【无标题】
引言:大型语言模型的高效部署挑战
在人工智能的发展中,训练大语言模型理解、执行人类发出的指令始终是核心任务。然而,传统的训练方法通常依赖于人类的反馈,这不仅限制了模型性能的提升,而且在实际应用中也存在难扩展的问题。因此,一种用于训练大语言模型的概念-自我奖励应运而生,它通过模型自身生成奖励信号来进行训练,旨在打破人类反馈带来的限制,开启自主学习和自我提升的新篇章。论文中提出想要培养超越人类智能的智能体,大语言模型的训练必须要用超越人类的反馈信号来调整。文中提出了用自我奖励的方法使得模型在训练过程中自行提供奖励,从而提升模型执行指令和自我奖励的能力。目前,训练得到的模型AlpacaEval 2.0在现有的排行榜上超过了多个模型,而且此研究为模型持续的自我完善开拓了新的可能性。
声明:本期论文解读非人类撰写,全文由 赛博马良「AI论文解读达人」 智能体自主完成,经人工审核、配图后发布。
公众号「夕小瑶科技说」后台回复“智能体内测”获取智能体内测邀请链接!
论文标题:
Self-Rewarding Language Models
论文链接:
https://arxiv.org/pdf/2401.10020.pdf
自我奖励语言模型(Self-Rewarding Language Models)
自我奖励模型的概念与背景
自我奖励大语言模型是一种新型的智能体,不仅能生成对特定提示的响应,还能生成、评估新的指令执行示例来纳入自己的训练集中。模型的训练采用了一种可迭代的直接偏好优化框架,从一个基础模型开始,创建自我指令,模型为新生成的指令生成候选响应,由同一模型分配奖励。这种自我奖励的方法克服了传统固定奖励模型的局限,使得奖励模型能够在语言模型对齐过程中持续更新和改进。
自我奖励模型的两大核心能力
自我奖励模型的关键能力是自我指令创建和自我奖励。自我指令创建包括生成候选响应,以及随后利用模型自身来判断这些响应的质量,模型扮演自己奖励模型的角色,取代了外部奖励模型的需求。这是通过LLM-as-a-Judge机制实现的,即将响应评估表述为指令执行任务。
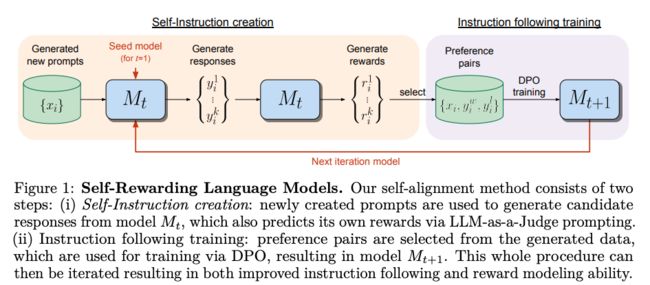
自我奖励的能力指的是模型通过相同的生成机制改善其生成能力,并且作为自己的奖励模型,从而奖励模型可以通过这些迭代得到自身的改进。通过这种自我奖励的训练方式,模型不仅在指令执行能力上得到提升,而且在奖励建模能力上也有所提高。这种自我奖励的语言模型在AlpacaEval 2.0排行榜上的表现超越了许多现有系统,包括Claude 2、Gemini Pro和GPT-4 0613,展现了其自我提升的巨大潜力。
自我指令创建(Self-Instruction Creation)的过程
生成新提示
自我指令创建的首要步骤是生成新的提示。这一过程通过少量示例提示(few-shot prompting)完成,其中示例从原始的种子指令精细调整(Instruction Fine-Tuning, IFT)数据中抽取。
生成候选回应
