当卷积数为3时准确率达到最大值82.09。_3*3卷积+1*3卷积+3*1卷积=白给的精度提升...
作者 | BBuf
编辑 | 唐里
ICCV2019: 通过非对称卷积块增强CNN的核骨架
下面要介绍的论文发于ICCV2019,题为「ACNet:Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric ConvolutionBlocks」,axriv地址为:https://arxiv.org/abs/1908.03930v1。

由于在给定的应用环境中设计合适的卷积神经网络(CNN)结构需要大量的人工工作或大量的GPU资源消耗,研究界正在寻找网络结构无关的CNN结构,这种结构可以很容易地插入到多个成熟的体系结构中,以提高我们实际应用程序的性能。我们提出了非对称卷积块(ACB)作为CNN的构造块,它使用一维非对称卷积核来增强方形卷积核,我们用ACBs代替标准的方形卷积核来构造一个非堆成卷积网络ACNet,该网络可以训练到更高的精度。训练后,我们等价地将ACNet转换为相同的原始架构,因此将不需要额外的计算。实验证明,ACNet可以CIFAR和ImageNet上显著提高各种经典模型的性能。
1. 研究背景
卷积神经网络在视觉理解方面取得了巨大的成功,这使得其可以应用在安全系统,移动电话,汽车等各种应用中。由于前端设备通常受限于计算资源,就要求网络在保证精度的条件下要尽可能轻量。另一方面,随着CNN架构设计的相关研究增多,模型的性能得到了显著改善,但当现有的模型不能满足我们的特定需求时,要定制一种新的架构需要花费极高的成本。最近,研究者们正在寻求与架构无关的新型CNN结构,例如SE块和准六边形内核,它们可以直接和各种网络结构结合使用,以提高它们的性能。最近对CNN结构的研究主要集中在1)层之间是如何相互连接的,例如简单的堆叠在一起,恒等映射,密集连接等;2)如何组合不同层的输出以提高学习表示的质量;本文提出了非对称卷积块(ACB),它是用三个并行的![]() 核来代替原始的
核来代替原始的![]() 核,如图Figure1所示:
核,如图Figure1所示:
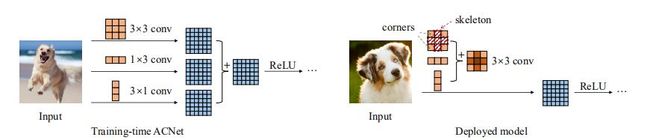
Figure 1
给定一个网络,我们通过将每个方形卷积核替换为ACB模块并训练网络到收敛。之后我们将每个ACB中非对称核的权值加到方形核的对应位置,将ACNet转换为和原始网络等效的结构。ACNet可以提高基准模型的性能,在CIFAR和ImageNet上优势明显。更好的是,ACNet引入了0参数,因此无需仔细调参就能将其与不同的CNN结构结合起来,并且易于在主流CNN框架上实现以及不需要额外的推理时间开销。
代码开源在:https://github.com/ShawnDing1994/ACN。
2. 相关工作
2.1 非对称卷积
非对称卷积通常用于逼近现有的正方形卷积以进行模型压缩和加速,先前的一些工作表明,可以将标准的卷积分解为![]() 和
和![]() 卷积,以减少参数量。其背后的理论相当简单:如果二维卷积核的秩为1,则运算可等价地转换为一系列一维卷积。然而,由于深度网络中下学习到的核具有分布特征值,其内在秩比实际中的高,因此直接将变换应用于核会导致显著的信息损失。Denton等人基于SVD分解找到一个低秩逼近,然后对上层进行精细化以恢复性能。Jaderberg等人通过最小化重构误差,成功学习了水平核和垂直核。Jin等人应用结构约束使二维卷积可分离,在获得相当精度的条件下时间加速了2倍。另一方面,非堆成卷积也被广泛的用来做网络结构设计,例如Inception-v3中,7*7卷积被1*7卷积和7*1卷积代替。语义分割ENet网络也采用这种方法来设计高效的语义分割网络,虽然精度略有下降,但降低了33%的参数量。
