03_Opencv简单实例演示效果和基本介绍
视频处理
视频分解图片
在后面我们要学习的机器学习中,我们需要大量的图片训练样本,这些图片训练样本如果我们全都使用相机拍照的方式去获取的话,工作量会非常巨大, 通常的做法是我们通过录制视频,然后提取视频中的每一帧即可!
接下来,我们就来学习如何从视频中获取信息
ubuntu下摄像头终端可以安装: sudo apt-get install cheese 然后输入cheese即可打开摄像头
实现步骤:
1. 加载视频
2. 获取视频信息
3. 解析视频
1. 读取摄像头
import cv2 as cv
capture = cv.VideoCapture(0)
capture.isOpened()
ok,frame = capture.read()
while ok:
cv.imshow("frame",frame)
cv.waitKey(1)
ok,frame = capture.read()2. 读取视频
import cv2 as cv
video = cv.VideoCapture("img/road.mp4")
isOpend = video.isOpened()
print("视频是否打开成功:",isOpend)
# 获取图片的信息:帧率
fps = video.get(cv.CAP_PROP_FPS)
#获取每帧的宽度
width = video.get(cv.CAP_PROP_FRAME_WIDTH)
# 获取每帧的高度
height = video.get(cv.CAP_PROP_FRAME_HEIGHT)
print("帧率:{},宽度:{},高度:{}".format(fps,width,height))
ok,frame = video.read()
#从视频中读取8帧信息
count = 0
while ok:
cv.imshow("frame",frame)
# cv.waitKey(125)
cv.waitKey(1)
flag,frame = video.read()
3.截取视频帧为图片
import cv2 as cv
video = cv.VideoCapture("img/twotiger.avi")
# 判断视频是否打开成功
isOpened = video.isOpened()
print("视频是否打开成功:",isOpened)
# 获取图片的信息:帧率
fps = video.get(cv.CAP_PROP_FPS)
# 获取每帧宽度
width = video.get(cv.CAP_PROP_FRAME_WIDTH)
# 获取每帧的高度
height = video.get(cv.CAP_PROP_FRAME_HEIGHT)
print("帧率:{},宽度:{},高度:{}".format(fps,width,height))
# 从视频中读取8帧信息
count=0
while count<8:
count = count + 1
# 读取成功or失败, 当前帧数据
flag,frame = video.read()
# 将图片信息写入到文件中
if flag: # 保存图片的质量
cv.imwrite("img/tiger%d.jpg"%count,frame,[cv.IMWRITE_JPEG_QUALITY,100])
print("图片截取完成啦!")HSV颜色模型
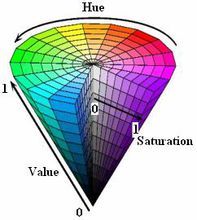
HSV(Hue, Saturation, Value)是根据颜色的直观特性由A. R. Smith在1978年创建的一种颜色空间, 也称六角锥体模型(Hexcone Model)。
这个模型中颜色的参数分别是:色调(H),饱和度(S),明度(V)
色调H
用角度度量,取值范围为0°~360°,从红色开始按逆时针方向计算,红色为0°,绿色为120°,蓝色为240°。它们的补色是:黄色为60°,青色为180°,品红为300°;
饱和度S
饱和度S表示颜色接近光谱色的程度。一种颜色,可以看成是某种光谱色与白色混合的结果。其中光谱色所占的比例愈大,颜色接近光谱色的程度就愈高,颜色的饱和度也就愈高。饱和度高,颜色则深而艳。光谱色的白光成分为0,饱和度达到最高。通常取值范围为0%~100%,值越大,颜色越饱和。
明度V
明度表示颜色明亮的程度,对于光源色,明度值与发光体的光亮度有关;对于物体色,此值和物体的透射比或反射比有关。通常取值范围为0%(黑)到100%(白)。
结论:
1. 当S=1 V=1时,H所代表的任何颜色被称为纯色;
2. 当S=0时,即饱和度为0,颜色最浅,最浅被描述为灰色(灰色也有亮度,黑色和白色也属于灰色),灰色的亮度由V决定,此时H无意义;
3. 当V=0时,颜色最暗,最暗被描述为黑色,因此此时H(无论什么颜色最暗都为黑色)和S(无论什么深浅的颜色最暗都为黑色)均无意义。
注意: 在opencv中,H、S、V值范围分别是[0,180],[0,255],[0,255],而非[0,360],[0,1],[0,1];
这里我们列出部分hsv空间的颜色值, 表中将部分紫色归为红色

