最优化方法之梯度下降法和牛顿法
大部分的机器学习算法的本质都是建立优化模型,通过最优化方法对目标函数(或损失函数)进行优化,从而训练出最好的模型。最常见的最优化方法有梯度下降法、牛顿法。
最优化方法:
最优化方法,即寻找函数极值点的数值方法。通常采用的是迭代法,它从一个初始点x0开始,反复使用某种规则从x.k 移动到下一个点x.k+1,直至到达函数的极值点。这些规则一般会利用一阶导数信息即梯度, 或者二阶导数信息即Hessian 矩阵。算法的依据是寻找梯度值为0 的点,因为根据极值定理,在极值点处函数的梯度必须为0 。
1. 梯度下降法
梯度下降法是最早最简单,也是最为常用的最优化方法。梯度下降法实现简单,当目标函数是凸函数时,梯度下降法的解是全局解。一般情况下,其解不保证是全局最优解,梯度下降法的速度也未必是最快的。梯度下降法的优化思想是用当前位置负梯度方向作为搜索方向,因为该方向为当前位置的最快下降方向,所以也被称为是”最速下降法“。最速下降法越接近目标值,步长越小,前进越慢。梯度下降法的搜索迭代示意图如下图所示:

梯度下降法的缺点:
(1)靠近极小值时收敛速度减慢,如下图所示;
(2)直线搜索时可能会产生一些问题;
(3)可能会“之字形”地下降

从上图可以看出,梯度下降法在接近最优解的区域收敛速度明显变慢,利用梯度下降法求解需要很多次的迭代。
公式推理过程:


根据多元函数的泰勒展开公式,如果忽略二次及以上的项,函数f(x) 在x 点处可以展开为:

变形之后,函数的增量与自变量的增量函数梯度的关系可以表示为:

如果能保证

则有:
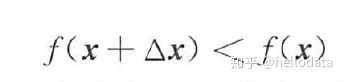
即函数值递减。选择合适的增量 就能保证函数值下降。
可以证明,当

即在梯度相反的方向函数值下降的最快。设

其中, y 为一个接近于0 的正数,称为步长,由人工设定,用于保证

在x 的邻域内,从而可以忽略泰勒展开中二次及更高的项
从初始点x0开始,使用如下迭代公式:

只要没有到达梯度为0 的点,函数值会沿着序列xk 递减,最终会收敛到梯度为0 的点,这就是梯度下降法。迭代终止的条件是函数的梯度值为0 ( 实际实现时是接近于0 ) ,此时认为已经达到极值点。梯度下降法只需要计算函数在某些点处的梯度,实现简单,计算量小。



2.牛顿法
基本思想
用一个二次函数去近似目标函数f(x),然后精确地求出这个二次函数的极小点.



根据极值定理,函数在点x* 处取得极值的必要条件是导数(对于多元函数是梯度)为
0 ,即

称x*为函数的驻点。可以通过寻找函数的驻点求解函数的极值。
对多元函数在x。处进行二阶泰勒展开,有
![]()
忽略二次及以上的项,将函数近似成二次函数,并对上式两边同时对x 求梯度,得到函
数的导数(梯度向量)为

其中,

即为Hessian 矩阵H 。令函数的梯度为0 ,则有

解这个线性方程组可以得到:

如果将梯度向量简写为g ,上面的公式可以简写为

由于在泰勒展开中忽略了高阶项,因此,这个解并不一定是函数的驻点,需要反复用这
个公式进行迭代。从初始点Xo 处开始,反复计算函数在处的Hessian 矩阵和梯度向量,然
后用下面的公式进行迭代:
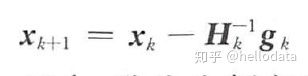
最终会到达函数的驻点。

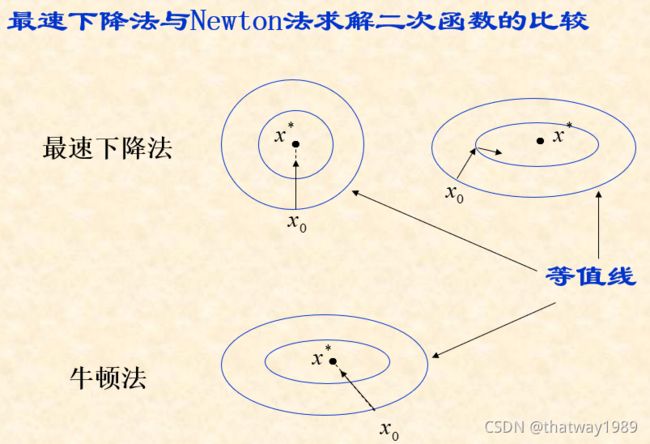
3、两者比较
关于牛顿法和梯度下降法的效率对比:
从本质上去看,牛顿法是二阶收敛,梯度下降是一阶收敛,所以牛顿法就更快。如果更通俗地说的话,比如你想找一条最短的路径走到一个盆地的最底部,梯度下降法每次只从你当前所处位置选一个坡度最大的方向走一步,牛顿法在选择方向时,不仅会考虑坡度是否够大,还会考虑你走了一步之后,坡度是否会变得更大。所以,可以说牛顿法比梯度下降法看得更远一点,能更快地走到最底部。(牛顿法目光更加长远,所以少走弯路;相对而言,梯度下降法只考虑了局部的最优,没有全局思想。)
根据wiki上的解释,从几何上说,牛顿法就是用一个二次曲面去拟合你当前所处位置的局部曲面,而梯度下降法是用一个平面去拟合当前的局部曲面,通常情况下,二次曲面的拟合会比平面更好,所以牛顿法选择的下降路径会更符合真实的最优下降路径。

牛顿法的优缺点总结:
优点:二阶收敛,收敛速度快;
缺点:牛顿法是一种迭代算法,每一步都需要求解目标函数的Hessian矩阵的逆矩阵,计算比较复杂。