语义分割-DeepLab系列
文章目录
- 官方 PPT Rethinking Atrous Convolution for Semantic Image Segmentation
- DeepLab v1
- DeepLab v2
- DeepLab v3
- DeepLab v3+
- 参考文献
官方 PPT Rethinking Atrous Convolution for Semantic Image Segmentation






















DeepLab v1
paper
Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
backbone
VGG16
DeepLab是结合**深度卷积神经网络(DCNNs)和概率模型(DenseCRF)**的方法。实验中发现DNNs做语义分割时精准度不够的根本原因是DCNN的高级特征的平移不变性,即高层次特征映射,根源于重复的池化和下采样。
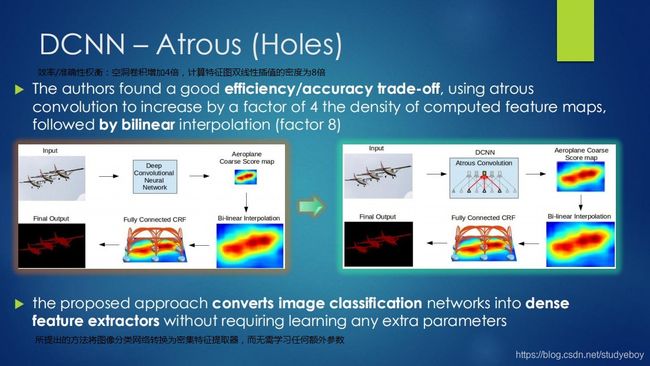
针对信号下采样或池化降低分辨率,DeepLab是采用的Atrous(带孔)算法扩展感受野获取更多的上下文信息。
分类器获取以对象中心的决策是需要空间变换的不变性,这天然的限制了DCNN的定位精度,DeepLab采用完全连接的条件随机场(CRF)提高模型捕获细节的能力。
除空洞卷积和CRFs之外,论文使用的tricks还有Multi-Scale features。其实就是U-Net和FPN的思想,在输入图像和前四个最大池化层的输出上还附件了两层的MLP,第一层是128个33卷积,第二层是128个11卷积。最终输出的特征与主干网的最后一层特征图融合,特征图增加5*128=640个通道。
实验表示多尺度有助于提升预测结果,但是效果不然CRF明显。
论文模型基于VGG16,在Titan GPU上运行速度达到了8FPS,全连接CRF平均推断需要0.5s,在PASCAL VOC-2012达到71.6% IOU accuracy。
DeepLab v2
paper
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution,
and Fully Connected CRFs
backbone
ResNet 101
DeepLabv2是相对于DeepLabv1基础上的优化。DeepLabv1在三个方向努力解决,但是问题依然存在:特征分辨率的降低、物体存在多尺度、DCNN的平移不变性。
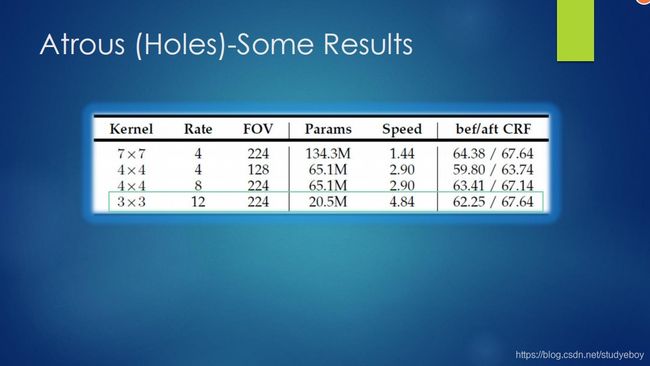
因为DCNN连续池化和下采样造成分辨率降低,DeepLabv2在最后几个最大池化层中去除下采样,取而代之的是空洞卷积,以更高的采样密度计算特征映射。
物体存在多尺度问题,DeepLabv1中是用多个MLP结合多尺度特征解决,虽然可以提供系统的性能,但是增加特征计算量和存储空间。
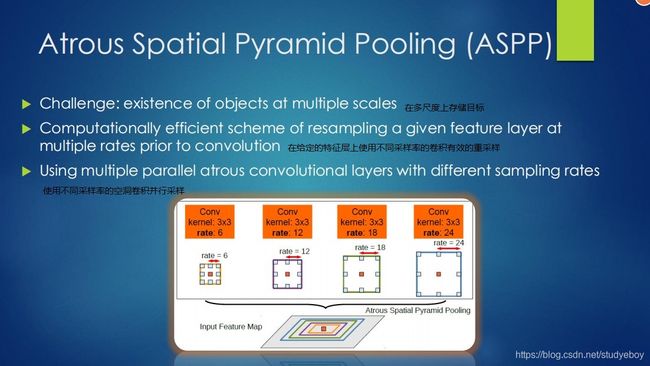
受Spatial Pyramid Pooling(SPP)的启发,提出了一个类似的结构,在给定的输入上以不同采样的空洞卷积并行采样,相当于以多个比例捕捉图像上下文,称为ASPP(Atrous spatial pyramid pooling)模块。
DCNN的分类不变形影响空间精度。DeepLabv2是采样全连接的CRF在增强模型捕捉细节的能力。
论文模型在基于ResNet, 在NVIDIA Titan X GPU上运行速度达到了8FPS,全连接CRF平均推断需要0.5s,在耗时方面和DeepLabv1无差异,但在PASCAL VOC-2012达到79.7 mIOU。
DeepLab v3
paper
Rethinking Atrous Convolution for Semantic Image Segmentation
backbone
ResNet 101
DeepLabv3依然在空洞卷积做文章,但是探讨不同结构的方向。比较了多种捕获多尺度信息的方式:

- Image Pyramid 将输入图片缩放成不同比例,分别应用在DCNN上,将预测结果融合得到最终输出。
- Encoder-Decoder 利用Encoder阶段的多尺度特征,运用到Decoder阶段上恢复空间分辨率,代表工作有FCN、SegNet,PSPNet等。
- Deeper w。 Atrous Convolution 在原始模型的顶端增加额外的模块,例如DenseCRF,捕捉像素间长距离信息。
- Spatial Pyramid Pooling 空间金字塔池化具有不同采样率和多种视野的卷积核,能够以多尺度捕捉对象。
DeepLabv1-v2都是使用带孔卷积提取密集特征来进行语义分割。但是为了解决分割对象的多尺度问题,DeepLabv3设计采用了多比例的带孔卷积级联或并行来捕获多尺度背景。
此外,DeepLabv3将修改之前提出的带孔空间金字塔池化模块,该模块用于探索多尺度卷积特征,将全局背景基于图像层次进行编码获得特征,取得state-of-art性能,在PASCAL VOC-2012达到86.9 mIOU。
DeepLab v3+
paper
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
backbone
Xception (最优)
ResNet 101
code
github TensorFlow
motivation
DeepLab v3的ASPP得到的特征分辨率即使在采用atrous convolution的情况下,依然有8倍的缩小,直接对1/8分辨率的结果图进行上采样,恢复成原始分辨率大小,得到逐像素的分割结果。直接上采样操作并不能充分恢复在降采样为1/8分辨率过程中损失的细节信息,造成分割的不精确。DeepLab v3的基础上,加入decoder的形式恢复原始分辨率的分割结果,使得边缘细节信息能够较好的保留。
创新点
- 将DeepLab v3作为编码器(利用atrous convolution生成任意维度的特征,并采用ASPP策略),在其后面级联解码器进而恢复边界细节信息。
- 探究了ResNet-101替换成Xception模型的可行性,采用depthwise separable convolution进一步提高分割算法的精度和速度。
DeepLabv3+继续在模型的架构上做文章,为了融合多尺度信息,引入语义分割常用的encoder-decoder。在encoder-decoder架构中,引入可以任意控制编码器提取特征的分辨率,通过空洞卷积平衡精度和耗时。
在语义分割任务中采用Xception模型,在ASPP和解码模块使用depthwise separable convolution,提高编码器-解码器网络的运行速率和健壮性,在PASCAL VOC 2012数据集上取得新的state-of-art表现,89.0 mIOU。
网络结构





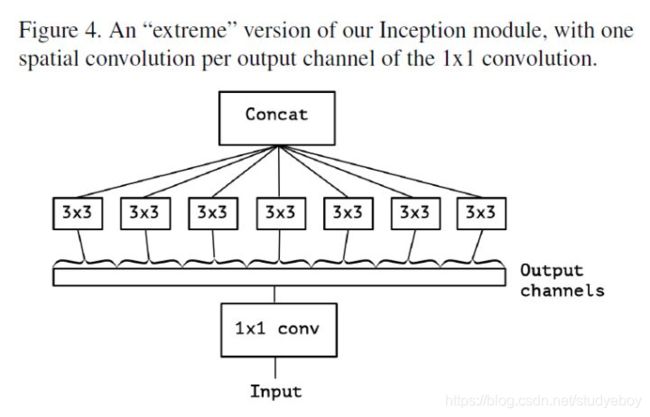

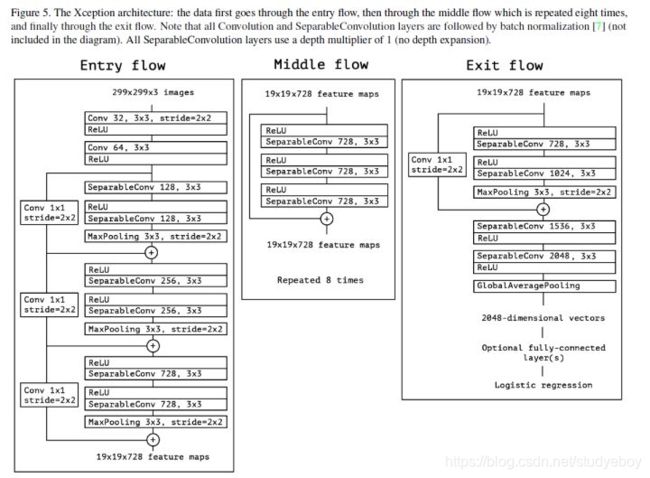




总结
从DeepLabv1-v3+,空洞卷积必不可少,从DeepLabv3开始去掉CRFs。
参考文献
https://blog.csdn.net/u011974639/article/details/79148719
http://web.eng.tau.ac.il/deep_learn/wp-content/uploads/2017/12/Rethinking-Atrous-Convolution-for-Semantic-Image-Segmentation-1.pdf
https://blog.csdn.net/u011974639/article/details/79518175
https://blog.csdn.net/JYZhang_CVML/article/details/79594940
http://www.sohu.com/a/224351199_500659
读Xception和DeepLab V3+