快乐学Python,如何对数据进行清洗?(缺失值处理和重复值删除)
上一篇文章中,我们介绍了通过pandas读取数据到DataFrame中之后,对DataFrame中数据的操作方式,这篇文章我们继续来介绍:数据清洗。即:当读取的数据出现缺失或异常时,我们如何对缺失的数据进行预处理。
1、缺失值是什么?
当我们从数据文件(CSV、Excel等)或者其他数据源加载到 DataFrame 中时,往往会遇到某些单元格的数据是缺失的。当我们打印出 DataFrame 时,缺失的部分会显示为 NaN, 或者 None,或者 NaT(取决于单元格的数据类型),这样的值我们就称之为缺失值。
比如下面的数据: 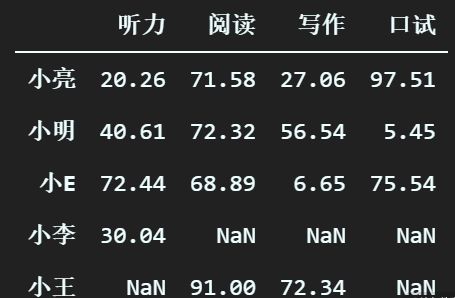
从图中我们可以看出,几个同学都或多或少存在缺失值,比如小王,听力和口试都是没有成绩的,不管是什么原因导致的(可能是作弊),对我们算班级平均分的时候都是有影响的。所以,我们在处理数据的时候,需要使用一些策略来对这些缺失的数据进行补充或者是剔除。
下面,我们来通过程序的方式查询一下这些缺失的数据。
2、甄别缺失值
既然知道了数据里有缺失值,那我们就可以根据实际需要,来甄别表里有哪些缺失值。方式如下:
❝①按单元格查看:DataFrame 提供了 isna 函数,isna 函数返回一个新的 DataFrame, 行数和列数和原 DataFrame 相同,新的 DataFrame 全部由布尔型数据组成,原 DataFrame 的单元格的数据是缺失值的话,在新的 DataFrame 对应位置的单元格就是 True,否则为 False。
# 调用 isna 函数,并查看结果
df_scores.isna()

❝②按列查看:由于现实项目中的 DataFrame 往往很大,我们不可能逐一去看 DataFrame 每个单元格是 True 还是 False,所以更常见的查看手段就是按列聚合缺失值的数量。我们只需要在 isna 函数的基础上再调用一次 sum 函数,即可实现按列聚合。
# 按列聚合缺失值并查看
df_scores.isna().sum()
❝③按行查看:既然可以按列查看,自然也是可以按行查看的。按行查看可以帮助我们了解某个同事的缺失值情况。按行查看的实现方式和按列类似,只需要在 sum 函数的参数中传入 1 即可。
# 按行聚合缺失值并查看
df_scores.isna().sum(1)
❝④查询有缺失值的列:我们希望单独将有缺失值的列过滤出来,查看大概情况,这时候配合使用 isna 函数和 loc 函数就可以实现。
# 行索引部分,取所有的行
# 列索引部分,取所有包含缺失值的列
# any 函数类似 sum 函数,但any 函数做的是布尔聚合,当列有一个或以上的 True 时,结果就是 True, 否则为 False
df_scores.loc[:, df_scores.isna().any()]
❝⑤查询有缺失值的行:如果我们想过滤出有缺失值的行,同样也可以通过 loc 配合 isna 实现
# 行索引部分,通过 any(1) 来聚合行维度的结果
# 列索引部分,取所有的列
df_scores.loc[df_scores.isna().any(1),:]
❝⑥统计表中有缺失值的总个数:对 isna 返回的布尔 DataFrame 做 sum,则可以得到各列各行有多少个缺失值,如果再对这个结果再做一次 sum,则可以得到整个 DataFrame 包含多少个缺失值。
df_scores.isna().sum().sum()
2、处理缺失值
当我们按照需要查询出了表中的缺失值,那就需要对缺失的数据进行处理了,处理的方式无非就是要么补全,要么删除。但是不管是补全还是删除,都需要一些规则来统一处理。Python中也有类似方法,具体如下:
(1)删除缺失值
pandas 的 DataFrame 提供了一个强大的删除缺失值的方法:dropna, 通过传入恰当的参数,我们可以灵活地删除部分或者全部的缺失值。
❝①删除有缺失值的行
df_scores.dropna()
❝②删除有缺失值的列
df_scores.dropna(axis = 1)
❝③删除少于X个正常值的行:这里解释一下,比如开篇的数据,小李有三个缺失值,如果我们要删除少于2个正常值的行,那肯定就要把小李的成绩给删掉了。
# 删除正常值小于 2 个的行
df_scores.dropna(thresh=2)
❝④根据权重删除行:比如在成绩里,比较重视听力的成绩,那么听力成绩为空的,就直接删除掉就行了。总体思路就是:根据某一项的权重来做删除依据。
# 删除写作一列是缺失值的所有行
df_scores.dropna(subset=["听力"])
(2)补全缺失值
既然有删除,就一定有补全。补全的思路也是根据某一个规则进行补全,具体方式如下:
❝①整体固定值补全:这里的固定值就属于给所有的缺失数据都补全一个值。比如下面代码的意思就是给所有为空的成绩都补全一个33分。这样补全是最简单的,也是最不负责任的。。。
df_scores.fillna(33.0)
❝②按列补全固定值:这个跟上面的类似,只是范围缩小到了只给某一列补全。下面代码的意思就是给听力字段缺失值补全一个66分。
df_scores_test["听力"] = df_scores_test["听力"].fillna(60.0)
❝③按行补全固定值:这个就相当于是给学生补全固定值,如下面代码所示,相当于是给小李补全分数,缺失的分数都按50分补全。
df_scores_test.loc["小李",:].fillna("50.0")
❝④根据最近有效值替换:这个规则比较绕,意思大概就是,如果有个值是空的,那么就会继续往下找,如果下一个是非空值,那么这个非空值就算是最近有效值。如果下一个值也是空的,那么就会继续找下一个值,非空就算是最近有效值。以此反复,找到有效值为止。pandas 中要实现最近有效值填充,给 fillna 函数传入 method 参数即可。代码如下:
df_scores.fillna(method="ffill")
(3)给缺失值推测插值
上面介绍了处理缺失值常用的删除或者是补全,但是基本上都属于简单规则,那么如果想根据已有的值进行推测插值,那么就需要下面的方法了。pandas 提供了 interpolate 函数可以帮助我们直接搞定。
# 调用 interpolate 对 Series 进行插值,默认为线性插值
df_scores.interpolate()
调用之后,从结果上,可以看到绿框的两个缺失值成功替换为了线性插值的版本,而红框部分却仍然是用的最近有效值,这是为何呢?其实很简单,线性插值需要缺失值前后有效值的信息来拟合方程,而红框部分都缺少后面的有效值,所以无法拟合。当线性插值无法拟合的时候,会默认采用最近有效值来填充。

3、重复值处理
在日常工作中,可能也会遇到重复数据,那么针对这类数据,我们怎么处理呢?
先做一个重复数据出来,结果如下:
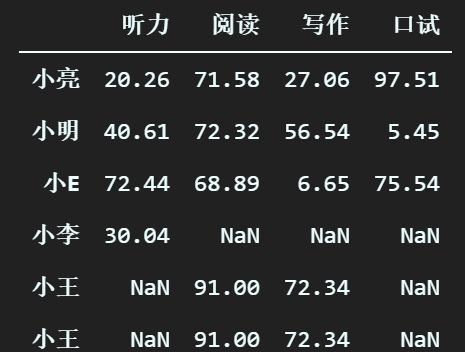
(1)先来查一下是否有重复值
df_scores.duplicated()
输出  当确定数据中有重复值,那我们就可以通过pandas进行去重。
当确定数据中有重复值,那我们就可以通过pandas进行去重。
(2)去除重复值
# 我们需要修改 df_scores ,所以需要将 drop_duplicates 的结果赋值回 df_scores
df_scores = df_scores.drop_duplicates()
df_scores
至此,重复值就自动删除掉了。
❝欢迎关注公众号:服务端技术精选
❝如果有疑问或者是其他需求,可公众号留言