2023浙江省大学生信息安全竞赛初赛misc方向wp
文章目录
- Number game
- EZ_misc
- Steins_Gate
Number game
队友直接手撕js…预期估计前端把if判断从==改成!=就好了
function _0x41b2(){var _0x581373=['random','110weBJzg','72Hfusyf','3399gncQtP','fromCharCode','round','57148oCRiuH','innerHTML','565DHmrSB','2543450CSzJEO','295299TseKck','40794iCQePa','3062gGLIpQ','9huxpnh','30409884zfOaIf','toString','15660bKtcCP'];_0x41b2=function(){return _0x581373;};return _0x41b2();}(function(_0x6b2864,_0x325f4f){var _0x19c61a=_0x359f,_0x596e22=_0x6b2864();while(!![]){try{var _0x410e5a=parseInt(_0x19c61a(0xd0))/0x1*(-parseInt(_0x19c61a(0xd6))/0x2)+-parseInt(_0x19c61a(0xd1))/0x3*(-parseInt(_0x19c61a(0xdb))/0x4)+parseInt(_0x19c61a(0xdd))/0x5*(-parseInt(_0x19c61a(0xcf))/0x6)+-parseInt(_0x19c61a(0xde))/0x7+-parseInt(_0x19c61a(0xd7))/0x8*(parseInt(_0x19c61a(0xdf))/0x9)+-parseInt(_0x19c61a(0xd4))/0xa*(parseInt(_0x19c61a(0xd8))/0xb)+parseInt(_0x19c61a(0xd2))/0xc;if(_0x410e5a===_0x325f4f)break;else _0x596e22['push'](_0x596e22['shift']());}catch(_0x1b9b94){_0x596e22['push'](_0x596e22['shift']());}}}(_0x41b2,0x79872));function _0x359f(_0xa22008,_0x233420){var _0x41b233=_0x41b2();return _0x359f=function(_0x359fd1,_0xe2d6d7){_0x359fd1=_0x359fd1-0xcf;var _0x308121=_0x41b233[_0x359fd1];return _0x308121;},_0x359f(_0xa22008,_0x233420);}function roll(){var _0x38f496=_0x359f,_0x1afb7a=Math[_0x38f496(0xda)](Math[_0x38f496(0xd5)]()*0x3e8);document['getElementById']('number')[_0x38f496(0xdc)]=_0x1afb7a[_0x38f496(0xd3)]();if(_0x1afb7a==0x539){var _0x14184c=[0x38,0x6f,0x1e,0x24,0x1,0x32,0x51,0x45,0x1,0x3c,0x24,0xb,0x55,0x38,0xa,0x5d,0x28,0x12,0x33,0xb,0x5d,0x20,0x1e,0x46,0x17,0x3d,0x10,0x2a,0x41,0x44,0x49,0x1a,0x31,0x5a],_0x477866='';for(var _0x6698b7=0x0;_0x6698b7<_0x14184c['length'];_0x6698b7++)_0x477866+=String[_0x38f496(0xd9)](_0x14184c[_0x6698b7]^_0x6698b7+0x5a);alert(_0x477866);}}
逆向脚本
array1=[0x38,0x6f,0x1e,0x24,0x1,0x32,0x51,0x45,0x1,0x3c,0x24,0xb,0x55,0x38,0xa,0x5d,0x28,0x12,0x33,0xb,0x5d,0x20,0x1e,0x46,0x17,0x3d,0x10,0x2a,0x41,0x44,0x49,0x1a,0x31,0x5a]
for i in range(len(array1)):
print(chr((array1[i]^i+0x5a)),end='')
#b4By_m1$c_@n3_b4By_f3On7eNd_731cK!
EZ_misc
白给题,一分多钟直接搓完一血~
一眼丁真,op无疑