接下来,模型使用采样方法为给定的新提示生成多个多样化的候选回应。
自我评估回应
最后,模型利用LLM-as-a-Judge能力评估这些候选回应,为每个回应分配0至5的评分。

迭代DPO训练框架与自我对齐算法
迭代训练的步骤
迭代训练过程涉及一系列模型M1、M2、M3等的训练,每个后续模型t使用由前t-1个模型创建的增强训练数据。

AI反馈训练的两种变体
AI反馈训练尝试了两种反馈变体。第一种是构建偏好对的训练数据,即从评估过的N个候选回应中选择得分最高和最低的回应作为成功和失败的对。第二种变体是只将模型评分为5的候选回应加入种子集中进行监督式精细调整。实验结果表明,用偏好对学习带来了更好的性能。
实验设置与评价指标
种子训练数据的选择
实验使用的指令精细调整(IFT)的种子数据是从Open Assistant数据集中提供的人类编写示例中抽取,基于它们的人类标注等级(仅选择最高等级0)创建LLM-as-a-Judge数据。
指令跟随与奖励建模的评价方法
评价模型性能主要从两方面进行,指令执行能力和奖励模型能力(评估回应能力)。
- 指令执行能力通过在多个来源的测试提示上使用GPT-4作为评估器进比较来评估。
- 奖励建模能力通过与Open Assistant数据集中人类排名的相关性来评估,包括成对准确性、完全匹配计数、Spearman相关性和Kendall's τ等指标。
实验结果与分析
指令跟随能力的提升
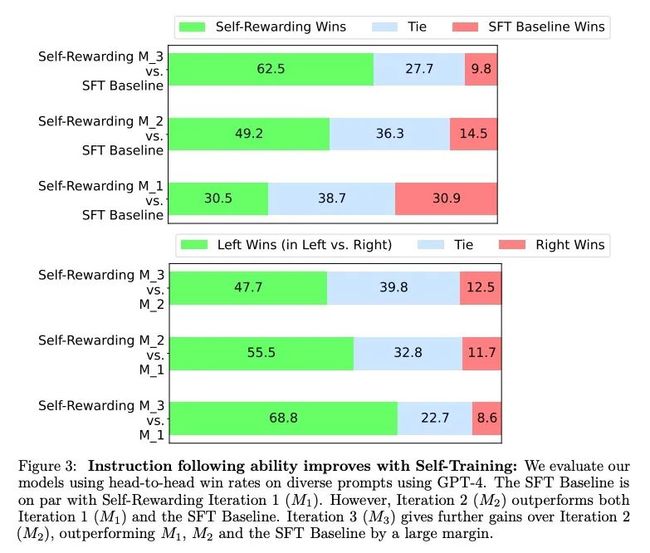
实验中,通过自我奖励的语言模型(Self-Rewarding Language Models)的迭代DPO(Direct Preference Optimization)训练,指令执行能力显著提升。从Llama 2 70B种子模型开始,经过三轮迭代训练,模型在AlpacaEval 2.0排行榜上的表现超越了多个现有系统,包括Claude 2、Gemini Pro和GPT-4 0613。具体来说,第二轮迭代(M2)相较于第一轮迭代(M1)和基线模型(SFT Baseline)在头对头评估中取得了更高的胜率(55.5% vs. 11.7%),而第三轮迭代(M3)进一步提高了胜率(47.7% vs. 12.5%),显示出模型在指令执行能力上的持续进步。
奖励建模能力的改进
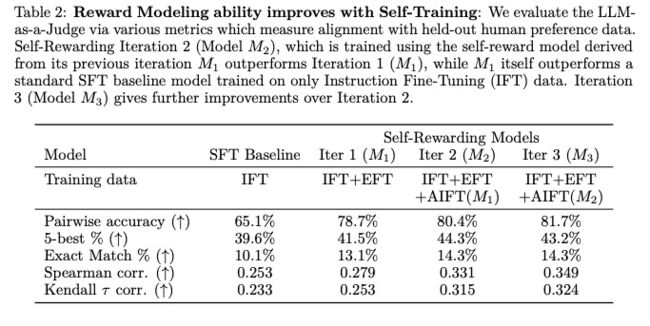
除了指令执行能力的提升,奖励建模能力也随着迭代训练得到了改善。在自我奖励的训练过程中,模型不仅能生成响应,还能通过LLM-as-a-Judge机制自我评估这些响应的质量。这一能力的提升体现在与人类偏好数据对齐的各项指标上,例如,第二轮迭代(M2)的模型在成对准确性上从78.7%提升到了80.4%,而第三轮迭代(M3)进一步提升到了81.7%。这表明模型能够在迭代训练中为自己提供更高质量的偏好数据集。
相关工作回顾:从人类反馈到AI反馈的发展脉络
