三、详解Synchronized
目录
临界区(Critical Section)
java对象布局
MarkWord
Klass Pointer
锁升级
轻量级锁
重量级锁
重量级加锁
重量级解锁
自旋优化
偏向锁
如何进行cas?
可偏向与真正偏向
加锁之后
禁用偏向锁
撤销偏向
批量重偏向
锁消除
临界区(Critical Section)
临界区是多线程编程中的一个术语,指的是一个访问共享资源的代码区域,这个区域不能被多个线程同时执行。也就是说,在同一时刻,只能有一个线程执行临界区的代码。
临界区主要用于处理多线程环境下的竞态条件,防止数据不一致的问题。例如,当两个线程同时修改同一个变量时,就可能会出现竞态条件,导致数据不一致。
为了解决这个问题,我们可以把修改变量的代码放在临界区内,这样在同一时刻只有一个线程能够修改这个变量,从而避免了数据不一致的问题。 在Java中,我们可以使用synchronized关键字或者Lock接口来创建临界区。例如:
// 使用synchronized关键字
synchronized (this) {
// 临界区
}
// 使用Lock接口
Lock lock = new ReentrantLock();
lock.lock();
try {
// 临界区
} finally {
lock.unlock();
}
上述代码给出了两种解决方案,分别为同步锁和lock锁。本章主要分析synchronized锁。
java对象布局
当在java中new一个对象的时候,会在内存分配一块空间,jvm分配空间的方式大概有两种:1、内存空闲表。2、指针碰撞
而分配的这块空间就用来存储当前对象。那么一个java对象的布局是什么样的呢?
1、java对象头(markword) 32位机器上占用4个字节
2、类型指针(klass pointer) 开启压缩占用4个字节,不开启压缩占用8个字节
3、数组长度(如果是数组类型的话)
4、实例数据(int-4字节,long-8字节)
5、对齐空间
关于对象的布局可以查看 二、jvm对象创建及内存分配-CSDN博客
MarkWord
MarkWord是Java对象头的一部分,主要用于存储对象、锁和垃圾收集信息等。它的大小和操作系统的位数有关,32位操作系统下MarkWord的大小为32位,也就是4字节,64位操作系统下MarkWord的大小为64位,也就是8字节。每一位代表的含义如图:
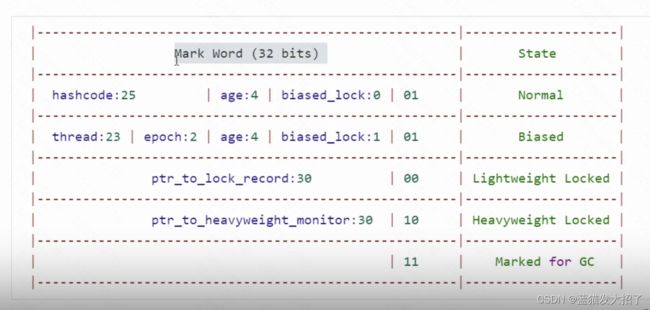
有图可以看到,根据当前对象的状态不同,markword的每一位表示的含义不一样。
1、无锁状态:用两个bit表示是否有锁(01),用一个bit表示是否为偏向锁,4bit表示对象年龄,25bit表示对象hashcode
2、偏向锁:用两个bit表示是否有锁(01),用一个bit表示加了偏向锁,4bit表示对象年龄,23bit表示偏向的线程id。
3、轻量级锁:用两个bit表示轻量级锁(00),同时其他bit表示加锁线程的栈帧中的【锁记录地址】。
4、重量级锁:用两个bit表示重量级锁(10),同时其他bit表示【monitor地址】
5、gc标记:直接用两bit(11)表示gcmark
Klass Pointer
Klass Pointer和Class Pointer是不一样的。Klass Pointer指向了当前class文件在元空间的地址,包括类的名称、访问修饰符、类变量、方法等。当加载一个class的时候,jvm将会在两个地方创建对象:1、在堆中创建Class对象。2、在元空间创建Klass对象。
锁升级
