DevOps工程师技能_容器化技术之K8s集群搭建
K8s-集群搭建部署说明
1、 安装包下载
CentOS Linux 7.6 1810 x86 64 iso官方原版镜像下载
https://renwole.com/archives/1530
2、系统环境配置
ip addr
vi /etc/sysconfig/network-scripts/ifcfg-ens33
service network restart

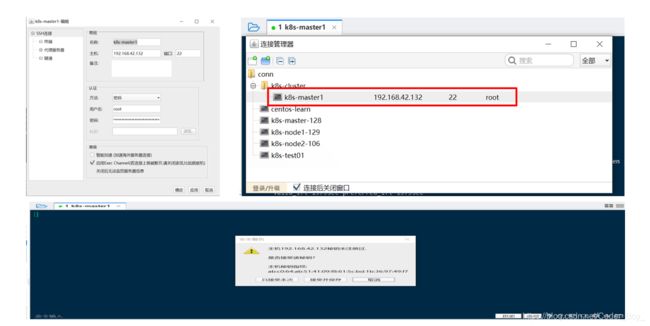
3、客户端连接配置
4、更新并安装依赖
3台机器都需要执行
yum -y update
yum install -y conntrack ipvsadm ipset jq sysstat curl iptables libseccomp

准备docker安装包

上传指定位置并安装docker
创建上传目录
mkdir -p /docker/rpm
进入目录
cd /docker/rpm
执行rpm安装命令
rpm -ivh *.rpm
docker 安装报错 container-selinux >= 2.9 解决

解决办法:下载阿里云的repo并安装所需的rpm
1.安装wget
yum install wget https://blog.csdn.net/FR13DNS/article/details/87555842
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
- 安装epel源
yum install epel-release
yum install container-selinux
安装成功后如右图:

再次安装Docker
警告:containerd.io-1.2.0-3.el7.x86_64.rpm: 头V4 RSA/SHA512 Signature, 密钥 ID 621e9f35: NOKEY
修改hosts文件
设置master的hostname,并且修改hosts文件
sudo hostnamectl set-hostname m
vi /etc/hosts
192.168.42.132 master
192.168.42.129 work1
192.168.42.130 work2
设置worker01/02的hostname,并且修改hosts文件
sudo hostnamectl set-hostname work1
sudo hostnamectl set-hostname work2
vi /etc/hosts
192.168.42.132 master
192.168.42.129 work1
192.168.42.130 work2
使用ping互相测试一下

系统基础前提配置
(1)关闭防火墙
systemctl stop firewalld && systemctl disable firewalld
(2)关闭selinux
setenforce 0
sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config
(3)关闭swap
swapoff -a
sed -i '/swap/s/^\(.*\)$/#\1/g' /etc/fstab
(4)配置iptables的ACCEPT规则
iptables -F && iptables -X && iptables -F -t nat && iptables -X -t nat && iptables -P FORWARD ACCEPT
(5)设置系统参数
cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system
Installing kubeadm, kubelet and kubectl
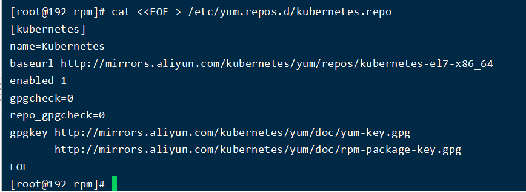
(1)配置yum源
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
(2)安装kubeadm&kubelet&kubectl
yum install -y kubeadm-1.14.0-0 kubelet-1.14.0-0 kubectl-1.14.0-0 【不推荐,除非熟悉版本匹配】
yum install -y kubeadm kubelet kubectl

