字节面试杂谈——JAVA并发
目录
一、并行和并发、进程和线程、守护线程、为什么使用多线程、多线程带来的问题
1.并行和并发有什么区别?
2.线程和进程的区别?
3.守护线程是什么?
4.请简要描述线程与进程的关系,区别及优缺点
5.为什么要使用多线程呢?
二、创建线程的方式
(1)继承Thread类创建线程
(2)实现Runnable接口创建线程
(3)使用Callable和Future创建线程
(4)使用线程池例如用Executor框架
三、Runnable和Callable
四、线程状态及转换(生命周期)
五、sleep() 与 wait()
六、run() 和 start()
七、Java程序中保证多线程的运行安全
八、JAVA线程同步方法
九、Thread.interrupt() 原理
十、ThreadLocal、ThreadLocal内存泄漏
十一、synchronized —— 使用方式、优化
十二、volatile
(1)谈⼀下你对 volatile 关键字的理解?
(2)happens-before
十三、synchronized 与 ReenTrantLock 、synchronized与volatile
(1)谈谈 synchronized 和 ReenTrantLock 的区别?
synchronized 和 volatile 的区别是什么?
十四、ReentrantReadWriteLock
十五、悲观锁和乐观锁、乐观锁常见的两种实现方式、乐观锁的缺点
十六、CAS、CAS 与 synchronized
十七、JAVA中的原子类
十八、atomic原理
十九、AQS
二十、信号量Semaphore
二十一、CountDownLatch 与 CyclicBarrier
二十二、线程池、ThreadPoolExecutor、四种拒绝策略、四个变型
二十三、execute(),submit()
二十四、JDK中提供了哪些并发容器
二十五、CopyOnWriteArrayList
二十六、BlockingQueue
二十七、ConcurrentSkipListMap
二十八、上下文切换
二十九、CPU高速缓存
三十、JMM:JAVA内存模型
三十一、有界、无界任务队列,手写BlockingQueue
(1)从有界无界上分
(2)JUC中的阻塞队列
(3)阻塞队列的基本操作方法
(4)ArrayBlockingQueue(公平、非公平)
(5)LinkedBlockingQueue(两个独立锁提高并发)
(6)PriorityBlockingQueue(compareTo 排序实现优先)
(7)DelayQueue(缓存失效、定时任务 )
(8)SynchronousQueue(不存储数据、可用于传递数据)
(9)LinkedTransferQueue
(10)LinkedBlockingDeque
(11)简单了解BlockingQueue
(12) BlockingQueue的核心方法:
(13)常见BlockingQueue
(14)手写BlockingQueue
三十二、锁升级
(1)Synchronized锁的3种使用形式(使用场景):
(2)锁的前置知识
(3)Java中的锁偏向锁
(4)轻量级锁
(5)自旋锁
(6)重量级锁Synchronized
三十三、JAVA中的锁
(1)乐观锁 VS 悲观锁
(2)自旋锁 VS 适应性自旋锁
(3) 无锁 VS 偏向锁 VS 轻量级锁 VS 重量级锁#
(4)公平锁 VS 非公平锁
(5)可重入锁 VS 非可重入锁
(6)独享锁 VS 共享锁
(7) 独享锁/共享锁
(8)互斥锁/读写锁
(9)分段锁
三十四、公平锁与非公平锁
三十五、lock()
三十六、两个线程交替打印
三十七、多线程哈希表
(1)HashMap
(2)ConcurrentHashMap
一、并行和并发、进程和线程、守护线程、为什么使用多线程、多线程带来的问题
1.并行和并发有什么区别?
2.线程和进程的区别?
3.守护线程是什么?
JVM 程序在什么情况下能够正常退出?
The Java Virtual Machine exits when the only threads running are all daemon threads.
上面这句话来自 JDK 官方文档,意思是:当 JVM 中不存在任何一个正在运行的非守护线程时,则 JVM 进程即会退出。
在Java中有两类线程:User Thread(用户线程)、Daemon Thread(守护线程)
用个比较通俗的比如,任何一个守护线程都是整个JVM中所有非守护线程的保姆:
只要当前JVM实例中尚存在任何一个非守护线程没有结束,守护线程就全部工作;只有当最后一个非守护线程结束时,守护线程随着JVM一同结束工作。
Daemon的作用是为其他线程的运行提供便利服务,守护线程最典型的应用就是 GC (垃圾回收器),它就是一个很称职的守护者。
User和Daemon两者几乎没有区别,唯一的不同之处就在于虚拟机的离开:如果 User Thread已经全部退出运行了,只剩下Daemon Thread存在了,虚拟机也就退出了。 因为没有了被守护者,Daemon也就没有工作可做了,也就没有继续运行程序的必要了。
值得一提的是,守护线程并非只有虚拟机内部提供,用户在编写程序时也可以自己设置守护线程。下面的方法就是用来设置守护线程的。
(2)建立守护进程
Thread daemonTread = new Thread();
// 设定 daemonThread 为 守护线程,default false(非守护线程)
daemonThread.setDaemon(true);
// 验证当前线程是否为守护线程,返回 true 则为守护线程
daemonThread.isDaemon(); (1) thread.setDaemon(true)必须在thread.start()之前设置,否则会跑出一个IllegalThreadStateException异常。你不能把正在运行的常规线程设置为守护线程。
(2) 在Daemon线程中产生的新线程也是Daemon的。
(3) 不要认为所有的应用都可以分配给Daemon来进行服务,比如读写操作或者计算逻辑。
因为你不可能知道在所有的User完成之前,Daemon是否已经完成了预期的服务任务。一旦User退出了,可能大量数据还没有来得及读入或写出,计算任务也可能多次运行结果不一样。这对程序是毁灭性的。造成这个结果理由已经说过了:一旦所有User Thread离开了,虚拟机也就退出运行了。
(3)补充说明:
定义:守护线程--也称“服务线程”,在没有用户线程可服务时会自动离开。
优先级:守护线程的优先级比较低,用于为系统中的其它对象和线程提供服务。
设置:通过setDaemon(true)来设置线程为“守护线程”;将一个用户线程设置为守护线程的方式是在 线程对象创建 之前 用线程对象的setDaemon方法。
example: 垃圾回收线程就是一个经典的守护线程,当我们的程序中不再有任何运行的Thread,程序就不会再产生垃圾,垃圾回收器也就无事可做,所以当垃圾回收线程是JVM上仅剩的线程时,垃圾回收线程会自动离开。它始终在低级别的状态中运行,用于实时监控和管理系统中的可回收资源。
生命周期:守护进程(Daemon)是运行在后台的一种特殊进程。它独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件。也就是说守护线程不依赖于终端,但是依赖于系统,与系统“同生共死”。当JVM中所有的线程都是守护线程的时候,JVM就可以退出了;如果还有一个或以上的非守护线程则JVM不会退出。
4.请简要描述线程与进程的关系,区别及优缺点
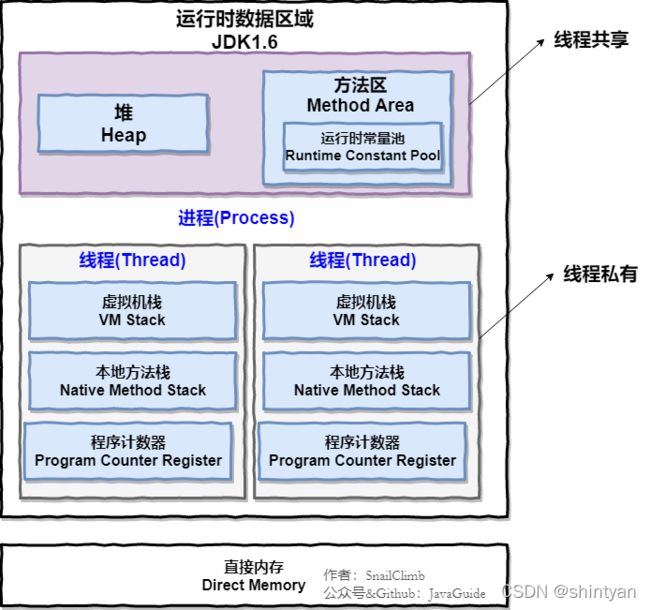
(1)简介:
5.为什么要使用多线程呢?
二、创建线程的方式
Java使用Thread类代表线程,所有的线程对象都必须是Thread类或其子类的实例。Java可以用四种方式来创建线程,如下所示:
1)继承Thread类创建线程
2)实现Runnable接口创建线程
3)使用Callable和Future创建线程
4)使用线程池例如用Executor框架
(1)继承Thread类创建线程
通过继承Thread类来创建并启动多线程的一般步骤如下
1】定义Thread类的子类,并重写该类的run()方法,该方法的方法体就是线程需要完成的任务,run()方法也称为线程执行体。
2】创建Thread子类的实例,也就是创建了线程对象
3】启动线程,即调用线程的start()方法
//继承Thread类来创建线程
public class ThreadTest {
public static void main(String[] args) {
//设置线程名字
Thread.currentThread().setName("main thread");
MyThread myThread = new MyThread();
myThread.setName("子线程:");
//开启线程
myThread.start();
for(int i = 0;i<5;i++){
System.out.println(Thread.currentThread().getName() + i);
}
}
}
class MyThread extends Thread{
//重写run()方法
public void run(){
for(int i = 0;i < 10; i++){
System.out.println(Thread.currentThread().getName() + i);
}
}
}(2)实现Runnable接口创建线程
通过实现Runnable接口创建并启动线程一般步骤如下:
1】定义Runnable接口的实现类,一样要重写run()方法,这个run()方法和Thread中的run()方法一样是线程的执行体
2】创建Runnable实现类的实例,并用这个实例作为Thread的target来创建Thread对象,这个Thread对象才是真正的线程对象
3】第三部依然是通过调用线程对象的start()方法来启动线程
//实现Runnable接口
public class RunnableTest {
public static void main(String[] args) {
//设置线程名字
Thread.currentThread().setName("main thread:");
Thread thread = new Thread(new MyRunnable());
thread.setName("子线程:");
//开启线程
thread.start();
for(int i = 0; i <5;i++){
System.out.println(Thread.currentThread().getName() + i);
}
}
}
class MyRunnable implements Runnable {
@Override
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println(Thread.currentThread().getName() + i);
}
}
}(3)使用Callable和Future创建线程
和Runnable接口不一样,Callable接口提供了一个call()方法作为线程执行体,call()方法比run()方法功能要强大。
a.call()方法可以有返回值
b.call()方法可以声明抛出异常
Java5提供了Future接口来代表Callable接口里call()方法的返回值,并且为Future接口提供了一个实现类FutureTask,这个实现类既实现了Future接口,还实现了Runnable接口,因此可以作为Thread类的target。在Future接口里定义了几个公共方法来控制它关联的Callable任务。
a.boolean cancel(boolean mayInterruptIfRunning):视图取消该Future里面关联的Callable任务
b.V get():返回Callable里call()方法的返回值,调用这个方法会导致程序阻塞,必须等到子线程结束后才会得到返回值
c.V get(long timeout,TimeUnit unit):返回Callable里call()方法的返回值,最多阻塞timeout时间,经过指定时间没有返回抛出TimeoutException
d.boolean isDone():若Callable任务完成,返回True
e.boolean isCancelled():如果在Callable任务正常完成前被取消,返回True
介绍了相关的概念之后,创建并启动有返回值的线程的步骤如下:
1】创建Callable接口的实现类,并实现call()方法,然后创建该实现类的实例(从java8开始可以直接使用Lambda表达式创建Callable对象)。
2】使用FutureTask类来包装Callable对象,该FutureTask对象封装了Callable对象的call()方法的返回值
3】使用FutureTask对象作为Thread对象的target创建并启动线程(因为FutureTask实现了Runnable接口)
4】调用FutureTask对象的get()方法来获得子线程执行结束后的返回值
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
//实现Callable接口
public class CallableTest {
public static void main(String[] args) {
//执行Callable 方式,需要FutureTask 实现实现,用于接收运算结果
FutureTask futureTask = new FutureTask(new MyCallable());
new Thread(futureTask).start();
//接收线程运算后的结果
try {
Integer sum = futureTask.get();
System.out.println(sum);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
class MyCallable implements Callable {
@Override
public Integer call() throws Exception {
int sum = 0;
for (int i = 0; i < 100; i++) {
sum += i;
}
return sum;
}
} (4)使用线程池例如用Executor框架
①使用线程池的好处
线程池提供了一种限制和管理资源(包括执行一个任务)的方式。每个线程池还维护一些基本统计信息,例如:已完成任务的数量。
使⽤线程池的好处
1、降低资源消耗:通过重复利用已创建的线程降低线程创建和销毁造成的消耗;
2、 提高响应速度:当任务到达时,任务可以不需要的等到线程创建就能立即执行;
3、 提高线程的可管理性:线程是稀缺资源,如果⽆限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
②创建线程池所需要的参数
public ThreadPoolExecutor( int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
} a.corePoolSize(线程池的基本大小):当提交一个任务到线程池时,如果当前 poolSize < corePoolSize 时,线程池会创建⼀个线程来执行任务,即使其他空闲的基本线程能够执行新任务也会创建线程,等到需要执行的任务数大于线程池基本大小时就不再创建。如果调用了线程池的prestartAllCoreThreads() 方法,线程池会提前创建并启动所有基本线程。
b.maximumPoolSize(线程池最大数量):线程池允许创建的最大线程数。如果队列满了,并且已创建的线程数小于最⼤线程数,则线程池会再创建新的线程执行任务。值得注意的是,如果使用了无界的任务队列这个参数就没什么效果。
c.keepAliveTime(线程活动保持时间):线程池的工作线程空闲后,保持存活的时间。所以,如果任务很多并且每个任务执行的时间比较短,可以调大时间,提高线程的利用率。
d.TimeUnit(线程活动保持时间的单位):可选的单位有天(DAYS)、小时(HOURS)、分钟(MINUTES)、毫秒(MILLISECONDS)、微秒(MICROSECONDS,千分之⼀毫秒)和纳秒(NANOSECONDS,千分之⼀微秒)。
e. workQueue(任务队列):用于保存等待执行的任务的阻塞队列。
可以选择以下几个阻塞队列:
1)、 ArrayBlockingQueue:是一个基于数组结构的有界阻塞队列,此队列按 FIFO(先进先出)原则对元素进行排序。
2)、LinkedBlockingQueue:⼀个基于链表结构的阻塞队列,此队列按 FIFO 排序元素,吞吐量通常要高于ArrayBlockingQueue。静态工厂方法 Executors.newFixedThreadPool() 使用了这个队列。
3)、SynchronousQueue:⼀个不存储元素的阻塞队列。每个插入操作必须等到另⼀个线程调用移除操作,否则插入操作⼀直处于阻塞状态,吞吐量通常要高于 LinkedBlockingQueue,静态工厂方法Executors.newCachedThreadPool 使⽤了这个队列。
4)、 PriorityBlockingQueue:⼀个具有优先级的无限阻塞队列。
f. threadFactory(创建线程池的工厂):用于设置创建线程的工厂,可以通过线程工厂给每个创建出来的线程设置更有意义的名字。
g.RejectExecutionHandler(饱和策略):队列和线程池都满了,说明线程池处于饱和状态,那么必须采取一种策略处理提交的新任务。这个策略默认情况下是 AbortPolicy,表示无法处理新任务时抛出异常。
饱和策略:
在 JDK1.5 中 Java 线程池框架提供了以下 4 种策略:
1. AbortPolicy:直接抛出异常。
2. CallerRunsPolicy:只用调用者所在线程来运行任务。(使用调用者线程来执行任务)
3. DiscardOldestPolicy:将最早进入队列的任务删除,之后再尝试加入队列。
4. DiscardPolicy:不处理,丢弃掉。
③创建线程池的方法
方式⼀:通过 ThreadPoolExecutor 的构造方法实现:
一般使用方式一创建线程:
④线程池中的的线程数一般怎么设置?需要考虑哪些问题?
⑤执行 execute() 方法和 submit() 方法的区别是什么呢?
1、 execute() ⽅法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功与否;
2、 submit() ⽅法用于提交需要返回值的任务。线程池会返回一个 Future 类型的对象,通过这个 Future 对象可以判断任务是否执行成功,并且可以通过 Future 的 get() ⽅法来获取返回值,get() 方法会阻塞当前线程直到任务完成,而使用 get(long timeout,TimeUnit unit) 方法则会阻塞当前线程⼀段时间后立即返回,这时候有可能任务没有执行完。
(5)实现 Runnable 接口和 Callable 接口的区别
Runnable 自 Java 1.0 以来一直存在,但 Callable 仅在 Java 1.5 中引⼊,目的就是为了来处理 Runnable 不支持的用例。 Runnable 接口不会返回结果或抛出检查异常,但是 Callable 接口可以。所以,如果任务不需要返回结果或抛出异常推荐使用 Runnable 接口。
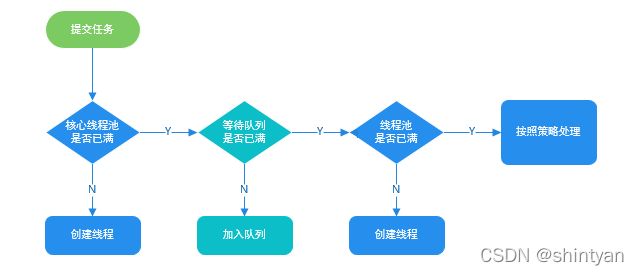
(6)线程池使用实例
public class Test {
public static void main(String[] args) {
ThreadPoolExecutor executor = new ThreadPoolExecutor(5, 10, 200,
TimeUnit.MILLISECONDS,
new ArrayBlockingQueue(5));
for(int i=0;i<15;i++)
{
MyTask myTask = new MyTask(i);
executor.execute(myTask);
System.out.println("线程池中线程数目:"+executor.getPoolSize()+
",队列中等待执行的任务数目:"+ executor.getQueue().size()+
",已执行完别的任务数目:"+executor.getCompletedTaskCount());
}
executor.shutdown();
}
}
class MyTask implements Runnable {
private int taskNum;
public MyTask(int num) {
this.taskNum = num;
}
@Override
public void run() {
System.out.println("正在执行task "+taskNum);
try {
Thread.currentThread().sleep(4000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("task "+taskNum+"执行完毕");
}
} 三、Runnable和Callable
public Future submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
} protected RunnableFuture newTaskFor(Runnable runnable, T value) {
return new FutureTask(runnable, value);
} public void execute(Runnable command) {
...
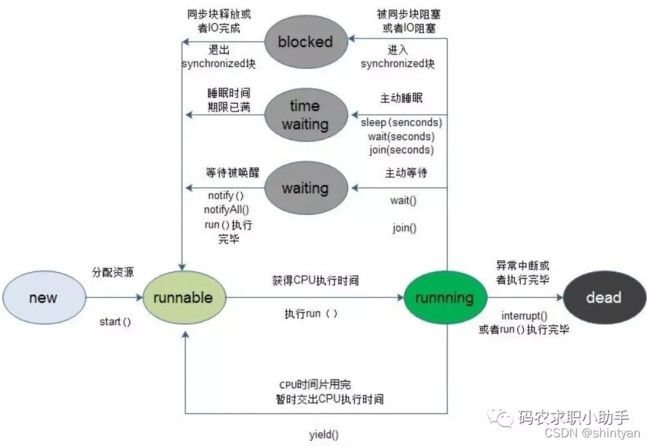
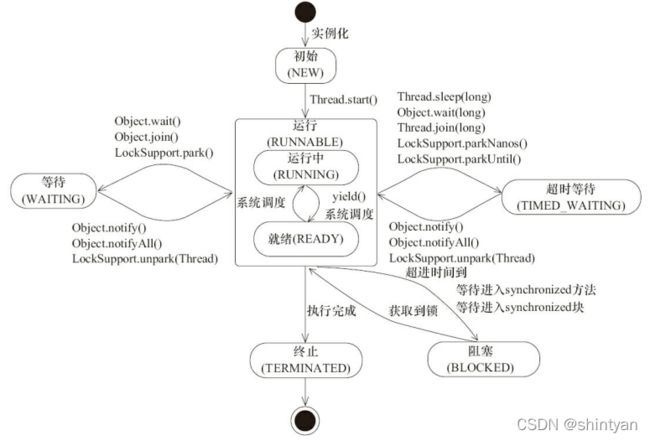
}四、线程状态及转换(生命周期)



