使用一个定时器(timer_fd)管理多个定时事件
使用一个定时器(timer_fd)管理多个定时事件
使用 timerfd_xxx 系列函数可以很方便的与 select、poll、epoll 等IO复用函数相结合,实现基于事件的定时器功能。大体上有两种实现思路:
- 为每个定时事件创建一个 timer_fd,绑定对应的定时回调函数,然后将 timer_fd 注册到 epoll(或其它IO复用函数)中,当 timer_fd 可读,调用其回调函数,然后关闭该文件描述符。
- 只创建一个 timer_fd。管理所有定时事件,timer_fd 每次只关注时间序列上下一个将要超时的时间,当 timer_fd 变得可读,从管理的所有定时事件中查找比 timer_fd 可读时刻小的定时事件,然后执行对应的回调函数。
这两种方法中,第一种实现起来相对简单,但一个定时事件就对应一个文件描述符,当定时事件较少且创建周期不频繁时,该方法没啥问题;但当定时事件较多,且定时事件的创建和销毁频繁时,会导致文件描述符的频繁创建和关闭,影响服务器性能。第二种方法只使用一个 timer_fd 来管理所有定时事件,能避免文件描述符频繁创建和关闭带来的系统影响,但在实现上相对复杂,关键在于如何高效地管理所有还未超时的定时事件。
下面将具体介绍第二种方法的实现思路和一些实现上的细节,该思路主要来自 muduo 网络库的实现,我尝试对其进行了一点点改进,并将思考一并写在下文。
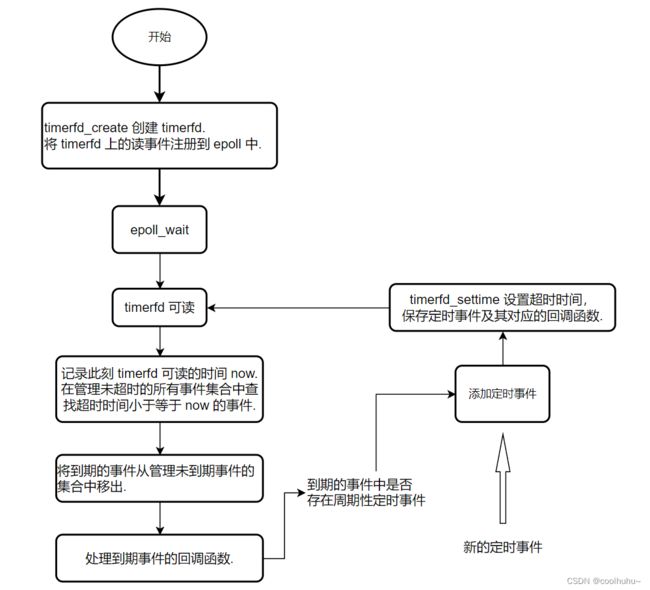
使用 timerfd_xxx 和 epoll 实现定时器的功能的主要逻辑如下面的流程图所示,一图胜千言,不再过多的文字解释。
下面介绍一些实现上的细节。
选用什么样的数据结构管理定时事件?对于定时事件的添加、删除和查找,要高效。因为只使用一个 timerfd 来管理多个定时事件,而 timerfd 每次只能关注一个超时时间,若每新添加一个定时事件,就调用 timerfd_settime 设置超时事件,会使前面的定时事件失效。因此一个自然的想法是,根据定时事件的超时时间从小到大排序,timerfd 每次只关注所有定时事件中超时时间最小的哪个时间。可以使用C++标准库中的 set 或 map 来管理定时事件,它们是有序集合,底层的数据结构为红黑树,插入、删除和查找的平均时间复杂度都为 O(log N),muduo 中就是使用 set 来管理定时事件的。
muduo 中的做法是,使用 set 来管理定时事件,set 中的元素类型为 pair。书中给出了采用这种做法的原因:
“不能直接用 map,因为这样无法处理两个Timer到期时间相同的情况。有两个解决方案,一是用 multimap 或 multiset,二是设法区分key。muduo现在采用的是第二种做法,这样可以避免使用不常见的 multimap class。具体来说,以 pair 为key,这样即便两个Timer的到期时间相同,它们的地址也必定不同。”
我在写定时器这部分功能时,采用的是 muduo 中提到的第二种方法,使用 multimap 管理定时事件。muduo 中 Timestamp 的精度为微妙,我的实现中 Timestamp 的精度为纳秒,因此几乎不可能存在两个 Timer 到期事件相同的情况,即便存在两个 Timer 到期的 Timestamp 相同,也无妨紧要,因为我在 Timer 类中添加了 TimerId 成员变量,用来唯一标识 Timer,可以通过成员函数来获取该标识。
如下TimerId、Timer和TimerQueue类的定义所示,TimerQueue中的 activeTimers_ 成员变量为 set 类型,其元素为 TimerId 类型,而 Timer 中具有获取 TimerId 成员变量的成员函数,因此在 TimerQueue 类中,timers_、activeTimers_ 和 cancelingTimers_ 三个成员变量可以很方便地进行相互转换查找。
class TimerId
{
public:
friend class TimerQueue;
public:
TimerId(): id_(0), timer_(nullptr) {}
TimerId(int64_t id, Timer* timer): id_(id), timer_(timer) {}
// ...
private:
int64_t id_;
Timer* timer_;
};
class Timer
{
public:
Timer(TimerCallback cb, Timestamp when, Seconds interval)
: callback_(std::move(cb)), expiration_(when),
interval_(interval), repeat_(interval_ > 0.0),
id_(++timerCount_, this)
{}
// ...
private:
TimerCallback callback_;
Timestamp expiration_;
Seconds interval_;
bool repeat_;
const TimerId id_; // 定时器唯一标识
static std::atomic_int64_t timerCount_;
};
class TimerQueue
{
public:
using TimerMap = std::multimap<Timestamp, std::unique_ptr<Timer>>;
using TimerVector = std::vector<std::unique_ptr<Timer>>;
using ActiveTimer = std::set<TimerId>;
explicit TimerQueue(EventLoop *loop);
// ...
private:
EventLoop *loop_;
int timerfd_;
Channel timerChannle_;
TimerMap timers_;
ActiveTimer activeTimers_;
std::set<Timer*> cancelingTimers_;
std::atomic_bool callingExpiredTimers_;
};
在确定了管理定时事件的数据结构后,按照上述所给的定时事件的处理流程来编写代码即可。在实现细节上,muduo 源码中对于上层应用删除一个定时器的实现,我觉得处理的很到位,在这里单独拿出来描述。
定时器对上层提供的接口无非就两类,一类是添加一个定时事件,另一类则是删除一个定时事件。添加一个定时事件的处理相比于删除一个定时事件要简单些,只需往 TimerMap 中插入一个 Timer 即可,然后判断一下添加的 Timer 的超时时间是否小于当前设置的超时时间,若小于则更新定时器的超时时间。这一步的实现很简单,因为 TimerMap 为 map 类型,只需 O(1) 的时间复杂度即可完成。
而对于删除一个定时事件,要复杂一些。
首先,对于定时事件超时,在处理完定时事件上的回调函数后,若超时的定时事件不是周期性的,需要能够自动删除。我通过 unique_ptr 来实现定时事件的自动删除,这也是 muduo 中提到的改进方法。当有定时事件发生,将超时的事件从 TimerMap move 到一个 vector 中,然后处理超时事件的回调函数,处理完后,若是周期性事件,则将其再次 move 到 TimerMap 中,若不是周期性事件,则什么都不用做,unique_ptr 管理的 Timer 会自动随着 vector 的析构而析构。
其次,对于上层调用删除指定实时事件,需要考虑这样一种场景,当具有周期性的定时事件超时后,且
正在处理定时事件的回调函数 时,上层应用调用删除指定定时事件的函数,且这个待删除的定时事件为正在超时处理的周期性定时事件。此时就不能简单的直接根据超时的定时事件为周期性事件就再次将其添加回 TimerMap 中,要同时判断其是否正在被删除。这也是为什么在 TimerQueue 类中需要具有一个 cancelingTimers_ 和 callingExpiredTimers_ 成员变量的原因,也是 muduo 中处理很巧妙的一部分。
具体的实现思路为:
- 使用 callingExpiredTimers_ 成员变量标识是否正在处理超时事件的回调函数。
callingExpiredTimers_ = true; cancelingTimers_.clear(); // 处理超时事件的回调函数 for (const auto& iter : expirationTimers) { iter->run(); } callingExpiredTimers_ = false; - 在上层应用调用删除定时事件的函数时,若删除的定时事件已超时,且正在执行超时回调函数,则将其添加到 cancelingTimers_ 中。
// 若定时事件未超时,则可以直接从 TimerMap 中删除 if (iter != activeTimers_.end()) { // ... } // 若删除的定时事件已超时,且正在执行超时回调函数 else if (callingExpiredTimers_) { cancelingTimers_.emplace(timer); } - 判断是否需要将超时的定时事件重新添加回 TimerMap 中。
// 超时的定时事件为周期性事件,且没有被删除,则重新添加回 TimerMap 中 if (timer->repeat() && cancelingTimers_.find(t) == cancelingTimers_.end()) { timer->restart(when); insert(std::move(timer)); }
我的实现采用了 muduo 中的实现方法,只不过我采用的是 multimap 来管理定时事件,在实现的细节上会有一些差别。此外,对于上述给出的 TimerQueue 类的定义,还可以有一些改进,将 activeTimers_ 和 cancelingTimers_ 成员变量改为 unordered_set 类型,查找删除的平均时间复杂度可以从 O(logN) 降到 O(1),不过需要自定义 hash 函数。留作为后续改进。