由于monitor对象是操作系统提供的,因此每次线程加锁就会导致用户态切换至系统态,如果每次都申请monitor,那么需要的代价就太大了。而在程序真正运行的时候,有一些情况下是不会真正触发并发的。因此可以考虑一种方式,减少申请monitor,让加锁更加的方便快捷。
轻量级锁
下面模拟一下synchronized的轻量级锁的加锁过程,参照下面的代码进行详解:
public void lock1(){
synchronized(this){
lock2();
}
}
public void lock2(){
synchronized(this){
//do something
}
}上述代码中,线程先执行lock1,在方法中针对this进行加锁,然后再临界区调用lock2。在lock2中继续对this进行加锁。下面分析一下整个流程:
1、当线程A进入lock1的时候,首先会在栈中创建【锁记录】。【锁记录】中包含两个部分:对象引用和锁记录地址。之后将对象引用指向this对象,并利用cas的方式将锁记录地址和this对象的markword进行替换。这里cas的过程就是通过判断this的markword的后两个bit是否为01来进行。
如果cas成功,那么进行替换。
如果cas失败。则说明当前this的markword后bit不是01,也就是说当前this已经被其他线程加了轻量级锁,此时进行锁膨胀(重量级锁)。

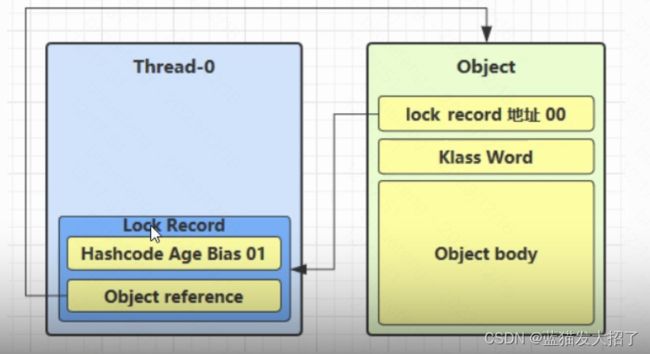
2、当线程A进入lock2之后,同样会创建【锁记录】。然后将对象引用指向this对象,然后利用cas将this的markword和自己的锁记录地址进行替换,但是此时肯定是失败了,因为在lock1中当前线程已经将this的markword进行了替换,但是由于是相同的线程进行重入,因此锁记录地址存储null,而不会执行锁膨胀。
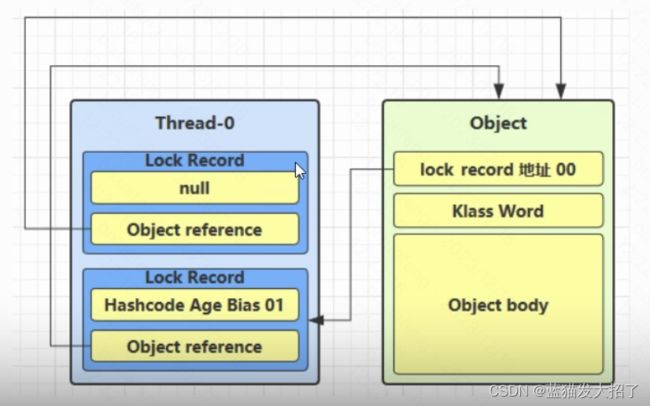
3、当线程A退出lock2方法的时候,会将上面的锁记录进行删除,然后退出lock1,此时应该将线程的栈帧中的锁记录中的 锁记录地址存储的this对象的markword进行cas替换,这里cas替换就是判断this对象的markword的值是否为自己的【锁记录地址】。此时又出两种情况
cas成功。意味着解锁成功。
cas失败。意味着有另一个线程把this对象的锁记录地址改了,也就是进行了锁膨胀了
重量级锁
在上述轻量级锁加锁和解锁过程中,都采用了cas操作,过程如下:
| 过程 | from |
| 加锁 | 对比obj对象的markword后两个bit是否为01。 |
| 解锁 | 对比obj对象的markword的前30bit是否为自己栈帧【锁记录地址】 |
但是在cas的加锁和解锁过程中可能会遇到失败情况:
| 过程 | 失败原因 | 结果 |
| 加锁 | 有另一个线程提前加了轻量级锁 |
重量级加锁 |
| 解锁 | 有另一个线程已经加了重量级锁 | 重量级解锁 |
因此,接下来详细介绍重量级加锁和重量级解锁。
重量级加锁
当线程A针对this对象加锁之后,另一个线程B也尝试对this对象进行加锁,但是此时this对象的markword为线程A的【锁记录地址】。
因此线程B加锁失败,此时线程B开始向操作系统申请monitor对象。并且进行一下事情:
1、将this对象的markword指向monitor对象的地址,并将最后两bit位置为10
2、将this对象之前的markword记录在monitor中
3、将monitor的owner指向线程A,
