taskflow 源码阅读笔记-1
之前写了一篇介绍Taskflow的短文:传送门
Taskflow做那种有前后依赖关系的任务管理还是不错的,而且他的源码里运用了大量C++17的写法,觉得还是非常值得学习的,因此决定看一下他的源码,这里顺便写了一篇代码学习笔记。
概述
代码链接:
https://github.com/taskflow/taskflow
本文是commitid: b91df2c365c20fa4cb43951192f6939fbe876abf 版本的源码学习记录,其他版本可能会有不同
简介
简介可以参考代码仓库的README
简单来说它是一个实现DAG(有向无环图)的多线程任务管理库, 下图截取自代码仓库的README: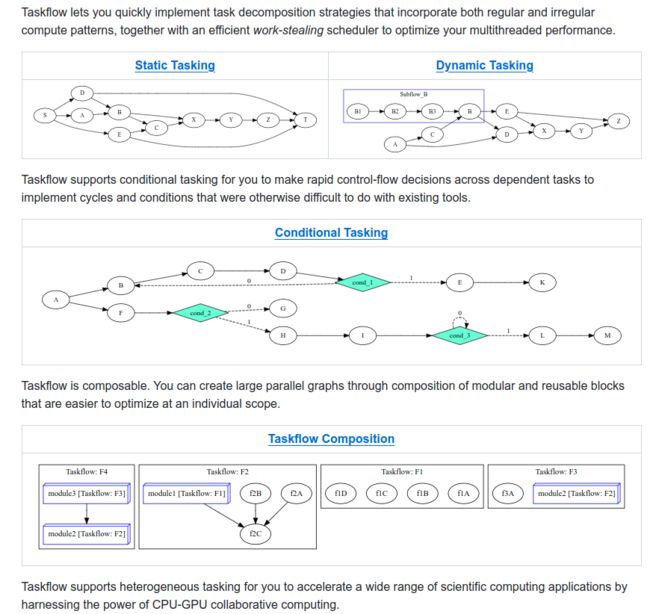
使用方法
使用方法见README,这里需要指出的是,作者分享了他的compile explorer https://godbolt.org/z/j8hx3xnnx, 我们可以在上面修改代码来看效果
这个是个纯头文件的库,只需要引用其头文件就行了
#include
但是这个头文件怎么来的呢?
其实这个和Eigen的使用方法一样,在源码库中,有一个taskflow文件夹,里面全部都是.hpp文件,在最外层有一个taskflow.hpp文件,它是总的入口文件,我们只要include这个文件就行。
具体来说,如果我们想在我们自己的项目中使用它,
一种方法是直接将taskflow文件夹中的所有文件拷贝到我们自己的代码仓库,
另一种更好的方式就是和Eigen一样,把他做成一个deb包安装在机器上,这样我们就可以在多个项目中使用它了
不管怎么安装,最后在我们需要使用它的地方#include
下面摘抄自代码仓库中的README:
#include 代码学习
核心代码量
主要功能代码约1.5万行,在taskflow文件夹下:
代码实现
从上面的使用示例来看,它给我们展示了几个接口:
- tf::Executor executor;
- tf::Taskflow taskflow;
- auto [A, B, C, D] = taskflow.emplace(… …);
- A.precede(B, C); // A runs before B and C
- D.succeed(B, C); // D runs after B and C
- executor.run(taskflow).wait();
下面我们就从这几个接口入手来看其代码实现
tf::Taskflow
首先来看命名空间tf
tf是本代码仓库的根命名空间,所有的代码都是在这个命名空间下的
然后我们来看tf::Taskflow
代码位于 taskflow/taskflow/core/taskflow.hpp
定义tf::Taskflow taskflow时,
首先会构造其成员变量:
其中实际会执行构造的只有 Graph _graph;
我们看下_graph的构造过程:
Gragh类只有一个成员变量 std::vector
再来看Graph类的无参构造函数,发现它直接是用的default构造函数,因此它也没做什么事情。
然后会调用构造函数:
因为没有传入参数,所以调用的是无参构造函数:
// Constructor
inline Taskflow::Taskflow() : FlowBuilder{_graph} {
}
Taskflow的构造函数啥都没有干,我们再看它的基类FlowBuilder的构造函数
FlowBuilder构造时需要传入_graph变量,这个变量是Taskflow类的成员变量,后面再看它是怎么构造的
// Constructor
inline FlowBuilder::FlowBuilder(Graph& graph) :
_graph {graph} {
}
FlowBuilder的构造函数也啥都没有干,只是把_graph赋值给它自己的成员变量,注意Graph类只有移动构造函数,也就是说,此时Taskflow类中的_graph已经报废了
因为FlowBuilder类中只有_graph这一个成员变量,因此在构造阶段它没啥别的事情了
taskflow.emplace(…)
Taskflow类里没有emplace(…)这个方法,它是Taskflow的基类FlowBuilder的成员函数
emplace(…)方法有5个实现版本, 其中一个的定义如下:
template <typename C, std::enable_if_t<is_static_task_v<C>, void>*>
Task FlowBuilder::emplace(C&& c) {
return Task(_graph._emplace_back("", 0, nullptr, nullptr, 0,
std::in_place_type_t<Node::Static>{}, std::forward<C>(c)
));
}
然后,作者在is_static_task_v的地方实现了不同版本的萃取方法:
- is_static_task_v
- is_dynamic_task_v
- is_condition_task_v
- is_multi_condition_task_v
- sizeof…(C )>1
示例代码中传入的是多个lamda表达式, 会匹配到 sizeof…©>1 这个版本,代码如下:
template <typename... C, std::enable_if_t<(sizeof...(C)>1), void>*>
auto FlowBuilder::emplace(C&&... cs) {
return std::make_tuple(emplace(std::forward<C>(cs))...);
}
然后再依次调用 is_static_task_v 的版本,代码如上所示:
做的事情是:
- 用传入的lamda表达式构造了一个Node,
- 然后把这个Node放到_graph中,
- 最后用_graph._emplace_back返回的Node*来构造一个Task实例返回
