Linux文件管理(下)
上上篇介绍了Linux文件管理的上部分内容,这次继续将 Linux文件管理的剩余部分说完。内容如下。

一、查看文件内容
1、cat 命令
1.1 输出文件内容
基本语法:
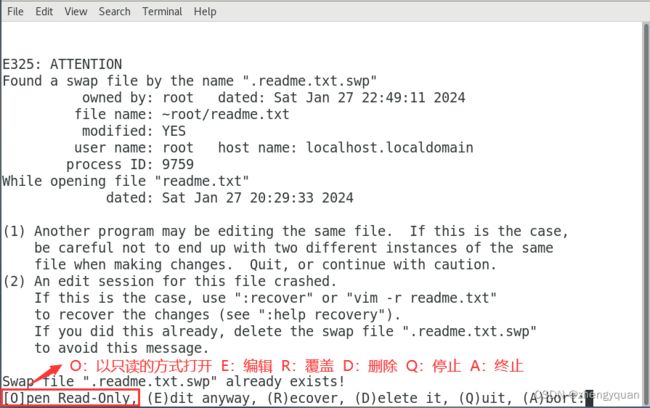
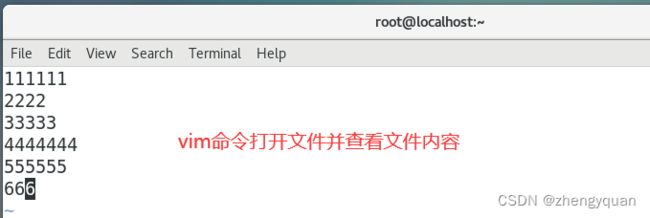
cat 文件名称
主要功能:正序输出文件的内容。
eg:输出 readme.txt文件的内容(正序)
1.2 合并多个文件内容
基本语法:
cat 文件名称1 文件名称2 ... > 合并后的文件名称
主要功能:把文件名称1、文件名称2、…中的内容合并到一个文件中
案例:将1.txt和 2.txt文件内容合并后,输出到 3.txt
cat 1.txt 2.txt > 3.txt
特别注意:cat 命令用于查看文件内容时,不论文件内容有多少,都会一次性显示。如果文件非常大,那么文件开头的内容就看不到了。cat 命令适合查看不太大的文件。
2、tac 命令
基本语法:
tac 文件名称
主要功能:倒序输出文件的内容
eg:输出 readme.txt文件的内容(倒序)

3、head 命令
基本语法:
head -n 文件名称
功能:查看一个文件的前n行,如果不指定n ,则默认显示前10行
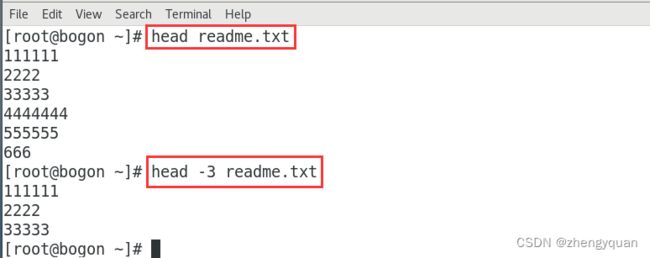
案例1:查询 readme.txt 文件中的前10行
head readme.txt
案例2:查询 readme.txt 文件中的前3行
head -3 readme.txt
4、tail 命令
基本语法:
tail -n 文件名称
主要功能:查看一个文件的最后n行,如果不指定n ,则默认显示最后10行
案例1:查询 linux.txt文件的最后10行
tail linux.txt
案例2:查询 linux.txt文件的最后3行
tail -3 linux.txt
5、tail -f 命令
基本语法:
tail -f 文件名称
主要功能:动态查看一个文件内容的输出信息 (主要用于将来查询日志文件的变化)
案例:查询系统的 /var/log/messages文件的日志信息
tail -f /var/log/messages
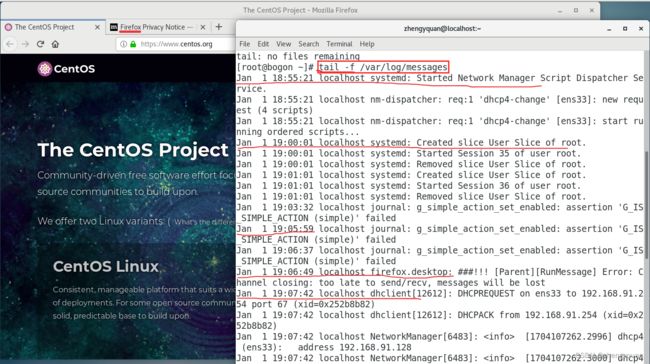
注:退出方式可以直接按快捷键: Ctrl+C ,中断操作
6、more分屏显示文件内容(了解)
基本语法:
more 文件名称
eg:分屏显示 anaconda-ks.cfg文件内容
more anaconda-ks.cfg
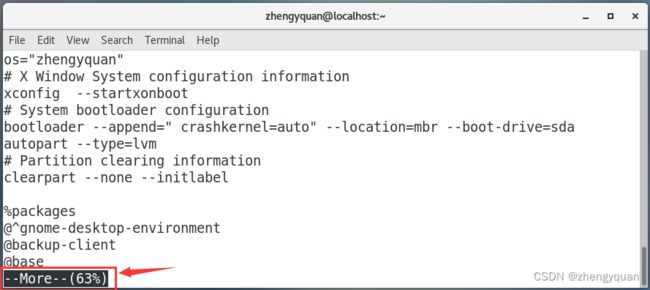
more命令拥有一些交互功能,可以通过快捷键来操作这个more的阅读器。

