前传02 | 线程模型
前传02 | 线程模型
- 一、Socket模型
- 二、IO多路复用(Reactor的技术实现)
- 三、线程模型的历史发展
-
- 多线程版设计
- 线程池版设计
- selector 版设计
- 四、Reactor模型的理论
-
- 工作机制
- 五、Reactor模型的实现
-
- Reactor单线程模型
- Reactor多线程模型
- Reactor主从模型
-
- 1) Selector
- 2) EventLoopGroup/EventLoop
- 3) ChannelPipeline
- Netty是哪一种呢?
一、Socket模型
使用 Socket 模型实现网络通信时,需要经过创建 Socket、监听端口、处
理连接和读写请求等多个步骤。
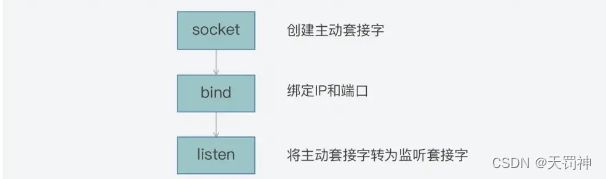
首先,当我们需要让服务器端和客户端进行通信时,可以在服务器端通过以下三步,来创建监听客户端连接的监听套接字(Listening Socket):
- 调用 socket 函数,创建一个套接字。我们通常把这个套接字称为主动套接字(Active
Socket); - 调用 bind 函数,将主动套接字和当前服务器的 IP 和监听端口进行绑定;
- 调用 listen 函数,将主动套接字转换为监听套接字,开始监听客户端的连接。
- 调用accept 函数,在完成上述三步之后,服务器端就可以接收客户端的连接请求了。为了能及时地收到客户端的连接请求,我们可以运行一个循环流程,在该流程中调用 accept 函数,用于接收客户端连接请求。
- 最后,服务器端可以通过调用 recv 或 send 函数,在刚才返回的已连接套接字上,接收并处理读写请求,或是将数据发送给客户端。
单线程模型:
listenSocket = socket(); //调用socket系统调用创建一个主动套接字
bind(listenSocket); //绑定地址和端口
listen(listenSocket); //将默认的主动套接字转换为服务器使用的被动套接字,也就是监听套接字
while (1) { //循环监听是否有客户端连接请求到来
connSocket = accept(listenSocket); //接受客户端连接
recv(connsocket); //从客户端读取数据,只能同时处理一个客户端
send(connsocket); //给客户端返回数据,只能同时处理一个客户端
}
多线程模型,使用多线程来提升服务器端的并发客户端处理能力。
listenSocket = socket(); //调用socket系统调用创建一个主动套接字
bind(listenSocket); //绑定地址和端口
listen(listenSocket); //将默认的主动套接字转换为服务器使用的被动套接字,即监听套接字
while (1) { //循环监听是否有客户端连接到来
connSocket = accept(listenSocket); //接受客户端连接,返回已连接套接字
pthread_create(processData, connSocket); //创建新线程对已连接套接字进行处理
}
//处理已连接套接字上的读写请求
processData(connSocket){
recv(connsocket); //从客户端读取数据,只能同时处理一个客户端
send(connsocket); //给客户端返回数据,只能同时处理一个客户端
}
二、IO多路复用(Reactor的技术实现)
功能差异:

select机制与使用
Linux 针对每一个套接字都会有一个文件描述符,也就是一个非负整数,用来唯一标识该套接字。所以,在多路复用机制的函数中,Linux 通常会用文件描述符作为参数。有了文件描述符,函数也就能找到对应的套接字,进而进行监听、读写等操作。
select函数:
select 机制中的一个重要函数就是 select 函数。
int select (int __nfds, fd_set *__readfds, fd_set *__writefds, fd_set *__excep, int *__timeout)