五、sleep() 与 wait()
- 调用obj的wait(), notify()方法前,必须获得obj锁,也就是必须写在synchronized(obj) 代码段内。
- 与等待队列相关的步骤和图
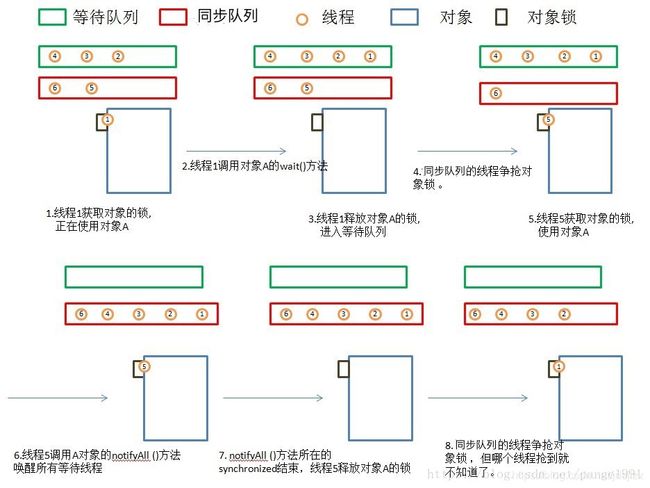
- 线程1获取对象A的锁,正在使用对象A。
- 线程1调用对象A的wait()方法。
- 线程1释放对象A的锁,并马上进入等待队列。
- 锁池里面的对象争抢对象A的锁。
- 线程5获得对象A的锁,进入synchronized块,使用对象A。
- 线程5调用对象A的notifyAll()方法,唤醒所有线程,所有线程进入同步队列。若线程5调用对象A的notify()方法,则唤醒一个线程,不知道会唤醒谁,被唤醒的那个线程进入同步队列。
- notifyAll()方法所在synchronized结束,线程5释放对象A的锁。
- 同步队列的线程争抢对象锁,但线程1什么时候能抢到就不知道了。
同步队列状态
- 当前线程想调用对象A的同步方法时,发现对象A的锁被别的线程占有,此时当前线程进入同步队列。简言之,同步队列里面放的都是想争夺对象锁的线程。
- 当一个线程1被另外一个线程2唤醒时,1线程进入同步队列,去争夺对象锁。
- 同步队列是在同步的环境下才有的概念,一个对象对应一个同步队列。
- 线程等待时间到了或被notify/notifyAll唤醒后,会进入同步队列竞争锁,如果获得锁,进入RUNNABLE状态,否则进入BLOCKED状态等待获取锁。
几个方法的比较
- Thread.sleep(long millis),一定是当前线程调用此方法,当前线程进入TIMED_WAITING状态,但不释放对象锁,millis后线程自动苏醒进入就绪状态。作用:给其它线程执行机会的最佳方式。
- Thread.yield(),一定是当前线程调用此方法,当前线程放弃获取的CPU时间片,但不释放锁资源,由运行状态变为就绪状态,让OS再次选择线程。作用:让相同优先级的线程轮流执行,但并不保证一定会轮流执行。实际中无法保证yield()达到让步目的,因为让步的线程还有可能被线程调度程序再次选中。Thread.yield()不会导致阻塞。该方法与sleep()类似,只是不能由用户指定暂停多长时间。
- thread.join()/thread.join(long millis),当前线程里调用其它线程 t 的join方法,当前线程进入WAITING/TIMED_WAITING状态,当前线程不会释放已经持有的对象锁。线程 t 执行完毕或者millis时间到,当前线程一般情况下进入RUNNABLE状态,也有可能进入BLOCKED状态(因为join是基于wait实现的)。
- obj.wait(),当前线程调用对象的wait()方法,当前线程释放对象锁,进入等待队列。依靠notify()/notifyAll()唤醒或者wait(long timeout) timeout时间到自动唤醒。
- obj.notify()唤醒在此对象监视器上等待的单个线程,选择是任意性的。notifyAll()唤醒在此对象监视器上等待的所有线程。
- LockSupport.park()/LockSupport.parkNanos(long nanos),LockSupport.parkUntil(long deadlines), 当前线程进入WAITING/TIMED_WAITING状态。对比wait方法,不需要获得锁就可以让线程进入WAITING/TIMED_WAITING状态,需要通过LockSupport.unpark(Thread thread)唤醒。
sleep()方法与yield()方法区别:
- sleep()方法暂停当前线程后,会给其他线程执行机会,不会理会其他线程优先级。yield()方法只会给同优先级或更高优先级线程执行机会。
- sleep()方法将当前线程转入阻塞状态,而yield()强制将当前线程转入就绪状态,因此完全可能某个线程调用yield()后立即再次获得CPU资源。
- sleep()方法申明抛出InterruptException异常,要么捕捉要么显示抛出,而yield()没有申明抛出任何异常。
- sleep()比yield()有更好的移植性,不建议yield()控制并发线程执行。
Wait()与Notity()方法
wait(): 持有锁的线程调用wait()方法后,会一直阻塞,直到有别的线程调用notify()将其唤醒
notify(): 只能通知一个等待线程,唤醒任意一个处于wait线程
notifyall():将等待队列中的所有线程唤醒,并加入同步队列
同步(线程间的通信)
object:wait()与notify()必须搭配synchronized使用,使用wait与notify有一个前提,必须在同步方法或同步代码快中使用,必 须拿到相应对象的锁才能调用,否则抛出illegalMonitorStateException
同步队列与等待队列
任意一个object以及其子类对象都有两个队列
同步队列:所有尝试获取该对象Monitor失败的线程,都加入同步队列排队获取锁
等待队列:已经拿到锁的线程在等待其他资源时,主动释放锁,置入该对象等待队列中,等待被唤醒,当调用notify()会在等待队列中任意唤醒一个线程,将其置入同步队列的尾部,排队获取锁 。
六、run() 和 start()
七、Java程序中保证多线程的运行安全
线程的安全性问题体现在:
原子性:一个或者多个操作在 CPU 执行的过程中不被中断的特性
可见性:一个线程对共享变量的修改,另外一个线程能够立刻看到
有序性:程序执行的顺序按照代码的先后顺序执行
导致原因:
缓存导致的可见性问题
线程切换带来的原子性问题
编译优化带来的有序性问题
解决办法:
JDK Atomic开头的原子类、synchronized、LOCK,可以解决原子性问题
synchronized、volatile、LOCK,可以解决可见性问题
Happens-Before 规则可以解决有序性问题
Happens-Before 规则如下:
程序次序规则:在一个线程内,按照程序控制流顺序,书写在前面的操作先行发生于书写在后面的操作
管程锁定规则:一个unlock操作先行发生于后面对同一个锁的lock操作
volatile变量规则:对一个volatile变量的写操作先行发生于后面对这个变量的读操作
线程启动规则:Thread对象的start()方法先行发生于此线程的每一个动作
线程终止规则:线程中的所有操作都先行发生于对此线程的终止检测
线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生
对象终结规则:一个对象的初始化完成(构造函数执行结束)先行发生于它的finalize()方法的开始
八、JAVA线程同步方法
九、Thread.interrupt() 原理
概念
阻塞表示线程的一种状态,在这种状态下,线程是不占用CPU的(也就是说,不执行你写的命令代码的),更进一步来说,也就是你的代码在执行过程中,在某个地方暂停了。
而中断最初的含义是,指计算机运行过程中,出现某些意外情况需主机干预时,机器能自动停止正在运行的程序并转入处理新情况的程序,处理完毕后又返回原被暂停的程序继续运行。但在java中,中断的作用明显被弱化了,中断更多的是指线程标志位的某个状态,而中断的处理逻辑需要用户自己来进行定制(你可以选择处理中断,也可以选择不处理),责任交给了用户。
首先,一个线程不应该由其他线程来强制中断或停止,而是应该由线程自己自行停止。所以,Thread.stop, Thread.suspend, Thread.resume 都已经被废弃了。而 Thread.interrupt 的作用其实也不是中断线程,而是「通知线程应该中断了」,具体到底中断还是继续运行,应该由被通知的线程自己处理。
具体来说,当对一个线程,调用 interrupt() 时,
① 如果线程处于被阻塞状态(例如处于sleep, wait, join 等状态),那么线程将立即退出被阻塞状态,并抛出一个InterruptedException异常。仅此而已。
② 如果线程处于正常活动状态,那么会将该线程的中断标志设置为 true,仅此而已。被设置中断标志的线程将继续正常运行,不受影响。
interrupt() 并不能真正的中断线程,需要被调用的线程自己进行配合才行。也就是说,一个线程如果有被中断的需求,那么就可以这样做。
① 在正常运行任务时,经常检查本线程的中断标志位,如果被设置了中断标志就自行停止线程。
② 在调用阻塞方法时正确处理InterruptedException异常。(例如,catch异常后就结束线程。)
中断的相关方法
public void interrupt() 将调用者线程的中断状态设为true。
public boolean isInterrupted() 判断调用者线程的中断状态。
public static boolean interrupted 只能通过Thread.interrupted()调用。
它会做两步操作:
返回当前线程的中断状态;
将当前线程的中断状态设为false;
十、ThreadLocal、ThreadLocal内存泄漏
public T get() {...}
public void set(T value) {...}
public void remove() {...}
protected T initialValue() {...}public class Thread implements Runnable {
......
//与此线程有关的ThreadLocal值。由ThreadLocal类维护
ThreadLocal.ThreadLocalMap threadLocals = null;
//与此线程有关的InheritableThreadLocal值。由InheritableThreadLocal类维护
ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
......
}public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}ThreadLocalMap(ThreadLocal firstKey, Object firstValue) {
......
}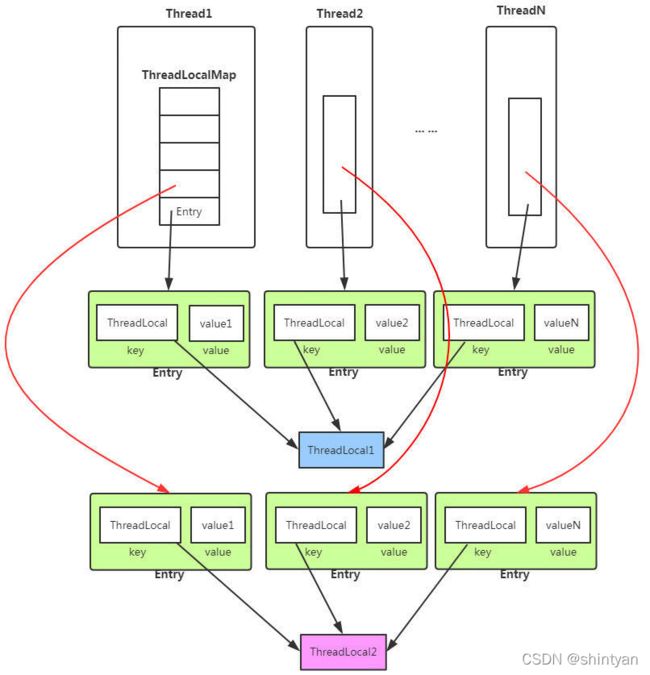
ThreadLocalMap 是 ThreadLocal 的静态内部类

static class Entry extends WeakReference> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal k, Object v) {
super(k);
value = v;
}
} 十一、synchronized —— 使用方式、优化
public class SynchronizedDemo {
public void method(){
synchronized(this){
System.out.println("xin");
}
}
}public class SynchronizedDemo2 {
public synchronized void method() {
System.out.println("xin");
}
}public class Singleton {
private volatile static Singleton uniqueInstance;
private Singleton() {}
public static Singleton getUniqueInstance() {
// 先判断对象是否已经实例过,没有实例化过才进⼊加锁代码
if (uniqueInstance == null) {
// 类对象加锁
synchronized (Singleton.class) {
if (uniqueInstance == null) {
uniqueInstance = new Singleton();
}
}
}
return uniqueInstance;
}
}synchronized void method() {
//业务代码
}synchronized void staic method() {
//业务代码
}synchronized(this) {
//业务代码
}(9) 讲⼀下 synchronized 关键字的底层原理
public class SynchronizedDemo {
public void method() {
synchronized (this) {
System.out.println("synchronized 代码块");
}
}
}public class SynchronizedDemo2 {
public synchronized void method() {
System.out.println("synchronized ⽅法");
}
}十二、volatile
(1)谈⼀下你对 volatile 关键字的理解?
(2)happens-before
在JMM中,如果一个操作执行的结果需要对另一个操作可见,那么这两个操作之间必须存在happens-before关系。
happens-before原则非常重要,它是判断数据是否存在竞争、线程是否安全的主要依据,依靠这个原则,我们解决在并发环境下两操作之间是否可能存在冲突的所有问题。下面我们就一个简单的例子稍微了解下happens-before ;
| 1 2 |
|
j 是否等于1呢?假定线程A的操作(i = 1)happens-before线程B的操作(j = i),那么可以确定线程B执行后j = 1 一定成立,如果他们不存在happens-before原则,那么j = 1 不一定成立。这就是happens-before原则的威力。
1、happens-before原则定义如下:
1. 如果一个操作happens-before另一个操作,那么第一个操作的执行结果将对第二个操作可见,而且第一个操作的执行顺序排在第二个操作之前。
2. 两个操作之间存在happens-before关系,并不意味着一定要按照happens-before原则制定的顺序来执行。如果重排序之后的执行结果与按照happens-before关系来执行的结果一致,那么这种重排序并不非法。
2、下面是happens-before原则规则:
1.程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作;
2.锁定规则:一个unLock操作先行发生于后面对同一个锁的lock操作;
3.volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作;
4.传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C;
5.线程启动规则:Thread对象的start()方法先行发生于此线程的每个一个动作;
6.线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生;
7.线程终结规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行;
8.对象终结规则:一个对象的初始化完成先行发生于他的finalize()方法的开始;
3、我们来详细看看上面每条规则(摘自《深入理解Java虚拟机第12章》):
程序次序规则:一段代码在单线程中执行的结果是有序的。注意是执行结果,因为虚拟机、处理器会对指令进行重排序(重排序后面会详细介绍)。虽然重排序了,但是并不会影响程序的执行结果,所以程序最终执行的结果与顺序执行的结果是一致的。故而这个规则只对单线程有效,在多线程环境下无法保证正确性。
锁定规则:这个规则比较好理解,无论是在单线程环境还是多线程环境,一个锁处于被锁定状态,那么必须先执行unlock操作后面才能进行lock操作。
volatile变量规则:这是一条比较重要的规则,它标志着volatile保证了线程可见性。通俗点讲就是如果一个线程先去写一个volatile变量,然后一个线程去读这个变量,那么这个写操作一定是happens-before读操作的。
传递规则:提现了happens-before原则具有传递性,即A happens-before B , B happens-before C,那么A happens-before C
线程启动规则:假定线程A在执行过程中,通过执行ThreadB.start()来启动线程B,那么线程A对共享变量的修改在接下来线程B开始执行后确保对线程B可见。
线程终结规则:假定线程A在执行的过程中,通过制定ThreadB.join()等待线程B终止,那么线程B在终止之前对共享变量的修改在线程A等待返回后可见。
上面八条是原生Java满足Happens-before关系的规则,但是我们可以对他们进行推导出其他满足happens-before的规则:
- 将一个元素放入一个线程安全的队列的操作Happens-Before从队列中取出这个元素的操作
- 将一个元素放入一个线程安全容器的操作Happens-Before从容器中取出这个元素的操作
- 在CountDownLatch上的倒数操作Happens-Before CountDownLatch#await()操作
- 释放Semaphore许可的操作Happens-Before获得许可操作
- Future表示的任务的所有操作Happens-Before Future#get()操作
- 向Executor提交一个Runnable或Callable的操作Happens-Before任务开始执行操作
这里再说一遍happens-before的概念:如果两个操作不存在上述(前面8条 + 后面6条)任一一个happens-before规则,那么这两个操作就没有顺序的保障,JVM可以对这两个操作进行重排序。如果操作A happens-before操作B,那么操作A在内存上所做的操作对操作B都是可见的。
下面就用一个简单的例子来描述下happens-before原则:
| 1 2 3 4 5 6 7 8 9 |
|
我们约定线程A执行write(),线程B执行read(),且线程A优先于线程B执行,那么线程B获得结果是什么?我们就这段简单的代码一次分析happens-before的规则(规则5、6、7、8 + 推导的6条可以忽略,因为他们和这段代码毫无关系):
- 由于两个方法是由不同的线程调用,所以肯定不满足程序次序规则;
- 两个方法都没有使用锁,所以不满足锁定规则;
- 变量 i 不是用volatile修饰的,所以volatile变量规则不满足;
- 传递规则肯定不满足;
所以我们无法通过happens-before原则推导出线程A happens-before线程B,虽然可以确认在时间上线程A优先于线程B指定,但是就是无法确认线程B获得的结果是什么,所以这段代码不是线程安全的。那么怎么修复这段代码呢?满足规则2、3任一即可。
happen-before原则是JMM中非常重要的原则,它是判断数据是否存在竞争、线程是否安全的主要依据,保证了多线程环境下的可见性。
下图是happens-before与JMM的关系图(摘自《Java并发编程的艺术》)

十三、synchronized 与 ReenTrantLock 、synchronized与volatile
(1)谈谈 synchronized 和 ReenTrantLock 的区别?

(1)synchronized是独占锁,加锁和解锁的过程自动进行,易于操作,但不够灵活。
ReentrantLock也是独占锁,加锁和解锁的过程需要手动进行,不易操作,但非常灵活。
(2)synchronized可重入,因为加锁和解锁自动进行,不必担心最后是否释放锁;
ReentrantLock也可重入,但加锁和解锁需要手动进行,且次数需一样,否则其他线程无法获得锁。
(3)synchronized不可响应中断,一个线程获取不到锁就一直等着;
ReentrantLock可以相应中断。
相同点:
-
1.ReentrantLock和synchronized都是独占锁,只允许线程互斥的访问临界区。但是实现上两者不同:synchronized加锁解锁的过程是隐式的,用户不用手动操作,优点是操作简单,但显得不够灵活。一般并发场景使用synchronized的就够了;ReentrantLock需要手动加锁和解锁,且解锁的操作尽量要放在finally代码块中,保证线程正确释放锁。ReentrantLock操作较为复杂,但是因为可以手动控制加锁和解锁过程,在复杂的并发场景中能派上用场。
-
2.ReentrantLock和synchronized都是可重入的。synchronized因为可重入因此可以放在被递归执行的方法上,且不用担心线程最后能否正确释放锁;而ReentrantLock在重入时要却确保重复获取锁的次数必须和重复释放锁的次数一样,否则可能导致其他线程无法获得该锁。
synchronized 和 volatile 的区别是什么?
十四、ReentrantReadWriteLock
- 读锁的重入是允许多个申请读操作的线程的,而写锁同时只允许单个线程占有,该线程的写操作可以重入。
- 如果一个线程占有了写锁,在不释放写锁的情况下,它还能占有读锁,即写锁降级为读锁。
- 对于同时占有读锁和写锁的线程,如果完全释放了写锁,那么它就完全转换成了读锁,以后的写操作无法重入,在写锁未完全释放时写操作是可以重入的。
- 公平模式下无论读锁还是写锁的申请都必须按照AQS锁等待队列先进先出的顺序。非公平模式下读操作插队的条件是锁等待队列head节点后的下一个节点是SHARED型节点,写锁则无条件插队。
- 读锁不允许newConditon获取Condition接口,而写锁的newCondition接口实现方法同ReentrantLock。
十五、悲观锁和乐观锁、乐观锁常见的两种实现方式、乐观锁的缺点
十六、CAS、CAS 与 synchronized
十七、JAVA中的原子类
AtomicReference等原子类的类,主要用于在高并发环境下的高效程序处理,来帮助我们简化同步处理.
在Java语言中,++i 和 i++操作并不是线程安全的,在使用的时候,不可避免的会用到synchronized关键字。而AtomicInteger则通过一种线程安全的加减操作接口。
//默认值为0
AtomicInteger atomicInteger = new AtomicInteger();
AtomicInteger atomicInteger = new AtomicInteger(0);2.方法
atomicInteger.get(); //获取当前值
atomicInteger.set(999); //设置当前值
AtomicInteger atomicInteger = new AtomicInteger(123);
System.out.println(atomicInteger.get()); --123
System.out.println(atomicInteger.getAndAdd(10)); --123 获取当前值,并加10
System.out.println(atomicInteger.get()); --133
System.out.println(atomicInteger.addAndGet(10)); --143 获取加10后的值,先加10
System.out.println(atomicInteger.get()); --143
AtomicInteger atomicInteger = new AtomicInteger(123);
System.out.println(atomicInteger.get()); --123
System.out.println(atomicInteger.getAndDecrement()); --123 获取当前值并自减
System.out.println(atomicInteger.get()); --122
System.out.println(atomicInteger.decrementAndGet()); --121 先自减再获取减1后的值
System.out.println(atomicInteger.get()); --121//1、创建给定长度的新 AtomicIntegerArray。
AtomicIntegerArray atomicIntegerArray = new AtomicIntegerArray(10);
//2、将位置 i 的元素设置为给定值,默认值为0
atomicIntegerArray.set(9,10);
//3、返回该数组的长度 length()方法:返回该数组的长度
AtomicIntegerArray atomicIntegerArray1 = new AtomicIntegerArray(10);
atomicIntegerArray1.length()
//4、以原子方式先对给定下标加上特定的值,再获取相加后的值
//addAndGet()方法:以原子方式先对给定下标加上特定的值,再获取相加后的值
AtomicIntegerArray atomicIntegerArray2 = new AtomicIntegerArray(10);
atomicIntegerArray2.set(5,10);
atomicIntegerArray2.addAndGet(5,10);
//5、如果当前值 == 预期值,则以原子方式将位置 i 的元素设置为给定的更新值。
//compareAndSet()方法:如果当前值 == 预期值,则以原子方式将位置 i 的元素设置为给定的更新值。
AtomicIntegerArray atomicIntegerArray3 = new AtomicIntegerArray(10);
atomicIntegerArray3.set(5,10);
Boolean bool = atomicIntegerArray3.compareAndSet(5,10,30);
//6、以原子方式先将当前下标的值减1,再获取减1后的结果
//decrementAndGet()方法:以原子方式先将当前下标的值减1,再获取减1后的结果
AtomicIntegerArray atomicIntegerArray4 = new AtomicIntegerArray(10);
atomicIntegerArray4.set(5,10);
Integer result1 = atomicIntegerArray4.decrementAndGet(5);
//getAndAdd()方法:以原子方式先获取当前下标的值,再将当前下标的值加上给定的值
//getAndDecrement()方法:以原子方式先获取当前下标的值,再对当前下标的值减1
//getAndIncrement()方法:以原子方式先获取当前下标的值,再对当前下标的值加1
//getAndSet()方法:将位置 i 的元素以原子方式设置为给定值,并返回旧值。
//incrementAndGet()方法:以原子方式先对下标加1再获取值
AtomicReference atomicReference = new AtomicReference<>(simpleObject);
atomicReference.set()
atomicReference.get()
atomicReference.getAndSet()
atomicReference.compareAndSet() public class AtomicIntegerFieldUpdaterDemo {
public static class Candidate {
int id;
volatile int score = 0;
AtomicInteger score2 = new AtomicInteger();
}
public static final AtomicIntegerFieldUpdater scoreUpdater =
AtomicIntegerFieldUpdater.newUpdater(Candidate.class, "score");
public static AtomicInteger realScore = new AtomicInteger(0);
public static void main(String[] args) throws InterruptedException {
final Candidate candidate = new Candidate();
Thread[] t = new Thread[10000];
for (int i = 0; i < 10000; i++) {
t[i] = new Thread() {
@Override
public void run() {
if (Math.random() > 0.4) {
candidate.score2.incrementAndGet();
scoreUpdater.incrementAndGet(candidate);
realScore.incrementAndGet();
}
}
};
t[i].start();
}
for (int i = 0; i < 10000; i++) {
t[i].join();
}
System.out.println("AtomicIntegerFieldUpdater Score=" + candidate.score);
System.out.println("AtomicInteger Score=" + candidate.score2.get());
System.out.println("realScore=" + realScore.get());
}
}
AtomicIntegerFieldUpdater Score=5897
AtomicInteger Score=5897
realScore=5897 用AtomicIntegerFieldUpdater与AtomicInteger其实效果是一致的
1.从AtomicIntegerFieldUpdaterDemo代码中我们不难发现,通过AtomicIntegerFieldUpdater更新score我们获取最后的int值时相较于AtomicInteger来说不需要调用get()方法!
2.对于AtomicIntegerFieldUpdaterDemo类的AtomicIntegerFieldUpdater是static final类型也就是说即使创建了100个对象AtomicIntegerField也只存在一个不会占用对象的内存,但是AtomicInteger会创建多个AtomicInteger对象,占用的内存比AtomicIntegerFieldUpdater大,所以对于熟悉dubbo源码的人都知道,dubbo有个实现轮询负载均衡策略的类AtomicPositiveInteger用的就是AtomicIntegerFieldUpdater。
十八、atomic原理
十九、AQS
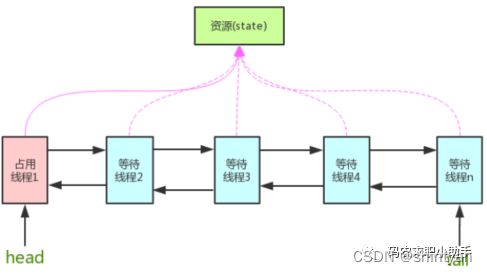
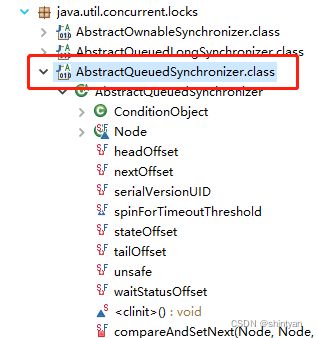
(5)简介

