JavaSE——数组
数组基础知识
-
- 数组的由来
- 数组的定义
- 第一种定义格式(数组的动态初始化)
-
- 第一种定义格式的内存机制
- 第二种定义格式(数组的静态初始化)
-
- 第二种定义格式的内存机制
- 数组的取值和赋值
-
- 取值
- 赋值
- 获取数组的长度
- 数组的遍历
- [案例]数组求和
- 数组的最值
-
- 思想
- 求数组中的最大值
- 求数组中的最小值
- 数组的空指针异常
- 数组的索引越界异常
- 补充
-
- 数组名与数组的地址值
- 不同类型数组的初始化默认值
- 数组的动态初始化与静态初始化
- 练习题
数组的由来
变量用来存取数据,每一个数据都需要单独声明一个变量来存储。现在有了这样一个需求:统计某公司员工的工资情况,例如计算平均工资、最高工资等。假设该公司有50名员工。要想存储50个人的月薪,就要申明50个独立的变量,每个变量单独存储一个人的薪资。当人数越来越多的时候,我们声明变量的语句将越来越多,重复性劳动,比较繁琐。如下所示。
在Java中,数组可以一次性声明多个变量,供我们多次使用。 我们可以利用数组来解决这样一个痛点。
数组是指一组数据的集合,数组中的每个数据被称作元素。数组可以存放任意类型的元素,但是同一个数组里存放的元素的类型必须一致。数组可以分为一维数组和多维数组。
数组的定义
第一种定义格式(数组的动态初始化)
数据类型 [ ] 数组名 = new 数据类型 [数组长度值];
int [] arr1 = new int [3];//声明了一个名称为arr1的整型数组,这个数组里面一次性声明了3个整型变量来存储数据。
String [] arr2 = new int [3];//声明了一个名称为arr2的字符串类型数组,这个数组里面一次性声明了3个字符串变量来存储数据。
第一种定义格式的内存机制
要搞清楚数组底层的存储机制需要知道这两个常识:
①内存中的每一个内存单元都会有一个唯一的地址值,一般用十六进制来表示内存地址值。十六进制:(以0x开头,通过0-9,A-F这些数字和字母来组成)。例如:0x72、0x4C…
②JVM的内存划分
我们都知道所有的Java程序最终都是运行在Java虚拟机(JVM)里面的。JVM里面的内存划分成了很多块。这里涉及到的主要是栈区和堆区。
栈:主要用来存放方法,方法中的局部变量会随着方法的入栈而入栈。(局部变量:定义在方法中的变量)
堆:主要用来存放对象(new出来的东西)
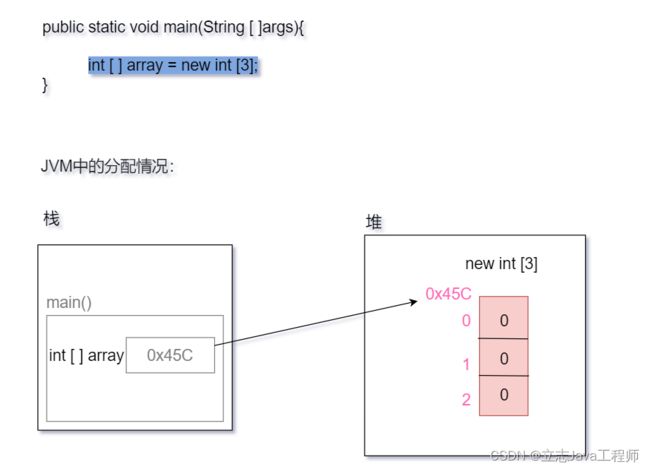
上图,从代码上来看,main()方法中声明了一个整型数组array,这个整型数组里面一次性声明了3个变量来存储数据。
从内存的角度来说:main()方法中声明了一个int[ ]类型的变量array,创建了一个对象,即长为3的整型数组,并将数组的地址值(0x45C)赋给了变量array。
main()方法进入栈中,main()方法中的局部变量int[ ] array也随着main()方法的入栈而入栈,变量int[ ] array会占据一块儿内存单元,它没有被分配初始值。内存中的状态如下图所示:
new int [3],意为:创建了一个对象,即:长度为3的整型数组。对象都是存储在堆中的。new int [3]在堆中会产生如下图所示的效果。
new int [ 3 ]这句话会在堆中开辟出3个连续的内存单元,并给这3个内存单元分别设置了索引值(0,1,2)同时因为是一个整型的数组,所以将这三块空间分别赋予了一个初始值0。
int [ ] array = new int [3];这句话则是将堆中创建的整型数组的地址值赋值给变量array。从而使得在程序运行期间可以使用变量array来引用数组。如下图所示:
注:栈和堆
当一个方法执行时,每个方法都会建立自己的内存栈,在这个方法内定义的变量将会逐个放入这个栈内存里,当方法的执行结束后,这个方法的内存栈也会被销毁。在程序中创建一个对象时,这个对象将会被保存到运行时数据区中,以便反复利用(因为对象的创建成本通常比较大),这个运行时数据区就是堆内存。堆内存中的对象不会随方法的结束而销毁,即使方法运行结束后,这个对象还可能被另一个引用变量所引用,则这个对象依然不会被销毁。只有当一个对象没有任何引用变量引用它时,系统的垃圾回收器才会在合适的时候回收它.


第二种定义格式(数组的静态初始化)
数据类型 [ ] 数组名 = {元素1,元素2,元素3…}
int [] arr3 = {12,13,15,18}//声明了一个名称为arr3的整型数组,这个数组里面一次性声明了4个整型变量,并且在定义数组的同时就为数组中的每一个元素进行了赋值
String [] arr4 = {"张三","李四","王五"}//声明了一个名称为arr4的字符串型数组,这个数组里面一次性声明了3个字符串类型的变量,并且在定义数组的同时就为数组中的每一个元素进行了赋值.
第二种定义格式的内存机制
在了解了第一种定义格式的内存机制的基础上,第二种定义格式的内存机制就很好理解了.
同第一种定义格式的内存机制一样,第二种定义格式的内存机制,只是在堆中多了一个覆盖的操作.

数组的取值和赋值
取值
格式:
数组名 [ 索引值 ] ;
例如:
数组名[0];//取出索引值为0的元素
数组名[1];//取出索引值为1的元素
数组名[2];//取出索引值为2的元素public class ArrayDemo01{ public static void main(String [] args){ //数组的定义 int [] array = new int [3]; //分别取出数组中索引值为0,1,2的元素,并在控制台中打印出来。 System.out.println(array[0]);//打印结果 0 System.out.println(array[1]);//打印结果 0 System.out.println(array[2]);//打印结果 0 } }
内存机制:
先由array指引找到堆中的整个数组空间,然后根据索引值去找对应索引值的空间,然后取出该元素。因为这是一个整型数组,所以数组中的各个元素的默认初始值都是0.