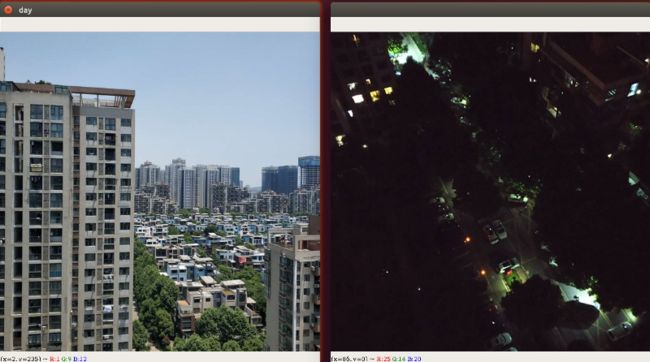
判断当前是白天还是晚上
实现步骤
1. 将图片从BGR颜色空间,转变成HSV颜色空间
2. 获取图片的宽高信息
3. 统计每个颜色点的亮度
4. 计算整张图片的亮度平均值
注意,这仅仅只能做一个比较粗糙的判定,按照我们人的正常思维,在傍晚临界点我们也无法判定当前是属于晚上还是白天!
def average_brightness(img):
# 封装一个计算图片平均亮度的函数
height,width = img.shape[0:2]
# 获取当前图片的HSV
hsv_img = cv.cvtColor(img, cv.COLOR_BGR2HSV)
# 提取出v通道信息
v_day = cv.split(hsv_img)[2]
#计算亮度之和
result = np.sum(v_day)
return result/(height*width)
#计算白天亮度平均值
img = cv.imread("img/22.jpg")
brightness1 = average_brightness(img)
print("白天亮度平均值为:", brightness1)
#计算晚上亮度平均值
img1 = cv.imread("img/5.jpg")
brightness2 = average_brightness(img1)
print("晚上亮度平均值为:", brightness2)显示效果:

注意:这里的亮度平均值是一个可变的值,需要自己调。
颜色过滤
在一张图片中,如果某个物体的颜色为纯色,那么我们就可以使用颜色过滤inRange的方式很方便的来提取这个物体.
下面我们有一张网球的图片,并且网球的颜色为一定范围内的绿色,在这张图片中我们找不到其它颜色也为绿色的图片,所以我们可以考虑使用绿色来提取它!
图片的颜色空间默认为BGR颜色空间,如果我们想找到提取纯绿色的话,我们可能需要写(0,255,0)这样的内容,假设我们想表示一定范围的绿色就会很麻烦!
所以我们考虑将它转成HSV颜色空间,绿色的色调H的范围我们很容易知道,剩下的就是框定颜色的饱和度H和亮度V就可以啦!
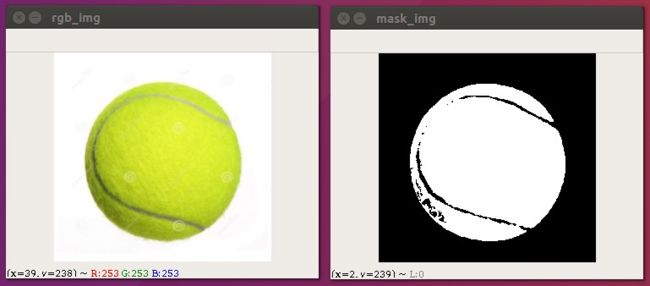
实现步骤:
1. 读取一张彩色图片
2. 将RGB转成HSV图片
3. 定义颜色的范围,下限位(30,120,130),上限为(60,255,255)
4. 根据颜色的范围创建一个mask
# 读取图片
rgb_img = cv.imread("img/2.jpg")
# getRGB(rgb_img)
# 将BGR颜色空间转成HSV空间
hsv_img = cv.cvtColor(rgb_img, cv.COLOR_BGR2HSV)
#定义范围 颜色范围
lowerb_color = (35,43, 46)
upper_color = (77,255, 255)
# 查找颜色
mask_img = cv.inRange(hsv_img, lowerb_color, upper_color)
# 在颜色范围内的内容是白色,其它为黑色
fig = plt.figure(figsize=(10,10))
fig.add_subplot(1,3,1)
getRGB(rgb_img)
fig.add_subplot(1,3,2)
getRGB(mask_img)
rgb_img[mask_img != 255] = (0,0,0)
fig.add_subplot(1,3,3)
getRGB(rgb_img)效果:

图像的二值化
图像二值化( Image Binarization)就是将图像上的像素点的灰度值设置为0或255,也就是将整个图像呈现出明显的黑白效果的过程。
在数字图像处理中,二值图像占有非常重要的地位,图像的二值化使图像中数据量大为减少,从而能凸显出目标的轮廓。
所使用的阈值,结果图片 = cv.threshold(img,阈值,最大值,类型)

| THRESH_BINARY |
高于阈值改为255,低于阈值改为0 |
| THRESH_BINARY_INV |
高于阈值改为0,低于阈值改为255 |
| THRESH_TRUNC |
截断,高于阈值改为阈值,最大值失效 |
| THRESH_TOZERO |
高于阈值不改变,低于阈值改为0 |
| THRESH_TOZERO_INV |
高于阈值该为0,低于阈值不改变 |
简单阈值
import cv2 as cv
# 读取图像
img = cv.imread("assets/car.jpg",cv.IMREAD_GRAYSCALE)
# 显示图片
cv.imshow("gray",img)
# 获取图片信息
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
# 定义阈值
thresh = 60
for row in range(height):
for col in range(width):
# 获取当前灰度值
grayValue = img[row,col]
if grayValue>thresh:
img[row,col]=255
else:
img[row,col]=0
# 直接调用api处理 返回值1:使用的阈值, 返回值2:处理之后的图像
# ret,thresh_img = cv.threshold(img, thresh, 255, cv.THRESH_BINARY)
# 显示修改之后的图片
cv.imshow("thresh",img);
cv.waitKey(0)
cv.destroyAllWindows()效果:

自适应阈值
我们使用一个全局值作为阈值。但是在所有情况下这可能都不太好,例如,如果图像在不同区域具有不同的照明条件。在这种情况下,自适应阈值阈值可以帮助。这里,算法基于其周围的小区域确定像素的阈值。因此,我们为同一图像的不同区域获得不同的阈值,这为具有不同照明的图像提供了更好的结果。
除上述参数外,方法cv.adaptiveThreshold还有三个输入参数:
该adaptiveMethod决定阈值是如何计算的:
- cv.ADAPTIVE_THRESH_MEAN_C:该阈值是该附近区域减去恒定的平均Ç。
- cv.ADAPTIVE_THRESH_GAUSSIAN_C:阈值是邻域值减去常数C的高斯加权和。
该BLOCKSIZE确定附近区域的大小和Ç是从平均值或附近的像素的加权和中减去一个常数。
import cv2 as cv
# 读取图像
img = cv.imread("assets/thresh1.jpg",cv.IMREAD_GRAYSCALE)
# 显示图片
cv.imshow("gray",img)
# 获取图片信息
imgInfo = img.shape
# 直接调用api处理 参数1:图像数据 参数2:最大值 参数3:计算阈值的方法, 参数4:阈值类型 参数5:处理块大小 参数6:算法需要的常量C
thresh_img = cv.adaptiveThreshold(img,255,cv.ADAPTIVE_THRESH_GAUSSIAN_C,cv.THRESH_BINARY,11,5)
# 显示修改之后的图片
cv.imshow("thresh",thresh_img);
cv.waitKey(0)
cv.destroyAllWindows()效果:

THRESH_OTSU
采用日本人大津提出的算法,又称作最大类间方差法,被认为是图像分割中阈值选取的最佳算法,采用这种算法的好处是执行效率高!
import cv2 as cv
# 读取图像
img = cv.imread("assets/otsu_test.png",cv.IMREAD_GRAYSCALE)
cv.imshow("src",img)
ret,thresh_img = cv.threshold(img, 225, 255, cv.THRESH_BINARY_INV)
cv.imshow("normal", thresh_img);
gaussian_img = cv.GaussianBlur(img,(5,5),0)
cv.imshow("g",gaussian_img)
ret,thresh_img = cv.threshold(gaussian_img, 0, 255, cv.THRESH_BINARY|cv.THRESH_OTSU)
cv.imshow("otsu", thresh_img);
print("阈值:",ret)
cv.waitKey(0)
cv.destroyAllWindows()效果: