CHI保序
为了满足CHI系统的保序需求,CHI协议指定了多种机制来达到该目的,可以划分为以下几小节:
- Multi-copy atomicity
- Completion Response and Ordering(用于RN保序)
- Completion acknowledgement(用于RN request和其它RN snoop之间保序)
- Transaction ordering(用于RN和HN之间保序)
1. Multi-copy atomicity
CHI协议要求系统架构为multi-copy atomic,所有相关组件必须确保所有的write-type必须是multi-copy atomic。一个写操作被定义为multi-copy atomic必须满足以下两个条件:
- 所有对同地址的写操作时串行的,即它们会被其他Requester以相同的顺序观察到,尽管有些Requester可能不会观察到所有写操作;
- 一笔写操作只有被所有Requester观察到后,才能被同地址的Read操作读出该值;
2. Completion Response and Ordering
不管是同一个agent还是不同agents,为了保证当前transaction和后续的transactions之间的顺序,CHI采用Comp,RespSepData,CompData响应来保证。具体细则如下:
- 对于Requester访问Non-cacheable或Device区间的Read transaction,RespSepData或CompData响应可以保证当前的传输访问的endpoint范围 可以被后续的transactions观察到;
- 对于Requester访问Cacheable地址的Read transaction,CompData或DataSeqResp响应可以保证当前的传输被后续任何agent发送的transactions观察到;
- 对于Requester访问Cacheable地址的Read transaction,RespSepData响应可以保证没有更早之前的transactions将会发送snoop请求给这个Requester,之后的transactions需要发送snoop请求只有等到HN收到该笔read transaction的CompAck之后才可以;
- 对于Dataless transaction,只能访问Cacheable memory空间,Comp响应就可以保证同地址的当前transaction可以被任何agent的后续transactions观察到;另外CleanSharePersist transaction,HN必须收到下游Persist节点的响应之后,才能往RN返回Comp;
- 对于访问Non-cacheable或Device nRnE或Device nRE的Write or Atomic transactions,Comp或CompData响应可以保证同endpoint范围的当前传输可以被任何agent的后续transactions观察到;
- 对于访问Cacheable或Device RE的Write or Atomic transactions,Comp或CompData响应可以保证同地址的当前传输可以被任何agent的后续transactions观察到;
注意: - endpoint address range取决于具体实现,通常的定义如下:对于外设,则是整个peripheral device区域;对于memory空间,则是整个cacheline大小;
- 对于EWA的Write transaction去访问Non-cacheable或Device空间,Comp不能保证同endpoint地址范围的该transaction被后续的transactions所观察到,如果需要确保保序,可以使用Endpoint Order来访问同一个endpoint address range;
3. Completion acknowledgement
对于Requester发送的transactions和其它Requester transactions产生的snoop transactions之间的相对保序关系是通过Completion Acknowledgment响应来确保的。这个可以保证在Requester的transaction之后的保序的snoop transaction是在Requester完成响应之后才被接收;
一笔transaction完成和发送CompAck之间的顺序如下:
- RN-F在收到Comp、RespSepData或CompData、RespSepData和DataSepResp两者之后,才发送CompAck;
- 除了ReadOnce*,HN-F只有在收到CompAck之后,才会发送下一笔同地址的snoop transaction;对于CopyBack transactions,WriteData蕴涵着CompAck,因此HN必须等到WriteData之后再发送同地址的snoop transaction;
除了ReadNoSnp和ReadOnce*,以上这个机制保证了Requester收到Comp和发送CompAck之间,不能收到任何的同地址的snoop请求。
对于一笔transaction中CompAck是否使用是取决于ExpCompAck域,RN在合适需要将ExpCompAck置位且产生CompAck响应有如下规定: - 除了ReadNoSnp和ReadOnce*操作,RN-F其它所有读操作都需要发送CompAck;
- RN-F其实也允许ReadNoSnp和ReadOnce*命令发送CompAck响应;
- 在StashOnce*、CMO、Atomic、Evict操作中,不能发送CompAck响应;
- RN-I和RN-D允许但不是必须在读操作中要包含CompAck响应;
- RN-I和RN-D的Dataless和Atomic传输不能包含CompAck响应;
- 保序的ReadNoSnp和ReadOnce*如果需要使用DMT,那么必须使用CompAck响应;
- 对于写操作,CompAck只能用于WriteUnique;
HN必须支持所有允许或需要使用CompAck的transactions,SN不需要支持CompAck的使用。
4. Transaction ordering
除了Comp响应用于保证一个Requester的多个transactions的顺序,CHI协议也定义了RN和HN、HN-I和SN-I之间的requests保序的机制,HN-F和SN-F之间的order域是用于获得request accepted acknowledge。
在一笔request中,RN与HN、HN-I与SN-I,这些对之间的Requester Order是通过Order域来表示的,Order域可以表示的order类型有:
- Request Order:这个保证了从同一个agent发往同一个地址的多笔transactions的顺序;
- Endpoint Order:这个保证了从同一个agent发往同一个Endpoint address range的多笔transactions的顺序,Endpoint Order包含了Request Order;
- Ordered Write Observation:这个保证了对于同一个agent的一串写操作,会被其它agents以相同的顺序观察到;
- Request Accepted:这个保证了Completer如果接收了该request,则会发送正向的acknowledgement响应;
Order域的值代表的意义如表1所示:
表1 Order field encodings
| Order[1:0] | Description | Notes | Between pairs |
|---|---|---|---|
| 0b00 | No ordering required | – | All pairs |
| 0b01 | Request Accepted | Applicable in Read request from HN-F to SN-F only. Reserved in all other cases | HN-F to SN-F |
| 0b10 | Reuqest Order/Ordered Write Observation required | Reserved in Read requests from HN-F to SN-F | RN to HN,HN-I to SN-I |
| 0b11 | Endpoint Order required, which includes Request Order | Reserved in Read requests from HN-F to SN-F | RN to HN,HN-I to SN-I |
| Order域只有在以下操作中才能置为非0值: |
- ReadNoSnp
- ReadNoSnpSep
- ReadOnce*
- WriteNoSnp
- WriteUnique
- Atomic
以上几种transaction结合order域的用法在下面一一阐述:
1、ReadNoSnp或ReadOnce* transaction要求Request Order或Endpoint Order时,则Requester需要接收到Completer发送的ReadReceipt后才能发下一个ordered request;Completer发送ReadReceipt意味着读请求已经到达保序点POS;
2、WriteNoSnp和non-Snoopable Atomic transaction要求Request Order或Endpoint Order时,则Requester需要接收到Completer发送的DBIDResp才能发下一个ordered request;Completer发送DBIDResp意味着它有资源且写请求已经到达保序点POS;
3、ExpCompAck不置位的WriteUnique transaction或Snoopable Atomic transaction要求Request Order时,则Requester必须收到Completer发送的DBIDResp之后才能发下一个同地址的ordered request;Completer发送DBIDResp意味着它有资源且请求已经到达保序点POS;
4、如果WriteUnique要求采用Ordered Write Observation传输,则RN需要将ExpCompAck置位;Completer是一个POS点,发送DBIDResp表示databuffer充足,且当前写操作的完成不依赖于下一笔Ordered Write Observation的写操作,且直到收到CompAck之后该笔写操作才能可见;
5、当HN-F和SN-F之间的ReadNoSnp或ReadNoSnpSep命令的Order为0b01时,Requester需要收到Completer发送的ReadReceipt,以确保Completer已经接收且不会retry该命令;
当一个Requester发出多个不同order需求的transactions组合时,最后能得到保障的order方式遵循如下原则:1、如果有No ordering命令,那么Order Guarantee将是No ordering;2、如果没有No ordering,有Request Order,那么Order Guarantee将是Request Order;3、如果没有No ordering和Request Order,那么Order Guarantee将是Endpoint Order。总结以上就是遵循最弱保序原则。
Read Request Order举例如图1所示:
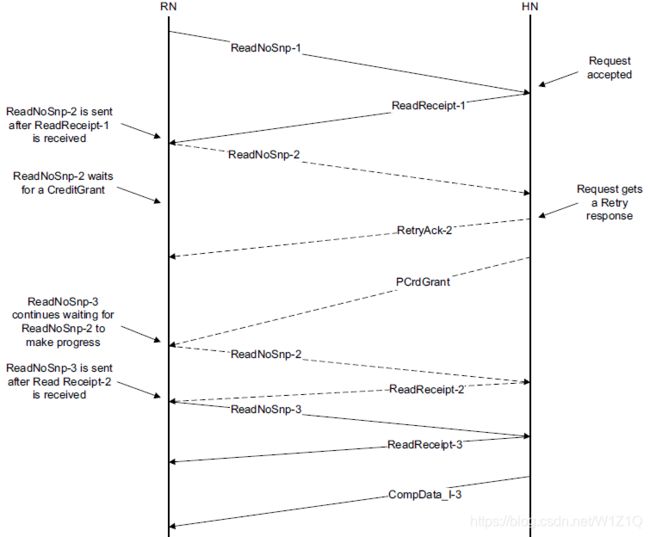
图1 Series of ordered read requests
5. Ordering semantics of RespSepData and DataSepResp
当Requester接收到第一笔DataSepResp后就可以认为该笔Read transaction已经被全局观察到了,由于没有其他操作会改变读数据了;
HN必须确保所有的snoop操作已经完成了才去触发新的transaction,如ReadNoSnpSep,该笔操作会导致DataSepResp响应发送给Requester;
当Requester接收到来自HN的RespSepData响应时,表示该Request在HN上已经做完保序且不会受到任何在该笔transaction之前的任何snoop请求。HN在发送RespSepData响应给Requester之前,必须确保没有同地址的outstanding snoop transactions,但并不表示当前transaction的snoop已经完成,因此RN在收到RespSepData并不保证HN已经完成了对系统中其它agent的snoop操作,也就有了Read transaction访问cacheable空间时,必须收到DataSepResp响应才能保证该笔Read transaction被全局观察到,而不是用RespSepData响应;
在分离的Comp和Data中,当Requester返回CompAck响应后,Requester告知它会负责hazard后续同地址的snoop请求,因为Requester收到RespSepData就可以发送CompAck,但此时其实该命令可能还没有处理完,即SN还需要给RN返回DataSepResp,但HN收到CompAck就会把该传输的hazard解开,因此hazard的责任就需要转移给RN了,因此CHI建议在分离的comp和data中,RN要收到RespSepData和DataSepResp两者后才发送CompAck。
在分离的Comp和Data中,有如下规则需要遵循:
- 除了ReadNoSnp和ReadOnce*外,RN在收到RespSepData响应后必须发送CompAck,CHI建议但不要求RN收到DataSepResp响应后再发送CompAck;
- 对于带保序需求的ReadOnce*和ReadNoSnp,即order域为10或11,且ExpCompAck置位,RN必须收到DataSepResp和RespSepData之后才能发送CompAck;
- Requester必须收到DataSepResp和RespSepData两者之后才能发送另一个同地址的请求;
6. Other
6.1 CopyBack Request order
对于正在进行的CopyBack transaction,RN-F必须等到CompDBID之后才能发送下一笔同地址的request。但又一个例外,如果是SnoopMe置位的Atomic transaction操作就允许RN-F还未收到CopyBack的CompDBID响应就发送出去。
6.2 Stream Ordering WriteUnique transactions
如果Requester要求发送一串WriteUnique transactions,且这些传输需要被其它Master以和发送相同的顺序观察到,Requester可以等待前一笔WriteUnique完成后再发送下一笔WriteUnique,这样的一个observation ordering通常成为能为Ordered Write Observation。CHI协议还提供了另一种称为Streaming Ordered WriteUniques来更有效率的达到这种效果流。
Streaming Ordered WriteUniques依赖于使用Ordered Write Observation ordering需求和CompAck来实现,使用这种方式RN和HN需要承担的功能有:
- Requester必须将Order域置为Ordered Write Observation,且ExpCompAck置位;
- WriteUnique的OWO需求需要HN-F完成该笔一致性写操作不依赖于下一笔一致性写操作的完成;
- Requester必须收到WriteUnique的DBIDResp响应之后,才能发送下一笔WriteUnique,也就是不需要等待Comp之后才能发送了,这样减少等待时间了;
- Requester在收到相应WriteUnique的Comp响应后,且之前WriteUnique transactions的Comp响应也都全部收到了,就必须要返回CompAck响应了;如果此时有写数据也要发送,那么RN可以将CompAck和Data组合起来为NCBWrDataCompACK后一块发送;
- HN-F在释放一笔WriteUnique transaction资源且对其它RN-Fs可见之前,必须需要收到RN-F发送的CompAck响应;
图2给出了RN-I使用Streaming Ordered WriteUniques的传输流程,这个流程防止一笔读操作在Write-A完成之前就读到了Write-B的值,为了简单起见,将Write-B的DBIDResp和NCBWrData省略掉。
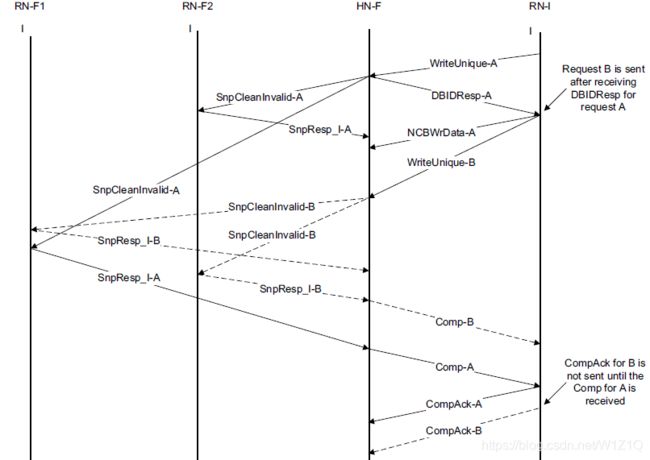
6.3 Optimized Streaming Ordered WriteUniques
Streaming Ordered WriteUnique机制可以进一步简化。如果之前WriteUnique是访问不同的目的节点,那么RN不需要等待DBIDResp就可以发送下一笔ordered WriteUnique。然而,如果ICN可以对TgtID remap,那Requester必须预知所有WriteUniques指向同一个HN-F并且不使用optimized Streaming Ordered WriteUnique流程。
使用Optimized Streaming Ordered WriteUnique必须注意死锁或活锁场景;OSOW的最大受益者通常是RN-I;通过使用WriteDataCancel messages可以避免资源相关的活锁和死锁,因此OSOW可以用于多于一个RN。