(3)docker和k8s设置同一个cgroup
linux系统创建/etc/docker/daemon.json (mkdir)
{
"registry-mirrors": ["https://zfzbet67.mirror.aliyuncs.com"]
}

docker
vi /etc/docker/daemon.json
"exec-opts": ["native.cgroupdriver=systemd"],
systemctl restart docker
kubelet
sed -i "s/cgroup-driver=systemd/cgroup-driver=cgroupfs/g" /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
systemctl enable kubelet && systemctl start kubelet
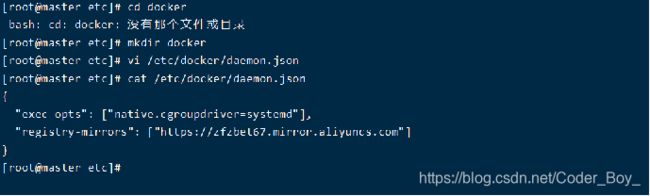
vi /etc/docker/daemon.json的问题
"/etc/docker/daemon.json" E212: Can't open file for writing
出现这个错误的原因是etc目录下没有docker目录,需要先在etc目录下创建docker文件夹,然后再对daemon。json进行修改。
命令参考
[root@localhost ~]# cd /etc
1
[root@localhost etc]# mkdir docker
1
[root@localhost etc]# cd docker
1
[root@localhost docker]# vi daemon.json
sed:无法读取 /etc/systemd/system/kubelet.service.d/10-kubeadm.conf:没有那个文件或目录看看是不是文件路径写错了!!!

proxy/pause/scheduler等国内镜像
(1)查看kubeadm使用的镜像
kubeadm config images list
可以发现这里都是国外的镜像

(2)解决国外镜像不能访问的问题
- 创建kubeadm.sh脚本,用于拉取镜像/打tag/删除原有镜像
kubeadm.sh
#!/bin/bash
set -e
KUBE_VERSION=v1.14.0
KUBE_PAUSE_VERSION=3.1
ETCD_VERSION=3.3.10
CORE_DNS_VERSION=1.3.1
GCR_URL=k8s.gcr.io
ALIYUN_URL=registry.cn-hangzhou.aliyuncs.com/google_containers
images=(kube-proxy:${KUBE_VERSION}
kube-scheduler:${KUBE_VERSION}
kube-controller-manager:${KUBE_VERSION}
kube-apiserver:${KUBE_VERSION}
pause:${KUBE_PAUSE_VERSION}
etcd:${ETCD_VERSION}
coredns:${CORE_DNS_VERSION})
for imageName in ${images[@]} ; do
docker pull $ALIYUN_URL/$imageName
docker tag $ALIYUN_URL/$imageName $GCR_URL/$imageName
docker rmi $ALIYUN_URL/$imageName
done
运行脚本和查看镜像 sh ./kubeadm.sh docker images



