Scikit-learn (sklearn)速通 -【莫凡Python学习笔记】
视频教程链接:【莫烦Python】Scikit-learn (sklearn) 优雅地学会机器学习
视频教程代码
scikit-learn官网
莫烦官网学习链接
本人matplotlib、numpy、pandas笔记
1 为什么学习
Scikit learn 也简称 sklearn, 是机器学习领域当中最知名的 python 模块之一.
Sklearn 包含了很多种机器学习的方式:
Classification 分类
Regression 回归
Clustering 非监督分类
Dimensionality reduction 数据降维
Model Selection 模型选择
Preprocessing 数据预处理
我们总能够从这些方法中挑选出一个适合于自己问题的, 然后解决自己的问题
2 安装
- Python(>=2.6 or >=3.3)
- Numpy(>=1.6.1)
- SciPy(>=0.9)
pip install -U scikit-learn
# or conda
conda install scikit-learn
3 如何选择机器学习方法
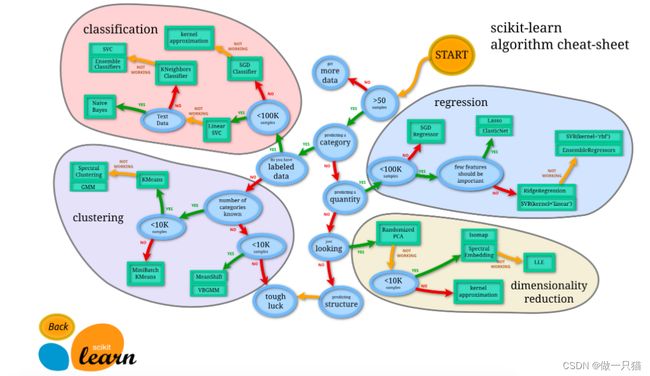
从 START 开始,首先看数据的样本是否 >50,小于则需要收集更多的数据。
由图中可以看到算法有四类,分类,回归,聚类,降维。
其中 分类 和 回归 是监督式学习,即每个数据对应一个 label。
聚类 是非监督式学习,即没有 label。
另外一类是 降维,当数据集有很多很多属性的时候,可以通过 降维 算法把属性归纳起来。例如 20 个属性只变成 2 个,注意,这不是挑出 2 个,而是压缩成为 2 个,它们集合了 20 个属性的所有特征,相当于把重要的信息提取的更好,不重要的信息就不要了。
然后看问题属于哪一类问题,是分类还是回归,还是聚类,就选择相应的算法。 当然还要考虑数据的大小,例如 100K 是一个阈值。
可以发现有些方法是既可以作为分类,也可以作为回归,例如 SGD。
4 通用学习模式
Sklearn 把所有机器学习的模式整合统一起来了,学会了一个模式就可以通吃其他不同类型的学习模式。
注:其数据库十分强大,可用作各种练习(包括Tensorflow等)
例如,分类器,
Sklearn 本身就有很多数据库,可以用来练习。 以 Iris 的数据为例,这种花有四个属性,花瓣的长宽,茎的长宽,根据这些属性把花分为三类。
我们要用 分类器 去把四种类型的花分开。

数据集:Iris plants dataset官网链接
4.1 导入模块
# sklearn.cross_validation 模块已经在 Scikit-learn 0.20 版本中被弃用
# 现使用 sklearn.model_selection 模块中的 train_test_split 函数来进行训练集和测试集的划分
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
4.2 创建数据
加载 iris 的数据,把属性存在 X,类别标签存在 y:
iris = datasets.load_iris()
iris_X = iris.data
iris_y = iris.target
观察一下数据集,X 有四个特征,y 有 0,1,2 三类:
print(iris_X[:2, :])
print(iris_y)
"""
[[ 5.1 3.5 1.4 0.2]
[ 4.9 3. 1.4 0.2]]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
"""
把数据集分为训练集和测试集,其中 test_size=0.3,即测试集占总数据的 30%:
X_train, X_test, y_train, y_test = train_test_split(iris_X, iris_y, test_size=0.3)
可以看到分开后的数据集,顺序也被打乱,这样更有利于学习模型:
print(y_train)
"""
[2 1 0 1 0 0 1 1 1 1 0 0 1 2 1 1 1 0 2 2 1 1 1 1 0 2 2 0 2 2 2 2 2 0 1 2 2
2 2 2 2 0 1 2 2 1 1 1 0 0 1 2 0 1 0 1 0 1 2 2 0 1 2 2 2 1 1 1 1 2 2 2 1 0
1 1 0 0 0 2 0 1 0 0 1 2 0 2 2 0 0 2 2 2 1 2 0 0 2 1 2 0 0 1 2]
"""
4.3 建立模型-训练-预测
什么是KNN(K近邻算法)?