A.precede(B, C)
从上面的分析可以知道, A/B/C都是Task类的实例,
先来看下Task类的构造:
inline Task::Task(Node* node) : _node {node} {
}
Task类中没有其他成员变量,只有一个Node* __node, 因此Task中只维护一个Node, Task类是Node类的观察者。
precede() 是Task类的方法, 它的实现如下:
template <typename... Ts>
Task& Task::precede(Ts&&... tasks) {
(_node->_precede(tasks._node), ...);
//_precede(std::forward(tasks)...);
return *this;
}
实际上是执行的Node类的precede
再来看Node类precede函数
inline void Node::_precede(Node* v) {
_successors.push_back(v);
v->_dependents.push_back(this);
}
这里涉及到两个变量:
SmallVector<Node*> _successors; // 下一个要执行的节点
SmallVector<Node*> _dependents; // 上一个执行的节点
这样用这两个向量把依赖关系保存起来
D.succeed(B, C)
和上一个函数类似,只是依赖关系改了一下:
template <typename... Ts>
Task& Task::succeed(Ts&&... tasks) {
(tasks._node->_precede(_node), ...);
//_succeed(std::forward(tasks)...);
return *this;
}
tf::Executor
Executor类的构造过程如下:
// 声明
explicit Executor(size_t N = std::thread::hardware_concurrency());
// 定义
inline Executor::Executor(size_t N) :
_MAX_STEALS {((N+1) << 1)},
_threads {N},
_workers {N},
_notifier {N} {
if(N == 0) {
TF_THROW("no cpu workers to execute taskflows");
}
_spawn(N);
// instantite the default observer if requested
if(has_env(TF_ENABLE_PROFILER)) {
TFProfManager::get()._manage(make_observer<TFProfObserver>());
}
}
我们用的示例是无参的,因此N默认为std::thread::hardware_concurrency(), 即当前系统支持的并发线程数的估计值
然后设置:
- _MAX_STEALS 为 (N+1)*2
- 实例化N个std::thread
- 实例化N个worker
- 实例化参数为N的notifier
然后调用_spawn()函数启动任务
executor.run(taskflow).wait()
inline tf::Future<void> Executor::run(Taskflow& f) {
return run_n(f, 1, [](){});
}
template <typename C>
tf::Future<void> Executor::run_n(Taskflow& f, size_t repeat, C&& c) {
return run_until(
f, [repeat]() mutable { return repeat-- == 0; }, std::forward<C>(c)
);
}
template <typename P, typename C>
tf::Future<void> Executor::run_until(Taskflow&& f, P&& pred, C&& c) {
std::list<Taskflow>::iterator itr;
{
std::scoped_lock<std::mutex> lock(_taskflows_mutex);
itr = _taskflows.emplace(_taskflows.end(), std::move(f));
itr->_satellite = itr;
}
return run_until(*itr, std::forward<P>(pred), std::forward<C>(c));
}
TODO: 这里还有很多没看的,先写到这里,有空继续补充。。。
用到C++功能
这个代码库使用了大量的modern C++的特性,下面列举一些:
- std::forward
- std::future
- std::function
- lamda表达式
- 模版元编程
- std::atomic
- std::decay_t
- std::is_void_v
- std::monostate
- std::tuple
- std::make_tuple
- std::get
- std::array
- std::index_sequence
- std::memory_order_relaxed
- std::is_invocable_v
- std::add_lvalue_reference_t
- std::find_if
- std::find_if_not
- std::distance
- std::next
- std::min_element
- std::advance
- std::lock_guard
- std::mutex
- std::invoke
- std::enable_if_t
- std::memcmp