private volatile int state;//共享变量,使⽤volatile修饰保证线程可⻅性状态信息通过 protected 类型的 getState,setState,compareAndSetState 进⾏操作
//返回同步状态的当前值
protected final int getState() {
return state;
}
// 设置同步状态的值
protected final void setState(int newState) {
state = newState;
}
//原⼦地(CAS操作)将同步状态值设置为给定值update如果当前同步状态的值等于expect(期望值)
protected final boolean compareAndSetState(int expect, int update) {
return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
}isHeldExclusively()//该线程是否正在独占资源。只有⽤到condition才需要去实现它。
tryAcquire(int)//独占⽅式。尝试获取资源,成功则返回true,失败则返回false。
tryRelease(int)//独占⽅式。尝试释放资源,成功则返回true,失败则返回false。
tryAcquireShared(int)//共享⽅式。尝试获取资源。负数表示失败;0表示成功,但没有剩余可⽤资
源;正数表示成功,且有剩余资源。
tryReleaseShared(int)//共享⽅式。尝试释放资源,成功则返回true,失败则返回false。二十、信号量Semaphore
二十一、CountDownLatch 与 CyclicBarrier
public class CountDownLatchExample1 {
// 处理⽂件的数量
private static final int threadCount = 6;
public static void main(String[] args) throws InterruptedException {
// 创建⼀个具有固定线程数量的线程池对象(推荐使⽤构造⽅法创建)
ExecutorService threadPool = Executors.newFixedThreadPool(10);
final CountDownLatch countDownLatch = new CountDownLatch(threadCount);
for (int i = 0; i < threadCount; i++) {
final int threadnum = i;
threadPool.execute(() -> {
try {
//处理⽂件的业务操作
......
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
//表示⼀个⽂件已经被完成
countDownLatch.countDown();
}
});
}
countDownLatch.await();
threadPool.shutdown();
System.out.println("finish");
}
}CompletableFuture task1 =
CompletableFuture.supplyAsync(()->{
//⾃定义业务操作
});
......
CompletableFuture task6 =
CompletableFuture.supplyAsync(()->{
//⾃定义业务操作
});
......
CompletableFuture
headerFuture=CompletableFuture.allOf(task1,.....,task6);
try {
headerFuture.join();
} catch (Exception ex) {
......
}
System.out.println("all done. ") //⽂件夹位置
List filePaths = Arrays.asList(...)
// 异步处理所有⽂件
List> fileFutures = filePaths.stream()
.map(filePath -> doSomeThing(filePath))
.collect(Collectors.toList());
// 将他们合并起来
CompletableFuture allFutures = CompletableFuture.allOf(
fileFutures.toArray(new CompletableFuture[fileFutures.size()])
); 二十二、线程池、ThreadPoolExecutor、四种拒绝策略、四个变型
①使用线程池的好处
线程池提供了一种限制和管理资源(包括执行一个任务)的方式。每个线程池还维护一些基本统计信息,例如:已完成任务的数量。
使⽤线程池的好处
1、降低资源消耗:通过重复利用已创建的线程降低线程创建和销毁造成的消耗;
2、 提高响应速度:当任务到达时,任务可以不需要的等到线程创建就能立即执行;
3、 提高线程的可管理性:线程是稀缺资源,如果⽆限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
②创建线程池所需要的参数
public ThreadPoolExecutor( int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
} a.corePoolSize(线程池的基本大小):当提交一个任务到线程池时,如果当前 poolSize < corePoolSize 时,线程池会创建⼀个线程来执行任务,即使其他空闲的基本线程能够执行新任务也会创建线程,等到需要执行的任务数大于线程池基本大小时就不再创建。如果调用了线程池的prestartAllCoreThreads() 方法,线程池会提前创建并启动所有基本线程。
b.maximumPoolSize(线程池最大数量):线程池允许创建的最大线程数。如果队列满了,并且已创建的线程数小于最⼤线程数,则线程池会再创建新的线程执行任务。值得注意的是,如果使用了无界的任务队列这个参数就没什么效果。
c.keepAliveTime(线程活动保持时间):线程池的工作线程空闲后,保持存活的时间。所以,如果任务很多并且每个任务执行的时间比较短,可以调大时间,提高线程的利用率。
d.TimeUnit(线程活动保持时间的单位):可选的单位有天(DAYS)、小时(HOURS)、分钟(MINUTES)、毫秒(MILLISECONDS)、微秒(MICROSECONDS,千分之⼀毫秒)和纳秒(NANOSECONDS,千分之⼀微秒)。
e. workQueue(任务队列):用于保存等待执行的任务的阻塞队列。
可以选择以下几个阻塞队列:
1)、 ArrayBlockingQueue:是一个基于数组结构的有界阻塞队列,此队列按 FIFO(先进先出)原则对元素进行排序。
2)、LinkedBlockingQueue:⼀个基于链表结构的阻塞队列,此队列按 FIFO 排序元素,吞吐量通常要高于ArrayBlockingQueue。静态工厂方法 Executors.newFixedThreadPool() 使用了这个队列。
3)、SynchronousQueue:⼀个不存储元素的阻塞队列。每个插入操作必须等到另⼀个线程调用移除操作,否则插入操作⼀直处于阻塞状态,吞吐量通常要高于 LinkedBlockingQueue,静态工厂方法Executors.newCachedThreadPool 使⽤了这个队列。
4)、 PriorityBlockingQueue:⼀个具有优先级的无限阻塞队列。
f. threadFactory(创建线程池的工厂):用于设置创建线程的工厂,可以通过线程工厂给每个创建出来的线程设置更有意义的名字。
g.RejectExecutionHandler(饱和策略):队列和线程池都满了,说明线程池处于饱和状态,那么必须采取一种策略处理提交的新任务。这个策略默认情况下是 AbortPolicy,表示无法处理新任务时抛出异常。
饱和策略:
在 JDK1.5 中 Java 线程池框架提供了以下 4 种策略:
1. AbortPolicy:直接抛出异常。
2. CallerRunsPolicy:只用调用者所在线程来运行任务。(使用调用者线程来执行任务)
3. DiscardOldestPolicy:将最早进入队列的任务删除,之后再尝试加入队列。
4. DiscardPolicy:不处理,丢弃掉。
③创建线程池的方法
方式⼀:通过 ThreadPoolExecutor 的构造方法实现:

一般使用方式一创建线程:
④线程池中的的线程数一般怎么设置?需要考虑哪些问题?
二十三、execute(),submit()
二十四、JDK中提供了哪些并发容器
二十五、CopyOnWriteArrayList
二十六、BlockingQueue
二十七、ConcurrentSkipListMap
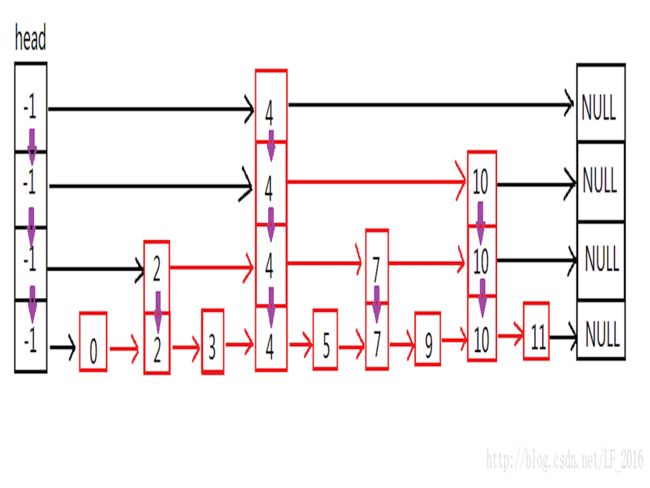
查询:类似于二分查找,二分查询
插入:在第 i 层链表中插入数据的概率是 ![]() 最下层为第0层
最下层为第0层
删除:每一层链表直接删除即可
二十八、上下文切换
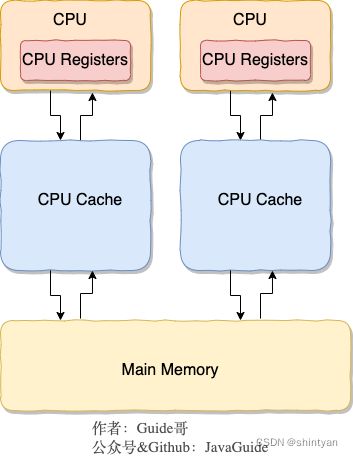
二十九、CPU高速缓存
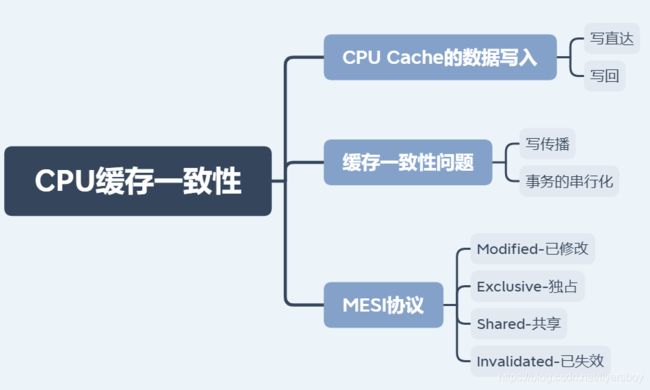
一、CPU Cache的数据写入
随着时间的推移,CPU 和内存的访问性能相差越来越⼤,于是就在 CPU 内部嵌⼊了 CPU Cache(⾼速缓存),CPU Cache 离 CPU 核心相当近,因此它的访问速度是很快的,于是它充当了 CPU 与内存之间的缓存角色。
CPU Cache 通常分为三级缓存:L1 Cache、L2 Cache、L3 Cache,级别越低的离 CPU 核心越近,访问速度也快,但是存储容量相对就会越小。其中,在多核心的 CPU 里,每个核心都有各自的 L1/L2 Cache,而 L3 Cache 是所有核心共享使用的。

CPU Cache 是由很多个 Cache Line 组成的,CPU Line 是 CPU从内存读取数据的基本单位,而 CPU Line 是由各种标志(Tag)+ 数据块(Data Block)组成。

事实上,数据不光是只有读操作,还有写操作,那么如果数据写⼊ Cache 之后,内存与 Cache 相对应的数据将会不同,这种情况下 Cache 和内存数据都不⼀致了,于是我们肯定是要把 Cache 中的数据同步到内存⾥的。
问题来了,那在什么时机才把 Cache中的数据写回到内存呢?为了应对这个问题,下面介绍两种针对写入数据的方法:
写直达(Write Through)与 写回(Write Back)
1、写直达
保持内存与 Cache ⼀致性最简单的⽅式是,把数据同时写⼊内存和 Cache 中,这种方法称为写直达(Write Through)。

在这个方法里,写⼊前会先判断数据是否已经在 CPU Cache 里面了:
如果数据已经在 Cache 里面,先将数据更新到 Cache 里面,再写⼊到内存里面;
如果数据没有在 Cache 里面,就直接把数据更新到内存里面。
【优点】写直达法很直观,也很简单
【缺点】⽆论数据在不在 Cache ⾥⾯,每次写操作都会写回到内存,这样写操作将会花费⼤量的时间,⽆疑性能会受到很⼤的影响。
2、写回
既然写直达由于每次写操作都会把数据写回到内存,⽽导致影响性能,于是为了要减少数据写回内存的频率,就出现了写回(Write Back)的⽅法。
在写回机制中,当发⽣写操作时,新的数据仅仅被写⼊ Cache Block ⾥,只有当修改过的 Cache Block「被替换」时才需要写到内存中,减少了数据写回内存的频率,这样便可以提⾼系统的性能。

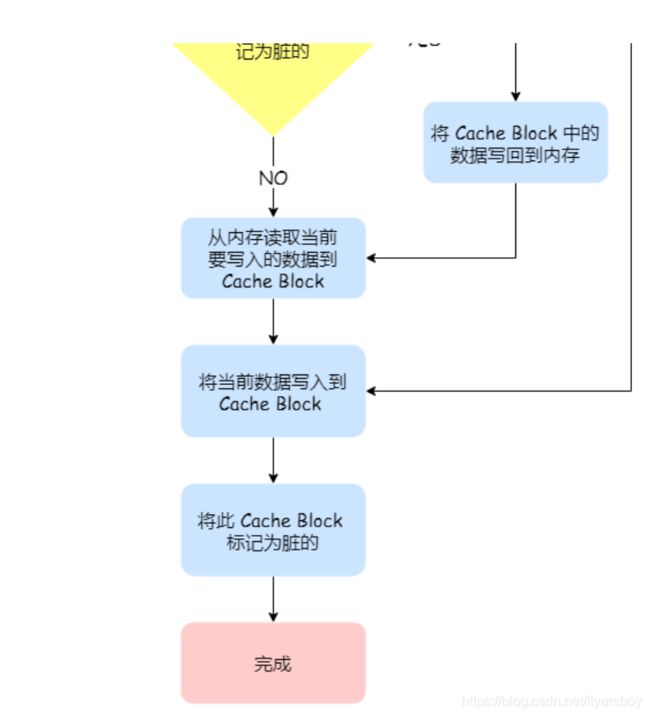
具体步骤:
如果当发⽣写操作时,数据已经在 CPU Cache ⾥的话,则把数据更新到 CPU Cache ⾥,同时标记CPU Cache ⾥的这个 Cache Block 为脏(Dirty)的,这个脏的标记代表这个时候,我们 CPU Cache⾥⾯的这个 Cache Block 的数据和内存是不⼀致的,这种情况是不⽤把数据写到内存⾥的;
如果当发⽣写操作时,数据所对应的 Cache Block ⾥存放的是「别的内存地址的数据」的话,就要检查这个 Cache Block ⾥的数据有没有被标记为脏的,如果是脏的话,我们就要把这个 Cache Block⾥的数据写回到内存,然后再把当前要写⼊的数据,写⼊到这个 Cache Block ⾥,同时也把它标记为脏的;如果 Cache Block ⾥⾯的数据没有被标记为脏,则就直接将数据写⼊到这个 Cache Block⾥,然后再把这个 Cache Block 标记为脏的就好了。
可以发现写回这个⽅法,在把数据写⼊到 Cache 的时候,只有在缓存不命中,同时数据对应的 Cache 中的 Cache Block 为脏标记的情况下,才会将数据写到内存中,而在缓存命中的情况下,则在写⼊后 Cache后,只需把该数据对应的 Cache Block 标记为脏即可,⽽不⽤写到内存⾥。这样的好处是,如果我们⼤量的操作都能够命中缓存,那么⼤部分时间⾥ CPU 都不需要读写内存,⾃然性能相⽐写直达会⾼很多。
二、缓存⼀致性问题
现在 CPU 都是多核的,由于 L1/L2 Cache 是多个核心各⾃独有的,那么会带来多核⼼的缓存⼀致性(Cache Coherence) 的问题,如果不能保证缓存⼀致性的问题,就可能造成结果错误。
那缓存⼀致性的问题具体是怎么发⽣的呢?我们以⼀个含有两个核⼼的 CPU 作为例⼦看⼀看。假设 A 号核心和 B 号核心同时运⾏两个线程,都操作共同的变量 i(初始值为 0 )。
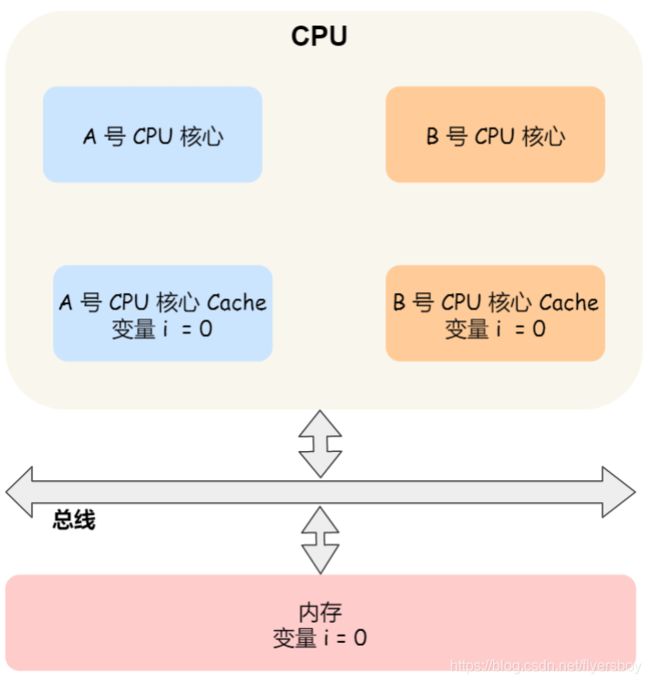
这时如果 A 号核⼼执⾏了 i++ 语句的时候,为了考虑性能,使⽤了我们前⾯所说的写回策略,先把值为1 的执⾏结果写⼊到 L1/L2 Cache 中,然后把 L1/L2 Cache 中对应的 Block 标记为脏的,这个时候数据其实没有被同步到内存中的,因为写回策略,只有在 A 号核⼼中的这个 Cache Block 要被替换的时候,数据才会写⼊到内存⾥。
如果这时旁边的 B 号核⼼尝试从内存读取 i 变量的值,则读到的将会是错误的值,因为刚才 A 号核⼼更新i 值还没写⼊到内存中,内存中的值还依然是 0。这个就是所谓的缓存⼀致性问题,A 号核⼼和 B 号核⼼的缓存,在这个时候是不⼀致,从⽽会导致执⾏结果的错误。

那么,要解决这⼀问题,就需要⼀种机制,来同步两个不同核⼼⾥⾯的缓存数据。要实现的这个机制的话,要保证做到下⾯这 2 点:
第⼀点,某个 CPU 核⼼⾥的 Cache 数据更新时,必须要传播到其他核⼼的 Cache,这个称为写传播(Wreite Propagation);
第⼆点,某个 CPU 核⼼⾥对数据的操作顺序,必须在其他核⼼看起来顺序是⼀样的,这个称为事务的串形化(Transaction Serialization)。
第⼀点写传播很容易就理解,当某个核⼼在 Cache 更新了数据,就需要同步到其他核⼼的 Cache ⾥。
而对于第⼆点事务事的串形化,我们举个例⼦来理解它。
假设我们有⼀个含有 4 个核⼼的 CPU,这 4 个核⼼都操作共同的变量 i(初始值为 0 )。A 号核⼼先把 i 值变为 100,⽽此时同⼀时间,B 号核⼼先把 i 值变为 200,这⾥两个修改,都会「传播」到 C 和 D 号核⼼。
那么问题就来了,C 号核⼼先收到了 A 号核⼼更新数据的事件,再收到 B 号核⼼更新数据的事件,因此 C号核⼼看到的变量 i 是先变成 100,后变成 200。
⽽如果 D 号核⼼收到的事件是反过来的,则 D 号核⼼看到的是变量 i 先变成 200,再变成 100,虽然是做到了写传播,但是各个 Cache ⾥⾯的数据还是不⼀致的。
所以,我们要保证 C 号核⼼和 D 号核⼼都能看到相同顺序的数据变化,⽐如变量 i 都是先变成 100,再变成 200,这样的过程就是事务的串形化。