定义模块方式 KNeighborsClassifier(), 用 fit 来训练 training data,这一步就完成了训练的所有步骤, 后面的 knn 就已经是训练好的模型,可以直接用来 predict 测试集的数据, 对比用模型预测的值与真实的值,可以看到大概模拟出了数据,但是有误差,是不会完全预测正确的
# 创建 KNN 分类器对象,并对训练集进行拟合
knn = KNeighborsClassifier()
knn.fit(X_train, y_train)
# 打印预测结果和真实标签
print(knn.predict(X_test))
print(y_test)
"""
[2 0 0 1 2 2 0 0 0 1 2 2 1 1 2 1 2 1 0 0 0 2 1 2 0 0 0 0 1 0 2 0 0 2 1 0 1
0 0 1 0 1 2 0 1]
[2 0 0 1 2 1 0 0 0 1 2 2 1 1 2 1 2 1 0 0 0 2 1 2 0 0 0 0 1 0 2 0 0 2 1 0 1
0 0 1 0 1 2 0 1]
"""
4.4 汇总
# sklearn.cross_validation 模块已经在 Scikit-learn 0.20 版本中被弃用
# 现使用 sklearn.model_selection 模块中的 train_test_split 函数来进行训练集和测试集的划分
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# 加载鸢尾花数据集
iris = datasets.load_iris()
iris_X = iris.data # 特征矩阵
iris_y = iris.target # 分类标签
##print(iris_X[:2, :])
##print(iris_y)
# 使用 train_test_split 函数将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(iris_X, iris_y, test_size=0.3) # 返回值是一个长度为 4 的元组
# 输出训练集标签
##print(y_train)
# 创建 KNN 分类器对象,并对训练集进行拟合
knn = KNeighborsClassifier() # 创建 KNN(K-Nearest Neighbors)分类器对
knn.fit(X_train, y_train) # 根据 X_train 和 y_train 的对应关系进行拟合,返回新knn
# 打印预测结果和真实标签
print(knn.predict(X_test)) # 使用训练好的 KNN 分类器对测试数据集 X_test 中的样本进行预测,并返回预测结果
print(y_test)
5 sklearn 强大数据库
5.1 波士顿房价
注: 波士顿数据因道德问题已从系统库中移除,这里改从其他地方获取数据
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
# 获取替代数据集
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
# header=None是Pandas中read_csv函数的一个参数选项,用于指示读取的CSV文件是否包含列名
# sep="\s+" 以空格进行分割
# skiprows=22 跳过前22行
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
model = LinearRegression()
# 机器学习y与x的关系
model.fit(data, target)
print(model.predict(data[:4, :]))
print(target[:4])
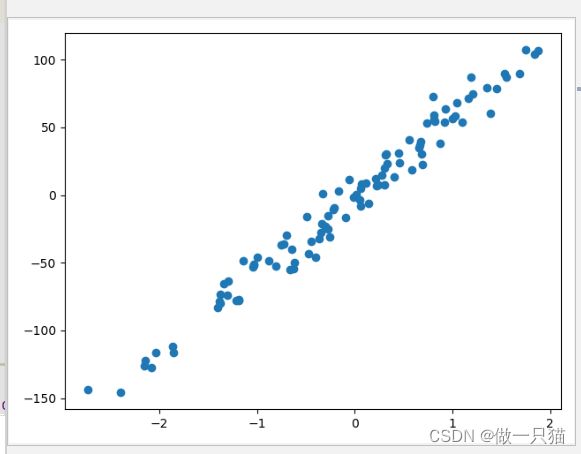
5.2 创建虚拟数据-可视化
下面是创造数据的例子。
用函数来建立 100 个 sample,有一个 feature,和一个 target,这样比较方便可视化。
import matplotlib.pyplot as plt
from sklearn import datasets
