【机器学习】模型的综合评判,备选模型和幸运模型
一、介绍
在快速发展的机器学习(ML)领域,模型的持续开发和部署对于技术进步和实际应用至关重要。这个生命周期的两个关键阶段是“候选模型”和“祝福模型”。对于任何参与机器学习的人来说,从数据科学家和工程师到依赖这些技术的企业的利益相关者,理解这些阶段都至关重要。本文深入探讨了机器学习工作流程中候选模型和祝福模型之间的特征、重要性以及差异。
机器学习的每一次伟大旅程都始于创新的一步,并以值得信赖的性能的进步而达到顶峰。从候选模型到受祝福的模型的道路证明了这种对卓越的持久追求。
二、背景
术语“候选模型”和“幸运模型”用于机器学习中,特别是在模型开发、测试和部署的背景下。
- 候选模型:候选模型是正在考虑部署的新开发或更新的机器学习模型。它通常处于测试或评估阶段,评估其性能。在此阶段,模型将接受各种测试,包括性能指标(如准确性、精确度、召回率)、鲁棒性、公平性评估和真实场景模拟。它被称为“候选者”,因为它是替换当前部署模型的竞争者,但尚未批准用于生产用途。
- 幸运模型:术语“幸运模型”是指已经通过所有必要的评估和测试,并已被批准在生产环境中部署的机器学习模型。根据其测试的性能指标,该模型被认为是稳定、可靠和有效的。它是“有福的”,因为它已被认可或批准使用。在生产环境中,受祝福的模型是当前提供预测或执行其设计任务的模型。
从候选模型到幸运模型的过渡涉及严格的测试,以确保新模型比现有模型表现更好或更高效,而不会引入新问题或偏差。这个过程对于维持和提高现实场景中机器学习应用程序的质量至关重要。
2.1 候选模型
创新的试验场候选模型代表了机器学习创新的前沿。它本质上是一个原型,通常是为了改进或替换现有模型而开发的。这一阶段的特点是实验,应用新的算法、数据集和调优技术。候选模型是实践中的假设,旨在通过严格的测试和验证来证明其价值。
评估候选模型的过程是多方面的。它涉及评估准确性、效率、可扩展性和公平性。候选模型可能会根据历史数据进行测试,进行压力测试,或评估偏见和道德影响。此阶段至关重要,因为它决定模型是否已准备好用于实际应用。然而,这也是一个充满挑战的阶段。过度拟合、欠拟合以及保持模型复杂性和泛化性之间的平衡是需要克服的常见障碍。
2.2 幸运的模型
机器学习可靠性的顶峰 一旦候选模型成功通过评估和测试的考验,它就会提升到受祝福模型的状态。这是被组织“祝福”部署在生产环境中的模型。它证明了该模型的可靠性、有效性以及处理现实世界任务的能力。
从候选人到受祝福的模特的转变意义重大。它不仅表明了技术优势,还表明了对模型持续且合乎道德地执行能力的信任和信心程度。幸运模型成为衡量所有新候选模型的标准。它是现任冠军,一直保持其地位,直到出现更好的候选模型来挑战其霸主地位。
2.3 对比分析
从候选模型到幸运模型的旅程从候选模型到幸运模型的旅程是严格测试、验证和改进的叙述。候选模型是关于探索和突破界限的,而幸运模型是关于稳定性和可靠性的。候选模型是创新的,但未经验证,而幸运模型是经过验证且值得信赖的。
这种转变不仅仅是一个技术过程,还涉及观念的转变。利益相关者必须对模型在现实场景中执行的能力充满信心,而不会产生不可预见的后果。这不仅需要技术验证,还需要透明度、道德考虑,有时甚至需要遵守法规。
三、代码
使用合成数据集和绘图创建完整的 Python 代码来演示候选模型与幸运模型的概念涉及几个步骤。我们将创建一个综合数据集,构建两个不同的机器学习模型(一个作为候选模型,另一个作为祝福模型),比较它们的性能,并将结果可视化。
让我们继续使用一个简单的合成数据集进行分类并使用两个不同的模型进行演示的示例。我将使用 Python 的scikit-learn库来构建模型和matplotlib绘图。
生成综合数据集:我们将创建一个简单的二元分类数据集。
构建两个不同的模型:一个将是我们的候选模型,另一个将是我们的幸运模型。
- 评估模型:我们将使用准确度、精确度和召回率等指标来评估两个模型的性能。
- 绘图:我们将创建绘图来可视化性能差异。
首先,我们首先编写代码来生成合成数据集并构建模型:
```python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
# Generate a synthetic dataset
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2, random_state=42)
