最小堆原理与实现
基本概念:
1、完全二叉树:若二叉树的深度为h,则除第h层外,其他层的结点全部达到最大值,且第h层的所有结点都集中在左子树。
2、满二叉树:满二叉树是一种特殊的的完全二叉树,所有层的结点都是最大值。
定义:
1、堆是一颗完全二叉树;
2、堆中的某个结点的值总是大于等于(最大堆)或小于等于(最小堆)其孩子结点的值。
3、堆中每个结点的子树都是堆树。
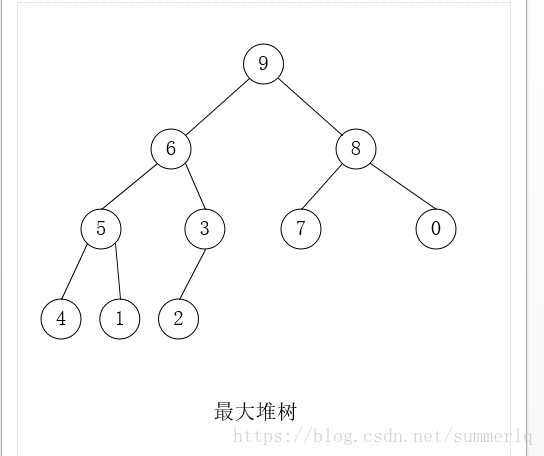

最大堆,最小堆类似,以下以最小堆为例进行讲解。
最小堆是满足以下条件的数据结构:
它是一棵完全二叉树;
所有父节点的值小于或等于两个子节点的值;
TOP K问题 :Top K指的是从n(很大)个数据中,选取最大(小)的k个数据。例如学校要从全校学生中找到成绩最高的500名学生,再例如某搜索引擎要统计每天的100条搜索次数最多的关键词。
堆排序解决TOP K
对于TOPK问题,解决方法有很多:
方法一:对源数据中所有数据进行排序,取出前K个数据,就是TopK。
但是当数据量很大时,只需要k个最大的数,整体排序很耗时,效率不高。
方法二:维护一个K长度的数组a[],先读取源数据中的前K个放入数组,对该数组进行升序排序,再依次读取源数据第K个以后的数据,和数组中最小的元素(a[0])比较,如果小于a[0]直接pass,大于的话,就丢弃最小的元素a[0],利用二分法找到其位置,然后该位置前的数组元素整体向前移位,直到源数据读取结束。
这比方法一效率会有很大的提高,但是当K的值较大的时候,长度为K的数据整体移位,也是非常耗时的。
对于这种问题,效率比较高的解决方法是使用最小堆。
最小堆思路
最小堆(小根堆)是一种数据结构,它首先是一棵完全二叉树,并且,它所有父节点的值小于或等于两个子节点的值。
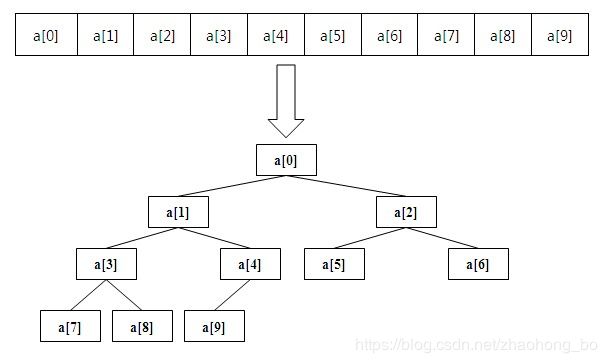
最小堆的存储结构(物理结构)实际上是一个数组。如下图:
堆有几个重要操作:
BuildHeap:将普通数组转换成堆,转换完成后,数组就符合堆的特性:所有父节点的值小于或等于两个子节点的值。
Heapify(int i):当元素i的左右子树都是小根堆时,通过Heapify让i元素下降到适当的位置,以符合堆的性质。
回到上面的取TopK问题上,用最小堆的解决方法就是:先去源数据中的K个元素放到一个长度为K的数组中去,再把数组转换成最小堆。再依次取源数据中的K个之后的数据和堆的根节点(数组的第一个元素)比较,根据最小堆的性质,根节点一定是堆中最小的元素,如果小于它,则直接pass,大于的话,就替换掉跟元素,并对根元素进行Heapify,直到源数据遍历结束。
最小堆解决TOPK
最小堆的实现:
public class MinHeap
{
// 堆的存储结构 - 数组
private int[] data;
// 将一个数组传入构造方法,并转换成一个小根堆
public MinHeap(int[] data)
{
this.data = data;
buildHeap();
}
// 将数组转换成最小堆
private void buildHeap()
{
// 完全二叉树只有数组下标小于或等于 (data.length) / 2 - 1 的元素有孩子结点,遍历这些结点。
// *比如上面的图中,数组有10个元素, (data.length) / 2 - 1的值为4,a[4]有孩子结点,但a[5]没有*
for (int i = (data.length) / 2 - 1; i >= 0; i--)
{
// 对有孩子结点的元素heapify
heapify(i);
}
}
private void heapify(int i)