参数说明:
1)监听的文件描述符数量,__nfds
2)被监听描述符的三个集合,__readfds、__writefds和*__exceptfds
__readfds:读数据事件
__writefds:写数据事件
__exceptfds:异常事件
3)监听时阻塞等待的超时时长,*__timeout
# fd_set 结构体
## __fd_mask类型是 long int 类型的别名,
## __FD_SETSIZE 和 __NFDBITS 这两个宏定义的大小默认为 1024 和 32
typedef struct {
…
__fd_mask __fds_bits[__FD_SETSIZE / __NFDBITS];
…
} fd_set
所以,fd_set 结构体的定义,其实就是一个 long int 类型的数组,该数组中一共有 32 个
元素(1024/32=32),每个元素是 32 位(long int 类型的大小),而每一位可以用来表
示一个文件描述符的状态。
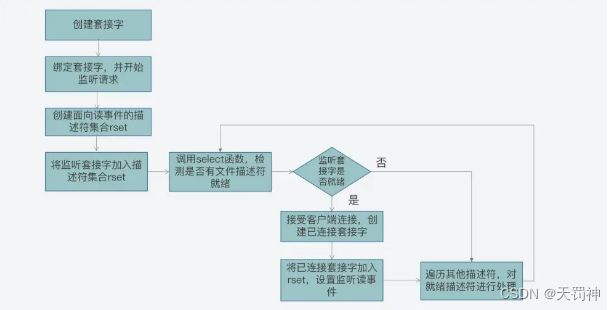
使用 select 函数,进行并发客户端处理的关键步骤和主要函数调用:
int sock_fd,conn_fd; //监听套接字和已连接套接字的变量
sock_fd = socket() //创建套接字
bind(sock_fd) //绑定套接字
listen(sock_fd) //在套接字上进行监听,将套接字转为监听套接字
fd_set rset; //被监听的描述符集合,关注描述符上的读事件
int max_fd = sock_fd
//初始化rset数组,使用FD_ZERO宏设置每个元素为0
FD_ZERO(&rset);
//使用FD_SET宏设置rset数组中位置为sock_fd的文件描述符为1,表示需要监听该文件描述符
FD_SET(sock_fd,&rset);
//设置超时时间
struct timeval timeout;
timeout.tv_sec = 3;
timeout.tv_usec = 0;
while(1) {
//调用select函数,检测rset数组保存的文件描述符是否已有读事件就绪,返回就绪的文件描述符个数
n = select(max_fd+1, &rset, NULL, NULL, &timeout);
//调用FD_ISSET宏,在rset数组中检测sock_fd对应的文件描述符是否就绪
if (FD_ISSET(sock_fd, &rset)) {
//如果sock_fd已经就绪,表明已有客户端连接;调用accept函数建立连接
conn_fd = accept();
//设置rset数组中位置为conn_fd的文件描述符为1,表示需要监听该文件描述符
FD_SET(conn_fd, &rset);
}
//依次检查已连接套接字的文件描述符
for (i = 0; i < maxfd; i++) {
//调用FD_ISSET宏,在rset数组中检测文件描述符是否就绪
if (FD_ISSET(i, &rset)) {
//有数据可读,进行读数据处理
}
}
}
两个设计上的不足:
1、select 函数对单个进程能监听的文件描述符数量是有限制的,它能监听的文件描述符个数由 __FD_SETSIZE 决定。__FD_SETSIZE 默认值是 1024,__fd_mask 默认32,因此,对于默认情况下的Linux系统,fd_set结构体可以同时支持 1024 * 32 = 32768 个文件描述符,即最多可以同时轮询 32768 个客户端连接。
2、当 select 函数返回后,我们需要遍历描述符集合,才能找到具体是哪些描述符就绪了。这个遍历过程会产生一定开销,从而降低程序的性能。
poll机制与使用
poll函数:
int poll (struct pollfd *__fds, nfds_t __nfds, int __timeout);
参数说明:
1)*__fds 是 pollfd 结构体数组,包含了要监听的描述符,以及该描述符上要监听的事件类型;
2) __nfds 表示的是 *__fds 数组的元素个数;