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Model 1 (Candidate Model): Logistic Regression
candidate_model = LogisticRegression(random_state=42)
candidate_model.fit(X_train, y_train)
candidate_predictions = candidate_model.predict(X_test)
# Model 2 (Blessed Model): Random Forest Classifier
blessed_model = RandomForestClassifier(random_state=42)
blessed_model.fit(X_train, y_train)
blessed_predictions = blessed_model.predict(X_test)
# Evaluation
candidate_accuracy = accuracy_score(y_test, candidate_predictions)
candidate_precision = precision_score(y_test, candidate_predictions)
candidate_recall = recall_score(y_test, candidate_predictions)
blessed_accuracy = accuracy_score(y_test, blessed_predictions)
blessed_precision = precision_score(y_test, blessed_predictions)
blessed_recall = recall_score(y_test, blessed_predictions)
# Plotting performance
labels = ['Accuracy', 'Precision', 'Recall']
candidate_scores = [candidate_accuracy, candidate_precision, candidate_recall]
blessed_scores = [blessed_accuracy, blessed_precision, blessed_recall]
x = np.arange(len(labels))
width = 0.35
fig, ax = plt.subplots()
rects1 = ax.bar(x - width/2, candidate_scores, width, label='Candidate Model')
rects2 = ax.bar(x + width/2, blessed_scores, width, label='Blessed Model')
ax.set_ylabel('Scores')
ax.set_title('Scores by model and metric')
ax.set_xticks(x)
ax.set_xticklabels(labels)
ax. Legend()
plt.show()
该代码将执行以下操作:
- 为二元分类任务生成合成数据集。
- 将数据集分为训练集和测试集。
- 训练两个不同的模型:逻辑回归作为候选模型,随机森林作为祝福模型。
- 使用准确度、精确度和召回率在测试集上评估这些模型。
- 绘制结果以进行直观比较。
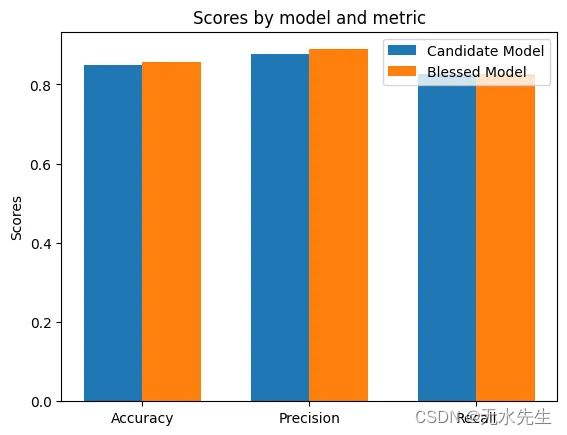
此示例是一个基本说明。在现实场景中,选择幸运模型的过程将涉及更复杂的数据、更全面的模型评估(包括交叉验证),并考虑模型可解释性、计算效率和现实世界适用性等其他因素。
四、结论
机器学习模型的动态生命周期 总之,候选模型和幸运模型的概念不仅仅代表机器学习模型生命周期的阶段。它们体现了该领域的动态本质——创新、测试、验证和部署的持续循环。对于参与机器学习技术开发和应用的任何人来说,理解并有效管理这个周期都至关重要。这是一个确保在不断变化的技术环境中不断改进和适应的过程,今天的幸运模型是明天的改进候选者。