ArcGIS arcpy代码工具——批量栅格转点文件导出属性表
系列文章目录
ArcGIS arcpy代码工具——批量对MXD文件的页面布局设置修改
ArcGIS arcpy代码工具——数据驱动工具批量导出MXD文档并同步导出图片
ArcGIS arcpy代码工具——将要素属性表字段及要素截图插入word模板
ArcGIS arcpy代码工具——定制属性表字段输出表格
文章目录
- 系列文章目录
- 功能说明
- 1 准备工作
-
-
- 知识点:arcgis 要素类和表名称规则和限制
-
- 2 代码分段
-
-
- (1) 设置工作目录
- (2) 设置工作空间,遍历栅格文件
- (3) 提取文件名称,去掉汉字
- (4) 栅格转点
- (5) 计算字段
- (6) 点文件添加XY坐标值
- (7) 点文件导出属性表
- (8) 点文件导出shape层
- (9) 其他代码
-
- 3 完整代码
- 4 后记
功能说明
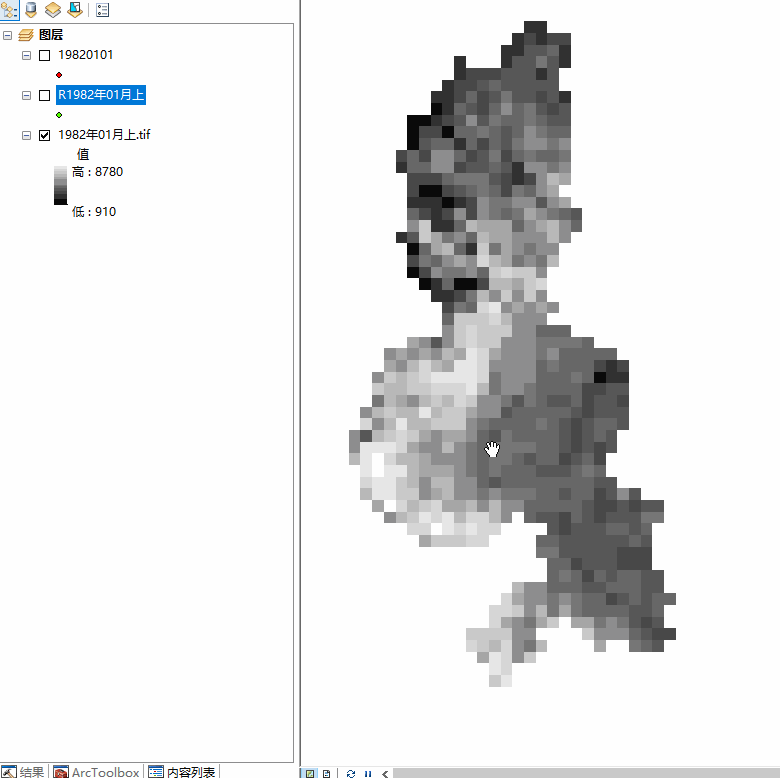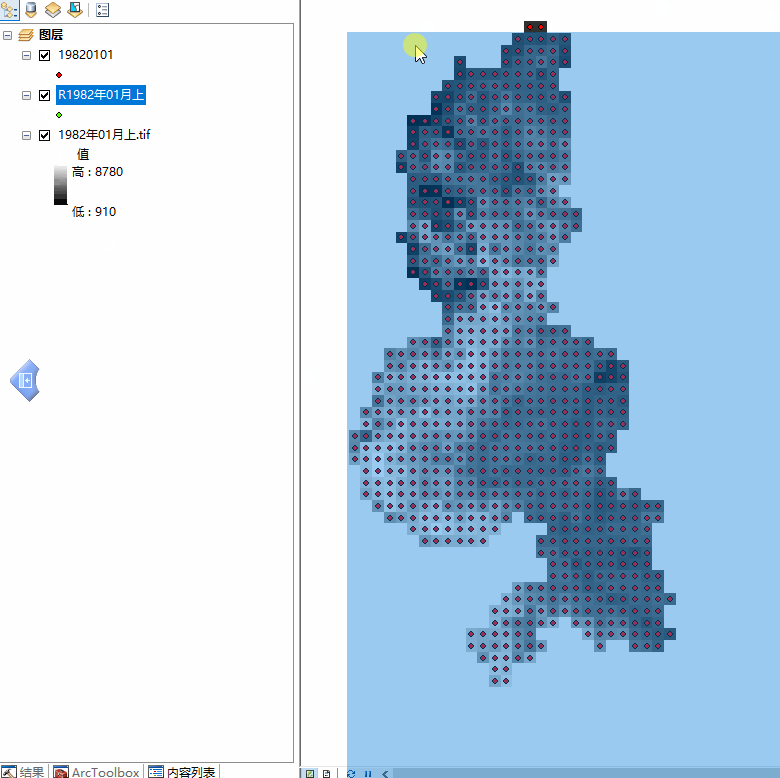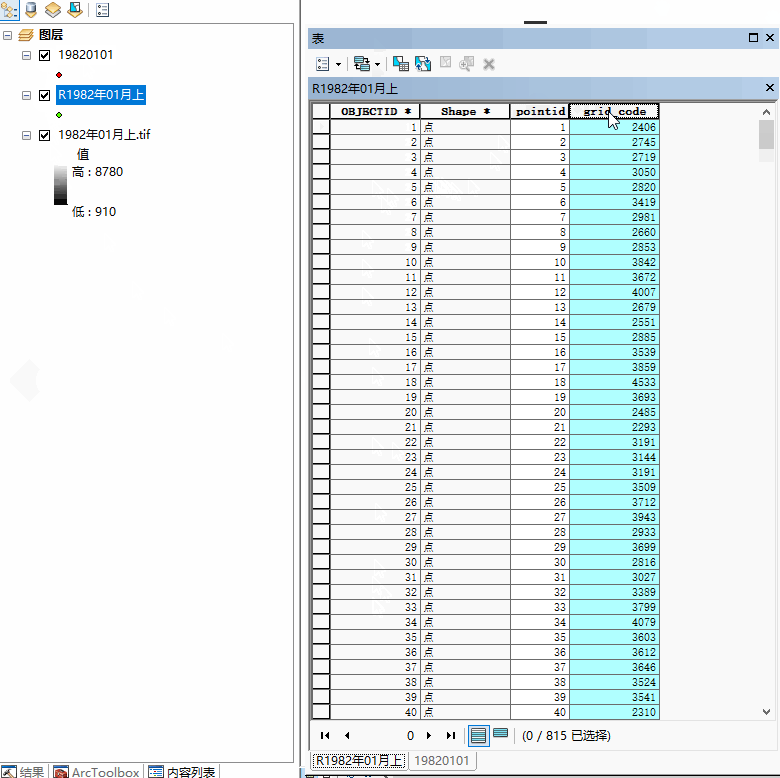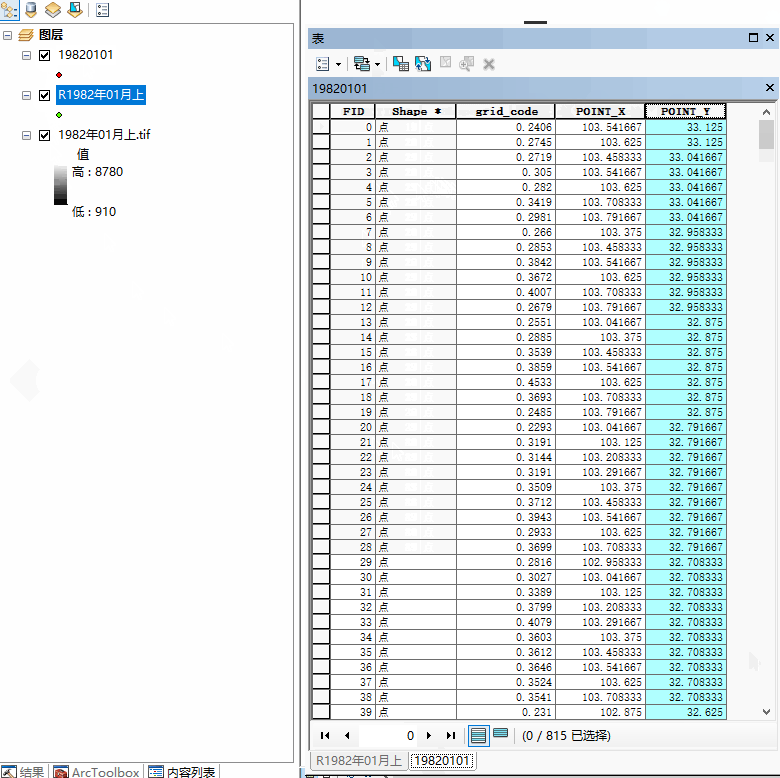
接到一个工作,内容描述如下:对数百个栅格文件转换为点文件,保留栅格的value值并除10000,并添加点坐标XY值,最后导出点文件为shape层、点属性表导出为excel表格。点shape层、表格名称需要将栅格文件名称的汉字去掉。效果如下图:
本代码目标为:
- 1 逐个读取栅格文件,栅格转换为点文件,保留栅格value值;
- 2 对点文件进行字段计算,value除以10000;
- 3 对点文件添加XY坐标值;
- 4 点文件属性表导出为excel表格,注意文件名重命名;
- 5 点文件导出为shape层。
1 准备工作
因为栅格文件数量较多,大小不一,首先选择2个较小的栅格文件测试,放入文件夹中。
栅格文件名称如下图1-1 ,标注1:

栅格名称:XXXX年XX月上.tif、XXXX年XX月下.tif。。。。。。每个月分 上、下 两幅栅格,
最终的成果表格和点shape层,名称修改为图中 标注3 、标注4 所示,即去掉汉字 年 ,
将汉字 月上 修改为 01, 月下 修改为 02。
知识点:arcgis 要素类和表名称规则和限制
arcgis对于要素类和表名称的命名,有特殊要求,其中一条就是名称不能以数值开头 ,其他规则如下图所示:
下表列出了受支持的要素类和表名称字符规则:

- 名称不能以 ‘下划线’ 开头,后面可以有 ‘下划线’ ;
- 名称不能以 ‘数字’ 开头,后面可以有 ‘数字’;
- 名称中不能有 ‘空格’ ;
- 名称中不能有符号(下划线除外);
- 名称中不能有上标字母和数字;
- 名称中不能有下标字母和数字。
- 其他要素类和表名称规则和限制如下:
要素类或表名称中不能包含保留字,例如 select 或 add。
编写代码也一样,最好不要使用 程序语言中的保留字,一般的IDE软件会有提示。 - 不支持具有以下前缀的要素类名或表名:
gdb_
sde_
delta_ - 要素类名称和表名称的长度取决于基础数据库。
特别注意: shape格式文件,作为一种通用数据交换格式,可以跨软件应用,所以不再受到arcgis的要素类名称限制,可以使用数字开头命名了。
针对本项目,栅格转点文件的过程层需要存入GDB空间数据库,受到arcgis软件的命名限制,名称不能以数字开头,故我在名称前添加字母 p ,如上图1-1 ,标注2。
2 代码分段
总体思路:首先栅格转点,计算点字段,导出表格。
栅格转点文件,在运行过程中先存入gdb数据库中,方便管理,最后统一导出为shape层。
下面开始分段编码:
(1) 设置工作目录
设置工作目录
rasterpath = r'D:/outexcel/栅格' # 栅格目录