3) __timeout 表示 poll 函数阻塞的超时时间;
struct pollfd {
int fd; //进行监听的文件描述符
short int events; //要监听的事件类型
short int revents; //实际发生的事件类型
};
事件类型,分别是:POLLRDNORM、POLLWRNORM 和 POLLERR,它们分别表示可读、可写和错误事件。
#define POLLRDNORM 0x040 //可读事件
#define POLLWRNORM 0x100 //可写事件
#define POLLERR 0x008 //错误事件
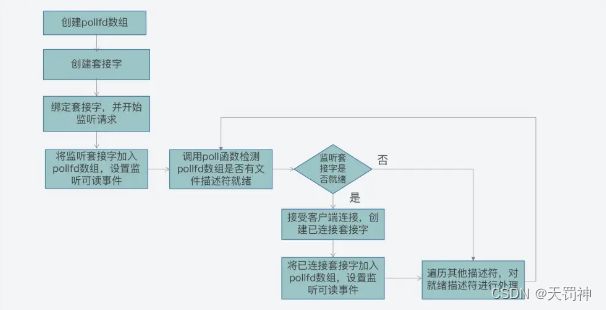
使用 poll 函数完成网络通信:
第一步,创建 pollfd 数组和监听套接字,并进行绑定;
第二步,将监听套接字加入 pollfd 数组,并设置其监听读事件,也就是客户端的连接请求;
第三步,循环调用 poll 函数,检测 pollfd 数组中是否有就绪的文件描述符。
1)如果是连接套接字就绪,这表明是有客户端连接,我们可以调用 accept 接受连接,并创建已连接套接字,并将其加入 pollfd 数组,并监听读事件;
2)如果是已连接套接字就绪,这表明客户端有读写请求,我们可以调用 recv/send 函数处理读写请求。
使用poll函数示例代码
int sock_fd,conn_fd; //监听套接字和已连接套接字的变量
sock_fd = socket() //创建套接字
bind(sock_fd) //绑定套接字
listen(sock_fd) //在套接字上进行监听,将套接字转为监听套接字
//poll函数可以监听的文件描述符数量,可以大于1024
#define MAX_OPEN = 2048
//pollfd结构体数组,对应文件描述符
struct pollfd client[MAX_OPEN];
//将创建的监听套接字加入pollfd数组,并监听其可读事件
client[0].fd = sock_fd;
client[0].events = POLLRDNORM;
maxfd = 0;
//初始化client数组其他元素为-1
for (i = 1; i < MAX_OPEN; i++)
client[i].fd = -1;
while(1) {
//调用poll函数,检测client数组里的文件描述符是否有就绪的,返回就绪的文件描述符个数
n = poll(client, maxfd+1, &timeout);
//如果监听套件字的文件描述符有可读事件,则进行处理
if (client[0].revents & POLLRDNORM) {
//有客户端连接;调用accept函数建立连接
conn_fd = accept();
//保存已建立连接套接字
for (i = 1; i < MAX_OPEN; i++){
if (client[i].fd < 0) {
client[i].fd = conn_fd; //将已建立连接的文件描述符保存到client数组
client[i].events = POLLRDNORM; //设置该文件描述符监听可读事件
break;
}
}
maxfd = i;
}
//依次检查已连接套接字的文件描述符
for (i = 1; i < MAX_OPEN; i++) {
if (client[i].revents & (POLLRDNORM | POLLERR)) {
//有数据可读或发生错误,进行读数据处理或错误处理
}
}
}
与 select 函数相比,poll 函数的改进之处主要就在于,它允许一次监听超过 1024个文件描述符。但是当调用了 poll 函数后,我们仍然需要遍历每个文件描述符,检测该描述符是否就绪,然后再进行处理。
epoll机制与使用
epoll 机制是使用 epoll_event 结构体,来记录待监听的文件描述符及其监听的事件类型的,这和 poll 机制中使用 pollfd 结构体比较类似。
typedef union epoll_data
{
...
int fd; //记录文件描述符
...