特别注意: more命令在加载文件时并不是一点一点进行加载,而是打开文件时就已经把文件的全部内容加载到内存中了。如果打开文件较大,则可能会出现卡顿情况。
more在读取文件时,默认已经加载文件的全部内容。
早期more命令没有现在这么强大,其只能前进不能后退。
7、less分屏显示文件内容(重点)
基本语法:
less 文件名称
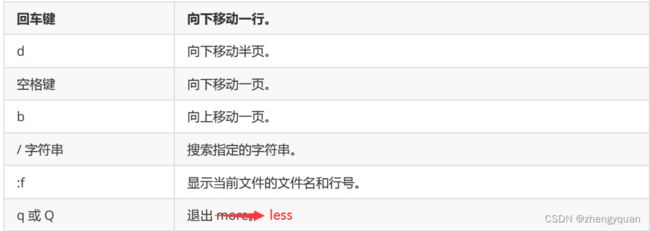
特别注意:less命令不是加载整个文件到内存,而是一点一点进行加载,相对而言,读取大文件时,效率比较高。
另外: less可以通过上下方向键显示上下内容,退出时不会在Shell中留下刚显示的内容
less 命令的执行也会打开一个交互界面(常用交互命令和more类似)
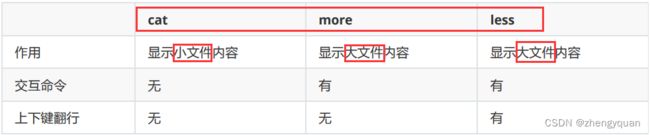
cat、more、less三者的对比
二、统计文件信息
1、wc命令
基本语法:
wc [选项] 文件名称
选项说明:
-l :表示lines, 行数(以回车/换行符为标准)
-W :表示words, 单词数依照空格来判断单词数量
-C :表示bytes, 字节数〈空格,回车,换行)
案例1 : 统计 linux.txt文件的总行数
wc -l linux.txt
案例2 : 统计 linux.txt文件中的单词数
wc -w linux.txt
案例3 : 统计文件的字节数(注意包括 空格,回车,换行)
wc -c linux.txt

扩展: wc [选项] 文件的名称,可以统计一个文件的信息,实际情况下,选项还可以一起使用
案例4 : 统计一个文件的总行数、总单词数以及总字节数
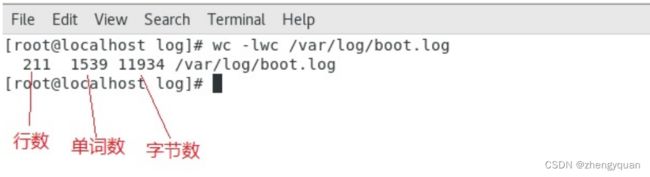
wc -wlc linux.txt
或
wc -lwc linux.txt
或
wc -clw linux.txt
2、du 命令
基本语法:
du [选项] 统计的文件或文件夹
选项说明:
-s : summaries, 只显示汇总的大小,统计文件夹的大小
-h : 以较高的可读性显示文件或文件夹的大小 (KB/MB/GB/TB)
主要功能 : 查看文件或目录(会递归显示子目录) 占用磁盘空间大小
案例1 : 显示 readme.txt文件的大小 (占用磁盘空间,不显示文件大小的单位)
du readme.txt
案例2 : 显示 readme.txt文件的大小(占用磁盘空间,显示文件大小的单位)
du -h readme.txt
案例3 : 统计 wechat文件夹的大小
du -sh wechat
案例4 : 统计 /etc目录的大小
du -sh /etc