要实现事务串形化,要做到 2 点:
CPU 核⼼对于 Cache 中数据的操作,需要同步给其他 CPU 核⼼;
要引⼊「锁」的概念,如果两个 CPU 核⼼⾥有相同数据的 Cache,那么对于这个 Cache 数据的更新,只有拿到了「锁」,才能进⾏对应的数据更新。
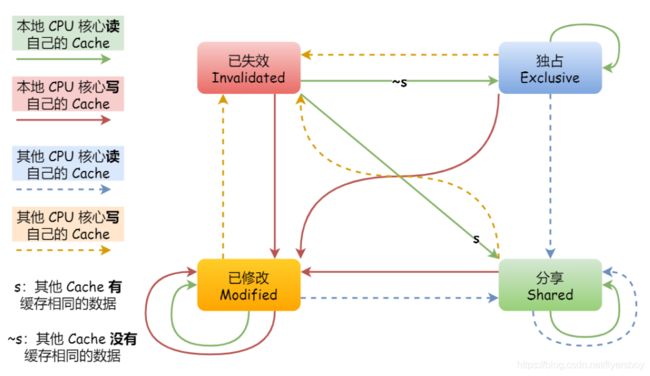
三、MESI 协议
MESI 协议其实是 4 个状态单词的开头字⺟缩写,分别是:
Modified,已修改
Exclusive,独占
Shared,共享
Invalidated,已失效
这四个状态来标记 Cache Line 四个不同的状态。
「已修改」状态就是我们前⾯提到的脏标记,代表该 Cache Block 上的数据已经被更新过,但是还没有写到内存⾥。⽽「已失效」状态,表示的是这个 Cache Block ⾥的数据已经失效了,不可以读取该状态的数据。
「独占」和「共享」状态都代表 Cache Block ⾥的数据是⼲净的,也就是说,这个时候 Cache Block ⾥的数据和内存⾥⾯的数据是⼀致性的。
「独占」和「共享」的差别在于,独占状态的时候,数据只存储在⼀个 CPU 核⼼的 Cache ⾥,⽽其他CPU 核⼼的 Cache 没有该数据。这个时候,如果要向独占的 Cache 写数据,就可以直接⾃由地写⼊,⽽不需要通知其他 CPU 核⼼,因为只有你这有这个数据,就不存在缓存⼀致性的问题了,于是就可以随便操作该数据。
另外,在「独占」状态下的数据,如果有其他核⼼从内存读取了相同的数据到各⾃的 Cache ,那么这个时候,独占状态下的数据就会变成共享状态。
那么,「共享」状态代表着相同的数据在多个 CPU 核⼼的 Cache ⾥都有,所以当我们要更新 Cache ⾥⾯的数据的时候,不能直接修改,⽽是要先向所有的其他 CPU 核⼼⼴播⼀个请求,要求先把其他核⼼的Cache 中对应的 Cache Line 标记为「⽆效」状态,然后再更新当前 Cache ⾥⾯的数据。
举例:
当 A 号 CPU 核⼼从内存读取变量 i 的值,数据被缓存在 A 号 CPU 核⼼⾃⼰的 Cache ⾥⾯,此时其他 CPU 核⼼的 Cache 没有缓存该数据,于是标记 Cache Line 状态为「独占」,此时其 Cache 中的数据与内存是⼀致的;
然后 B 号 CPU 核⼼也从内存读取了变量 i 的值,此时会发送消息给其他 CPU 核⼼,由于 A 号 CPU核⼼已经缓存了该数据,所以会把数据返回给 B 号 CPU 核⼼。在这个时候, A 和 B 核⼼缓存了相同的数据,Cache Line 的状态就会变成「共享」,并且其 Cache 中的数据与内存也是⼀致的;
当 A 号 CPU 核⼼要修改 Cache 中 i 变量的值,发现数据对应的 Cache Line 的状态是共享状态,则要向所有的其他 CPU 核⼼⼴播⼀个请求,要求先把其他核⼼的 Cache 中对应的 Cache Line 标记为「⽆效」状态,然后 A 号 CPU 核⼼才更新 Cache ⾥⾯的数据,同时标记 Cache Line 为「已修改」状态,此时 Cache 中的数据就与内存不⼀致了。
如果 A 号 CPU 核⼼「继续」修改 Cache 中 i 变量的值,由于此时的 Cache Line 是「已修改」状态,因此不需要给其他 CPU 核⼼发送消息,直接更新数据即可。
如果 A 号 CPU 核⼼的 Cache ⾥的 i 变量对应的 Cache Line 要被「替换」,发现 Cache Line 状态是「已修改」状态,就会在替换前先把数据同步到内存。
如果A号CPU核心的Cache里的 i 变量对应的Cache Line状态是「已修改」,A读取到其他的CPU核心要读取变量 i,则把 i 写回到内存,并把状态设置为「共享」。
所以,可以发现当 Cache Line 状态是「已修改」或者「独占」状态时,修改更新其数据不需要发送⼴播给其他 CPU 核⼼,这在⼀定程度上减少了总线带宽压⼒。
事实上,整个 MESI 的状态可以⽤⼀个有限状态机来表示它的状态流转。还有⼀点,对于不同状态触发的事件操作,可能是来⾃本地 CPU 核⼼发出的⼴播事件,也可以是来⾃其他 CPU 核⼼通过总线发出的⼴播事件。下图即是 MESI 协议的状态图:
四、小结
CPU 在读写数据的时候,都是在 CPU Cache 读写数据的,原因是 Cache 离 CPU 很近,读写性能相⽐内存⾼出很多。对于 Cache ⾥没有缓存 CPU 所需要读取的数据的这种情况,CPU 则会从内存读取数据,并将数据缓存到 Cache ⾥⾯,最后 CPU 再从 Cache 读取数据。
⽽对于数据的写⼊,CPU 都会先写⼊到 Cache ⾥⾯,然后再在找个合适的时机写⼊到内存,那就有「写直达」和「写回」这两种策略来保证 Cache 与内存的数据⼀致性:
写直达,只要有数据写⼊,都会直接把数据写⼊到内存⾥⾯,这种⽅式简单直观,但是性能就会受限于内存的访问速度;
写回,对于已经缓存在 Cache 的数据的写⼊,只需要更新其数据就可以,不⽤写⼊到内存,只有在需要把缓存⾥⾯的脏数据交换出去的时候,才把数据同步到内存⾥,这种⽅式在缓存命中率⾼的情况,性能会更好;
当今 CPU 都是多核的,每个核⼼都有各⾃独⽴的 L1/L2 Cache,只有 L3 Cache 是多个核⼼之间共享的。所以,我们要确保多核缓存是⼀致性的,否则会出现错误的结果。
要想实现缓存⼀致性,关键是要满⾜ 2 点:
第⼀点是写传播,也就是当某个 CPU 核⼼发⽣写⼊操作时,需要把该事件⼴播通知给其他核⼼;
第⼆点是事物的串⾏化,这个很重要,只有保证了这个,才能保障我们的数据是真正⼀致的,我们的程序在各个不同的核⼼上运⾏的结果也是⼀致的;
基于总线嗅探机制的 MESI 协议,就满⾜上⾯了这两点,因此它是保障缓存⼀致性的协议。
MESI 协议,是已修改、独占、共享、已实现这四个状态的英⽂缩写的组合。整个 MSI 状态的变更,则是根据来⾃本地 CPU 核⼼的请求,或者来⾃其他 CPU 核⼼通过总线传输过来的请求,从⽽构成⼀个流动的状态机。另外,对于在「已修改」或者「独占」状态的 Cache Line,修改更新其数据不需要发送⼴播给其他 CPU 核⼼。
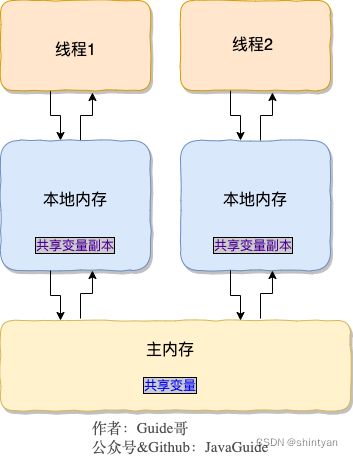
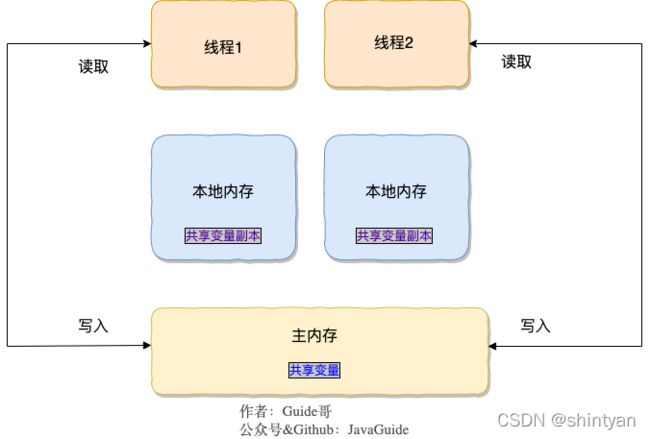
三十、JMM:JAVA内存模型
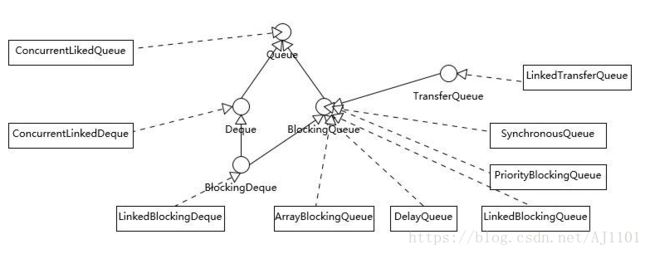
三十一、有界、无界任务队列,手写BlockingQueue
(1)从有界无界上分
常见的有界队列为
- ArrayBlockingQueue 基于数组实现的阻塞队列
- LinkedBlockingQueue 其实也是有界队列,但是不设置大小时就时Integer.MAX_VALUE,内部是基于链表实现的
- ArrayBlockingQueue 与 LinkedBlockingQueue 对比
- ArrayBlockingQueue 实现简单,表现稳定,添加和删除使用同一个锁,通常性能不如后者
- LinkedBlockingQueue 添加和删除两把锁是分开的,所以竞争会小一些
- SynchronousQueue 比较奇葩,内部容量为零,适用于元素数量少的场景,尤其特别适合做交换数据用,内部使用 队列来实现公平性的调度,使用栈来实现非公平的调度,在Java6时替换了原来的锁逻辑,使用CAS代替了
- 上面三个队列他们也是存在共性的
- put take 操作都是阻塞的
- offer poll 操作不是阻塞的,offer 队列满了会返回false不会阻塞,poll 队列为空时会返回null不会阻塞
- 补充一点,并不是在所有场景下,非阻塞都是好的,阻塞代表着不占用CPU,在有些场景也是需要阻塞的,put take 存在必有其存在的必然性
常见的无界队列
- ConcurrentLinkedQueue 无锁队列,底层使用CAS操作,通常具有较高吞吐量,但是具有读性能的不确定性,弱一致性——不存在如ArrayList等集合类的并发修改异常,通俗的说就是遍历时修改不会抛异常
- PriorityBlockingQueue 具有优先级的阻塞队列
- DelayedQueue 延时队列,使用场景
- 缓存:清掉缓存中超时的缓存数据
- 任务超时处理
- 补充:内部实现其实是采用带时间的优先队列,可重入锁,优化阻塞通知的线程元素leader
- LinkedTransferQueue 简单的说也是进行线程间数据交换的利器,在SynchronousQueue 中就有所体现,并且并发大神 Doug Lea 对其进行了极致的优化,使用15个对象填充,加上本身4字节,总共64字节就可以避免缓存行中的伪共享问题,其实现细节较为复杂,可以说一下大致过程:
- 比如消费者线程从一个队列中取元素,发现队列为空,他就生成一个空元素放入队列 , 所谓空元素就是数据项字段为空。然后消费者线程在这个字段上旅转等待。这叫保留。直到一个生产者线程意欲向队例中放入一个元素,这里他发现最前面的元素的数据项字段为 NULL,他就直接把自已数据填充到这个元素中,即完成了元素的传送。大体是这个意思,这种方式优美了完成了线程之间的高效协作。
- 现在也来说一说无界队列的共同点
- put 操作永远都不会阻塞,空间限制来源于系统资源的限制
- 底层都使用CAS无锁编程
(2)JUC中的阻塞队列
| 队列 | 作用 |
| ArrayBlockingQueue | 数组实现的阻塞队列,按照FIFO原则对元素进行排序 |
| LinkedBlockingQueue | 链表实现的有界阻塞队列,默认和最大长度都为Integer.MAX_VALUE。此队列按照FIFO排序 |
| PriorityBlockingQueue | 支持优先级排序,也可以自定义类实现CompareTo()方法指定排序规则 |
| DelayQueue | 优先级队列实现的无界阻塞队列,插入Queue中的数据可以按照自定义的delay时间进行排序。只有delay时间小于0的元素才能够被取出。 |
| SynchronousQueue | 不存储元素的阻塞队列,每一个put都必须等待有个take操作 |
| LinkedTransferQueue | 链表实现的无界阻塞队列 |
| LinkedBlockingDeque | 链表实现的双向阻塞队列 |
(3)阻塞队列的基本操作方法
插入操作
add 添加元素到队列,队列满了,继续插入抛异常
offer 添加元素到队列,返回添加状态
put 当队列满了后继续添加,生产者线程会被阻塞一定的时间,如果超时,则线程直接退出
移除操作
remove 队列为空返回false ,移除成功返回true
poll 队列中存在元素,则取出一个元素,为空则返回false,可设置等待时间
take 基于阻塞的方式返回队列中的元素,如果队列为空,则take方法会一直阻塞,直到队列中有新数据可以消费
Java 中的阻塞队列:
1. ArrayBlockingQueue :由数组结构组成的有界阻塞队列。
2. LinkedBlockingQueue :由链表结构组成的有界阻塞队列。
3. PriorityBlockingQueue :支持优先级排序的无界阻塞队列。
4. DelayQueue:使用优先级队列实现的无界阻塞队列。
5. SynchronousQueue:不存储元素的阻塞队列。
6. LinkedTransferQueue:由链表结构组成的无界阻塞队列。
7. LinkedBlockingDeque:由链表结构组成的双向阻塞队列

