sql优化:两表关联字段类型不一致导致的查询问题
在平常的工作中,经常需要写大量的的sql语句,比如列表查询、数据更新之类的操作。那么,查询sql的效率非常重要,直接影响用户的体验,记录一次sql表关联字段类型不一致导致的sql查询问题。
1:student表:
CREATE TABLE `student` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键',
`student_no` bigint NOT NULL COMMENT '学号',
`name` varchar(20) DEFAULT NULL COMMENT '名字',
`address` varchar(100) DEFAULT NULL COMMENT '地址',
`sex` char(1) DEFAULT NULL COMMENT '性别',
PRIMARY KEY (`id`),
KEY `student_no` (`student_no`)
) ENGINE=InnoDB AUTO_INCREMENT=320557 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;2:student_info表:
CREATE TABLE `student_info` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键',
`student_no` bigint NOT NULL COMMENT '学号',
`hobbies` varchar(200) DEFAULT NULL COMMENT '兴趣爱好',
KEY `id` (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=210006 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;3:通过存储过程,两个表分别插入测试数据:
CREATE PROCEDURE `insert_student_info_data`()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 30000 DO
INSERT INTO student_info (student_no, hobbies)
VALUES ('3456789098765434512'+i, '唱歌');
SET i = i + 1;
END WHILE;
ENDCREATE PROCEDURE `insert_student_data`()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 30000 DO
INSERT INTO student (student_no,name,address, sex)
VALUES ('3456789098765434534'+i,'张三','陕西宝鸡', '男');
SET i = i + 1;
END WHILE;
END4:student表的 student_no 字段为 bigint 类型,student_info表的 student_no 为 varchar 类型,执行查询sql:
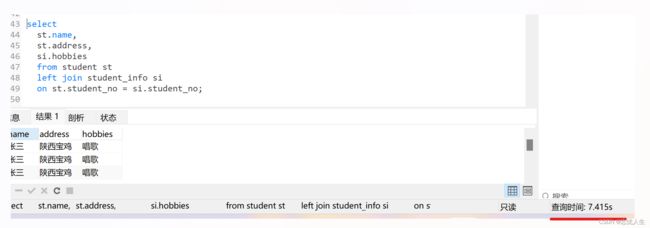
两个表,关联字段一个类型为bigint,一个为varchar,耗时7.41秒
两个表的字段类型一致,都为bigint,耗时0.35秒:
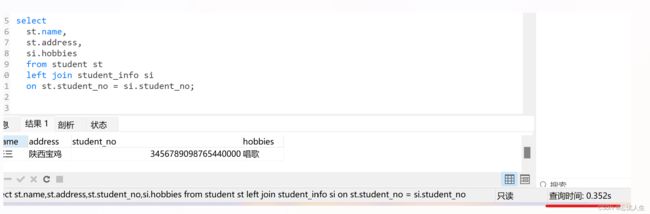
5:从上面结果可以看出,每个表三万条数据,如果类型一致,查询效率提升了二三十倍。如果类型不一致,查询时进行类型转换,比较耗时。所以,在平常开发的过程中,一定要注意这些细节问题。这个sql看起来没有什么复杂的逻辑,但是如果类型不一致,查询就很耗时。
不断学习,才能遇见更好的自己。加油,美好的风景一直在路上!