4、将自己add到monitor的同步队列中,进入到block状态。
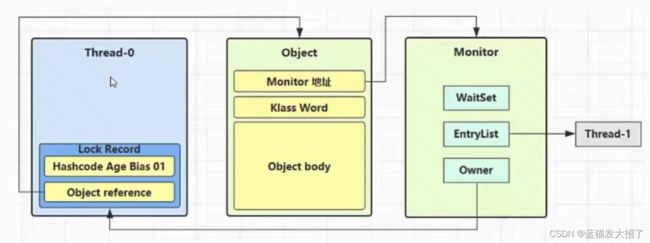
重量级解锁
当线程A执行结束之后,开始进行解锁。此时线程A尝试cas去将自己栈帧的锁记录数据还原到this对象的markword中。但是此时this对象的markword已经不是线程A的【锁记录地址】了,已经被B替换成monitor地址了。因此线程A 解锁失败,开始进行重量级解锁。
线程A根据this对象的markword中的monitor地址找到monitor。然后将monitor的owner设置为null,同时唤醒monitor中的同步队列中的线程。
自旋优化
当一个线程A加了轻量级锁之后,线程B开始加重量级锁,然后去block自己。但是jvm在此进行了优化,也就是说,线程B不会立刻block自己,而是通过自旋的方式不断重试去判断monitor的owner是否为null。这样可以在一定程度上提高性能,不用block。
但是如果线程B在自旋之后,依然判断monitor的owner不是null,那么线程B依然会block自己。但是至于自旋的次数由jvm来自动调整。
偏向锁
当线程进行轻量级加锁的时候,首先会去对this对象的markword进行cas替换。但是,当线程不断的重入当前的锁,则依然会进行cas替换,虽然cas替换肯定失败,但是cas操作也是影响性能呢。
如何进行cas?
因此,在此基础上,进行一步优化,当第一次加锁的时候,利用cas去将this对象的markword替换成thread-id。这个替换利用cas,但是到底是如何对比的呢?也就是说,cas本身是compareAndSet,那么在执行的时候,如何找到一个原始值呢?
当一个对象刚刚被new出来的时候,其对应的hashcode全为0,因此compareAndSet的时候那个原始值当然就是0了。
但是问题点在于我们在调用obj.hashcode()返回的数值不是0啊。这是因为对象的hashcode在第一次调用hashcode()方法的时候才会真正修改markword。一旦对象被调用了hashcode方法,则该对象不能进行偏向锁,因为jvm不知道如何进行cas了。
代码验证:
public void showMarkWord(){
Dog dog = new Dog();
ClassLayout.parseInstance(dog).toPrintableSimple(true);
}返回的结果如下:
![]()
可以看到,刚new来的对象后两bit为01表示无锁,后第三个bit为0表示非偏向。而且前25个bit全为0,即可以看出对象的hashcode为0。
可偏向与真正偏向
在学习的时候,之前经常有一个误区:认为markword中biase标志一旦为1就代表当前对象已经被加了偏向锁。其实不然,真正的理解是biase标志位只是标记当前对象是否可偏向。如果biase==1表示当前对象可以偏向,但不一定此刻一定偏向。如果biase==0,表示当前对象不可偏向。
在上面的示例中,为什么dog对象不可偏向呢。实际上dog对象是可以偏向的,只不过jvm在启动的时候延迟偏向功能,如果在程序中sleep几秒中之后,在此观看,dog的biase标志就会变成1。如果不想让jvm延迟偏向功能,可以在启动的时候添加如下参数:
-XX:+UseBiasedLocking -XX:BiasedLockingStartupDelay=0
加锁之后
通过程序,我们对比一下针对一个对象,我们加锁之前,加锁之后,解锁之后,对象markword的值是什么样的?
