192.168.16.6 24
quit
interface g0/0/01
ip address 192.168.26.6 24
quit
interface g0/0/02
ip address 192.168.36.6 24
quit
interface g4/0/0
ip address 192.168.56.6 24
quit
interface loopback 0
ip address 10.10.6.6 32
quit
bgp 45
router-id 6.6.6.6
network 10.10.6.6 32
peer 192.168.16.1 as-number 100
peer 192.168.26.2 as-number 200
peer 192.168.36.3 as-number 300
peer 192.168.56.5 as-number 45
quit

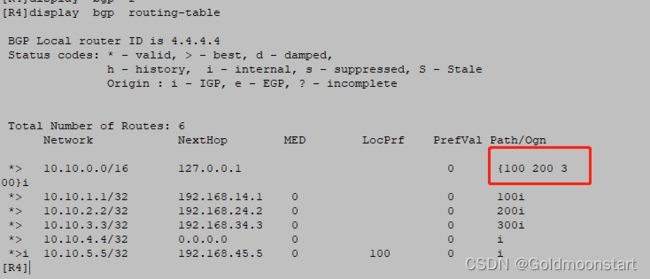
R4上,针对 10.10.1.1/32 ,10.10.2.2/32 ,10.10.3.3/32 进行汇总,汇总后的路由条目是: 10.10.0.0/16
手动汇总,配置命令如下
[R4-bgp]aggregate 10.10.0.0 16 ?
as-set Generate the route with AS-SET path-attribute
attribute-policy Set aggregation attributes
detail-suppressed Filter more detail route from updates
origin-policy Filter the originate routes of the aggregate
suppress-policy Filter more detail route from updates through a Routing
policy
重要字段解释
detail-suppressed # 表示发送汇总路由的时候,“ 抑制 ” 所有的明细路由
suppress-policy # 表示基于该命令后面的 “ route-policy ” 包含的规则,进行有选择的抑制,不在 是“ 抑制所有明细路由 ”,优先级比 detail-suppressed 高。
as-set # 表示让汇总路由,继承所有明细路由的 “ as-path ” 属性中包含的 AS 号,如此以来可以 防止汇总路由在不同的 AS 之间,形成环路{ 该命令在汇总时,是必选命令 }
attribute-policy # 该参数后面跟的是,某一个 route-policy ,凡是在路由器上存在该 route-policy 所包含的明细路由,才能产生汇总,如果没有这些路由存在,就无法产生汇 总,所以这个参数也可以理解为:有条件的产生 BGP 汇总路由。
在 R4 上,直接进行汇总,不跟任何参数:发现汇总和明细都发
R4
bgp 45
aggregate 10.10.0.0 16
R4]display bgp routing-table
BGP Local router ID is 4.4.4.4
Status codes: * - valid, > - best, d - damped,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
Total Number of Routes: 6
Network NextHop MED LocPrf PrefVal Path/Ogn
*> 10.10.0.0/16 127.0.0.1 0 i
*> 10.10.1.1/32 192.168.14.1 0 0 100i
*> 10.10.2.2/32 192.168.24.2 0 0 200i
*> 10.10.3.3/32 192.168.34.3 0 0 300i
*> 10.10.4.4/32 0.0.0.0 0 0 i
*>i 10.10.5.5/32 192.168.45.5 0 100 0 i
[R4]
此时我们去 R5 上查看 ,只有汇总路由,没有明细路由

在 R4上进行汇总,但是对部分路由进行抑制,比如: 仅仅抑制 10.10.2.2
acl 2002
rule permit source 10.10.2.2 0.0.0
quit
route-policy A permit node 10
if-match acl 2002
quit
bgp 45
aggregate 10.10.0.0 16 suppress-policy A
[R4]display bgp routing-table
BGP Local router ID is 4.4.4.4
Status codes: * - valid, > - best, d - damped,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
Total Number of Routes: 6
Network NextHop MED LocPrf PrefVal Path/Ogn
*> 10.10.0.0/16 127.0.0.1 0 i
*> 10.10.1.1/32 192.168.14.1 0 0 100i
s> 10.10.2.2/32 192.168.24.2 0 0 200i
*> 10.10.3.3/32 192.168.34.3 0 0 300i
*> 10.10.4.4/32 0.0.0.0 0 0 i
*>i 10.10.5.5/32 192.168.45.5 0 100 0 i
在 R4 上进行汇总以后,虽然汇总路由继承了很多类型的 BGP 属性,但是明细路由的 as-path 属性却没有继承,如此一来,导致 as-path 属性丢失,这样导致的结果,有可能是:让形成的 BGP 汇总路由,有可能形成环路
所以,在配置 BGP 汇总路由的时候,一定不要丢失该属性,所以需要添加 as-set 参数
配置汇总,不带 as-set 参数
R4
bgp 45
aggregate 10.10.0.0 16
此时,汇总路由的 as-path 是空的