pointgdb = r'D:/outexcel/point.gdb' # 点文件数据库
pointpath = r'D:/outexcel/矢量' # 点shape层目录
excelpath = r'D:/outexcel/导出表格' # 表格目录
(2) 设置工作空间,遍历栅格文件
设置存放栅格的文件夹为工作空间,遍历里面的栅格文件。
arcpy.env.workspace = rasterpath
raster_files = arcpy.ListRasters()
for raster_file in raster_files:
(3) 提取文件名称,去掉汉字
提取栅格文件名称(完整路径,作为arcgis动作的输入文件路径)
raster_name = os.path.basename(raster_file)
去掉汉字,有很多方法,本次编码使用 列表截取方法。
这里我分两步:
- 第一步 ,去掉 “年”;
- 第二步,通过if判断,替换 "月上"和 “月下”;
// #第一步 ,去掉 "年"
lastname = raster_name[:4] + raster_name[5:-4]
// #第二步 ,替换 "月上"和 "月下"
if "月上" in raster_name:
lastname = lastname[:6] + "01"
elif "月下" in raster_name:
lastname = lastname[:6] + "02"
第二步的”IF“语句,直接使用了汉字编码,arcigs软件配套的python2.7对汉字支持较差,但其实是支持中文汉字的,我的方法是在代码首行添加如下:# -- coding: 936 --,936代表GBK中文编码。
# -*- coding: 936 -*-
此时的 lastname 已经是最终表格的名称了 19820101、19820102。
(4) 栅格转点
栅格转点文件,放入 pointgdb.gdb 中间数据库,名称前添加字母 “p”.