赋值
格式:
数组名 [ 索引值] = 值;
例如:
数组名[0] = 1;//将索引值为0的元素赋值为1
数组名[1] = 2;//将索引值为1的元素赋值为2
数组名[2] = 3;//将索引值为2的元素赋值为3public class ArrayDemo01{ public static void main(String [] args){ //数组的定义 int [] array = new int [3]; //分别将数组中索引值为0,1,2的元素,赋值为1,2,3 array[0]=1; array[1]=2; array[2]=3; System.out.println(array[0]);//打印结果 1 System.out.println(array[1]);//打印结果 2 System.out.println(array[2]);//打印结果 3 } }
内存机制:
先由array指引找到堆中的整个数组空间,然后根据索引值去找对应索引值的空间,然后将其元素值改变。

获取数组的长度
在Java中,为了方便获取数组的长度,提供了一个length属性,在程序中可以通过
数组名.length 的方式获取数组的长度,即元素的个数.public class ArrayDemo01{ public static void main(String [] args){ int [] array = new int [3]; //获取数组的长度 并将数组的长度值打印出来 System.out.println(array.length);//打印结果 3 } }
数组的遍历
数组的遍历:将数组中的元素一 一 取出
public class ArrayDemo01{ public static void main(String [] args){ double [] arr = {10.1,12.1,13.4,15.6}; //将arr1数组里的元素一一取出 for(int i=0;i<arr.length;i++){ System.out.println(arr[i]); } } }
打印结果
10.1
12.1
13.4
15.6
[案例]数组求和
public class ArrayDemo01{ public static void main(String [] args){ //对数组中的元素进行求和 double [] arr1 = {10.1,12.1,13.4,15.6}; double sum = 0.0; for(int i=0;i<arr1.length;i++){ sum=sum+arr1[i]; } System.out.println(sum); } }
打印结果 :51.2
数组的最值
思想
定义一个临时变量max用来记住最大值.假设数组中的第一个元素为最大值,并将它赋值给max,接下来遍历数组,在遍历过程中只要遇到比max还要大的元素,就将该元素赋值给max.这样一来,变量max就能够在循环结束时,记住数组中的最大值.
定义一个临时变量min用来记住最小值.假设数组中的第一个元素为最小值,并将它赋值给min,接下来遍历数组,在遍历过程中只要遇到比min还要小的元素,就将该元素赋值给min.这样一来,变量min就能够在循环结束时,记住数组中的最小值.
求数组中的最大值
public class ArrayDemo01{ public static void main(String [] args){ //1、声明一个数组 int [] arr = {100,12,75,103,1}; //2、求出数组arr中的最大值 int max = arr[0];//定义一个临时变量max,用来记住最大值,并假设数组中的第一个元素arr[0]为最大值。 for(int i = 1;i<arr.length;i++){//遍历数组 if(arr[i]>arr[0]){//在遍历过程中只要遇到比max值还大的元素,就将该值赋值给max max = arr[i]; } } System.out.println(max);//打印出最终的最大值 } }
打印结果:
103
求数组中的最小值
public class ArrayDemo01{ public static void main(String [] args){ //1、声明一个数组 int [] arr = {100,12,75,103,1}; //2、求出数组arr中的最小值 int min = arr[0];//定义一个临时变量min,用来记住最小值,并假设数组中的第一个元素arr[0]为最小值。 for(int i = 1;i<arr.length;i++){//遍历数组 if(arr[i]<arr[0]){//在遍历过程中只要遇到比min值还小的元素,就将该值赋值给min min = arr[i]; } } System.out.println(min);//打印出最终的最小值 } }
打印结果:
1
数组的空指针异常
public class ArrayDemo01{ public static void main(String [] args){ int [] array = new int [3];//声明一个数组 array[0]=5;//将数组的0号位元素赋值为5 System.out.println("array[0]="+array[0]);//访问数组的元素 array = null;//将变量arr的值置为null System.out.println("array[0]="+array[0]); } }
运行结果:
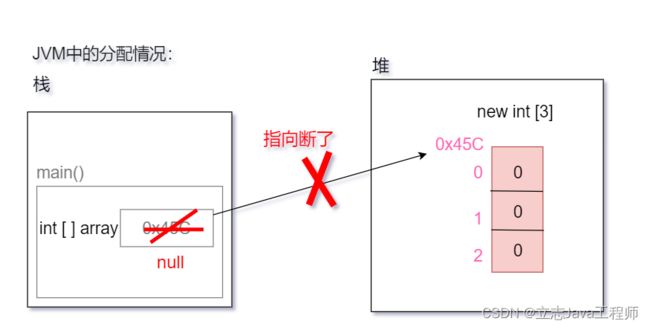
由上面的运行结果可以看出,第4、5行代码都能通过变量arr正常地操作数组,第7行代码将变量array置为null,当第7行代码再次访问数组时就出现了空指针异常(NullPointerException)
在Java中,使用变量引用一个数组时,变量必须指向一个有效的数组对象,如果该变量的值为null,则意味着没有指向任何数组,此时通过该变量访问的元素就会出现空指针异常.
注:
null:空常量
null:只能赋值给引用数据类型(数组、类、接口)
数组的空指针异常,在内存中呈现如下图所示的机制
将变量array的值置为null,则意味着没有指向任何数组,也就是将原来的指向给切断了.于是当再次想要通过array去访问之前的数组时,就会产生空指针异常(找不到)

数组的索引越界异常
每个数组的索引值都有一个边界: 0~length-1 (0到数组的长度-1),在访问数组元素时,索引不能超出这个范围,否则程序会报错.
public class ArrayDemo01{ public static void main(String [] args){ String [] array = {"张三","李四","王五","赵六"};//声明了一个String类型的数组,这个数组的长度为4,索引范围为0~4-1(0-3) //获取数组中的元素 System.out.println(array[0]);//在索引范围内 System.out.println(array[1]);//在索引范围内 System.out.println(array[2]);//在索引范围内 System.out.println(array[3]);//在索引范围内 System.out.println(array[4]);//超出索引范围 } }
运行结果:
该数组的索引值范围为:0-3,第13行代码超出了这个索引范围.于是报出异常:ArrayIndexOutOfBoundsException(数组索引越界异常)
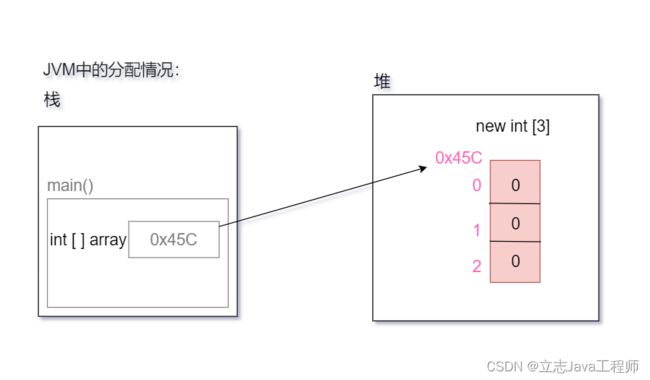
数组索引越界异常产生的内存机制:
改数组的索引值只有0,1,2,除此之外没有了别的,所以一旦超出了这个范围就会发生数组索引越界异常

补充
数组名与数组的地址值
当我们将数组名打印出来时,会呈现如下的效果。
public class ArrayDemo01{ public static void main(String [] args){ //数组的定义 int [] array = new int [3]; System.out.println(array); } }打印结果:
[I@6d1e7682// 相当于打印出了数组的地址值
其中
[代表这是一个一维数组
I代表只是一个int类型的数组
@分隔作用(隔开左右边,为了好看)
6d1e7682代表该数组所在的内存的地址值
数组名的打印结果,也进一步佐证了,定义数组时,在内存中是由栈中的数组名指向了堆中数组的实际位置.
不同类型数组的初始化默认值
| 数据类型 | 默认初始化值 |
|---|---|
| byte、short、int、long | 0 |
| float、double | 0.0 |
| char | 一个空字符,即 ‘\u0000’ |
| boolean | false |
| 引用数据类型 | null,表示变量不引用任何对象 |
数组的动态初始化与静态初始化
在定义数组时,只指定数组的长度,由系统自动为元素赋初值的方式称作动态初始化.例如数组的第一种定义格式.
int[] arr = new int [3];这是一个int类型的数组,数组长度为3,即数组中的元素个数为3个,这3个元素的个数的初始值都为0.
在定义数组的同时就为数组的每一个元素赋值.例如数组的第二种定义格式:
int [] arr = {11,12,13};