} epoll_data_t;
epoll_data_t 联合体中有记录文件描述符的成员变量 fd;
struct epoll_event
{
uint32_t events; //epoll监听的事件类型
epoll_data_t data; //应用程序数据
};
epoll_data_t :如上。
events :会取值使用不同的宏定义值来表示 epoll_data_t 变量中的文件描述符所关注的事件类型。
EPOLLIN:读事件,表示文件描述符对应套接字有数据可读。
EPOLLOUT:写事件,表示文件描述符对应套接字有数据要写。
EPOLLERR:错误事件,表示文件描述符对于套接字出错。
我们在使用 epoll 机制时,就不用像使用 select 和 poll 一样,遍历查询哪些文件描述符已经就绪了。这样一来, epoll 的效率就比 select 和 poll 有了更高的提升。
在创建了 epoll 实例后,我们需要再使用 epoll_ctl 函数,给被监听的文件描述符添加监听事件类型,以及使用 epoll_wait 函数获取就绪的文件描述符。
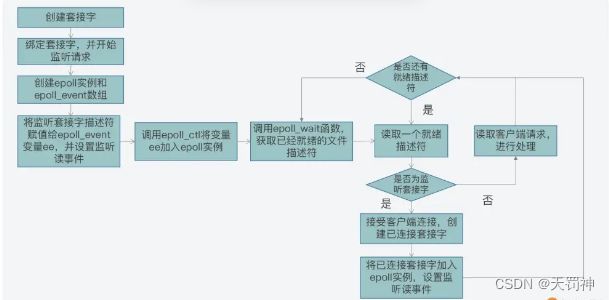
int sock_fd,conn_fd; //监听套接字和已连接套接字的变量
sock_fd = socket() //创建套接字
bind(sock_fd) //绑定套接字
listen(sock_fd) //在套接字上进行监听,将套接字转为监听套接字
epfd = epoll_create(EPOLL_SIZE); //创建epoll实例,
//创建epoll_event结构体数组,保存套接字对应文件描述符和监听事件类型
ep_events = (epoll_event*)malloc(sizeof(epoll_event) * EPOLL_SIZE);
//创建epoll_event变量
struct epoll_event ee
//监听读事件
ee.events = EPOLLIN;
//监听的文件描述符是刚创建的监听套接字
ee.data.fd = sock_fd;
//将监听套接字加入到监听列表中
epoll_ctl(epfd, EPOLL_CTL_ADD, sock_fd, &ee);
while (1) {
//等待返回已经就绪的描述符
n = epoll_wait(epfd, ep_events, EPOLL_SIZE, -1);
//遍历所有就绪的描述符
for (int i = 0; i < n; i++) {
//如果是监听套接字描述符就绪,表明有一个新客户端连接到来
if (ep_events[i].data.fd == sock_fd) {
conn_fd = accept(sock_fd); //调用accept()建立连接
ee.events = EPOLLIN;
ee.data.fd = conn_fd;
//添加对新创建的已连接套接字描述符的监听,监听后续在已连接套接字上的读事件
epoll_ctl(epfd, EPOLL_CTL_ADD, conn_fd, &ee);
} else { //如果是已连接套接字描述符就绪,则可以读数据
...//读取数据并处理
}
}
}
三、线程模型的历史发展
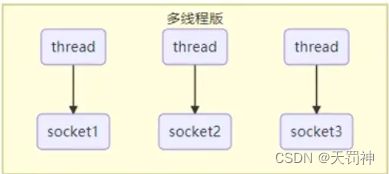
多线程版设计
一个线程管理一个socket连接。
多线程版缺点
- 内存占用高
- 线程上下文切换成本高
- 只适合连接数少的场景
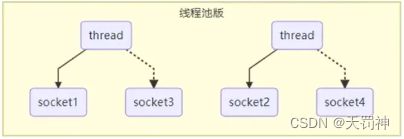
线程池版设计
一个线程管理多个socket连接。
线程池版缺点
- 阻塞模式下,线程仅能处理一个 socket 连接
- 仅适合短连接场景
selector 版设计
selector 的作用就是配合一个线程来管理多个 channel,获取这些 channel 上发生的事件,这些 channel 工作在非阻塞模式下,不会让线程吊死在一个 channel 上。适合连接数特别多,但流量低的场景(low traffic)