out_point_feature = os.path.join(pointgdb, "p" + lastname)
arcpy.RasterToPoint_conversion(
in_raster=raster_file,
out_point_features=out_point_feature)
(5) 计算字段
由于栅格转点后,点图层的字段 [grid_code] 存储的是栅格value值,但是字段格式为文本型,任务要求除以10000,需要新建一个数值型字段 并计算。
这里先将 [grid_code] 字段改名,最终的数值型字段仍然使用[grid_code] 字段名。
arcpy.AlterField_management(in_table=out_point_feature, field="grid_code", new_field_name="gridcode")
arcpy.AddField_management(in_table=out_point_feature, field_name="grid_code", field_type="DOUBLE")
arcpy.CalculateField_management(in_table=out_point_feature,
field="grid_code", expression="[gridcode]/10000",
expression_type="VB", code_block="")
删除多余的字段
arcpy.DeleteField_management(in_table=out_point_feature, drop_field="gridcode")
arcpy.DeleteField_management(in_table=out_point_feature, drop_field="pointid")
(6) 点文件添加XY坐标值
arcpy.AddXY_management(in_features=out_point_feature)
(7) 点文件导出属性表
属性表导出为excel格式
Output_Excel_File_name = os.path.join(excelpath, lastname + ".xls")
arcpy.TableToExcel_conversion(Input_Table=out_point_feature,
Output_Excel_File=Output_Excel_File_name)
(8) 点文件导出shape层
由于过程中,点文件都存入了 pointgdb.gdb过程数据库,它并不在 最初设置的工作空间中
arcpy.env.workspace = rasterpath ,
故,首先需要更新工作空间,然后遍历 pointgdb.gdb 库,将所有图层导出为 shape层,注意文件名称重命名。
注意: shape层的名称不受arcgis的要素类名称规则限制,所有可以用数字命名。
arcpy.env.workspace = pointgdb
feature_classes = arcpy.ListFeatureClasses()
for fc in feature_classes:
shape_name = fc[1:] # 重命名,去掉首字母 p
output_shapefile = os.path.join(pointpath, shape_name + ".shp")
arcpy.FeatureClassToFeatureClass_conversion(fc, pointpath, shape_name)
(9) 其他代码
由于栅格文件太多,且大小也不同,故每一个步骤运行的时间差异较大,所以最好将栅格文件按大小分类,分批次运行代码。
为了方便观察进度,在代码中,添加一些print()语句,打印出每一步开始的时间,方便观察进度。
适当进行暂停,给软件喘息时间。
3 完整代码
完整代码如下:
# -*- coding: 936 -*-
import arcpy
import os
import sys
import time
reload(sys)
sys.setdefaultencoding('utf-8')
rasterpath = r'D:/outexcel/栅格' # the_folder_where_the_raster_is_stored
pointgdb = r'D:/outexcel/point.gdb' # the_database_of_the_storage_point_shape
pointpath = r'D:/outexcel/矢量' # shape folder
excelpath = r'D:/outexcel/导出表格' # the_folder_where_the_table_is_stored
arcpy.env.workspace = rasterpath
raster_files = arcpy.ListRasters()
for raster_file in raster_files:
raster_name = os.path.basename(raster_file)
lastname = raster_name[:4] + raster_name[5:-4]
print(lastname)
if "月上" in raster_name:
lastname = lastname[:6] + "01"
elif "月下" in raster_name:
lastname = lastname[:6] + "02"
print(time.strftime("%Y-%m-%d %H:%M:%S"), "start raster to point feather")
out_point_feature = os.path.join(pointgdb, "p" + lastname)
arcpy.RasterToPoint_conversion(
in_raster=raster_file,
out_point_features=out_point_feature)
time.sleep(10) # time_out 10 second
arcpy.AlterField_management(in_table=out_point_feature, field="grid_code", new_field_name="gridcode")
arcpy.AddField_management(in_table=out_point_feature, field_name="grid_code", field_type="DOUBLE")
arcpy.CalculateField_management(in_table=out_point_feature,
field="grid_code", expression="[gridcode]/10000",
expression_type="VB", code_block="")
arcpy.DeleteField_management(in_table=out_point_feature, drop_field="gridcode")
arcpy.DeleteField_management(in_table=out_point_feature, drop_field="pointid")
arcpy.AddXY_management(in_features=out_point_feature)
print(time.strftime("%Y-%m-%d %H:%M:%S"), "start point feather to excel")
Output_Excel_File_name = os.path.join(excelpath, lastname + ".xls")
arcpy.TableToExcel_conversion(Input_Table=out_point_feature,
Output_Excel_File=Output_Excel_File_name)
time.sleep(10) # time_out 10 second
print("---------")
print(time.strftime("%Y-%m-%d %H:%M:%S"), "start all point feather to shape")
arcpy.env.workspace = pointgdb
feature_classes = arcpy.ListFeatureClasses()
for fc in feature_classes:
shape_name = fc[1:]
output_shapefile = os.path.join(pointpath, shape_name + ".shp")
arcpy.FeatureClassToFeatureClass_conversion(fc, pointpath, shape_name)
print(time.strftime("%Y-%m-%d %H:%M:%S"), "the end")
4 后记
运行效果如下图:
可以看到,我在代码中添加了 time.sleep()语句进行了几次暂停,这也是给argis软件的一个缓存时间,我的测试对象是小栅格文件,实际应用中,大栅格文件在转点和导出表格时,用时较长,所以电脑需要关闭待机、睡眠等设置,防止程序中断。有了print()语句可以方便查看进度,在操作大栅格文件时尤其有用。
通过以上代码,可以总结出来,arcgis的常见工具都可以使用arcpy编写代码来实现,只是值不值来编程而已。一般的批量重复动作,文件数量比较多的时候,才会使用arcpy来实现。这也是pyhton语言的座右铭:人生苦短,我用Python,用python来打败重复劳动。syq