R4
bgp 45
aggregate 10.10.0.0 16 as-set
此时,汇总路由的 as-path 不是空的,使用 { }将所有的明细路由的 as-path 全都包含起来
这种通过{ } 来包含的 as ,我们也称之为 as-set ( as 结合)
在 as-set 中,虽然包含的也是公有 as ,但是这些 as 是没有仍会顺序而言的,
但是,as-path 中的每个 as 号,都是有严格的顺序的,as-set 会在公网上,随着 bgp 路由一起传递。
假如说,我们在 R9 上,看到这样一个 as-path 的路由
999 32 659 { 100, 200, 300}
问题1:该路由是否被汇总过?------》 是的
问题 2 : 如果被汇总了,是在那个 as 进行的汇总 ? as 659
问题 3: 被汇总的明细路由,曾经穿越过那些 as ? 100/200/300
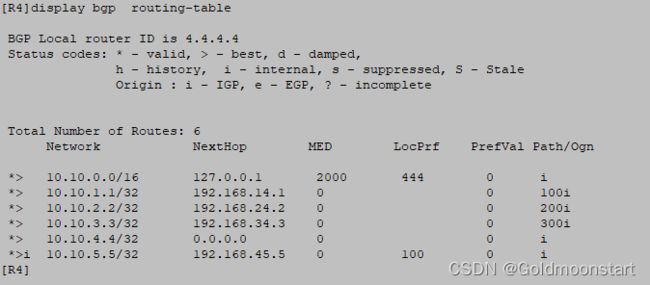
在 R4 上,进行 BGP 汇总,既然很多属性的继承规则,非常麻烦,所以我们可以基于自己的路由控制需求,明确的配置一些属性,通过 attribute-policy
例如,我们将 汇总路由 10.10.0.0/16 的 MED 设置为 2000,本地优先级设置为 444 ,起源属性为 1 ,那么配置如下
route-policy C permit node 10
apply cost 2000
apply local-preference 444
apply arigin igp
quit
bgp 45
aggregate 10.10.0.0 16 attribute-policy C
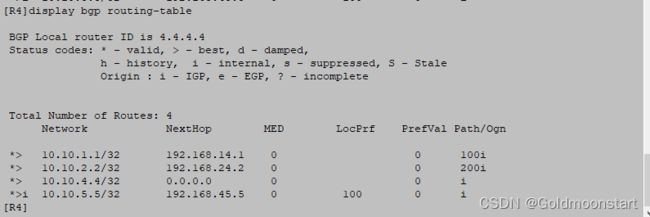
在 R4 上,针对 BGP 路由,进行有条件的汇总:即并不是任何一个明细路由存在都可以形成汇总 的,只有我们关注的明细路由存在,才可以形成汇总,使用的参数是 :origin-policy
比如:我们在 R4 上,希望明细路由 10.10.3.3/32 存在的时候,才可以形成汇总命令如下
ip ip-prefix 3.3 premit 10.10.3.3 32
route-polict D permit node 10
if-match ip-prefix 3.3
quit
bgp 45
aggregate 10.10.0.0 16 arigin-policy 0
首先我们看下 R 4 的路由

然后我们在R3 上
[R3-LoopBack0]undo ip address
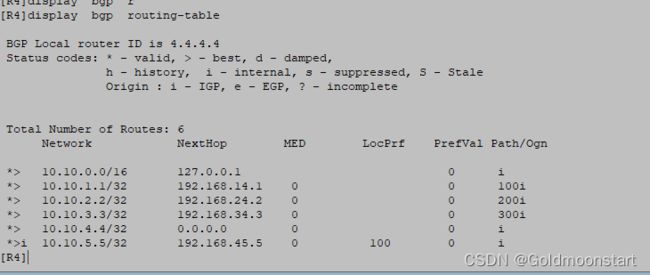
然后可以在 R4 上看到 汇总路由消失了
重新在 R3 上添加 10.10.3.3 32
路由惩罚
该特性,在 BGP 路由器上,默认是关闭的,如果开启的话,也仅仅是针对 EBGP 邻居之间的路由翻滚起作用,即:当 EBGP 邻居之间传递的路由非常不稳定,总是平凡的 up/down ,那么开启了 BGP 惩罚机制的 EBGP 邻居路由器,就回为这个 不稳定的路由,赋予 1个惩罚值,1000 ,每翻滚一次,惩罚值都会增加 1000,当惩罚值增加到 一定数值以后,改路由就开始被惩罚,前面的标志就变成 D,这个惩罚值的标准,默认是 2000.
但是该惩罚值也会随着时间的推移,自动的降低,每隔一段时间都会降低一次,并且每次都会降低一半。这个时间内,我们称之为半衰期,默认是 15分钟
如果翻滚导致的惩罚值增加的速度很慢,衰减的速度又很快,该路由的惩罚值一直都是在降低的,如果降低到一个标准,该路由就可以被重新使用了,这个标准称之为重用阈值,默认 750,一旦被重用了,那么该路由就可以放入到自己的路由表,同时也可以发送给其他的邻居设备。
比如 R1 的链路非常的不稳定,严重影响了R4 的稳定性,所以在 R4 上开启 BGP 尘封机制的命令是:
bgp 45
[R4]bgp 45
[R4-bgp]dampening ?
INTEGER<1-45> Half-life time (in minutes) for the penalty when reachable
route-policy Routing policy to specify criteria for dampening
# 如果直接回车,使用的就都是默认的参数了,如果想要修改默认参数的话,各个参数顺序如下
[R4-bgp]dampening 5 700 3000 5000
- 其中 ,5 表示 的是半衰期单位是 分钟
- 其中 , 700表示的是重用阈值,单位是分钟
- 其中 ,3000 表示的是抑制阈值
- 其中,5000 表示的是惩罚值得最大值,
为了看到效果,我们可以在 R1 上;不断删除 loopback 0 ,然后重新添加 loopback 0 ,多来几次,然后查看 R4 得 BGP 数据库:

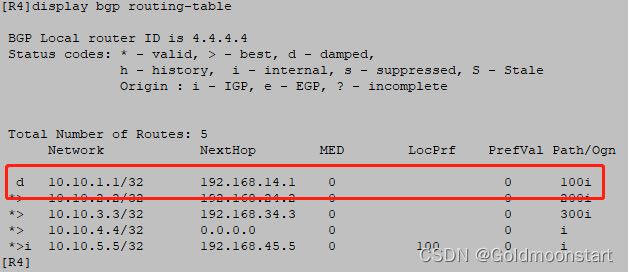
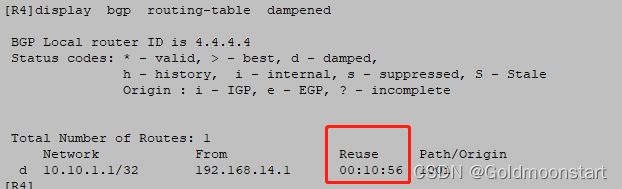
如果想要查看当前得 BGP 惩罚路由得具体信息,可以使用命令:
BGP的高级特性
认证
MD5 认证
加密对象是 TCP 连接,不是 BGP 报文;每次针对一个邻居,只能使用 1个密码;
R1 和 R4 之间的 MD5 认证:
R1
bgp 100
peer 192.168.14.4 password cipher HCIE
R4
bgp 45
peer 192.168.14.0 password cipher HCIE
key-chain 认证
加密对象和 MD5 相同,都是针对 TCP 连接,不是针对 BGP 报文。但是 key-chian 工具可以同时包含多个密码,并且可以基于不同的时间端,自动的更换密码,非常的方便和安全。
R2和R4 之间配置 key-chain 认证,在 2022年6月 26日。0 点至 3点之间。分别使用不同的密码进行加密和解密;
R2
[R2]keychain ABC mode absolute
[R2-keychain]key-id 1
[R2-keychain-keyid-1]send-time utc 00:00 2022-6-26 to 03:00 2022-6-26
[R2-keychain-keyid-1]qUIT
[R2-keychain]key-id 2
[R2-keychain-keyid-2]key-string HCIA
[R2-keychain-keyid-2]receive-time utc 00:00 2022-6-26 to 03:00 2022-6-26
[R2-keychain-keyid-2]quit
R4
[R4]keychain AAA mode absolute
[R4-keychain]ke
[R4-keychain]key-id 1
[R4-keychain-keyid-1]key-string HCIE
[R4-keychain-keyid-1]receive-time utc 00:00 2022-6-26 to 03:00 2022-6-26
[R4-keychain-keyid-1]quit
[R4-keychain]key-id 2
[R4-keychain-keyid-2]key-string HCIA
[R4-keychain-keyid-2]send-time utc 00:00 2022-6-26 to 03:00 2022-6-26
[R4-keychain-keyid-2]quit
[R4-keychain]quit
[R4]bgp 45
[R4-bgp]peer 192.168.24.2 keychain AAA
[R4-bgp]quit
[R4]
注意:
以上钥匙中所使用的时间,是根据配置设备的本地时间来计算的,所以,应该确保整个网络中的所有设备的时钟应该都是相同的,想要查看设备的时钟,使用命令是
display clack
GTSM ( 该机制不对 BGP 报文或者 TCP 连接进行加密,但是会检查 BGP 保温你得合法性)
该机制,主要是通过检查 BGP 邻居之间发送的 BGP 报文的 TTL 值,是不是在 GTSM 机制所规定的“ 合法的 TTL "范围内,如果不在的话,默认行为是丢弃这样的 TTL 报文。
peer x,x.x.x valid-ttl-hops
注意:
默认情况下,IBGP 邻居之间的 BGP 报文,TTL 默认是 255
默认情况下,EBGP 邻居之间的 BGP 报文,TTL 默认是 1
对等体组

