linux -- 内存管理 -- 页面分配器
linux内存管理
为什么要了解linux内存管理
分配并使用内存,是内核程序与驱动程序中非常重要的一环。内存分配函数都依赖于内核中一个非常复杂而重要的组件 - 内存管理。 linux驱动程序不可避免要与内核中的内存管理模块打交道。
linux内存管理可以总体上分为两大块:一是对物理内存的管理,二是对虚拟内存的管理。
物理内存管理
对物理内存的定义,引入了三个概念:内存节点node,内存区域zone,内存页page
对于物理内存的管理,总体上可以分为两层:
- 最底层的页面级内存管理
- 页面级管理之上,有slab内存管理
内存节点 node
为了将UMA系统和NUMA系统,结合起来,所以引入了内存节点这样一个概念。
在计算机体系结构上,有两种物理内存管理模型,被广泛使用:
- UMA(一致内存访问, Uniform Memory Access)模型,该模型的内存空间在物理上,也许是不连续的(比如有空洞的存在),但是所有内存空间对系统中的处理器而言,具有相同的访问特性
- NUMA(非一致内存访问,Non-Uniform Memory Access)模型,该模型总是用在多核处理器系统,系统中每个处理器都有本地内存,处理器与处理器之间通过总线连接起来,以支持其他处理器对比其本地的访问。与UMA模型不同的是,处理器在访问本地内存时速度更加快。
两种模型的区别:

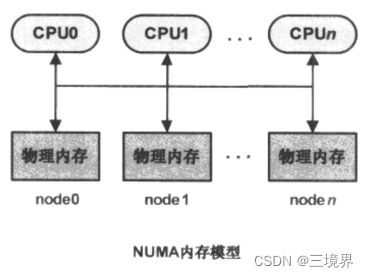
linux源码中,以struct pglist_data数据结构,来表示单个内存节点,NUMA系统,有多个内存节点,所以会有多个pglist_data结构存在。而UMA结构中,只会有一个pglist_data结构。
内存区域zone
内存区域的概念,其范围要小于内存节点的概念。系统中各个模块,对物理内存的属性有不同的要求,因此linux又将每个内存节点所管理的物理内存,划分为不同的内存区域。
linux源码中,以strcut zone数据结构表示一个内存区域,内存区域的类型用枚举类型 zone_type表示:
ZONE_DMA:
当有些设备不能使用所有的ZONE_NORMAL区域中的内存作为内存空间的DMA访问时,就可以使用ZONE_DMA所表示的内存区域,于是我们把这部分空间划分出来专门用与DMA访问的内存空间。这部分区域的空间访问是处理器体系结构相关的(比如32位的x86体系结构下DMA只能访问16MB以下的物理内存空间)
ZONE_NORMAL:
常规内存访问区域,如果DMA可以使用这个区域作为内存访问,也可以使用这个区域。
ZONE_HIGHMEM:
高端内存区域,这个区域无法从内核虚拟地址空间直接作线性映射,所以为访问该区域,必须经内核作特殊的页映射。
i386体系上,内核空间1GB,除去其他开销,能对物理地址进行线性映射的空间大约只有896MB,高于896MB以上的物理地址空间就叫ZONE_HIGHMEM区域。
enum zone_type {
/*
* ZONE_DMA and ZONE_DMA32 are used when there are peripherals not able
* to DMA to all of the addressable memory (ZONE_NORMAL).
* On architectures where this area covers the whole 32 bit address
* space ZONE_DMA32 is used. ZONE_DMA is left for the ones with smaller
* DMA addressing constraints. This distinction is important as a 32bit
* DMA mask is assumed when ZONE_DMA32 is defined. Some 64-bit
* platforms may need both zones as they support peripherals with
* different DMA addressing limitations.
*/
#ifdef CONFIG_ZONE_DMA
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
ZONE_DMA32,
#endif
/*
* Normal addressable memory is in ZONE_NORMAL. DMA operations can be
* performed on pages in ZONE_NORMAL if the DMA devices support
* transfers to all addressable memory.
*/
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
/*
* A memory area that is only addressable by the kernel through
* mapping portions into its own address space. This is for example
* used by i386 to allow the kernel to address the memory beyond
* 900MB. The kernel will set up special mappings (page
* table entries on i386) for each page that the kernel needs to
* access.
*/
ZONE_HIGHMEM,
#endif
/*
* ZONE_MOVABLE is similar to ZONE_NORMAL, except that it contains
* movable pages with few exceptional cases described below. Main use
* cases for ZONE_MOVABLE are to make memory offlining/unplug more
* likely to succeed, and to locally limit unmovable allocations - e.g.,
* to increase the number of THP/huge pages. Notable special cases are:
*
* 1. Pinned pages: (long-term) pinning of movable pages might
* essentially turn such pages unmovable. Therefore, we do not allow
* pinning long-term pages in ZONE_MOVABLE. When pages are pinned and
* faulted, they come from the right zone right away. However, it is
* still possible that address space already has pages in
* ZONE_MOVABLE at the time when pages are pinned (i.e. user has
* touches that memory before pinning). In such case we migrate them
* to a different zone. When migration fails - pinning fails.
* 2. memblock allocations: kernelcore/movablecore setups might create
* situations where ZONE_MOVABLE contains unmovable allocations
* after boot. Memory offlining and allocations fail early.
* 3. Memory holes: kernelcore/movablecore setups might create very rare
* situations where ZONE_MOVABLE contains memory holes after boot,
* for example, if we have sections that are only partially
* populated. Memory offlining and allocations fail early.
* 4. PG_hwpoison pages: while poisoned pages can be skipped during
* memory offlining, such pages cannot be allocated.
* 5. Unmovable PG_offline pages: in paravirtualized environments,
* hotplugged memory blocks might only partially be managed by the
* buddy (e.g., via XEN-balloon, Hyper-V balloon, virtio-mem). The
* parts not manged by the buddy are unmovable PG_offline pages. In
* some cases (virtio-mem), such pages can be skipped during
* memory offlining, however, cannot be moved/allocated. These
* techniques might use alloc_contig_range() to hide previously
* exposed pages from the buddy again (e.g., to implement some sort
* of memory unplug in virtio-mem).
* 6. ZERO_PAGE(0), kernelcore/movablecore setups might create
* situations where ZERO_PAGE(0) which is allocated differently
* on different platforms may end up in a movable zone. ZERO_PAGE(0)
* cannot be migrated.
* 7. Memory-hotplug: when using memmap_on_memory and onlining the
* memory to the MOVABLE zone, the vmemmap pages are also placed in
* such zone. Such pages cannot be really moved around as they are
* self-stored in the range, but they are treated as movable when
* the range they describe is about to be offlined.
*
* In general, no unmovable allocations that degrade memory offlining
* should end up in ZONE_MOVABLE. Allocators (like alloc_contig_range())
* have to expect that migrating pages in ZONE_MOVABLE can fail (even
* if has_unmovable_pages() states that there are no unmovable pages,
* there can be false negatives).
*/
ZONE_MOVABLE,
#ifdef CONFIG_ZONE_DEVICE
ZONE_DEVICE,
#endif
__MAX_NR_ZONES
};
内存页
page,是内存管理中的最小粒度,优势也叫做页帧(page frame,页帧号pfn)。linux会为系统物理内存的每个页都创建一个struct page对象,系统同一用struct page* mem_map存放所有物理页page 对象的指针。
一个内存页的大小,取决于MMU,ARMv8MMU可以支持4KB,16KB,64KB这三种页面粒度。一般来说4KB用的最多。
/*
* Each physical page in the system has a struct page associated with
* it to keep track of whatever it is we are using the page for at the
* moment. Note that we have no way to track which tasks are using
* a page, though if it is a pagecache page, rmap structures can tell us
* who is mapping it.
*/
struct page {
unsigned long flags; /* Atomic flags, some possibly
* updated asynchronously */
atomic_t _count; /* Usage count, see below. */
union {
atomic_t _mapcount; /* Count of ptes mapped in mms,
* to show when page is mapped
* & limit reverse map searches.
*/
struct { /* SLUB */
u16 inuse;
u16 objects;
};
};
union {
struct {
unsigned long private; /* Mapping-private opaque data:
* usually used for buffer_heads
* if PagePrivate set; used for
* swp_entry_t if PageSwapCache;
* indicates order in the buddy
* system if PG_buddy is set.
*/
struct address_space *mapping; /* If low bit clear, points to
* inode address_space, or NULL.
* If page mapped as anonymous
* memory, low bit is set, and
* it points to anon_vma object:
* see PAGE_MAPPING_ANON below.
*/
};
#if USE_SPLIT_PTLOCKS
spinlock_t ptl;
#endif
struct kmem_cache *slab; /* SLUB: Pointer to slab */
struct page *first_page; /* Compound tail pages */
};
union {
pgoff_t index; /* Our offset within mapping. */
void *freelist; /* SLUB: freelist req. slab lock */
};
struct list_head lru; /* Pageout list, eg. active_list
* protected by zone->lru_lock !
*/
/*
* On machines where all RAM is mapped into kernel address space,
* we can simply calculate the virtual address. On machines with
* highmem some memory is mapped into kernel virtual memory
* dynamically, so we need a place to store that address.
* Note that this field could be 16 bits on x86 ... ;)
*
* Architectures with slow multiplication can define
* WANT_PAGE_VIRTUAL in asm/page.h
*/
#if defined(WANT_PAGE_VIRTUAL)
void *virtual; /* Kernel virtual address (NULL if
not kmapped, ie. highmem) */
#endif /* WANT_PAGE_VIRTUAL */
#ifdef CONFIG_WANT_PAGE_DEBUG_FLAGS
unsigned long debug_flags; /* Use atomic bitops on this */
#endif
#ifdef CONFIG_KMEMCHECK
/*
* kmemcheck wants to track the status of each byte in a page; this
* is a pointer to such a status block. NULL if not tracked.
*/
void *shadow;
#endif
};
页面分配器(page allocator)
物理内存分配。linux系统的物理内存分配是建立在伙伴系统的基础之上的。系统初始化期间,伙伴系统负责对物理内存进行整理,跟踪哪些物理内存页面已经被占用,哪些是空闲的。
其他组件,通过访问伙伴系统,可以获取单独的,或者连续的多个物理页面。 驱动程序如果需要使用比较大的地址空间,可以利用这一层面的页面分配器提供的接口函数。这些函数,或者是宏,只能分配2的整数次幂个连续的物理页
下面给出mem_map – 物理内存页面 – 系统虚拟地址空间 之间的关系
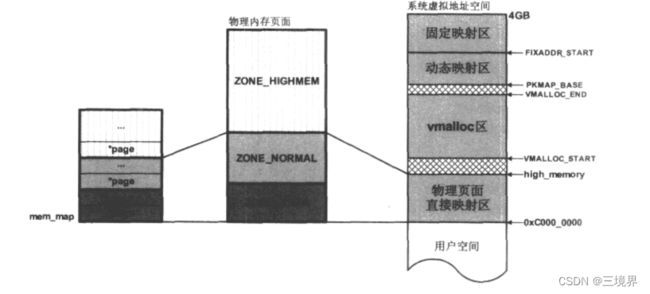
物理内存页面,被分为三个区域:ZONE_HIGHMEM, ZONE_NORMAL, ZONE_DMA。mem_map集合中,每个struct page
对象都与物理页面之间一一对应,所以mem_map也会被分为三个区域。(图中颜色相同的,对应同一个区)
在linux内核的初始化阶段,虚拟地址空间中 物理页面直接映射区域 会被映射到 ZONE_NORMAL和ZONE_DMA中。进内核后,可以直接通过页面分配器分配 物理页面直接映射这块区域的内存,因为这块区域对应的页表项已经建立好了。他们的内核虚拟地址和物理地址之间只是有个一差值(PAGE_OFFSET,也就是图中的0xC000_0000)。
如果页面分配器分配到的页面,落在ZONE_HIGHMEM中,此时内核是暂时没有对该页面进行映射的,因此,页面分配器的使用者,需要作一些前置操作:在内核虚拟地址空间的动态映射区,或者固定映射区,分配一个虚拟地址,然后建立映射,到这块区域的物理页面上。(内核已经提供了实现这些步骤的接口函数)
页面分配器所提供的接口函数,对于UMA和NUMA系统都是一样的。
核心成员:
- alloc_pages
- __get_free_pages
这两个函数最后都是会调用到alloc_pages_node,二者背后实现原理都是一样的
区别是__get_free_pages无法在高端内存区分配页面。
这两个函数有一些变体,这些变体只是调整了一些参数,然后换了个马甲。
gfp_mask
gfp_mask是这些页面分配函数的一个重要参数,决定了他们的分配行为,可以告诉内核应该到哪一个zone中分配物理内存页面。
/*
* In case of changes, please don't forget to update
* include/trace/events/mmflags.h and tools/perf/builtin-kmem.c
*/
/* Plain integer GFP bitmasks. Do not use this directly. */
#define ___GFP_DMA 0x01u
#define ___GFP_HIGHMEM 0x02u
#define ___GFP_DMA32 0x04u
#define ___GFP_MOVABLE 0x08u
#define ___GFP_RECLAIMABLE 0x10u
#define ___GFP_HIGH 0x20u
#define ___GFP_IO 0x40u
#define ___GFP_FS 0x80u
#define ___GFP_ZERO 0x100u
/* 0x200u unused */
#define ___GFP_DIRECT_RECLAIM 0x400u
#define ___GFP_KSWAPD_RECLAIM 0x800u
#define ___GFP_WRITE 0x1000u
#define ___GFP_NOWARN 0x2000u
#define ___GFP_RETRY_MAYFAIL 0x4000u
#define ___GFP_NOFAIL 0x8000u
#define ___GFP_NORETRY 0x10000u
#define ___GFP_MEMALLOC 0x20000u
#define ___GFP_COMP 0x40000u
#define ___GFP_NOMEMALLOC 0x80000u
#define ___GFP_HARDWALL 0x100000u
#define ___GFP_THISNODE 0x200000u
#define ___GFP_ACCOUNT 0x400000u
#define ___GFP_ZEROTAGS 0x800000u
#ifdef CONFIG_KASAN_HW_TAGS
#define ___GFP_SKIP_ZERO 0x1000000u
#define ___GFP_SKIP_KASAN 0x2000000u
#else
#define ___GFP_SKIP_ZERO 0
#define ___GFP_SKIP_KASAN 0
#endif
#ifdef CONFIG_LOCKDEP
#define ___GFP_NOLOCKDEP 0x4000000u
#else
#define ___GFP_NOLOCKDEP 0
#endif
/* If the above are modified, __GFP_BITS_SHIFT may need updating */
带有__下划线的宏留给内存管理部件内部使用,内核也利用这些内部宏定义了一些给其他模块使用的宏:
#define GFP_ATOMIC (__GFP_HIGH|__GFP_KSWAPD_RECLAIM)
#define GFP_KERNEL (__GFP_RECLAIM | __GFP_IO | __GFP_FS)
#define GFP_KERNEL_ACCOUNT (GFP_KERNEL | __GFP_ACCOUNT)
#define GFP_NOWAIT (__GFP_KSWAPD_RECLAIM)
#define GFP_NOIO (__GFP_RECLAIM)
#define GFP_NOFS (__GFP_RECLAIM | __GFP_IO)
#define GFP_USER (__GFP_RECLAIM | __GFP_IO | __GFP_FS | __GFP_HARDWALL)
#define GFP_DMA __GFP_DMA
#define GFP_DMA32 __GFP_DMA32
#define GFP_HIGHUSER (GFP_USER | __GFP_HIGHMEM)
#define GFP_HIGHUSER_MOVABLE (GFP_HIGHUSER | __GFP_MOVABLE | __GFP_SKIP_KASAN)
#define GFP_TRANSHUGE_LIGHT ((GFP_HIGHUSER_MOVABLE | __GFP_COMP | \
__GFP_NOMEMALLOC | __GFP_NOWARN) & ~__GFP_RECLAIM)
#define GFP_TRANSHUGE (GFP_TRANSHUGE_LIGHT | __GFP_DIRECT_RECLAIM)
最常用的是GFP_KERNEL与GFP_ATOMIC,如果不指定__GFP_HIGHMEM或者__GFP_DMA,默认就是__GFP_NORMAL,优先在ZONE_KERNEL里分配,其次是ZONE_DMA域。
GFP_DMA限制了页面分配器只能在ZONE_DMA中分配空闲的物理页面,用于分配DMA缓冲区的内存。
alloc_pages
/*
* Allocate pages, preferring the node given as nid. When nid == NUMA_NO_NODE,
* prefer the current CPU's closest node. Otherwise node must be valid and
* online.
*/
static inline struct page *alloc_pages_node(int nid, gfp_t gfp_mask,
unsigned int order)
{
if (nid == NUMA_NO_NODE)
nid = numa_mem_id();
return __alloc_pages_node(nid, gfp_mask, order);
}
static inline struct page *alloc_pages(gfp_t gfp_mask, unsigned int order)
{
return alloc_pages_node(numa_node_id(), gfp_mask, order);
}
负责分配2的order次方个连续的物理页面并返回其实页的struct page实例。传入gfp_mask如果没有指明__GFP_HIGHMEM,那么分配的物理页必然来自ZONE_NORMAL或者ZONE_DMA,这两个区域在内核初始化阶段就建立了映射关系。
内核模块可以使用page_address来获得对应页面的内核虚拟地址KVA。
ZONE_NORMAL和ZONE_DMA的PA和KVA之间是简单的线性映射关系,有一个PAGE_OFFSET差值:
page_address宏的实现原理:
unsigned long pfn = (unsigned long)(page - mem_map); //页帧
unsigned long pg_pa = pfn << PAGE_SHIFT; //获得页面所在的物理地址
return (void* )__va(pg_pa); //KVA = PAGE_OFFSET + pg_pa
如果gfp_mask = __GFP_HIGHMEM,那么页分配器将有限在ZONE_HIGHMEM域中分配物理页,但也不排除因为ZONE_HIGHMEM没有足够的空闲页导致页面来自ZONE_NORMAL和ZONE_DMA。
新分配的来自高端物理区域的页面,由于内核还没在页表建立映射,所以需要:
- 在内核的动态映射区域分配一个KVA
- 操作页表,KVA 映射到该物理页面
步骤2,内核已经实现了这种函数:kmap
kmap/unkmap系统调用是用来映射高端物理内存页到内核地址空间的api函数
arch/arm/mm/highmem.c
void *kmap(struct page *page)
{
might_sleep();
if (!PageHighMem(page)){//如果是低端内存,则直接返内存页对应的直接映射虚拟地址
//printk("low mem page\n");
return page_address(page);//所有的低端内存,在内核初始化时就已经映射好了,并且是不变得,且物理到虚拟相差0xc0000000
}else{
//printk("high mem page\n");
}
return kmap_high(page);//高端内存页
}
/**
* kmap_high - map a highmem page into memory
* @page: &struct page to map
*
* Returns the page's virtual memory address.
*
* We cannot call this from interrupts, as it may block.
*/
void *kmap_high(struct page *page)
{
unsigned long vaddr;
/*
* For highmem pages, we can't trust "virtual" until
* after we have the lock.
*/
lock_kmap();
vaddr = (unsigned long)page_address(page);
if (!vaddr)
vaddr = map_new_virtual(page); //建立MMU的页表项
pkmap_count[PKMAP_NR(vaddr)]++;
BUG_ON(pkmap_count[PKMAP_NR(vaddr)] < 2);
unlock_kmap();
return (void *) vaddr;
}
EXPORT_SYMBOL(kmap_high);
kmap在执行过程中可能会睡眠,不能用于中断上下文中。
涉及页表建立,开销比较大
kunmap函数拆除页表项中对page的映射,同时来自动态映射区的KVA被释放出去,使得KVA可以被用于映射其他的物理页面。
如果不想让kmap睡眠,可以使用kmap_atomic,原子执行,且比kmap快。
alloc_page 是 alloc_pages 在order=0时的简化形式,分配单个页面。
__get_free_pages
/*
* Common helper functions. Never use with __GFP_HIGHMEM because the returned
* address cannot represent highmem pages. Use alloc_pages and then kmap if
* you need to access high mem.
*/
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order)
{
struct page *page;
page = alloc_pages(gfp_mask & ~__GFP_HIGHMEM, order);
if (!page)
return 0;
return (unsigned long) page_address(page);
}
EXPORT_SYMBOL(__get_free_pages);
函数注释里说的很清楚了,绝不要使用__GFP_HIGHMEM,因为返回的地址不会存在与高端内存页面。如果你要访问高端内存,那你就通过alloc_pages然后kmap这种路子吧
即使传入__GFP_HIGHMEM,也会将它mask掉 gfp_mask & ~__GFP_HIGHMEM
返回的是KVA
get_zero_page
分配物理页面,并以0填充。返回的是内核线性地址
__get_dma_pages
从ZONE_DMA区域分配物理页面,返回页面所在的内核线性地址
SLAB分配器
页面分配器分配出的内存粒度比较大,如果需要更细的粒度,比如几十,几百字节的,还得是SLAB分配器。slab是内核最早推出的小内存分配方案,slob和slub分配器则是内核在2.6版本新增的替代品,针对大型系统和嵌入式系统。
查看下节