X, y = datasets.make_regression(n_samples=100, n_features=1, n_targets=1, noise=10) #噪声程度视实际情况而定
plt.scatter(X, y)
plt.show()
6 sklearn 常用属性与功能
以 LinearRegressor 为例,导入包、数据和模型
from sklearn import datasets
from sklearn.linear_model import LinearRegression
loaded_data = datasets.load_boston()
data_X = loaded_data.data
data_y = loaded_data.target
model = LinearRegression()
6.1 训练和预测
model.fit 和 model.predict 属于 Model 的功能,用于训练模型 和 用训练好的模型预测
model.fit(data_X, data_y)
print(model.predict(data_X[:4, :]))
"""
[ 30.00821269 25.0298606 30.5702317 28.60814055]
"""
6.2 参数和分数
model.coef_ 和 model.intercept_ 属于 Model 的属性, 例如对于 LinearRegressor 这个模型,这两个属性分别输出模型的斜率和截距(与y轴的交点)
print(model.coef_)
print(model.intercept_)
"""
[ -1.07170557e-01 4.63952195e-02 2.08602395e-02 2.68856140e+00
-1.77957587e+01 3.80475246e+00 7.51061703e-04 -1.47575880e+00
3.05655038e-01 -1.23293463e-02 -9.53463555e-01 9.39251272e-03
-5.25466633e-01]
36.4911032804
"""
model.get_params() 用于获取当前机器学习模型的参数设置
print(model.get_params())
"""
{'copy_X': True, 'normalize': False, 'n_jobs': 1, 'fit_intercept': True}
"""
model.score(data_X, data_y) 可对 Model 用 R^2 的方式进行打分,输出精确度。关于 R^2 coefficient of determination 可以查看 wiki
print(model.score(data_X, data_y)) # R^2 coefficient of determination
"""
0.740607742865
"""
7 正规化 Normalization
7.1 数据标准化
将范围相差较大的数据压缩到相近的范围中
from sklearn import preprocessing #标准化数据模块
import numpy as np
#建立Array
a = np.array([[10, 2.7, 3.6],
[-100, 5, -2],
[120, 20, 40]], dtype=np.float64)
#将normalized后的a打印出
print(preprocessing.scale(a))
# [[ 0. -0.85170713 -0.55138018]
# [-1.22474487 -0.55187146 -0.852133 ]
# [ 1.22474487 1.40357859 1.40351318]]
7.2 数据标准化对机器学习成效的影响
加载模块
# 标准化数据模块
from sklearn import preprocessing
import numpy as np
# 将资料分割成train与test的模块
from sklearn.model_selection import train_test_split
# 生成适合做classification资料的模块
from sklearn.datasets.samples_generator import make_classification
# Support Vector Machine中的Support Vector Classifier
from sklearn.svm import SVC
# 可视化数据的模块
import matplotlib.pyplot as plt
生成适合做Classification数据
#生成具有2种属性的300笔数据
X, y = make_classification(
n_samples=300, n_features=2,
n_redundant=0, n_informative=2,
random_state=22, n_clusters_per_class=1,
scale=100)
#可视化数据
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.show()
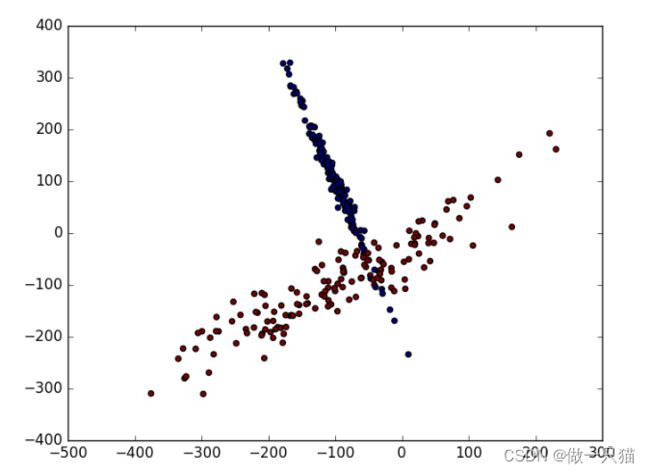
数据标准化前
标准化前的预测准确率只有0.477777777778
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
clf = SVC()
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))
# 0.477777777778
数据标准化后
数据的单位发生了变化, X 数据也被压缩到差不多大小范围
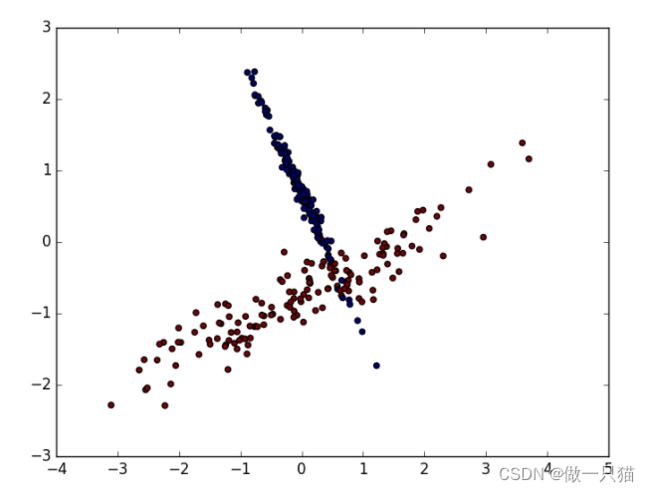
标准化后的预测准确率提升至0.9
X = preprocessing.scale(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
clf = SVC()
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))
# 0.9
8 检验神经网络 (Evaluation)
在神经网络的训练当中,神经网络可能会因为各种各样的问题, 出现学习的效率不高, 或者是因为干扰太多, 学到最后并没有很好的学到规律 。而这其中的原因可能是多方面的,可能是数据问题,学习效率 等参数问题
8.1 Training and Test data
为了检验并评价神经网络, 避免和改善这些问题,通常会把收集到的数据分为 训练数据 和 测试数据,一般用于训练的数据可以是所有数据的70%,剩下的30%可以拿来测试学习结果
8.2 误差曲线
对于神经网络的评价基本上是基于30%的测试数据
评价机器学习可以从误差值开始, 随着训练时间的变长,优秀的神经网络能预测到更为精准的答案,预测误差也会越少,到最后能够提升的空间变小,曲线也趋于水平

8.3 准确度曲线
最好的精度是趋向于100%精确
在神经网络的分类问题中, 100个样本中,有90个样本分类正确,预测精确度就是90%
在回归的问题中,可以引用 R2 分数在测量回归问题的精度,R2给出的最大精度也是100%
所以分类和回归有统一的精度标准
8.4 正规化
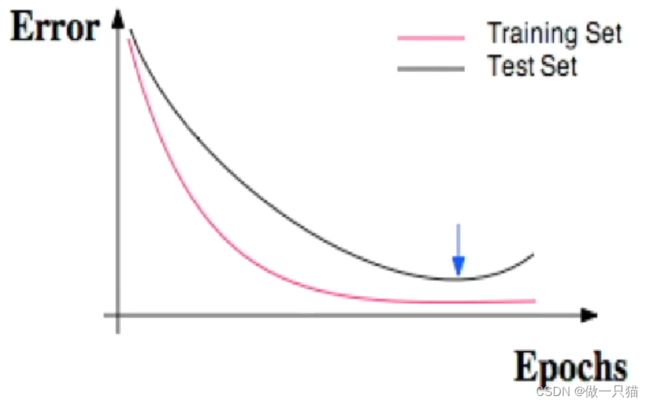
对于测试样本太过依赖,会产生过拟合现象,如下图,红色的是训练误差, 黑色的是测试误差,训练时的误差比测试的误差小
在机器学习中,解决过拟合也有很多方法 ,比如 l1,l2 正规化,dropout 方法
9 交叉验证
9.1 Model 基础验证法
from sklearn.datasets import load_iris # iris数据集
from sklearn.model_selection import train_test_split # 分割数据模块
from sklearn.neighbors import KNeighborsClassifier # K最近邻(kNN,k-NearestNeighbor)分类算法
#加载iris数据集
iris = load_iris()
X = iris.data
y = iris.target
#分割数据并