(4)ArrayBlockingQueue(公平、非公平)
用数组实现的有界阻塞队列。此队列按照先进先出(FIFO)的原则对元素进行排序。默认情况下不保证访问者公平的访问队列,所谓公平访问队列是指阻塞的所有生产者线程或消费者线程,当队列可用时,可以按照阻塞的先后顺序访问队列,即先阻塞的生产者线程,可以先往队列里插入元素,先阻塞的消费者线程,可以先从队列里获取元素。通常情况下为了保证公平性会降低吞吐量。
我们可以使用以下代码创建一个公平的阻塞队列:
ArrayBlockingQueue fairQueue = new ArrayBlockingQueue(1000,true);
ArrayBlockingQueue的主要属性有:
//存储元素的数组
final Object[] items;
//下一个出队的索引
int takeIndex;
//下一个入队的索引
int putIndex;
//队列的大小
int count;
//可重入锁
final ReentrantLock lock;
//出队操作的等待
private final Condition notEmpty;
//入队操作的等待
private final Condition notFull;
实现原理:通过可重入锁ReenTrantLock+Condition 来实现多线程之间的同步效果
入队过程:
add方法:插入成功返回true;插入失败抛异常
put方法:插入元素到尾部,如果失败则调用Condition.await()方法进行阻塞等待,直到被唤醒;
offer方法:插入元素到尾部,如果失败则直接返回false,
offer(timeout):插入元素到尾部,如果失败则调用Condition.await(timeout)方法进行阻塞等待指定时间,直到被唤醒或阻塞超时,还是失败就返回false
而一旦插入成功,就会唤醒出队的等待操作,执行出队的Condition的signal()方法
出队过程:
主要方法为:poll()、take()、remove()
基本上和入队过程类似,出队结束会唤醒入队的等待操作,执行入队的Condition的signal()方法
而不管是入队操作还是出队操作,都会通过ReentrantLock来控制同步效果,通过两个Condition来控制线程之间的通信效果
另外入队和出队操作分别通过两个索引 takeIndex 和putIndex来指定数组的位置,默认从0开始分别递增,如果达到数组的容量大小,就表示到了数组的边界了,此时再设置index=0,相当于数组是一个环形数组
环形数组的好处是增删数据时不需要挪动数组中的其他数据,只需要改变入队和出队的指针即可。而如果不是环形数组而是顺序数组的话,入队和出队就需要大量移动数据,否则数组空间一下就被用完了,性能较差
(5)LinkedBlockingQueue(两个独立锁提高并发)
基于链表的阻塞队列,同 ArrayBlockingQueue 类似,此队列按照先进先出(FIFO)的原则对元素进行排序。而 LinkedBlockingQueue 之所以能够高效的处理并发数据,还因为其对于生产者端和消费者端分别采用了独立的锁来控制数据同步,这也意味着在高并发的情况下生产者和消费者可以并行地操作队列中的数据,以此来提高整个队列的并发性能。
LinkedBlockingQueue 会默认一个类似无限大小的容量(Integer.MAX_VALUE)。
基本属性:
//队列大小,默认为Integer的最大值
private final int capacity;
//当前队列元素个数
private final AtomicInteger count = new AtomicInteger();
//队列的头部元素
transient LinkedBlockingQueue.Node head;
//队列的尾部元素
private transient LinkedBlockingQueue.Node last;
//出队锁
private final ReentrantLock takeLock = new ReentrantLock();
//出队的condition
private final Condition notEmpty = takeLock.newCondition();
//入队锁
private final ReentrantLock putLock = new ReentrantLock();
//入队的condition
private final Condition notFull = putLock.newCondition();
LinkedBlockingQueue的属性和ArrayBlockingQueue的属性大致差不多,都是通过ReentrantLock和Condition来实现多线程之间的同步,而LinkedBlockingQueue却多了一个ReentrantLock,而不是入队和出队共用同一个锁。
那么为什么ArrayBlockingQueue只需要一个ReentrantLock而LinkedBlockingQueue需要两个ReentrantLock呢?
首先,ArrayBlockingQueue当然可以像LinkedBlockingQueue那样使用两个ReenTrantLock实现。如果使用两个锁,需要考虑到线程并发对count的影响。
为什么没有这么做呢?个人猜想这是设计者考虑到ArrayBlockingQueue底层是使用的数组,而LinkedBlockingQueue底层使用的是链表。
LinkedBlockingQueue添加元素时有一个构造节点的时间,为了尽量减少这部分时间占比,使用一个读锁一个写锁可以实现并发存取的优化。而ArrayBlockingQueue在添加元素时不需要开辟空间等等(创建时指定数组大小),所以反而是加锁解锁时间占比较大,如果继续使用这种读写锁分离的设计,增加的时间损耗大于并发读写带来的收益。
(6)PriorityBlockingQueue(compareTo 排序实现优先)
是一个支持优先级的无界队列。默认情况下元素采取自然顺序升序排列。可以自定义实现compareTo()方法来指定元素进行排序规则,或者初始化 PriorityBlockingQueue 时,指定构造参数 Comparator 来对元素进行排序。需要注意的是不能保证同优先级元素的顺序。
(7)DelayQueue(缓存失效、定时任务 )
是一个支持延时获取元素的无界阻塞队列。队列使用 PriorityQueue 来实现。队列中的元素必须实现 Delayed 接口,在创建元素时可以指定多久才能从队列中获取当前元素。只有在延迟期满时才能从队列中提取元素。我们可以将 DelayQueue 运用在以下应用场景:
1. 缓存系统的设计:可以用 DelayQueue 保存缓存元素的有效期,使用一个线程循环查询DelayQueue,一旦能从 DelayQueue 中获取元素时,表示缓存有效期到了。
2. 定时任务调度:使用 DelayQueue 保存当天将会执行的任务和执行时间,一旦从DelayQueue 中获取到任务就开始执行,从比如 TimerQueue 就是使用 DelayQueue 实现的。
(8)SynchronousQueue(不存储数据、可用于传递数据)
是一个不存储元素的阻塞队列。每一个 put 操作必须等待一个 take 操作,否则不能继续添加元素。
SynchronousQueue 可以看成是一个传球手,负责把生产者线程处理的数据直接传递给消费者线程。队列本身并不存储任何元素,非常适合于传递性场景,比如在一个线程中使用的数据,传递给另 外 一 个 线 程 使 用 , SynchronousQueue 的 吞 吐 量 高 于 LinkedBlockingQueue 和ArrayBlockingQueue。
(9)LinkedTransferQueue
是 一 个 由 链 表 结 构 组 成 的 无 界 阻 塞 TransferQueue 队 列 。 相 对 于 其 他 阻 塞 队 列 ,LinkedTransferQueue 多了 tryTransfer 和 transfer 方法。
1. transfer 方法:如果当前有消费者正在等待接收元素(消费者使用 take()方法或带时间限制的poll()方法时),transfer 方法可以把生产者传入的元素立刻 transfer(传输)给消费者。如果没有消费者在等待接收元素,transfer 方法会将元素存放在队列的 tail 节点,并等到该元素被消费者消费了才返回。
2. tryTransfer 方法。则是用来试探下生产者传入的元素是否能直接传给消费者。如果没有消费者等待接收元素,则返回 false。和 transfer 方法的区别是 tryTransfer 方法无论消费者是否接收,方法立即返回。而 transfer 方法是必须等到消费者消费了才返回。
对于带有时间限制的 tryTransfer(E e, long timeout, TimeUnit unit)方法,则是试图把生产者传入的元素直接传给消费者,但是如果没有消费者消费该元素则等待指定的时间再返回,如果超时还没消费元素,则返回 false,如果在超时时间内消费了元素,则返回 true。
(10)LinkedBlockingDeque
是一个由链表结构组成的双向阻塞队列。所谓双向队列指的你可以从队列的两端插入和移出元素。
双端队列因为多了一个操作队列的入口,在多线程同时入队时,也就减少了一半的竞争。相比其他的阻塞队列,LinkedBlockingDeque 多了 addFirst,addLast,offerFirst,offerLast,peekFirst,peekLast 等方法,以 First 单词结尾的方法,表示插入,获取(peek)或移除双端队列的第一个元素。以 Last 单词结尾的方法,表示插入,获取或移除双端队列的最后一个元素。另外插入方法 add 等同于 addLast,移除方法 remove 等效于 removeFirst。 take 方法等同于 takeFirst。
在初始化 LinkedBlockingDeque 时可以设置容量防止其过渡膨胀。另外双向阻塞队列可以运用在“工作窃取”模式中
入队列 简单示意图:
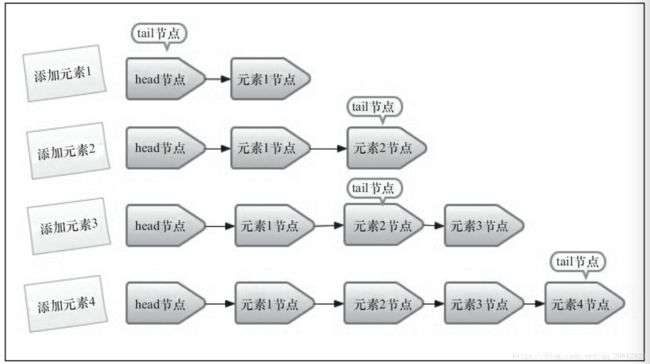 入队列就是将入队节点添加到队列的尾部。
入队列就是将入队节点添加到队列的尾部。
第一步添加元素1。队列更新head节点的next节点为元素1节点。又因为tail节点默认情况下等于head节点,所以它们的next节点都指向元素1节点。
第二步添加元素2。队列首先设置元素1节点的next节点为元素2节点,然后更新tail节点指向元素2节点。
第三步添加元素3,设置tail节点的next节点为元素3节点。
第四步添加元素4,设置元素3的next节点为元素4节点,然后将tail节点指向元素4节点。
(11)简单了解BlockingQueue
在新增的Concurrent包中,BlockingQueue很好的解决了多线程中,如何高效安全“传输”数据的问题。通过这些高效并且线程安全的队列类,为我们快速搭建高质量的多线程程序带来极大的便利。本文详细介绍了BlockingQueue家庭中的所有成员,包括他们各自的功能以及常见使用场景。
阻塞队列,顾名思义,首先它是一个队列,而一个队列在数据结构中所起的作用大致如下图所示:
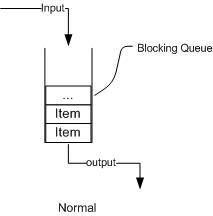
从上图我们可以很清楚看到,通过一个共享的队列,可以使得数据由队列的一端输入,从另外一端输出;
常用的队列主要有以下两种:(当然通过不同的实现方式,还可以延伸出很多不同类型的队列,DelayQueue就是其中的一种)
先进先出(FIFO):先插入的队列的元素也最先出队列,类似于排队的功能。从某种程度上来说这种队列也体现了一种公平性。
后进先出(LIFO):后插入队列的元素最先出队列,这种队列优先处理最近发生的事件。
多线程环境中,通过队列可以很容易实现数据共享,比如经典的“生产者”和“消费者”模型中,通过队列可以很便利地实现两者之间的数据共享。假设我们有若干生产者线程,另外又有若干个消费者线程。如果生产者线程需要把准备好的数据共享给消费者线程,利用队列的方式来传递数据,就可以很方便地解决他们之间的数据共享问题。但如果生产者和消费者在某个时间段内,万一发生数据处理速度不匹配的情况呢?理想情况下,如果生产者产出数据的速度大于消费者消费的速度,并且当生产出来的数据累积到一定程度的时候,那么生产者必须暂停等待一下(阻塞生产者线程),以便等待消费者线程把累积的数据处理完毕,反之亦然。然而,在concurrent包发布以前,在多线程环境下,我们每个程序员都必须去自己控制这些细节,尤其还要兼顾效率和线程安全,而这会给我们的程序带来不小的复杂度。好在此时,强大的concurrent包横空出世了,而他也给我们带来了强大的BlockingQueue。(在多线程领域:所谓阻塞,在某些情况下会挂起线程(即阻塞),一旦条件满足,被挂起的线程又会自动被唤醒),下面两幅图演示了BlockingQueue的两个常见阻塞场景:

如上图所示:当队列中没有数据的情况下,消费者端的所有线程都会被自动阻塞(挂起),直到有数据放入队列。
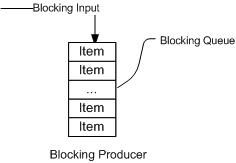
如上图所示:当队列中填满数据的情况下,生产者端的所有线程都会被自动阻塞(挂起),直到队列中有空的位置,线程被自动唤醒。
这也是我们在多线程环境下,为什么需要BlockingQueue的原因。作为BlockingQueue的使用者,我们再也不需要关心什么时候需要阻塞线程,什么时候需要唤醒线程,因为这一切BlockingQueue都给你一手包办了。既然BlockingQueue如此神通广大,让我们一起来见识下它的常用方法:
(12) BlockingQueue的核心方法:
1.放入数据
(1)offer(anObject):表示如果可能的话,将anObject加到BlockingQueue里,即如果BlockingQueue可以容纳,则返回true,否则返回false.(本方法不阻塞当前执行方法的线程);
(2)offer(E o, long timeout, TimeUnit unit):可以设定等待的时间,如果在指定的时间内,还不能往队列中加入BlockingQueue,则返回失败。
(3)put(anObject):把anObject加到BlockingQueue里,如果BlockQueue没有空间,则调用此方法的线程被阻断直到BlockingQueue里面有空间再继续.
2. 获取数据
(1)poll(time):取走BlockingQueue里排在首位的对象,若不能立即取出,则可以等time参数规定的时间,取不到时返回null;
(2)poll(long timeout, TimeUnit unit):从BlockingQueue取出一个队首的对象,如果在指定时间内,队列一旦有数据可取,则立即返回队列中的数据。否则知道时间
超时还没有数据可取,返回失败。
(3)take():取走BlockingQueue里排在首位的对象,若BlockingQueue为空,阻断进入等待状态直到BlockingQueue有新的数据被加入;
(4)drainTo():一次性从BlockingQueue获取所有可用的数据对象(还可以指定获取数据的个数),通过该方法,可以提升获取数据效率;不需要多次分批加锁或释放锁。
(13)常见BlockingQueue
在了解了BlockingQueue的基本功能后,让我们来看看BlockingQueue家庭大致有哪些成员?