将这些镜像推送到自己的阿里云仓库【可选,根据自己实际的情况】 登录自己的阿里云仓库
docker login --username=用户名 registry.cn-qingdao.aliyuncs.com
docker tag quay.io/coreos/hyperkube:v1.7.6_coreos.0 registry.cn-qingdao.aliyuncs.com/jiangp-istio/hyperkube:v1.7.6_coreos.0
docker tag grafana/grafana:5.2.3 registry.cn-qingdao.aliyuncs.com/jiangp-istio/grafana:5.2.3
docker tag docker.io/prom/prometheus:v2.3.1 registry.cn-qingdao.aliyuncs.com/jiangp-istio/prometheus:v2.3.1
docker tag docker.io/jaegertracing/all-in-one:1.5 registry.cn-qingdao.aliyuncs.com/jiangp-istio/all-in-one:1.5
运行脚本 sh ./kubeadm-push-aliyun.sh
#!/bin/bash
set -e
KUBE_VERSION=v1.14.0
KUBE_PAUSE_VERSION=3.1
ETCD_VERSION=3.3.10
CORE_DNS_VERSION=1.3.1
GCR_URL=k8s.gcr.io
ALIYUN_URL=registry.cn-qingdao.aliyuncs.com/jiangp-k8s
images=(kube-proxy:${KUBE_VERSION}
kube-scheduler:${KUBE_VERSION}
kube-controller-manager:${KUBE_VERSION}
kube-apiserver:${KUBE_VERSION}
pause:${KUBE_PAUSE_VERSION}
etcd:${ETCD_VERSION}
coredns:${CORE_DNS_VERSION})
for imageName in ${images[@]} ; do
docker tag $GCR_URL/$imageName $ALIYUN_URL/$imageName
docker push $ALIYUN_URL/$imageName
docker rmi $ALIYUN_URL/$imageName
done
kube init初始化master
(1)kube init流程
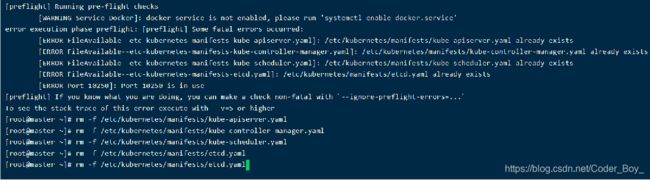
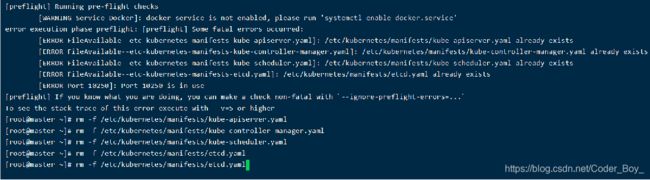
下图对应下一页的重新初始化集群状态:kubeadm reset 需要删除已有文件才能执行ok
01-进行一系列检查,以确定这台机器可以部署kubernetes
02-生成kubernetes对外提供服务所需要的各种证书可对应目录 /etc/kubernetes/pki/*
03-为其他组件生成访问kube-ApiServer所需的配置文件
ls /etc/kubernetes/
admin.conf controller-manager.conf kubelet.conf scheduler.conf
04-为 Master组件生成Pod配置文件。
ls /etc/kubernetes/manifests/.yaml
kube-apiserver.yaml
kube-controller-manager.yaml
kube-scheduler.yaml
05-生成etcd的Pod YAML文件。
ls /etc/kubernetes/manifests/.yaml
kube-apiserver.yaml
kube-controller-manager.yaml
kube-scheduler.yaml etcd.yaml 06-一旦这些 YAML 文件出现在被 kubelet 监视的/etc/kubernetes/manifests/目录下,kubelet就会自动创建这些yaml文件定义的pod,即master组件的容器。master容器启动后,kubeadm会通过检查localhost:6443/healthz这个master组件的健康状态检查URL,等待master组件完全运行起来07-为集群生成一个bootstrap token
08-将ca.crt等 Master节点的重要信息,通过ConfigMap的方式保存在etcd中,工后续部署node节点使用
09-最后一步是安装默认插件,kubernetes默认kube-proxy和DNS两个插件是必须安装的
(2)初始化master节点
注意:此操作是在主节点上进行
kubeadm init --kubernetes-version=v1.18.3 --pod-network-cidr=10.0.0.0/16 --apiserver-advertise-address=192.168.42.132 --service-cidr 11.0.0.0/12 --image-repository=registry.aliyuncs.com/google_containers
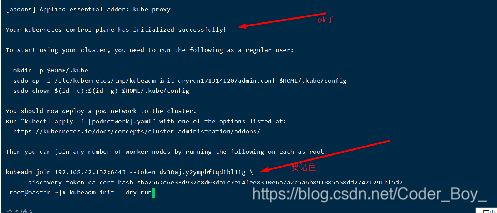
【若要重新初始化集群状态:kubeadm reset,然后再进行上述操作】
查看执行流程使用:
kubeadm init --dry-run
记得保存好最后kubeadm join的信息
如果初始化过程出现问题,使用如下命令重置:
kubeadm reset
rm -rf /var/lib/cni/ $HOME/.kube/config
过程中遇到异常:
`[preflight] Some fatal errors occurred:
[ERROR DirAvailable--var-lib-etcd]: /var/lib/etcd is not empty`
直接删除/var/lib/etcd文件夹
参考文档: https://www.cnblogs.com/hongdada/p/9761336.html
解决办法:
重启一下kubeadm:
[root@k8s-master ~]# kubeadm reset