{
// 获取左右结点的数组下标
int l = left(i);
int r = right(i);
// 这是一个临时变量,表示 跟结点、左结点、右结点中最小的值的结点的下标
int smallest = i;
// 存在左结点,且左结点的值小于根结点的值
if (l < data.length && data[l] < data[i])
smallest = l;
// 存在右结点,且右结点的值小于以上比较的较小值
if (r < data.length && data[r] < data[smallest])
smallest = r;
// 左右结点的值都大于根节点,直接return,不做任何操作
if (i == smallest)
return;
// 交换根节点和左右结点中最小的那个值,把根节点的值替换下去
swap(i, smallest);
// 由于替换后左右子树会被影响,所以要对受影响的子树再进行heapify
heapify(smallest);
}
// 获取右结点的数组下标
private int right(int i)
{
return (i + 1) << 1;
}
// 获取左结点的数组下标
private int left(int i)
{
return ((i + 1) << 1) - 1;
}
// 交换元素位置
private void swap(int i, int j)
{
int tmp = data[i];
data[i] = data[j];
data[j] = tmp;
}
// 获取对中的最小的元素,根元素
public int getRoot()
{
return data[0];
}
// 替换根元素,并重新heapify
public void setRoot(int root)
{
data[0] = root;
heapify(0);
}
}利用最小堆获取TopK:
public class TopK
{
public static void main(String[] args)
{
// 源数据
int[] data = {56,275,12,6,45,478,41,1236,456,12,546,45};
// 获取Top5
int[] top5 = topK(data, 5);
for(int i=0;i<5;i++)
{
System.out.println(top5[i]);
}
}
// 从data数组中获取最大的k个数
private static int[] topK(int[] data,int k)
{
// 先取K个元素放入一个数组topk中
int[] topk = new int[k];
for(int i = 0;i< k;i++)
{
topk[i] = data[i];
}
// 转换成最小堆
MinHeap heap = new MinHeap(topk);
// 从k开始,遍历data
for(int i= k;i root)
{
heap.setRoot(data[i]);
}
}
return topk;
}
} 最小堆的删除操作
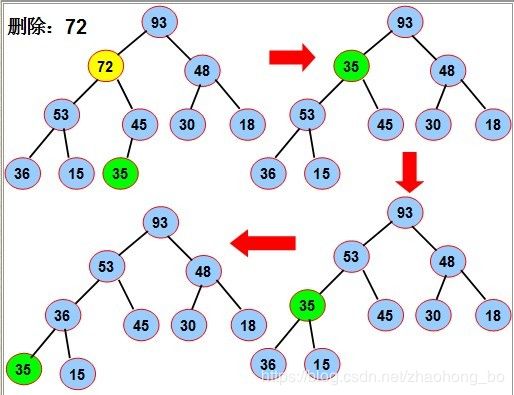
前面在介绍最小堆解决TOPK问题的时候,已经涉及到建堆、添加元素的过程,接下来介绍最小堆的删除过程。
操作原理是:当删除节点的数值时,原来的位置就会出现一个孔,填充这个孔的方法就是,
把最后的叶子的值赋给该孔并下调到合适位置,最后把该叶子删除。
如图中要删除72,先用堆中最后一个元素来35替换72,再将35下沉到合适位置,最后将叶子节点删除。
“结点下沉”