1. ArrayBlockingQueue
基于数组的阻塞队列实现,在ArrayBlockingQueue内部,维护了一个定长数组,以便缓存队列中的数据对象,这是一个常用的阻塞队列,除了一个定长数组外,ArrayBlockingQueue内部还保存着两个整形变量,分别标识着队列的头部和尾部在数组中的位置。
ArrayBlockingQueue在生产者放入数据和消费者获取数据,都是共用同一个锁对象,由此也意味着两者无法真正并行运行,这点尤其不同于LinkedBlockingQueue;按照实现原理来分析,ArrayBlockingQueue完全可以采用分离锁,从而实现生产者和消费者操作的完全并行运行。Doug Lea之所以没这样去做,也许是因为ArrayBlockingQueue的数据写入和获取操作已经足够轻巧,以至于引入独立的锁机制,除了给代码带来额外的复杂性外,其在性能上完全占不到任何便宜。 ArrayBlockingQueue和LinkedBlockingQueue间还有一个明显的不同之处在于,前者在插入或删除元素时不会产生或销毁任何额外的对象实例,而后者则会生成一个额外的Node对象。这在长时间内需要高效并发地处理大批量数据的系统中,其对于GC的影响还是存在一定的区别。而在创建ArrayBlockingQueue时,我们还可以控制对象的内部锁是否采用公平锁,默认采用非公平锁。
2.LinkedBlockingQueue
基于链表的阻塞队列,同ArrayListBlockingQueue类似,其内部也维持着一个数据缓冲队列(该队列由一个链表构成),当生产者往队列中放入一个数据时,队列会从生产者手中获取数据,并缓存在队列内部,而生产者立即返回;只有当队列缓冲区达到最大值缓存容量时(LinkedBlockingQueue可以通过构造函数指定该值),才会阻塞生产者队列,直到消费者从队列中消费掉一份数据,生产者线程会被唤醒,反之对于消费者这端的处理也基于同样的原理。而LinkedBlockingQueue之所以能够高效的处理并发数据,还因为其对于生产者端和消费者端分别采用了独立的锁来控制数据同步,这也意味着在高并发的情况下生产者和消费者可以并行地操作队列中的数据,以此来提高整个队列的并发性能。
作为开发者,我们需要注意的是,如果构造一个LinkedBlockingQueue对象,而没有指定其容量大小,LinkedBlockingQueue会默认一个类似无限大小的容量(Integer.MAX_VALUE),这样的话,如果生产者的速度一旦大于消费者的速度,也许还没有等到队列满阻塞产生,系统内存就有可能已被消耗殆尽了。
ArrayBlockingQueue和LinkedBlockingQueue是两个最普通也是最常用的阻塞队列,一般情况下,在处理多线程间的生产者消费者问题,使用这两个类足以。
3. DelayQueue
DelayQueue中的元素只有当其指定的延迟时间到了,才能够从队列中获取到该元素。DelayQueue是一个没有大小限制的队列,因此往队列中插入数据的操作(生产者)永远不会被阻塞,而只有获取数据的操作(消费者)才会被阻塞。
使用场景:
DelayQueue使用场景较少,但都相当巧妙,常见的例子比如使用一个DelayQueue来管理一个超时未响应的连接队列。
4. PriorityBlockingQueue
基于优先级的阻塞队列(优先级的判断通过构造函数传入的Compator对象来决定),但需要注意的是PriorityBlockingQueue并不会阻塞数据生产者,而只会在没有可消费的数据时,阻塞数据的消费者。因此使用的时候要特别注意,生产者生产数据的速度绝对不能快于消费者消费数据的速度,否则时间一长,会最终耗尽所有的可用堆内存空间。在实现PriorityBlockingQueue时,内部控制线程同步的锁采用的是公平锁。
5. SynchronousQueue
一种无缓冲的等待队列,类似于无中介的直接交易,有点像原始社会中的生产者和消费者,生产者拿着产品去集市销售给产品的最终消费者,而消费者必须亲自去集市找到所要商品的直接生产者,如果一方没有找到合适的目标,那么对不起,大家都在集市等待。相对于有缓冲的BlockingQueue来说,少了一个中间经销商的环节(缓冲区),如果有经销商,生产者直接把产品批发给经销商,而无需在意经销商最终会将这些产品卖给那些消费者,由于经销商可以库存一部分商品,因此相对于直接交易模式,总体来说采用中间经销商的模式会吞吐量高一些(可以批量买卖);但另一方面,又因为经销商的引入,使得产品从生产者到消费者中间增加了额外的交易环节,单个产品的及时响应性能可能会降低。
声明一个SynchronousQueue有两种不同的方式,它们之间有着不太一样的行为。公平模式和非公平模式的区别:
如果采用公平模式:SynchronousQueue会采用公平锁,并配合一个FIFO队列来阻塞多余的生产者和消费者,从而体系整体的公平策略;
但如果是非公平模式(SynchronousQueue默认):SynchronousQueue采用非公平锁,同时配合一个LIFO队列来管理多余的生产者和消费者,而后一种模式,如果生产者和消费者的处理速度有差距,则很容易出现饥渴的情况,即可能有某些生产者或者是消费者的数据永远都得不到处理。
(14)手写BlockingQueue
1、数组
public interface BlockingQueue {
void put(T element) throws InterruptedException;
T take() throws InterruptedException;
}
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class MiniBlockingQueue implements BlockingQueue{
//底层是一个数组
private Object[] elementData;
private int size;
public MiniBlockingQueue(int size) {
this.elementData = new Object[size];
this.size = size;
}
//当前队列中的元素个数, put时的指针索引, take时的指针索引
private int count , putIndex, takeIndex;
private Lock lock = new ReentrantLock();
private Condition fullCondition = lock.newCondition();
private Condition emptyCondition = lock.newCondition();
@Override
public void put(T element) throws InterruptedException {
lock.lock();
try {
//当阻塞队列满时 该put的线程需要进入条件队列中等待
if (count == size){
fullCondition.await();
}
elementData[putIndex] = element;
putIndex++;
count++;
if (putIndex == size) putIndex = 0;
//通知take阻塞的线程来消费
emptyCondition.signal();
} finally {
lock.unlock();
}
}
@Override
public T take() throws InterruptedException {
lock.lock();
try {
//当队列为空时,需要进入条件队列中等待
if (count == 0){
emptyCondition.await();
}
Object element = elementData[takeIndex];
takeIndex++;
count--;
if (takeIndex == size) takeIndex = 0;
fullCondition.signal();
return (T) element;
} finally {
lock.unlock();
}
}
2、链表
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class LinkedBlockingQueueV1 {
private NodeV1 head;
private NodeV1 tail;
private Lock lock = new ReentrantLock();
private Condition full = lock.newCondition();
private Condition empty = lock.newCondition();
private int capacity;
private int count = 0;
public LinkedBlockingQueueV1() {
this(Integer.MAX_VALUE);
}
public LinkedBlockingQueueV1(int capacity) {
this.capacity = capacity;
NodeV1 e = new NodeV1(null);
head = tail = e;
}
public void put(E e) throws InterruptedException {
lock.lock();
try {
while (count == capacity)
full.await();
enqueue(e);
} finally {
lock.unlock();
}
}
public E take() throws InterruptedException {
lock.lock();
try {
while (count == 0)
empty.await();
return dequeue();
} finally {
lock.unlock();
}
}
private E dequeue() {
NodeV1 h = head;
NodeV1 first = h.next;
h.next = first.next;
E data = first.data;
first = null;
count--;
full.signalAll();
return data;
}
private void enqueue(E e) {
NodeV1 node = new NodeV1(e);
tail = tail.next = node;
count++;
empty.signalAll();
}
}
class NodeV1 {
public E data;
public NodeV1 next;
public NodeV1(E data) {
this.data = data;
}
}
3、Condition实现
Condition由ReentrantLock对象创建,并且可以同时创建多个
static Condition notEmpty = lock.newCondition();
static Condition notFull = lock.newCondition();
Condition接口在使用前必须先调用ReentrantLock的lock()方法获得锁。之后调用Condition接口的await()将释放锁,并且在该Condition上等待,直到有其他线程调用Condition的signal()方法唤醒线程。使用方式和wait,notify类似。
- 一个使用condition的简单例子
public class ConditionTest {
static ReentrantLock lock = new ReentrantLock();
static Condition condition = lock.newCondition();
public static void main(String[] args) throws InterruptedException {
lock.lock();
new Thread(new SignalThread()).start();
System.out.println("主线程等待通知");
try {
condition.await();
} finally {
lock.unlock();
}
System.out.println("主线程恢复运行");
}
static class SignalThread implements Runnable {
@Override
public void run() {
lock.lock();
try {
condition.signal();
System.out.println("子线程通知");
} finally {
lock.unlock();
}
}
}
}阻塞队列是一种特殊的先进先出队列,它有以下几个特点
1.入队和出队线程安全
2.当队列满时,入队线程会被阻塞;当队列为空时,出队线程会被阻塞。
- 阻塞队列的简单实现
public class MyBlockingQueue {
int size;//阻塞队列最大容量
ReentrantLock lock = new ReentrantLock();
LinkedList list=new LinkedList<>();//队列底层实现
Condition notFull = lock.newCondition();//队列满时的等待条件
Condition notEmpty = lock.newCondition();//队列空时的等待条件
public MyBlockingQueue(int size) {
this.size = size;
}
public void enqueue(E e) throws InterruptedException {
lock.lock();
try {
while (list.size() ==size)//队列已满,在notFull条件上等待
notFull.await();
list.add(e);//入队:加入链表末尾
System.out.println("入队:" +e);
notEmpty.signal(); //通知在notEmpty条件上等待的线程
} finally {
lock.unlock();
}
}
public E dequeue() throws InterruptedException {
E e;
lock.lock();
try {
while (list.size() == 0)//队列为空,在notEmpty条件上等待
notEmpty.await();
e = list.removeFirst();//出队:移除链表首元素
System.out.println("出队:"+e);
notFull.signal();//通知在notFull条件上等待的线程
return e;
} finally {
lock.unlock();
}
}
}
三十二、锁升级
(1)Synchronized锁的3种使用形式(使用场景):
Synchronized修饰普通同步方法:锁对象当前实例对象;
Synchronized修饰静态同步方法:锁对象是当前的类Class对象;
Synchronized修饰同步代码块:锁对象是Synchronized后面括号里配置的对象,这个对象可以是某个对象(xlock),也可以是某个类(Xlock.class);
注意:
使用synchronized修饰非静态方法或者使用synchronized修饰代码块时制定的为实例对象时,同一个类的不同对象拥有自己的锁,因此不会相互阻塞。
使用synchronized修饰类和对象时,由于类对象和实例对象分别拥有自己的监视器锁,因此不会相互阻塞。
使用使用synchronized修饰实例对象时,如果一个线程正在访问实例对象的一个synchronized方法时,其它线程不仅不能访问该synchronized方法,该对象的其它synchronized方法也不能访问,因为一个对象只有一个监视器锁对象,但是其它线程可以访问该对象的非synchronized方法。
线程A访问实例对象的非static synchronized方法时,线程B也可以同时访问实例对象的static synchronized方法,因为前者获取的是实例对象的监视器锁,而后者获取的是类对象的监视器锁,两者不存在互斥关系。
(2)锁的前置知识
(1)锁的类型
锁从宏观上分类,分为悲观锁与乐观锁。
乐观锁
乐观锁是一种乐观思想,即认为读多写少,遇到并发写的可能性低。每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,采取在写时先读出当前版本号,然后加锁操作(比较跟上一次的版本号,如果一样则更新),如果失败则要重复读-比较-写的操作。
java中的乐观锁基本都是通过CAS操作实现的,CAS是一种更新的原子操作,比较当前值跟传入值是否一样,一样则更新,否则失败。
悲观锁
悲观锁是就是悲观思想,即认为写多,遇到并发写的可能性高。每次去拿数据的时候都认为别人会修改,所以每次在读写数据的时候都会上锁,这样别人想读写这个数据就会阻塞(block)直到拿到锁。
java中的悲观锁就是Synchronized、AQS框架下的锁则是先尝试CAS乐观锁去获取锁,获取不到才会转换为悲观锁,如:ReentrantLock。
(2)线程阻塞的代价
java的线程是映射到操作系统原生线程之上的,如果要阻塞或唤醒一个线程就需要操作系统介入,需要在用户态与核心态之间切换,这种切换会消耗大量的系统资源。因为用户态与内核态都有各自专用的内存空间,专用的寄存器等,用户态切换至内核态需要传递给许多变量、参数给内核,内核也需要保护好用户态在切换时的一些寄存器值、变量等,以便内核态调用结束后切换回用户态继续工作。
- 如果线程状态切换是一个高频操作时,这将会消耗很多CPU处理时间;
- 如果对于那些需要同步的简单的代码块,获取锁挂起操作消耗的时间比用户代码执行的时间还要长,这种同步策略显然非常糟糕的。
synchronized会导致争用不到锁的线程进入阻塞状态,所以说它是java语言中一个重量级的同步操纵,被称为重量级锁。为了缓解上述性能问题【synchronized】,JVM从1.5开始,引入了轻量锁与偏向锁,默认启用了自旋锁,他们都属于乐观锁。
明确java线程切换的代价,是理解java中各种锁的优缺点的基础之一。
(3)Mark Word
对象的markword和java各种类型的锁密切相关;
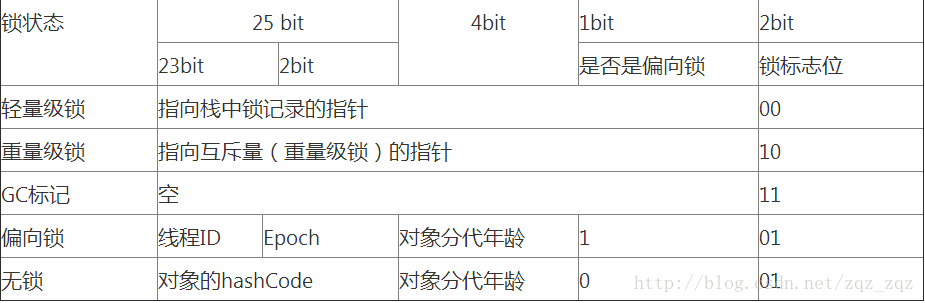
markword数据的长度在32位和64位的虚拟机(未开启压缩指针)中分别为32bit和64bit,它的最后2bit是锁状态标志位,用来标记当前对象的状态,对象的所处的状态,决定了markword存储的内容,如下表所示:
| 状态 | 标志位 | 存储内容 |
|---|---|---|
| 未锁定 | 01 | 对象哈希码、对象分代年龄 |
| 轻量级锁定 | 00 | 指向锁记录的指针 |
| 膨胀(重量级锁定) | 10 | 执行重量级锁定的指针 |
| GC标记 | 11 | 空(不需要记录信息) |
| 可偏向 | 01 | 偏向线程ID、偏向时间戳、对象分代年龄 |
32位虚拟机在不同状态下markword结构如下图所示:
了解了markword结构,有助于后面了解java锁的加锁解锁过程;
前面提到了java的4种锁,他们分别是重量级锁、自旋锁、轻量级锁和偏向锁。不同的锁有不同特点,每种锁只有在其特定的场景下,才会有出色的表现,java中没有哪种锁能够在所有情况下都能有出色的效率,引入这么多锁的原因就是为了应对不同的情况;
(3)Java中的锁偏向锁
Java偏向锁(Biased Locking)是Java6引入的一项多线程优化,它通过消除资源无竞争情况下的同步原语,进一步提高了程序的运行性能。
偏向锁,顾名思义它会偏向于第一个访问锁的线程,如果在运行过程中,同步锁只有一个线程访问,不存在多线程争用的情况,则线程是不需要触发同步的,这种情况下,就会给线程加一个偏向锁。
如果在运行过程中,遇到了其他线程抢占锁,则持有偏向锁的线程会被挂起,JVM会消除它身上的偏向锁,将锁恢复到标准的轻量级锁。
偏向锁获取过程
- 访问Mark Word中偏向锁的标识是否设置成1,锁标志位是否为01,确认为可偏向状态。
- 如果为可偏向状态,则测试线程ID是否指向当前线程,如果是,进入步骤5,否则进入步骤3。
- 如果线程ID并未指向当前线程,则通过CAS操作竞争锁。如果竞争成功,则将Mark Word中线程ID设置为当前线程ID,然后执行5;如果竞争失败,执行4。
- 如果CAS获取偏向锁失败,则表示有竞争。当到达全局安全点(safepoint)时获得偏向锁的线程被挂起,偏向锁升级为轻量级锁,然后被阻塞在安全点的线程继续往下执行同步代码。(撤销偏向锁的时候会导致stop the world)
- 执行同步代码。
注意:第四步中到达安全点safepoint会导致stop the world,时间很短。
偏向锁获取过程
偏向锁的撤销在上述第四步骤中有提到。偏向锁只有遇到其他线程尝试竞争偏向锁时,持有偏向锁的线程才会释放锁,线程不会主动去释放偏向锁。偏向锁的撤销,需要等待全局安全点(在这个时间点上没有字节码正在执行),它会首先暂停拥有偏向锁的线程,判断锁对象是否处于被锁定状态,撤销偏向锁后恢复到未锁定(标志位为“01”)或轻量级锁(标志位为“00”)的状态。
偏向锁的适用场景
始终只有一个线程在执行同步块,在它没有执行完释放锁之前,没有其它线程去执行同步块,在锁无竞争的情况下使用,一旦有了竞争就升级为轻量级锁,升级为轻量级锁的时候需要撤销偏向锁,撤销偏向锁的时候会导致stop the world操作;
在有锁的竞争时,偏向锁会多做很多额外操作,尤其是撤销偏向锁的时候会导致进入安全点,安全点会导致stw,导致性能下降,这种情况下应当禁用。
Jvm开启/关闭偏向锁
- 开启偏向锁:
-XX:+UseBiasedLocking-XX:BiasedLockingStartupDelay=0 - 关闭偏向锁:
-XX:-UseBiasedLocking
(4)轻量级锁
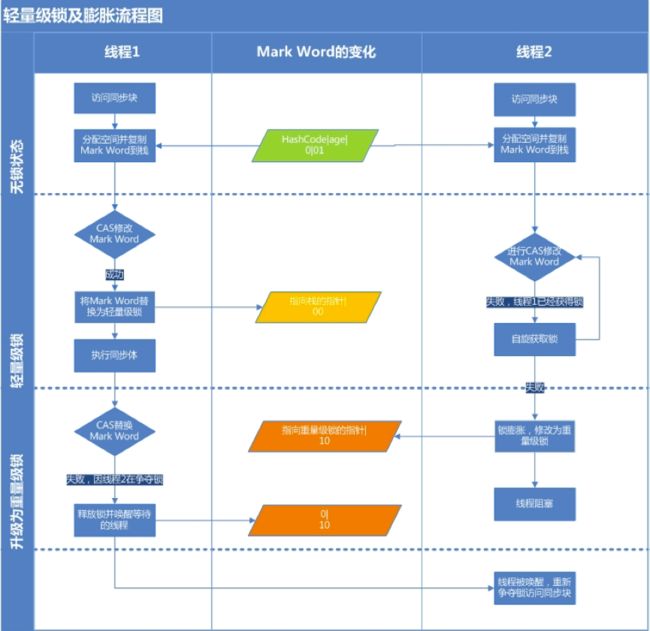
轻量级锁是由偏向锁升级来的,偏向锁运行在一个线程进入同步块的情况下,当第二个线程加入锁争用的时候,偏向锁就会升级为轻量级锁;
轻量级锁加锁过程
-
在代码进入同步块的时候,如果同步对象锁状态为无锁状态(锁标志位为“01”状态,是否为偏向锁为“0”),虚拟机首先将在当前线程的栈帧中建立一个名为锁记录(Lock Record)的空间,用于存储锁对象目前的Mark Word的拷贝,官方称之为 Displaced Mark Word。这时候线程堆栈与对象头的状态如图所示:
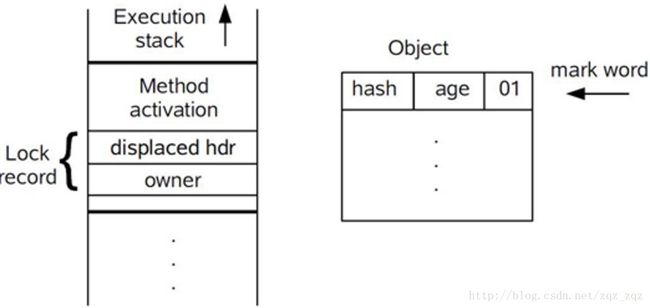
-
拷贝对象头中的Mark Word复制到锁记录中;
-
拷贝成功后,虚拟机将使用CAS操作尝试将对象的Mark Word更新为指向Lock Record的指针,并将Lock record里的owner指针指向object mark word。如果更新成功,则执行步骤4,否则执行步骤5。
-
如果这个更新动作成功了,那么这个线程就拥有了该对象的锁,并且对象Mark Word的锁标志位设置为“00”,即表示此对象处于轻量级锁定状态,这时候线程堆栈与对象头的状态如图所示:
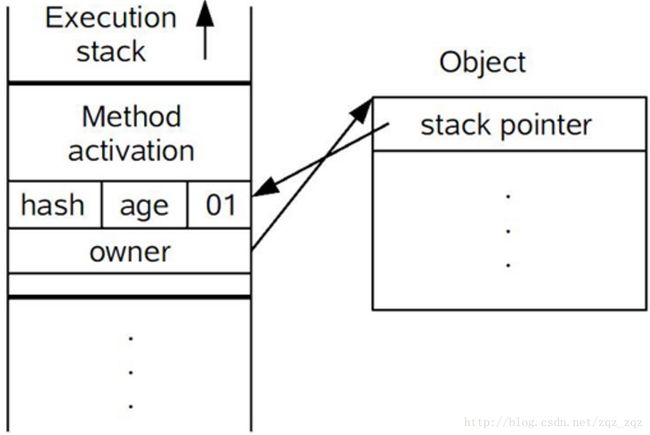
-
如果这个更新操作失败了,虚拟机首先会检查对象的Mark Word是否指向当前线程的栈帧,如果是就说明当前线程已经拥有了这个对象的锁,那就可以直接进入同步块继续执行。否则说明多个线程竞争锁,轻量级锁就要膨胀为重量级锁,锁标志的状态值变为“10”,Mark Word中存储的就是指向重量级锁(互斥量)的指针,后面等待锁的线程也要进入阻塞状态。 而当前线程便尝试使用自旋来获取锁,自旋就是为了不让线程阻塞,而采用循环去获取锁的过程。
轻量级锁释放过程
释放锁线程视角:由轻量锁切换到重量锁,是发生在轻量锁释放锁的期间,之前在获取锁的时候它拷贝了锁对象头的markword,在释放锁的时候如果它发现在它持有锁的期间有其他线程来尝试获取锁了,并且该线程对markword做了修改,两者比对发现不一致,则切换到重量锁。
因为重量级锁被修改了,所有display mark word和原来的markword不一样了。怎么补救?就是进入mutex前,compare一下obj的markword状态,确认该markword是否被其他线程持有。此时如果线程已经释放了markword,那么通过CAS后就可以直接进入线程,无需进入mutex,就这个作用。
尝试获取锁线程视角:如果线程尝试获取锁的时候,轻量锁正被其他线程占有,那么它就会修改markword,修改重量级锁,表示该进入重量锁了。
还有一个注意点:等待轻量锁的线程不会阻塞,它会一直自旋等待锁,并如上所说修改markword。
这就是自旋锁,尝试获取锁的线程,在没有获得锁的时候,不被挂起,而转而去执行一个空循环,即自旋。在若干个自旋后,如果还没有获得锁,则才被挂起,获得锁,则执行代码。
(5)自旋锁
自旋锁原理非常简单,如果持有锁的线程能在很短时间内释放锁资源,那么那些等待竞争锁的线程就不需要做内核态和用户态之间的切换进入阻塞挂起状态,它们只需要等一等(自旋),等持有锁的线程释放锁后即可立即获取锁,这样就避免用户线程和内核的切换的消耗。
但是线程自旋是需要消耗CPU的,说白了就是让CPU在做无用功,如果一直获取不到锁,那线程也不能一直占用CPU自旋做无用功,所以需要设定一个自旋等待的最大时间。如果持有锁的线程执行的时间超过自旋等待的最大时间扔没有释放锁,就会导致其它争用锁的线程在最大等待时间内还是获取不到锁,这时争用线程会停止自旋进入阻塞状态。
自旋锁的优缺点
优:自旋锁尽可能的减少线程的阻塞,这对于锁的竞争不激烈,且占用锁时间非常短的代码块来说性能能大幅度的提升,因为自旋的消耗会小于线程阻塞挂起再唤醒的操作的消耗,这些操作会导致线程发生两次上下文切换!
缺:但是如果锁的竞争激烈,或者持有锁的线程需要长时间占用锁执行同步块,这时候就不适合使用自旋锁了,因为自旋锁在获取锁前一直都是占用cpu做无用功,占着茅坑又不拉屎,同时有大量线程在竞争一个锁,会导致获取锁的时间很长,线程自旋的消耗大于线程阻塞挂起操作的消耗,其它需要CPU的线程又不能获取到cpu,造成cpu的浪费。所以这种情况下我们要关闭自旋锁;
自旋锁时间阈值
自旋锁的目的是为了占着CPU的资源不释放,等到获取到锁立即进行处理。但是如何去选择自旋的执行时间呢?如果自旋执行时间太长,会有大量的线程处于自旋状态占用CPU资源,进而会影响整体系统的性能。因此自旋的周期选的额外重要!
JVM对于自旋周期的选择,jdk1.5这个限度是一定的写死的,在1.6引入了适应性自旋锁,适应性自旋锁意味着自旋的时间不在是固定的了,而是由前一次在同一个锁上的自旋时间以及锁的拥有者的状态来决定,基本认为一个线程上下文切换的时间是最佳的一个时间,同时JVM还针对当前CPU的负荷情况做了较多的优化:
- 如果平均负载小于CPUs则一直自旋;
- 如果有超过(CPUs/2)个线程正在自旋,则后来线程直接阻塞;
- 如果正在自旋的线程发现Owner发生了变化则延迟自旋时间(自旋计数)或进入阻塞;
- 如果CPU处于节电模式则停止自旋;
- 自旋时间的最坏情况是CPU的存储延迟(CPU A存储了一个数据,到CPU B得知这个数据直接的时间差);
- 自旋时会适当放弃线程优先级之间的差异;
自旋锁的开启
JDK1.6中 -XX:+UseSpinning 开启;-XX:PreBlockSpin=10 为自旋次数;
JDK1.7后,去掉此参数,由jvm控制;
(6)重量级锁Synchronized
在JDK1.5之前都是使用synchronized关键字保证同步的,它可以保证方法或者代码块在运行时,同一时刻只有一个方法可以进入到临界区,同时它还可以保证共享变量的内存可见性。
- 普通同步方法,锁是当前实例对象 ;
- 静态同步方法,锁是当前类的class对象 ;
- 同步方法块,锁是括号里面的对象;
Synchronized的实现
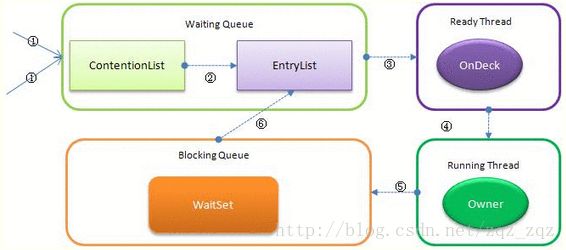
它有多个队列,当多个线程一起访问某个对象监视器的时候,对象监视器会将这些线程存储在不同的容器中。
- Contention List:竞争队列,所有请求锁的线程首先被放在这个竞争队列中;
- Entry List:候选者队列 ,Contention List中那些有资格成为候选资源的线程被移动到Entry List中;
- Wait Set:阻塞队列,哪些调用wait方法被阻塞的线程被放置在这里;
- OnDeck:任意时刻,最多只有一个线程正在竞争锁资源,该线程被成为OnDeck;
- Owner:当前已经获取到所资源的线程被称为Owner;
- !Owner:当前释放锁的线程。
JVM每次从队列的尾部取出一个数据用于锁竞争候选者(OnDeck),但是并发情况下,ContentionList会被大量的并发线程进行CAS访问,为了降低对尾部元素的竞争,JVM会将一部分线程移动到EntryList中作为候选竞争线程。Owner线程会在unlock时,将ContentionList中的部分线程迁移到EntryList中,并指定EntryList中的某个线程为OnDeck线程(一般是最先进去的那个线程)。Owner线程并不直接把锁传递给OnDeck线程,而是把锁竞争的权利交给OnDeck,OnDeck需要重新竞争锁。这样虽然牺牲了一些公平性,但是能极大的提升系统的吞吐量,在JVM中,也把这种选择行为称之为“竞争切换”。
OnDeck线程获取到锁资源后会变为Owner线程,而没有得到锁资源的仍然停留在EntryList中。如果Owner线程被wait方法阻塞,则转移到WaitSet队列中,直到某个时刻通过notify或者notifyAll唤醒,会重新进去EntryList中。
处于ContentionList、EntryList、WaitSet中的线程都处于阻塞状态,该阻塞是由操作系统来完成的(Linux内核下采用pthread_mutex_lock内核函数实现的)。
Synchronized是非公平锁,在线程进入ContentionList时,等待的线程会先尝试自旋获取锁,如果获取不到就进入ContentionList,这明显对于已经进入队列的线程是不公平的,还有一个不公平的事情就是自旋获取锁的线程还可能直接抢占OnDeck线程的锁资源。
Synchronized锁的演变过程
- 检测Mark Word里面是不是当前线程的ID,如果是则表示当前线程处于偏向锁;
- 如果不是,则使用CAS将当前线程的ID替换Mard Word,如果成功则表示当前线程获得偏向锁,置偏向标志位1;
- 如果失败,则说明发生竞争,撤销偏向锁,进而升级为轻量级锁;
- 当前线程使用CAS将对象头的Mark Word替换为锁记录指针,如果成功,当前线程获得锁;
- 如果失败,表示其他线程竞争锁,当前线程便尝试使用自旋来获取锁;
- 如果自旋成功则依然处于轻量级状态;
- 如果自旋失败,则升级为重量级锁;
在所有的锁都启用的情况下线程进入临界区时会先去获取偏向锁,如果已经存在偏向锁了,则会尝试获取轻量级锁,启用自旋锁,如果自旋也没有获取到锁,则使用重量级锁,没有获取到锁的线程阻塞挂起,直到持有锁的线程执行完同步块唤醒他们;
偏向锁是在无锁争用的情况下使用的,也就是同步开在当前线程没有执行完之前,没有其它线程会执行该同步块,一旦有了第二个线程的争用,偏向锁就会升级为轻量级锁,如果轻量级锁自旋到达阈值后,没有获取到锁,就会升级为重量级锁;
注意:如果线程争用激烈,那么应该禁用偏向锁。