文件头一眼丁真jpg,字节reverse
![]()
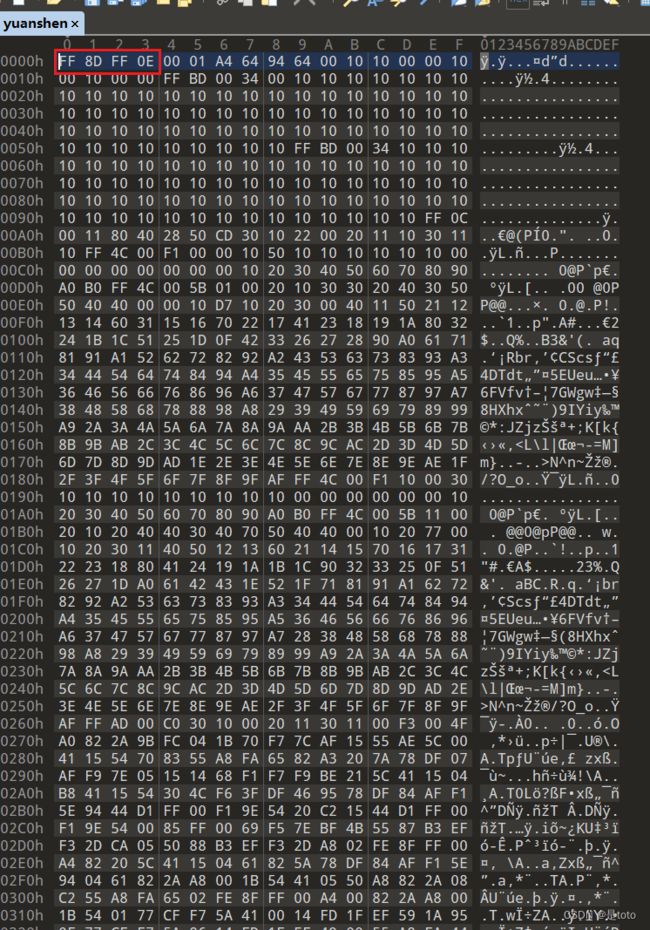
搓个脚本
import binascii
with open('yuanshen','rb') as file1:
with open('yuanshen.jpg','wb') as file2:
hex_list = ("{:02X}".format(int(c)) for c in file1.read())
for i in hex_list:
file2.write(bytes.fromhex(i[::-1]))
stegseek一把梭,是空密码的steghide
得到的flag.txt很明显是摩斯,连变量名都对应好了,DASH替换为-,DOT替换为.
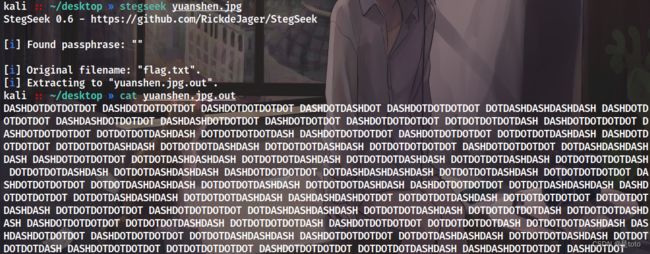

Steins_Gate
到手一个50mb大小的png…
放大后是一堆“嘟嘟噜”
每个文字基本上RGB差不多,盲猜是把原图每个像素替换成一个文字了,测量后每个文字所在正方形为16*16

简单读取一个16*16正方形的像素后发现由于图片压缩导致部分文字像素有渐进,同时可以看出背景像素为(211, 211, 211)
from PIL import Image
im = Image.open('Steins_Gate.png')
pix = im.load()
for x in range(0,16):
for y in range(0,16):
r, g, b = pix[x, y]
print(r,g,b)

这里想到选择统计并排序16*16方格的像素频率
from PIL import Image
im = Image.open('Steins_Gate.png')
pix = im.load()
width = im.size[0]
height = im.size[1]
im1 = Image.new("RGB", (int(width / 16), int(height / 16)))
for i in range(0, width, 16):
for j in range(0, height, 16):
dic = {}
for x in range(i, i + 16):
for y in range(j, j + 16):
r, g, b = pix[x, y]
if (r, g, b) in dic:
dic[(r, g, b)] += 1
else:
dic[(r, g, b)] = 1
sorted_dict = sorted(dic.items(), key=lambda x: x[1], reverse=True)
print(sorted_dict)
绝大多数情况下背景频率最高,原像素就是频率第二高的RGB值,直接选取sorted_dict[1]即可
但这样子恢复出来的图像有点问题卡了很久,后来发现有几个点原像素的频率值比背景(211,211,211)的频率还高
if sorted_dict[0][0] != (211, 211, 211):
print(sorted_dict)

得多加个判断,最终脚本如下:
(其实在一开始直接加个排除掉背景像素的操作就不会有这种情况发生了)
from PIL import Image
im = Image.open('Steins_Gate.png')
pix = im.load()
width = im.size[0]
height = im.size[1]
im1 = Image.new("RGB", (int(width / 16), int(height / 16)))
for i in range(0, width, 16):
for j in range(0, height, 16):
dic = {}
for x in range(i, i + 16):
for y in range(j, j + 16):
r, g, b = pix[x, y]
if (r, g, b) in dic:
dic[(r, g, b)] += 1
else:
dic[(r, g, b)] = 1
sorted_dict = sorted(dic.items(), key=lambda x: x[1], reverse=True)
if sorted_dict[0][0]!=(211, 211, 211):
print(sorted_dict)
im1.putpixel((int(i / 16), int(j / 16)), sorted_dict[0][0])
else:
im1.putpixel((int(i / 16), int(j / 16)), sorted_dict[1][0])
im1.show()
im1.save("output.png")
恢复出原图