删除之前已经存在的文件
rm –f 文件名
解决方法输入
echo "1" >/proc/sys/net/ipv4/ip_forward

执行提示命令即可使用集群
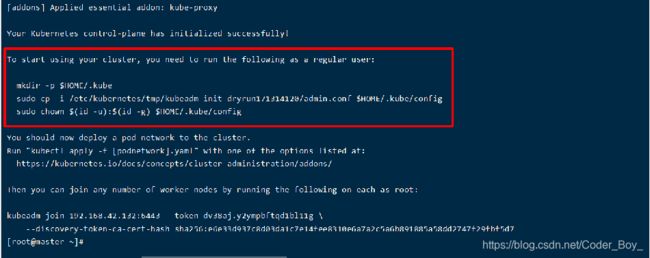
检查是否搭建ok
此时kubectl cluster-info查看一下,输出类似于以下信息说明就连接成功了:发现报错

Unable to connect to the server: x509: certificate signed by unknown authority (possibly because of "crypto/rsa: verification error" while trying to verify candidate authority certificate "kubernetes")
解决方法:
先删除 $HOME/.kube
[root@master ~]# rm -rf $HOME/.kube
[root@master ~]# mkdir -p $HOME/.kube
[root@master ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@master ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config
[root@master ~]# kubectl get svc
查看node状态是否正常 node NotReady 因为没有创建k8s网络插件 ( K8s网络插件flannel与calico)
推荐安装calico选择网络插件:https://kubernetes.io/docs/concepts/cluster-administration/addons/
calico网络插件:https://docs.projectcalico.org/v3.9/getting-started/kubernetes/

部署calico网络插件
calico,同样在master节点上操作 注意:calico镜像拉取可能拉取比较慢,可以先手动pull一下
docker pull calico/pod2daemon-flexvol:v3.9.1
docker pull calico/kube-controllers:v3.9.1
docker pull calico/cni:v3.9.1
在k8s中安装calico
kubectl apply -f https://docs.projectcalico.org/v3.9/manifests/calico.yaml
确认一下calico是否安装成功
kubectl get pods --all-namespaces -w
显示效果:Pod状态实时更新的

检查集群状态
查看pod验证一下
kubectl get pods -n kube-system
等待一会儿,同时可以发现像etc,controller,scheduler等组件都以pod的方式安装成功了
coredns没有启动,需要安装网络插件,或者网络插件安装有问题
健康检查
curl -k https://localhost:6443/healthz

kube join 追加node节点
记得保存初始化master节点的最后打印信息【注意这边大家要自己的,下面我的只是一个参考】

NAME STATUS ROLES AGE VERSION
master-kubeadm-k8s Ready master 19m v1.14.0
worker01-kubeadm-k8s Ready <none> 3m6s v1.14.0
worker02-kubeadm-k8s Ready <none> 2m41s v1.14.0

master节点上检查集群信息
kubectl get nodes查看集群状态
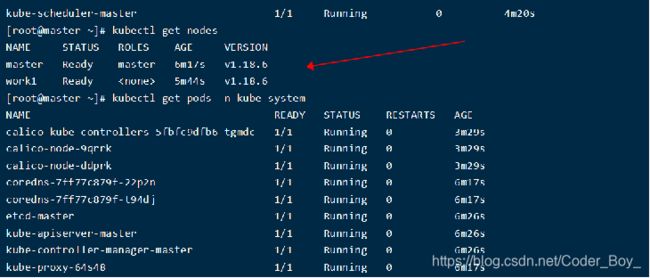
到此K8s集群搭建成功了!