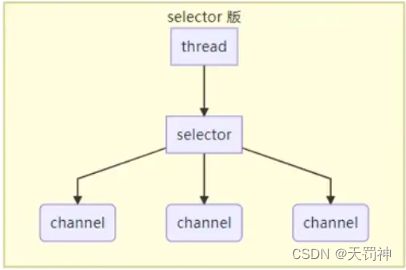
调用 selector 的 select() 会阻塞直到 channel 发生了读写就绪事件,这些事件发生,select 方法就会返回这些事件交给 thread 来处理。
四、Reactor模型的理论
工作机制
Reactor 模型就是网络服务器端用来处理高并发网络 IO 请求的一种编程模型。
这个模型的特征用两个“三”来总结,也就是:
1、三类处理事件,即连接事件、写事件、读事件;
2、三个关键角色,即 reactor、acceptor、handler。
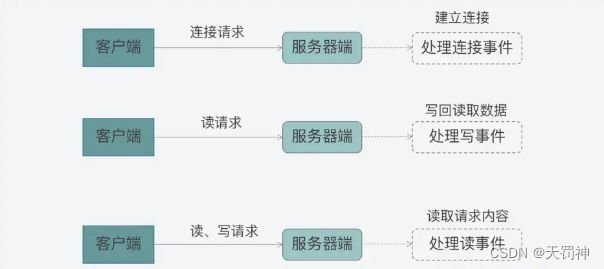
三类处理事件
1、连接事件:当一个客户端要和服务器端进行交互时,客户端会向服务器端发送连接请求,以建立连接,这就对应了服务器端的一个连接事件。
2、写事件:一旦连接建立后,客户端会给服务器端发送读请求,以便读取数据。服务器端在处理读请求时,需要向客户端写回数据,这对应了服务器端的写事件。
3、读事件:无论客户端给服务器端发送读或写请求,服务器端都需要从客户端读取请求内容,所以在这里,读或写请求的读取就对应了服务器端的读事件。

三个关键角色:(这三类事件是由谁来处理的呢?)
1、首先,连接事件由 acceptor 来处理,负责接收连接;acceptor 在接收连接后,会创建handler,用于网络连接上对后续读写事件的处理;
2、其次,读写事件由 handler 处理;
3、最后,在高并发场景中,连接事件、读写事件会同时发生,所以,我们需要有一个角色专门监听和分配事件,这就是 reactor 角色。当有连接请求时,reactor 将产生的连接事件交由 acceptor 处理;当有读写请求时,reactor 将读写事件交由 handler 处理。
事件驱动框架
(又该如何实现这三者的交互呢?这就离不开事件驱动框架)
事件驱动框架包括了两部分:一是事件初始化;二是事件捕获、分发和处理主循
环。

1、事件初始化是在服务器程序启动时就执行的,它的作用主要是创建需要监听的事件类型,以及该类事件对应的 handler。
2、初始化后服务器程序就需要进入到事件捕获、分发和处理的主循环中,在开发代码时,我们通常会用一个 while 循环作为这个主循环,循环中需要捕获发生的事件、判断事件类型,并根据事件类型,调用在初始化时创建好的事
件 handler 来实际处理事件。
五、Reactor模型的实现
Reactor 模型中有 2 个关键组成:
- Reactor,Reactor 在一个单独的线程中运行,负责监听和分发事件,分发给适当的处理程序来对 IO 事件做出反应。它就像公司的电话接线员,它接听来自客户的电话并将线路转移到适当的联系人。
- Handlers,处理程序执行 I/O 事件要完成的实际事件,类似于客户想要与之交谈的公司中的实际官员。Reactor 通过调度适当的处理程序来响应 I/O 事件,处理程序执行非阻塞操作。
可以这样理解,Reactor 就是一个执行 while (true) { selector.select(); …} 循环的线程,会源源不断的产生新的事件,称作反应堆很贴切。
取决于 Reactor 的数量和 Hanndler 线程数量的不同,Reactor 模型有 3 个变种:
Reactor单线程模型
最简单的Reactor单线程模型,由于Reactor模式使用的是异步非阻塞IO,所有的IO操作都不会被阻塞,理论上一个线程可以独立处理所有的IO操作。这时Reactor线程是个多面手,负责多路分离套接字,Accept新连接,并分发请求到处理链中。
Reactor多线程模型
该模型在处理链部分采用了多线程(线程池)。在绝大多数场景下,该模型都能满足性能需求。但是,在一些特殊的应用场景下,如服务器会对客户端的握手消息进行安全认证。这类场景下,单独的一个Acceptor线程可能会存在性能不足的问题。为了解决这些问题,产生了第三种Reactor线程模型;
Reactor主从模型
该模型相比第二种模型,是将Reactor分成两部分,mainReactor负责监听server socket,accept新连接;并将建立的socket分派给subReactor。subReactor负责多路分离已连接的socket,读写网络数据,对业务处理功能,其扔给worker线程池完成。通常,subReactor个数上可与CPU个数等同。
1) Selector
Selector即为NIO中提供的SelectableChannel多路复用器,充当着demultiplexer的角色。
2) EventLoopGroup/EventLoop
当系统在运行过程中,如果频繁的进行线程上下文切换,会带来额外的性能损耗。多线程并发执行某个业务流程,业务开发者还需要时刻对线程安全保持警惕,哪些数据可能会被并发修改,如何保护?这不仅降低了开发效率,也会带来额外的性能损耗。
为了解决上述问题,Netty采用了串行化设计理念,从消息的读取、编码以及后续Handler的执行,始终都由IO线程EventLoop负责,这就意外着整个流程不会进行线程上下文的切换,数据也不会面临被并发修改的风险。这也解释了为什么Netty线程模型去掉了Reactor主从模型中线程池。
EventLoopGroup是一组EventLoop的抽象,EventLoopGroup提供next接口,可以总一组EventLoop里面按照一定规则获取其中一个EventLoop来处理任务,对于EventLoopGroup这里需要了解的是在Netty中,在Netty服务器编程中我们需要BossEventLoopGroup和WorkerEventLoopGroup两个EventLoopGroup来进行工作。通常一个服务端口即一个ServerSocketChannel对应一个Selector和一个EventLoop线程,也就是说BossEventLoopGroup的线程数参数为1。BossEventLoop负责接收客户端的连接并将SocketChannel交给WorkerEventLoopGroup来进行IO处理。
EventLoop的实现充当Reactor模式中的分发(Dispatcher)的角色。
3) ChannelPipeline
ChannelPipeline其实是担任着Reactor模式中的请求处理器这个角色。
ChannelPipeline的默认实现是DefaultChannelPipeline,DefaultChannelPipeline本身维护着一个用户不可见的tail和head的ChannelHandler,他们分别位于链表队列的头部和尾部。tail在更上层的部分,而head在靠近网络层的方向。在Netty中关于ChannelHandler有两个重要的接口,ChannelInBoundHandler和ChannelOutBoundHandler。inbound可以理解为网络数据从外部流向系统内部,而outbound可以理解为网络数据从系统内部流向系统外部。用户实现的ChannelHandler可以根据需要实现其中一个或多个接口,将其放入Pipeline中的链表队列中,ChannelPipeline会根据不同的IO事件类型来找到相应的Handler来处理,同时链表队列是责任链模式的一种变种,自上而下或自下而上所有满足事件关联的Handler都会对事件进行处理。
ChannelInBoundHandler对从客户端发往服务器的报文进行处理,一般用来执行半包/粘包,解码,读取数据,业务处理等;ChannelOutBoundHandler对从服务器发往客户端的报文进行处理,一般用来进行编码,发送报文到客户端。
Netty是哪一种呢?
在JAVA NIO方面Selector给Reactor模式提供了基础,Netty结合Selector和Reactor模式设计了高效的线程模型。Netty 主要基于主从 Reactors 多线程模型做了一定的修改。