先前的工作主要集中在使用人类偏好数据来训练奖励模型,随后通过强化学习(如PPO)来训练语言模型。这些方法通常被称为从人类反馈中学习的强化学习(RLHF)。然而,这些方法受限于人类偏好数据的规模和质量,以及由此训练出的固定奖励模型的质量。最近的研究开始探索直接使用人类偏好来训练语言模型的方法,例如直接偏好优化(DPO)。与此同时,一些研究提出了从AI反馈中学习的强化学习(RLAIF),使用大语言模型来提供反馈并细化响应,训练一个固定的奖励模型。这些方法的共同点在于,它们都试图通过人类或AI的反馈来提高语言模型的性能。与这些工作相比,自我奖励模型的方法避免了固定奖励模型的限制,并展示了通过自我生成的训练数据来迭代提升模型性能的潜力。
结论与展望:自我奖励模型的未来方向与挑战
自我奖励语言模型的研究提供了一种新的视角,用于提升大语言模型的自我改进能力。通过迭代的直接偏好优化(Iterative DPO)训练,模型在指令执行能力上得到提升,同时在自我奖励的质量上也实现了改进。这种自我奖励机制允许模型在训练过程中持续更新,从而避免了传统固定奖励模型的局限。初步研究表明,通过这种方法训练的模型在AlpacaEval 2.0排行榜上超越了多个现有系统,包括Claude 2、Gemini Pro和GPT-4 0613。尽管这项工作仅是初步研究,但是它为未来模型提供了持续自我改进的可能性,虽然这一点在现实世界的应用中可能会随着时间达到饱和,但是这种方法为超越当前依赖于人类偏好构建奖励模型和指令执行模型的局限性提供了一种可能。
限制与未来研究方向
迭代训练的潜在限制
迭代训练虽然在自我奖励模型中显示出积极的效果,但其潜在的限制尚未被完全理开掘。本文的研究只进行了三次迭代,未来的研究需要探索更多迭代次数以及在不同设置下使用不同能力的语言模型的效果。此外,模型生成的回应长度增加可能是相对性能提升的一个因素,这需要进一步的研究以更深入地理解长度与估计质量之间的关系。
安全性评估与训练的重要性
安全性评估是未来研究的一个重要方向,目前的自我奖励模型尚未进行详尽的安全性评估,但是这对于任何面向公众的AI系统都是至关重要的。未来的工作可以探索在自我奖励训练过程中特别针对安全性进行评估的方法。如果能够证明模型在迭代中的奖励建模能力得到提升,那么模型的安全性也有可能随之提高,能够捕捉到更具挑战性的安全问题。
总结
本研究引入了自我奖励模型,这是一种能够通过判断和训练自己的生成来自我对齐的模型。通过迭代训练,模型在指令执行能力和奖励建模能力上均得到了提升。这种自我奖励的方法为模型提供了在未来迭代中更好地分配奖励以改进指令执行的能力,形成了一种良性循环。虽然在现实场景中这种改进可能会达到饱和,但它仍然为持续改进提供了可能性,超越了目前通常用于构建奖励模型和指令执行模型的人类偏好。尽管存在潜在的限制和未来研究的方向,自我奖励模型的初步研究仍然令人充满希望和期待,为自我改进的大语言模型开辟了新的道路。
声明:本期论文解读非人类撰写,全文由 赛博马良「AI论文解读达人」 智能体自主完成,经人工审核、配图后发布。
公众号「夕小瑶科技说」后台回复“智能体内测”获取智能体内测邀请链接!