三、文件处理命令
1、find 命令
基本语法:
find 搜索路径 [选项]
选项说明:
-name:指定要搜索文件的名称,支持*星号通配符
-type:代表搜索的文件类型,f代表普通文件,d代表文件夹=>加快检索速度
功能:当我们查找一个文件时,必须使用的一个命令。
案例1:搜索 /var目录中 boot.log文件(普通文件)
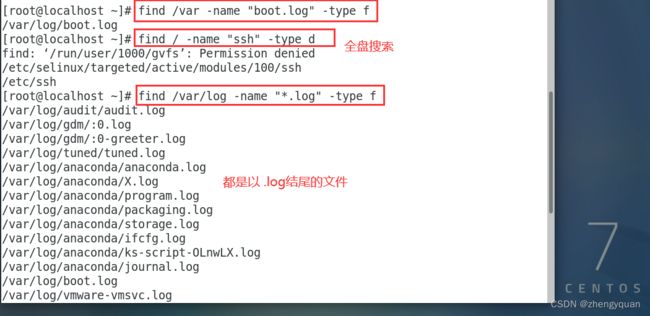
find /var -name "boot.log" -type f
案例2:全盘搜索ssh目录
find / -name "ssh" -type d
当出现与查找条件相符合的结果不止一个时,可以采用全盘搜索,以查找出所有符合条件的结果。
注:实际工作时,尽量减少全盘检索,因为全盘搜索比较消耗资源
扩展:find实现模糊查询(必须结合通配符)
案例3:搜索 /var/log目录下的所有的以".log"结尾的文件信息
find /var/log -name "*.log" -type f
* :通配符,代表任意个任意字符。如*.log代表以.log结尾的文件,apache*代表搜索以apache开头的文件信息。
2、grep命令
基本语法:
grep [选项] 要搜索的关键词 搜索的文件名称
选项说明:
-n :代表显示包含关键词的行号信息
单位:行
主要功能:在文件中直接找到包含指定关键词的那些行,并把这些信息高亮显示出来
案例1:在initial-setup-ks.cfg文件中搜索包含关键词"network"的行
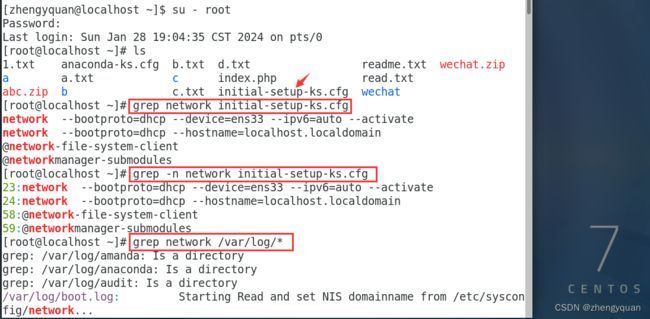
grep network initial-setup-ks.cfg
案例2:在 initial-setup-ks.cfg文件中搜索包含关键词"network"的行,然后显示行号信息
grep -n network initial-setup-ks.cfg
扩展语法:
grep 要搜索的关键词 多个文件的名称
主要功能:在多个文件中查找包含指定关键词的那些行,并高亮显示出来
案例3:搜索 /var/log目录下所有文件,找到包含关键词"network"的所有行信息
grep network /var/log/*
3、echo命令
基本语法:
echo "文本内容"
主要功能:在终端中输入指定的文本内容
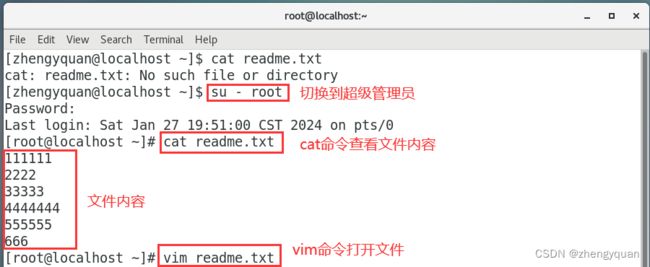
案例:在终端中,输出hello world字符串
echo "hello world"
4、输出重定向
场景:一般命令的输出都会显示在终端中,有些时候需要将一些命令的执行结果想要保存到文件中进行后续的分析/统计,则这时候需要使用到的输出重定向技术。
> :标准输出重定向 : 覆盖输出,会覆盖掉原先的文件内容
>>:追加重定向 : 追加输出,不会覆盖原始文件内容,会在原始内容末尾继续添加
案例1:把 echo输出的 "hello world"写入到 readme.txt文件中
echo "hello world" > readme.txt
以上程序的主要功能代表把echo命令的执行结果,输出写入到 readme.txt文件中,如果 readme.txt文件中存在内容,则首先清空,然后再写入hello world
案例2:把 echo输出的"hello linux"写入到 readme.txt,要求不能覆盖原来的内容
echo "hello linux" >> readme.txt