代码:
public void showMarkWord(){
Dog dog = new Dog();
//加锁前
ClassLayout.parseInstance(dog).toPrintableSimple(true);
synchronized(dog){
//加锁后
ClassLayout.parseInstance(dog).toPrintableSimple(true);
}
//解锁后
ClassLayout.parseInstance(dog).toPrintableSimple(true);
}结果:

在加锁之前,可以看到后两个bit为01,表示无锁。第三个bit为1,表示对象可以偏向。其他的bit为0。
在加锁之后,可以看到后两个bit为01,表示无锁。第三个bit为1,其他bit为线程id。
在加锁之后,对象的markword没有变化,因此偏向锁的意义就是偏向某个线程,一旦偏向了线程,就基本不会变,除非有一个线程来加锁。
禁用偏向锁
一般在公司生产环境下,用利用jvm参数来禁用偏向锁。这是因为很多时候,一旦程序员在一个地方使用synchronized,那基本上可以断定,这个地方发生并发的概率已经很大了,所以使用偏向锁其实意义不大的。那么在禁用偏向锁之后,obj的对象markword是什么样的呢?如图

由图可知,禁用偏向锁之后,对象的biase标志位为0,表示当前对象不可偏向。那么针对obj进行加锁的时候,可以看到后两个bit为00,表示直接加了轻量级锁,跳过了偏向锁。解锁之后,obj对象又恢复了初始状态。
撤销偏向
所谓的撤销偏向,就是将对象的biase标志设置为0,代表当前对象不可以被偏向。在上一节已经提到,当调用obj.hashcode()的时候,当前对象的biase标记被标记为0。除此之外,当发生锁竞争的时候,也会出现【撤销偏向】。
针对上面的代码,分别用两个线程串行执行,也就是线程A先加锁、解锁,然后线程B在加锁、解锁。观察dog对象的的markword。

由图可以看出来,当线程A加锁之前,对象为01无锁且可偏向,之后进行加锁,对象为01无锁且可偏向,markword替换成线程id,当线程A释放之后,对象的markword没有变化,保持对线程A的偏向。
之后线程B开始加锁,当B发现对象已经偏向了某个线程,则将进行00轻量级锁,对象的markword变成线程B的栈帧【锁记录地址】,当B释放锁之后,可以发现对象为01无锁且不可偏向。
批量重偏向
当多个线程对同一个对象串行访问的时候,会导致对象的偏向标志为0,撤销当前对象的偏向。但是如果在代码中有很多加锁对象,并且这些对象在某个代码环节会全都偏向另一个线程。那么jvm就会做一个优化,将这些对象批量偏向另一个线程。例如:
1、首先创建100个对象。
2、线程A开始对每个对象进行加锁。此时这100个对象都会偏向于线程A。
3、线程A释放锁
4、之后,线程B开始对每个对象进行加锁。按照上面的分析,这个100个对象将会进行轻量级锁,然后撤销偏向。
5、但是实际运行发现前20个对象确实撤销了偏向,但是从第21个开始,每个对象偏向的线程ID变成了线程B,也就是说,剩下的80个对象都批量的偏向于线程B了。
锁消除
锁消除是Java HotSpot虚拟机提供的一种锁优化技术。通过JIT编译器的逃逸分析,判断出一些代码块中的锁操作是不必要的,然后在编译这些代码块时,就把这些不必要的锁操作去掉。
例如,在程序代码中,虽然我们使用了synchronized关键字来对obj进行加锁。但是jvm也会判断当前加锁对象是否为多线程共享的。如果synchronized加锁的对象为一个局部变量,那么jvm会将进行锁消除。