观察到原图的0通道都有异样
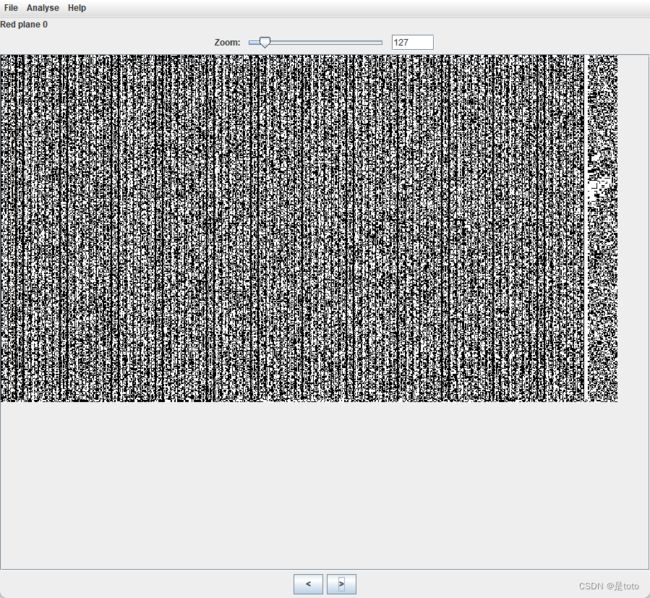
选0通道可以看到有很多base64,直接导出

直接zsteg也行

可以观察到每15*16个base64后跟着12个字节的冗余数据
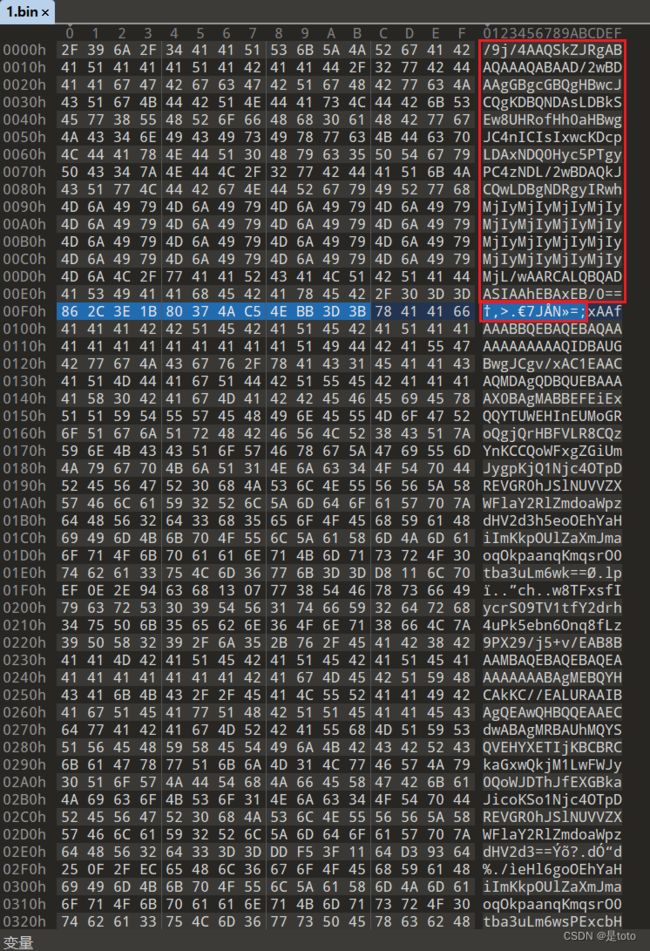
简单写个脚本过滤一下
with open('11.bin','rb')as f:
with open('11.txt','wb') as f1:
data=f.read()
for i in range(0,len(data),252):
f1.write(data[i:i+240])
f1.write(b'\n')
解出来是个jpg

前面这么多行的base64,可以联想到base64隐写
得到密码DuDuLu~T0_Ch3@t_THe_w0r1d
![]()
尝试了几个隐写后是outguess