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=4)
#建立模型
knn = KNeighborsClassifier()
#训练模型
knn.fit(X_train, y_train)
#将准确率打印出
print(knn.score(X_test, y_test))
# 0.973684210526
9.2 Model 交叉验证法(Cross Validation)
from sklearn.cross_validation import cross_val_score # K折交叉验证模块
#使用K折交叉验证模块
scores = cross_val_score(knn, X, y, cv=5, scoring='accuracy')
#将5次的预测准确率打印出
print(scores)
# [ 0.96666667 1. 0.93333333 0.96666667 1. ]
#将5次的预测准确平均率打印出
print(scores.mean())
# 0.973333333333
9.3 以准确率(accuracy)判断
k个邻居
import matplotlib.pyplot as plt #可视化模块
#建立测试参数集
k_range = range(1, 31)
k_scores = []
#藉由迭代的方式来计算不同参数对模型的影响,并返回交叉验证后的平均准确率
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
scores = cross_val_score(knn, X, y, cv=10, scoring='accuracy')
k_scores.append(scores.mean())
#可视化数据
plt.plot(k_range, k_scores)
plt.xlabel('Value of K for KNN')
plt.ylabel('Cross-Validated Accuracy')
plt.show()
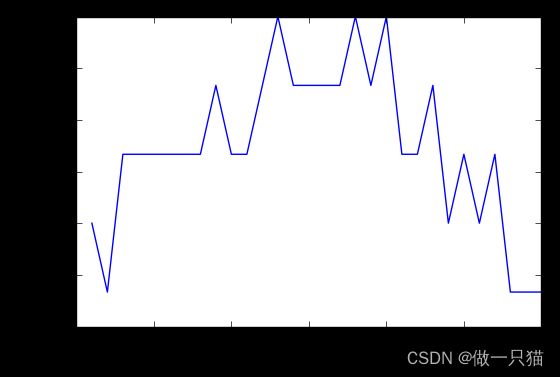
从图中可以得知,选择12~18的k值最好。高过18之后,准确率开始下降则是因为过拟合(Over fitting)的问题
9.4 以均方误差(Mean squared error)
一般来说均方误差(Mean squared error)会用于判断回归(Regression)模型的好坏
import matplotlib.pyplot as plt
k_range = range(1, 31)
k_scores = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
loss = -cross_val_score(knn, X, y, cv=10, scoring='mean_squared_error') # 注意加负号
k_scores.append(loss.mean())
plt.plot(k_range, k_scores)
plt.xlabel('Value of K for KNN')
plt.ylabel('Cross-Validated MSE')
plt.show()
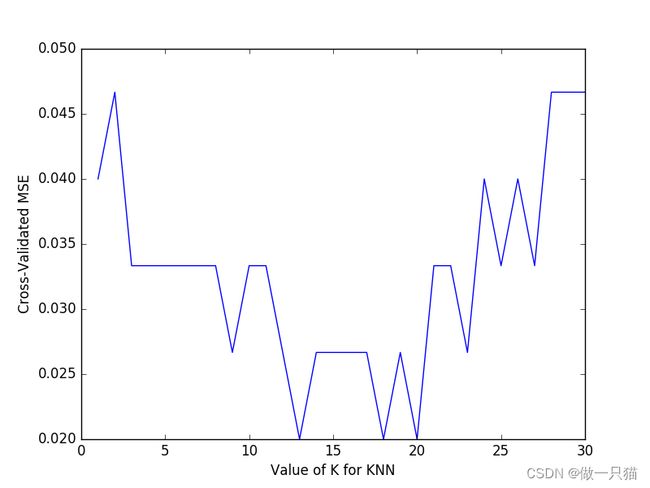
由图可以得知,平均方差越低越好,因此选择13~18左右的K值会最好
9.5 Learning curve 检视过拟合
learning_curve()官方API
这个函数主要是用来判断(可视化)模型是否过拟合的
加载对应模块:
from sklearn.learning_curve import learning_curve #学习曲线模块
from sklearn.datasets import load_digits #digits数据集
from sklearn.svm import SVC #Support Vector Classifier
import matplotlib.pyplot as plt #可视化模块
import numpy as np
补充说明:
learning_curve()函数: earning_curve(estimator, X, y, cv=None, train_sizes=None, scoring=None)