所谓的对等体组,指的是 peer-group,即,将很多很多具有相同配置的邻居,可以加入到同一个组中;然后我们的命令,仅仅是针对这个“ 组 ” 配置。然后属于该组的所有邻居设备。都可以共享使用这些所有的 BGP 配置命令,所以带来的好处有两个:
- 可以大大减少网络工程师的配置复杂度
- 在路由传输角度来说,可以让路由器在产生路由的时候,节省很多系统资源。因为一个 BGP 路由器会为一个邻居产生一个 update ,此时这个行为是需要消耗资源的;如果BGP 路由器本身存在 20 个BGP邻居。那么就需要产生 20 个update 。但是我们如果将这 20 个邻居,加入到一个 peer-group ,那么 BGP 路由器,就仅仅产生一个 update ,给这个组,就可以了。但是通过“ 对等体组 ”这个技术,快速的将这一个 update 复制 20 份,然后快速的转发给 20 个邻居,所以,相比较“ 路哟器产生新的 update ”来说,“ 复制 update ”的行为更加的节省系统资源。
在上图中,在 R1上,与 AS 200 的边界设备,建立邻居的时候,因为对他们的配置命令都是类似的,所以可以使用对等体组
- 在 R1 上建立 BGP 对等体组
- 在 R1 上配置BGP 对等体组
- 在 R1 上将具体的邻居加入到对等体组
- 验证BGP 对等体组,以及最终的邻居的状态
- R1
- bgp 100
- router-id 1.1.1.1
- group as-200 external # 指定对等体组 as-200 的类型是“ 外部 ”,因为一会我们要向这个对等体组中加入的邻居都是属于 AS 200的,这些邻居相对于 R1 而言,都是 EBGP 邻居,但是如果不指定这个对等体组的类型,那么默认的是 内部 ”的
- peer as-200 as-number 200 # 对等体组,指定 as 号
- peer192.168.12.2 group as-200 # 将邻居 IP 地址192.168.12.2 加入到对等体组
- peer192.168.13.3 group as-200 # 将邻居 IP 地址192.168.13.3 加入到对等体组
- router-id 1.1.1.1
- bgp 100
- R1
BGP peer-group: as-200 # 对等体组的名字
Remote AS: 200 # 对等体组属于的 as 号
Authentication type configured: None # 为对等体组配置的认证类型
ype : external # 对等体组的类型是 EBGP
PeerSession Members:
192.168.12.2 192.168.13.3
Peer Members:
192.168.12.2 192.168.13.3
查看对等体组的详细信息