卷积,以减少参数量。其背后的理论相当简单:如果二维卷积核的秩为1,则运算可等价地转换为一系列一维卷积。然而,由于深度网络中下学习到的核具有分布特征值,其内在秩比实际中的高,因此直接将变换应用于核会导致显著的信息损失。Denton等人基于SVD分解找到一个低秩逼近,然后对上层进行精细化以恢复性能。Jaderberg等人通过最小化重构误差,成功学习了水平核和垂直核。Jin等人应用结构约束使二维卷积可分离,在获得相当精度的条件下时间加速了2倍。另一方面,非堆成卷积也被广泛的用来做网络结构设计,例如Inception-v3中,7*7卷积被1*7卷积和7*1卷积代替。语义分割ENet网络也采用这种方法来设计高效的语义分割网络,虽然精度略有下降,但降低了33%的参数量。
2.2 CNN架构中的中性结构
我们不打算修改CNN架构,而是使用一些与架构无关的结构来增强现有的模型。因此,我们的方法对任何网络都是有效的。例如,SE块可以附加到卷积层后,使用学习到的权重重新缩放特征图通道数,从而在合理的附加参数量和计算代价下显著提高精度。作为另一个示例,可以将辅助分类器插入模型中以帮助监督学习过程,这确实可以提高性能,但是需要额外的人为调整超参数。相比之下,ACNet在训练中不会引入任何超参数,并且在推理过程中不需要额外的参数和计算。因此,在实际应用中,开发人员可以使用ACNet来增强各种模型,而无需进行详细的参数调整,并且最终用户可以享受性能提升而又不会减慢推理速度。
3. 方法
3.1 公式
对于一个尺寸为![]() 通道数为D的卷积核,以通道数为C的特征图作为输入,我们使用
通道数为D的卷积核,以通道数为C的特征图作为输入,我们使用![]() 表示卷积核,
表示卷积核,![]() 表示输入,这是一个尺寸为UxV通道数为C的特征图,
表示输入,这是一个尺寸为UxV通道数为C的特征图,![]() 代表输出特征图。对于这个层的第j个卷积核,相应的输出特征映射通道是:
代表输出特征图。对于这个层的第j个卷积核,相应的输出特征映射通道是:
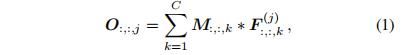
其中*是二维卷积算子。![]() 是M的第k个通道的尺寸为UxV的特征图,
是M的第k个通道的尺寸为UxV的特征图,![]() 代表
代表![]() 的第k个通道的尺寸为HxW的特征图。在现代CNN体系结构中,批量归一化(BN)被广泛使用,以减少过度拟合,加快训练过程。通常情况下,批量归一化层之后通常会接一个线性变化,以增强表示能力。和公式1相比,输入变成:
的第k个通道的尺寸为HxW的特征图。在现代CNN体系结构中,批量归一化(BN)被广泛使用,以减少过度拟合,加快训练过程。通常情况下,批量归一化层之后通常会接一个线性变化,以增强表示能力。和公式1相比,输入变成:
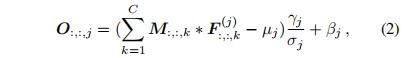
其中,![]() 和
和![]() 是批标准化的通道平均值和标准差,
是批标准化的通道平均值和标准差,![]() 和
和![]() 是缩放系数和偏移量。
是缩放系数和偏移量。
3.2 利用卷积的可加性
我们试图以不对称卷积可以等效地融合到标准方形核层中的方式来使用,这样就不会引入额外的推理时间计算负担。我们注意到卷积的一个有用性质:如果几个大小兼容的二维核在相同的输入上以相同的步幅操作以产生相同分辨率的输出,并且它们的输出被求和,我们可以将这些核在相应的位置相加,从而得到一个产生相同输出的等效核。也就是说,二维卷积的可加性可以成立,即使核大小不同,
其中![]() 是一个矩阵,
是一个矩阵,![]() 和
和![]() 是具有兼容尺寸的两个2D核,
是具有兼容尺寸的两个2D核,![]() 是在对应位置的求和操作。注意可能会被裁剪或者执行Padding操作。这里,“兼容”意味着我们可以把较小的内核“修补”到较大的内核上。在形式下,p层和q的下面这种转换是可行的:
是在对应位置的求和操作。注意可能会被裁剪或者执行Padding操作。这里,“兼容”意味着我们可以把较小的内核“修补”到较大的内核上。在形式下,p层和q的下面这种转换是可行的:
例如,3x1和1x3是和3x3兼容的。通过研究滑动窗口形式的卷积计算,可以很容易地验证这一点,如图Figure2所示:
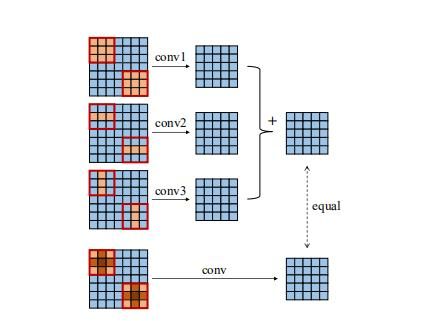
Figure 2
对于一个特定的卷积核,一个指定的点y,则输出![]() 可以使用下式计算:
可以使用下式计算:

其中,X是输入M上相应的滑动窗口。显然,当我们将两个滤波器产生的输出通道相加时,如果一个通道上的每个y,其在另一个通道上的对应点共享相同的滑动窗口,则其相加性质(等式3)成立。
3.3 ACB不增加任何推理时间开销
在本文中,我们关注3x3卷积,这在现代CNN体系结构中大量使用。在给定的体系结构下,我们通过简单地将每个3x3卷积层替换为ACB来构建ACNet,该ACB模块包含三个并行层,内核大小分别为3x3,1x3,和3x1。和标准CNN的常规做法类似,在三层中的每一层之后都进行批量归一化,这被成为分子,并将三个分支的输出综合作为ACB的输出。请注意,我们可以使用与原始模型相同的配置来训练ACNet,而无需调整任何额外的超参数。如4.1和4.2节中所示,我们可以训练ACNet达到更高的精度。训练完成后,我们尝试将每个ACB转换为产生相同输出的标准卷积层这样,与经过常规训练的对等方相比,我们可以获得不需要任何额外计算的功能更强大的网络。该转换通过两个步骤完成,即BN融合和分支融合。
BN融合 卷积的同质性使得后续的BN和线性变换可以等价的融合到具有附加偏置的卷积层中。从公式2可以看出,对于每个分支,如果我们构造一个新的内核![]() 然后加上偏置
然后加上偏置![]() ,我们可以产生相同的输出。
,我们可以产生相同的输出。
分支融合 我们通过在平方核的相应位置加入非对称核,将三个BN融合分支合并成标准卷积层。在实际应用中,这种转换是通过建立一个原始结构的网络并使用融合的权值进行初始化来实现的,这样我们就可以在与原始结构相同的计算预算下产生与ACNet相同的输出。更正式地,对于第j个卷积核,![]() 表示融合后的卷积核,
表示融合后的卷积核,![]() 代表偏置,
代表偏置,![]() 和
和![]() 分别代表1x3和3x1卷积核的输出,融合后的结果可以表示为:
分别代表1x3和3x1卷积核的输出,融合后的结果可以表示为:
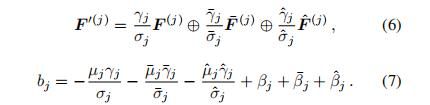
然后我们可以很容易地验证对于任意滤波器j,
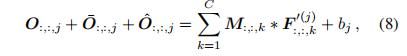
其中,![]() 代表原始
代表原始![]() 三个分支的输出。Figure3展示了这个过程。
三个分支的输出。Figure3展示了这个过程。
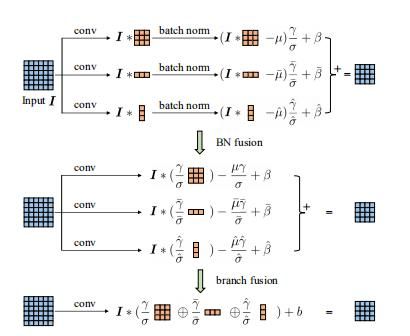
Figure 3
值得注意的是,尽管可以将ACB等价地转换为标准层,但是等效值仅在推理时才成立,因为训练动态是不同的,从而导致不同的性能。训练过程的不等价性是由于内核权重的随机初始化,以及由它们参与的不同计算流得出的梯度
4. 实验
4.1节和4.2节,论文在CIFAR10和CIFAR100数据集,ImageNet数据集进行对比测试,结果如Table1,Table2,Table3所示:


4.3节还展示了消融研究,也就是对AlexNet和ResNet在ImageNet图像上进行测试,采用控制变量法控制ACB的三个关键影响因素,同时对比了将图片旋转的测试效果,最终使用了ACB模块全部技巧的网络模型获得了几乎所有测试情况的新SOAT结果,证明了ACB模块能够增加对数据旋转的适应能力。
4.4 节用以说明ACB增强了方形卷积核的骨架信息。论文在训练过程中通过随机丢弃网络中3*3卷积核的骨架权重和边角权重,所谓骨架权重和边角权重的定义如Figure6所示,骨架权重就是和中间位置直接相连的4个位置加上自身,剩下的就是边角部分了。

Figure 6
然后,画出不同丢弃比例下的测试集准确率图,如Figure5所示:

Figure 5
通过对比图Figure5(a)和Figure5(b)发现,丢弃骨架部分的权重会降低准确率,而丢弃边角部分的权重却能获得更好的精度。然后,我们通过研究卷积核的数值来研究上叙述现象发生的原因。我们使用幅度(即绝对值)作为衡量参数重要性的指标,许多先前的CNN加速工作都采用了该指标。具体来说,我们将一个卷积层中所有融合的2D卷积核都加起来,通过最大值进行逐层归一化,最后获得所有层的归一化核的平均值。更正式地,我们让![]() 表示第i个3x3卷积层的第j个核,L代表3x3卷积层的个数,max和abs代表逐像素的求最大值和取绝对值操作,所以平均核矩阵可以计算为:
表示第i个3x3卷积层的第j个核,L代表3x3卷积层的个数,max和abs代表逐像素的求最大值和取绝对值操作,所以平均核矩阵可以计算为:

其中,

我们在Figure6(a)和Figure6(b)上给出了经过正常训练的ResNet56和融合了ACNet的A值。某个网格的数值和颜色表示该参数在所有位置上平均重要性。从Figure5(a)看出正常训练的ResNet56参数分布是不平衡的,即中心点的A值最大,而四个角点的A值最小。Figure5(b)显示ACNet加剧了这种不平衡,因为四个角点的A值减小到了0.4以下,并且骨架中心点的A值为1.0,这意味着该位置在每个3*3层中始终占据主导地位。值得注意的是,方向,水平,垂直核的相应位置上的权重可能会在符号上相反,因此它们将它们相加可能会产生更大或者更小的幅度。但我们观察到一个一致的现象,即模型学会了在每一层增强骨骼部位的权重。我们继续研究如果将非对称核加到其他位置而不是中心骨架时模型的行为。具体来说,我们使用和以前相同的训练配置来训练Resnet56的ACNet对应网络,但是将水平卷积核向下平移一个像素,垂直卷积核向右平移一个像素。因此,在分支融合时,我们得到Figure6(c)的结果。我们观察到, 这样的ACB网络还可以增强边界,但是强度不如常规ACB对骨骼的增强。该模型的准确度为94.67%,比常规的ACNet低0.42%(Table1)。此外我们对模型融合进行了类似的消融实验,可以看到丢弃边角部分的参数仍然获得了最高的精度,丢弃增强的右下角边界不会比丢弃左上角2*2方形的权重得到更好的结果。
总结一下,1)3*3卷积核的骨架部分比边角部分更加重要;2)ACB可以增强卷积核的骨架部分,从而提高性能;3)和常规的ACB相比,将水平和垂直核添加到边界会降低模型的性能;4)这样做也可以增加边界的重要性,但是不能削弱其它部分的重要性。因此,我们将ACNet的有效性部分归因于它进一步增强卷积核骨架的能力。
5. 结论
为了提高各种CNN架构的性能,我们提出了非对称卷积块(ACB),该算法将三个分别具有正方形,水平和垂直核的卷积分支的输出求和。我们通过使用ACB替换成熟体系结构中的方形核卷积层来构建非对称卷积网络(ACNet),并在训练后将其转换为原始网络结构。在CIFAR和ImageNet数据集上,通过在经典网络上使用ACNet评估我们的性能,取得了SOTA结果。我们已经表明,ACNet可以以可观察的幅度增强模型对旋转失真的鲁棒性,并显著增强方形卷积核的骨骼部分。并且ACNet也易于使用主流框架实现,方便研究者follow这项工作。