- estimator:要评估的模型(例如:SVC())
- X:特征数据
- y:目标数据
- cv:交叉验证的折数
- train_sizes:训练集大小的数组(例如:[0.1, 0.25, 0.5, 0.75, 1]),表示按百分比划分的训练集大小
- scoring:评估指标(例如:‘mean_squared_error’)
- 返回值:训练集大小、训练集上的损失和交叉验证集上的损失
train_sizes是一个表示不同训练集大小的数组,由learning_curve()生成,其中每个元素都是相对于总样本数的百分比,例如0.1表示使用10%的样本进行训练
train_scores是一个数组,表示在不同训练集大小下的训练集得分,即模型在训练集上的表现情况
test_scores是一个数组,表示在不同训练集大小下的交叉验证集得分,即模型在验证集上的表现情况。
SVC类的主要参数包括以下几个:
- C:惩罚参数,用于控制分类决策边界的平衡,C越小表示决策边界越平滑
- kernel:核函数,用于将数据从输入空间映射到另一个特征空间。常用的核函数包括’linear’(线性核函数)、‘poly’(多项式核函数)、‘rbf’(径向基函数)等
- degree:多项式核函数的阶数,仅当kernel为’poly’时有效
- gamma:核函数的系数,影响模型的复杂度和拟合效果,值越大模型越复杂
- coef0:核函数中的独立系数,仅当kernel为’poly’或’rbf’时有效
train_sizes参数可以是以下几种形式之一:
- 浮点数:表示相对于整个训练集大小的比例。例如,0.1表示使用10%的训练集大小
- 整数:表示具体的训练集大小。例如,100表示使用100个样本作为训练集
- 数组:包含了多个浮点数或整数,表示多个具体的训练集大小。例如,[0.1, 0.25, 0.5, 0.75, 1]表示使用10%、25%、50%、75%和100%的训练集大小
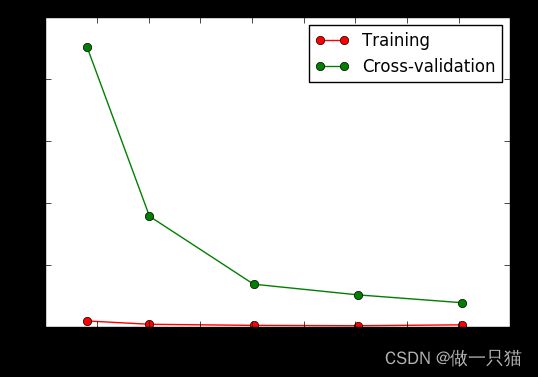
# 加载digits数据集,其包含的是手写体的数字,从0到9。数据集总共有1797个样本,每个样本由64个特征组成, 分别为其手写体对应的8×8像素表示,每个特征取值0~16
digits = load_digits()
X = digits.data
y = digits.target
# 观察样本由小到大的学习曲线变化, 采用K折交叉验证 cv=10, 选择平均方差检视模型效能 scoring='mean_squared_error', 样本由小到大分成5轮检视学习曲线(10%, 25%, 50%, 75%, 100%):
train_sizes, train_loss, test_loss = learning_curve(
SVC(gamma=0.001), X, y, cv=10, scoring='mean_squared_error',
train_sizes=[0.1, 0.25, 0.5, 0.75, 1]) # 参数顺序先后不影响
# 平均每一轮所得到的平均方差(共5轮,分别为样本10%、25%、50%、75%、100%)
train_loss_mean = -np.mean(train_loss, axis=1) # 单纯用numpy方法求平均值
test_loss_mean = -np.mean(test_loss, axis=1)
# 可视化图形:
plt.plot(train_sizes, train_loss_mean, 'o-', color="r",
label="Training")
plt.plot(train_sizes, test_loss_mean, 'o-', color="g",
label="Cross-validation")
plt.xlabel("Training examples")
plt.ylabel("Loss")
plt.legend(loc="best")
plt.show()
9.6 validation_curve 检视过拟合
validation_curve()官方API
validation_curve():这个函数主要是用来查看在参数不同的取值下模型的性能
validation_curve(estimator, X, y, param_name, param_range, cv=None, scoring=None, n_jobs=None)
- estimator:要使用的机器学习模型对象
- X:特征数据
- y:目标变量数据
- param_name:超参数的名称
- param_range:超参数的取值范围
- cv:交叉验证的折数
- scoring:可选参数,评估指标
- n_jobs:可选参数,指定并行计算的作业数量
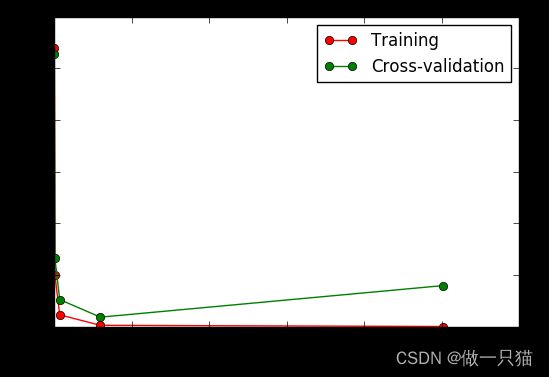
from sklearn.learning_curve import validation_curve #validation_curve模块
from sklearn.datasets import load_digits
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
# digits数据集
digits = load_digits()
X = digits.data
y = digits.target
# 建立参数测试集
param_range = np.logspace(-6, -2.3, 5)
# 使用validation_curve快速找出参数对模型的影响
train_loss, test_loss = validation_curve(
SVC(), X, y, param_name='gamma', param_range=param_range, cv=10, scoring='mean_squared_error')
# 平均每一轮的平均方差
train_loss_mean = -np.mean(train_loss, axis=1)
test_loss_mean = -np.mean(test_loss, axis=1)
# 可视化图形
plt.plot(param_range, train_loss_mean, 'o-', color="r",
label="Training")
plt.plot(param_range, test_loss_mean, 'o-', color="g",
label="Cross-validation")
plt.xlabel("gamma")
plt.ylabel("Loss")
plt.legend(loc="best")
plt.show()
10 保存模型
10.1 使用 pickle 保存
简单建立与训练一个SVCModel
from sklearn import svm
from sklearn import datasets
clf = svm.SVC()
iris = datasets.load_iris()
X, y = iris.data, iris.target
clf.fit(X,y)
用pickle来保存与读取训练好的Model
pickle学习链接
import pickle #pickle模块
#保存Model(注:save文件夹要预先建立,否则会报错)
with open('save/clf.pickle', 'wb') as f:
pickle.dump(clf, f)
#读取Model
with open('save/clf.pickle', 'rb') as f:
clf2 = pickle.load(f)
#测试读取后的Model
print(clf2.predict(X[0:1]))
# [0]
10.2 使用 joblib 保存
joblib是sklearn的外部模块
from sklearn.externals import joblib #jbolib模块
#保存Model(注:save文件夹要预先建立,否则会报错)
joblib.dump(clf, 'save/clf.pkl')
#读取Model
clf3 = joblib.load('save/clf.pkl')
#测试读取后的Model
print(clf3.predict(X[0:1]))
# [0]
joblib在使用上比较容易,读取速度也相对pickle快