ORF( outbound route filter :出向路由过滤 )
拓扑

在上诉得拓扑中,我们在 AS 200 的边界设备 ( ASBR )--R2/R3,针对 AS 100 发过来的路由,配置入项策略,干掉 10.10.12.12/32为了实现路由的精准匹配,所以我们在 R2/R3 上,针对 R1 ,使用 ip-prefix 匹配 10.10.12.12 /32 配置命令如下:
在 R1 上宣告 多个 测试路由:
R1
[R1]interface LoopBack 0
[R1-LoopBack0]ip address 10.10.10.10 32
[R1-LoopBack0]quit
[R1]interface LoopBack 11
[R1-LoopBack11]ip address 10.10.11.11 32
[R1-LoopBack11]int loopback 12
[R1-LoopBack12]ip address 10.10.12.12 32
[R1-LoopBack12]quit
[R1]bgp 100
[R1-bgp]network 10.10.10.10 32
[R1-bgp]network 10.10.11.11 32
[R1-bgp]network 10.10.13.13 32
R2
[R2]ip ip-prefix 12.12 deny 10.10.12.12 32
[R2]ip ip-prefix 12.12 permit 0.0.0.0 0 less-equal 32
[R2]bgp 200
[R2-bgp]peer 192.168.12.1 ip-prefix 12.12 import
R3
[R3]ip ip-prefix 12.12 deny 10.10.12.12 32
[R3]ip ip-prefix 12.12 permit 0.0.0.0 0 less-equal 32
[R3-bgp]quit
[R3]bgp 200
[R3-bgp]peer 192.168.13.1 ip-prefix 12.12 import
[R3-bgp]qUIT
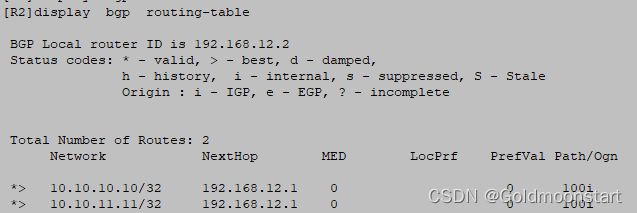
此时在 R2/R3 上的 BGP 数据库如下:以 R2 为例
但是,虽然 R2/R3 不接收10.10.12.12/32 这个路由,但是 R1 其实依然会发送该路由的,
那么,导致的结果就是:有一个废路由,无情的占用了 AS 之间的宝贵的链路的带宽资源,但所以,为了防止这些” 不想要的 路由“ 对中间链路资源的占用,我们可以考虑:在 R1 上这蒙迪欧 R2/R3 配置出向策略。
我们是 AS200 的网络工程师,是没有权限操作合作运营商-AS 100 的路由器的,所以我们,不能去配置 R1 ,也不能要求 AS 100的工程师去配置 R1,但是我们可以哎 AS100/AS 200 之间,建立 BGP 邻居关系的时候,提前协商号 BGP 的一种可选能力------ ORP
该能力:可以将自身所配置的 用作“ 入向策略 ”“ 前缀列表 ” 这个工具,发送给对端的 EBGP 邻居 R1,使用相同的 “ 前缀列表 ” ,用作" 出向策略 ",从而影响了 R1 的发送路由的结果,从而节省了 A100/ AS 200 之间的链路资源
配置如下:
在 R2 / R3上,针对 R1 ,开启 ORF 功能
R2
bgp 200
[R2-bgp]peer 192.168.12.1 capability-advertise orf ip-prefix both
R3
bgp 200
[R3-bgp]peer 192.168.13.1 capability-advertise orf ip-prefix both
在 R1 上,针对 R2/ R3 ,开启 ORF 功能
R1
bgp 100
[R1-bgp]peer as-200 capability-advertise orf ip-prefix both
配置完上述的命之后,批次之间的 BGP 邻居关系会端口,是因为:BGP 邻居之间的能力协商靠的是 OPEN 报文,而该报文只有在建立 TCP 连接之后才会发送,所以,一旦输入 ORF 能力协商,两边的 原有TCP 连接会断开,当再次建立的时候,才会发送 Open 报文。等待邻居从新建立之后,我们再次在 R1 上验证:发送个给 R2 的路由,已经不包含 10.10.12.12/32了。

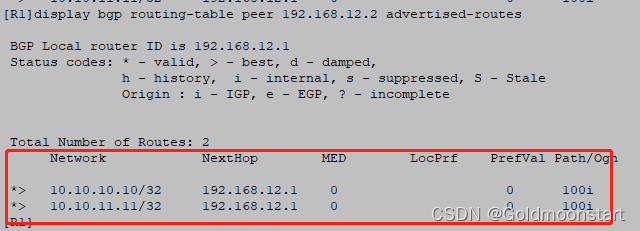
R1 之所以在发送路由的时候,就直接干掉了 10.10.12.12/32 ,是因为: R1 收到了 R2 发送过来的 ip-prefix 并且用在了 R1 对R2 的出向:
