python 学习之 re库的基本使用(正则匹配)下
目录
一、关于 %s 的使用
二、正则匹配规则
1、字符簇
2、单个字符匹配
3、其他常见正则表达式符号
4、正则表达式常用修饰符(也称为标志)
5、其他
一、关于 %s 的使用
%s 是一种字符串格式化的方式,用于将字符串中的占位符替换为相应的值,替代的变量是通过 % 操作符的右侧提供的。
测试代码:
list = ['zxc', 'asd', 'qwe', 123]
for i in list:
print(i)
print('列表中存在的元素有%s' % i)运行结果:

我们也可以使用多个 %s ,% 右边使用括号将多个变量包裹,变量之间使用逗号分割
测试代码:
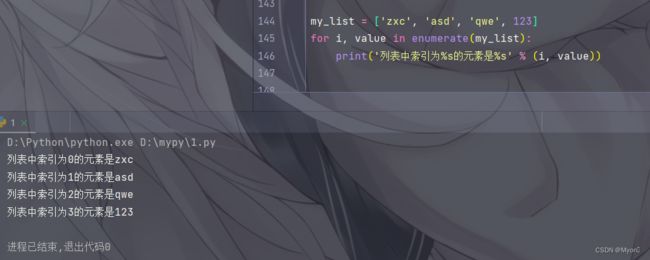
enumerate() 函数用于同时获取列表元素和它们的索引,在字符串中使用两个不同的 %s 分别代表索引和元素的值。
my_list = ['zxc', 'asd', 'qwe', 123]
for i, value in enumerate(my_list):
print('列表中索引为%s的元素是%s' % (i, value))运行结果:
二、正则匹配规则
1、字符簇
把所有的字符放在一个方括号里,但只能表示一个字符。
我们来看看加方括号和不加方括号的区别
测试代码:
import re
ret = re.match('myon', 'myon666')
print(ret.group())
ret2 = re.match('[myon]', 'myon666')
print(ret2.group())运行结果:

常见的有:
[a-z] // 匹配所有的小写字母
[A-Z] // 匹配所有的大写字母
[a-zA-Z] // 匹配所有的字母
[0-9] // 匹配所有的数字
[0-9\.\-] // 匹配所有的数字,句号和减号
[ \f\r\t\n] // 匹配所有的白字符
2、单个字符匹配
\d 表示匹配一个数字字符,等价于 [0-9]
\D 则表示匹配一个非数字字符,等价于 [^0-9]
\s 匹配空白(空格、tab)
\S 匹配非空白
\w 匹配非特殊字符(a-z、A-Z、0-9、_、汉字)
\W 匹配特殊字符(非字母、非数字、非下划线、非汉字). 匹配任意1个字符(除 \n )
测试代码:
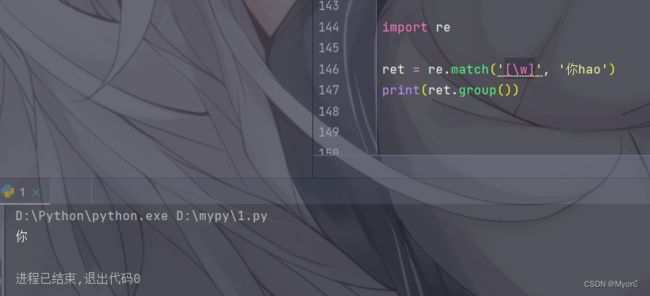
import re
ret = re.match('[\w]', '你hao')
print(ret.group())
运行结果:
上面只是以 match 函数做演示,你们也可以用 search、findall 等进行测试和熟悉。
3、其他常见正则表达式符号
^ 匹配输入字行首
$ 匹配输入行尾
* 匹配前面的子表达式任意次
+ 匹配前面的子表达式一次或多次(大于等于1次)
? 匹配前面的子表达式零次或一次
x|y 匹配x或y
[xyz] 字符集合,匹配所包含的任意一个字符
[^xyz] 负字符集合,匹配未包含的任意字符
测试代码:
import re
ret = re.match('[xyz]', 'z12zx5dy')
print(ret.group())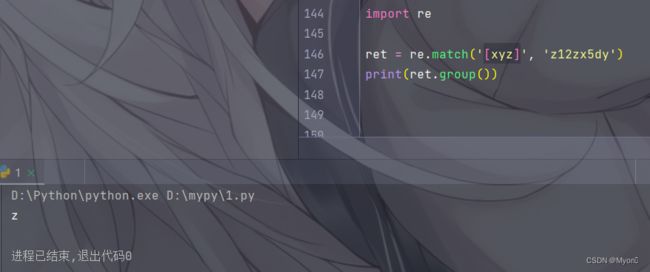
4、正则表达式常用修饰符(也称为标志)
re.I 将匹配设置为不区分大小写
re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
re.M multi line - 多行匹配 使边界字符 ^ 和 $ 匹配每一行的开头和结尾
re.S 特殊字符圆点 . 并且包括换行符在内的任意字符
re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
re.X 为了增加可读性,忽略空格和 # 后面的注释
用法示例:
re.I (re.IGNORECASE): 将匹配设置为不区分大小写。
import re
pattern = re.compile(r'apple', re.I)
result = pattern.match('APPLE')
print(result.group()) # 输出 'APPLE're.L (re.LOCALE): 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境(locale)。
这个修饰符通常在非英语语言环境中使用。
import re
pattern = re.compile(r'\w+', re.L)
result = pattern.match('ééé')
print(result.group()) # 输出 'ééé're.M (re.MULTILINE): 多行匹配,使边界字符 ^ 和 $ 匹配每一行的开头和结尾。
import re
pattern = re.compile(r'^start', re.M)
result = pattern.findall('start\nstart again')
print(result) # 输出 ['start', 'start']re.S (re.DOTALL): 特殊字符圆点 . 并且包括换行符在内的任意字符。
import re
pattern = re.compile(r'.*pattern.*', re.S)
result = pattern.match('This is\na pattern\nexample')
print(result.group()) # 输出 'This is\na pattern\nexample're.U (re.UNICODE): 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库。
import re
pattern = re.compile(r'\w+', re.U)
result = pattern.match('你好')
print(result.group()) # 输出 '你好're.X (re.VERBOSE): 为了增加可读性,忽略空格和 # 后面的注释。
import re
pattern = re.compile(r'''
\d+ # 匹配一或多个数字
\s* # 匹配零或多个空白字符
[a-z]+ # 匹配一或多个小写字母
''', re.X)
result = pattern.match('123 abc')
print(result.group()) # 输出 '123 abc'5、其他
开头的 ^ 和结尾的 $ 让PHP从字符串开头检查到结尾,假使没有 $,仍会匹配到末尾。
尽管 [a-z] 代表 26 个字母的范围,但在这里它只能与第一个字符是小写字母的字符串匹配。
前面曾经提到^表示字符串的开头,但它还有另外一个含义,当在一组方括号里使用 ^ 时,它表示"非"或"排除"的意思,常常用来剔除某个字符。