三十三、JAVA中的锁
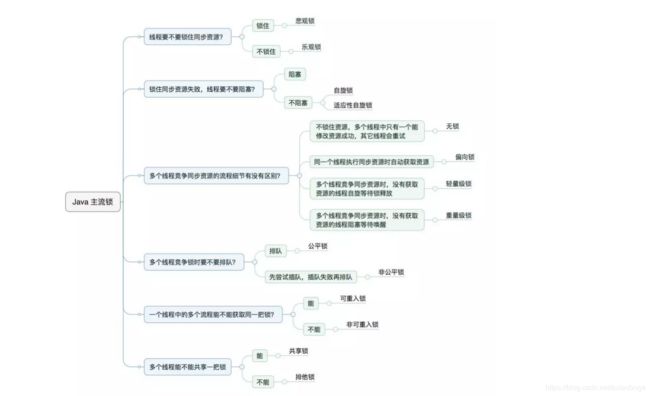
Java提供了种类丰富的锁,每种锁因其特性的不同,在适当的场景下能够展现出非常高的效率。本文旨在对锁相关源码(本文中的源码来自JDK 8)、使用场景进行举例,为读者介绍主流锁的知识点,以及不同的锁的适用场景。
Java中往往是按照是否含有某一特性来定义锁,我们通过特性将锁进行分组归类,再使用对比的方式进行介绍,帮助大家更快捷的理解相关知识。下面给出本文内容的总体分类目录:
(1)乐观锁 VS 悲观锁
乐观锁与悲观锁是一种广义上的概念,体现了看待线程同步的不同角度。在Java和数据库中都有此概念对应的实际应用。
先说概念。对于同一个数据的并发操作,悲观锁认为自己在使用数据的时候一定有别的线程来修改数据,因此在获取数据的时候会先加锁,确保数据不会被别的线程修改。Java中,synchronized关键字和Lock的实现类都是悲观锁。
而乐观锁认为自己在使用数据时不会有别的线程修改数据,所以不会添加锁,只是在更新数据的时候去判断之前有没有别的线程更新了这个数据。如果这个数据没有被更新,当前线程将自己修改的数据成功写入。如果数据已经被其他线程更新,则根据不同的实现方式执行不同的操作(例如报错或者自动重试)。
乐观锁在Java中是通过使用无锁编程来实现,最常采用的是CAS算法,Java原子类中的递增操作就通过CAS自旋实现的。

根据从上面的概念描述我们可以发现:
-
悲观锁适合写操作多的场景,先加锁可以保证写操作时数据正确。
-
乐观锁适合读操作多的场景,不加锁的特点能够使其读操作的性能大幅提升。
光说概念有些抽象,我们来看下乐观锁和悲观锁的调用方式示例:

通过调用方式示例,我们可以发现悲观锁基本都是在显式的锁定之后再操作同步资源,而乐观锁则直接去操作同步资源。
CAS全称 Compare And Swap(比较与交换),是一种无锁算法。在不使用锁(没有线程被阻塞)的情况下实现多线程之间的变量同步。java.util.concurrent包中的原子类就是通过CAS来实现了乐观锁。
CAS算法涉及到三个操作数:
-
需要读写的内存值 V。
-
进行比较的值 A。
-
要写入的新值 B。
当且仅当 V 的值等于 A 时,CAS通过原子方式用新值B来更新V的值(“比较+更新”整体是一个原子操作),否则不会执行任何操作。一般情况下,“更新”是一个不断重试的操作。
之前提到java.util.concurrent包中的原子类,就是通过CAS来实现了乐观锁,那么我们进入原子类AtomicInteger的源码,看一下AtomicInteger的定义:
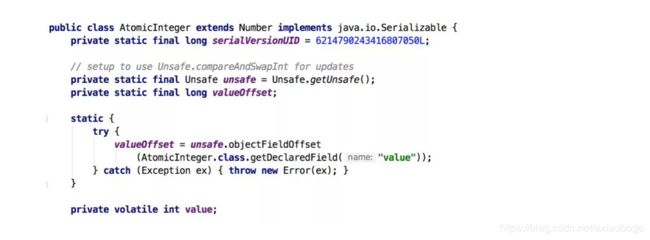
根据定义我们可以看出各属性的作用:
-
unsafe: 获取并操作内存的数据。
-
valueOffset: 存储value在AtomicInteger中的偏移量。
-
value: 存储AtomicInteger的int值,该属性需要借助volatile关键字保证其在线程间是可见的。
接下来,我们查看AtomicInteger的自增函数incrementAndGet()的源码时,发现自增函数底层调用的是unsafe.getAndAddInt()。但是由于JDK本身只有Unsafe.class,只通过class文件中的参数名,并不能很好的了解方法的作用,所以我们通过OpenJDK 8 来查看Unsafe的源码:

根据OpenJDK 8的源码我们可以看出,getAndAddInt()循环获取给定对象o中的偏移量处的值v,然后判断内存值是否等于v。如果相等则将内存值设置为 v + delta,否则返回false,继续循环进行重试,直到设置成功才能退出循环,并且将旧值返回。整个“比较+更新”操作封装在compareAndSwapInt()中,在JNI里是借助于一个CPU指令完成的,属于原子操作,可以保证多个线程都能够看到同一个变量的修改值。
后续JDK通过CPU的cmpxchg指令,去比较寄存器中的 A 和 内存中的值 V。如果相等,就把要写入的新值 B 存入内存中。如果不相等,就将内存值 V 赋值给寄存器中的值 A。然后通过Java代码中的while循环再次调用cmpxchg指令进行重试,直到设置成功为止。
CAS虽然很高效,但是它也存在三大问题,这里也简单说一下:
1. ABA问题。CAS需要在操作值的时候检查内存值是否发生变化,没有发生变化才会更新内存值。但是如果内存值原来是A,后来变成了B,然后又变成了A,那么CAS进行检查时会发现值没有发生变化,但是实际上是有变化的。ABA问题的解决思路就是在变量前面添加版本号,每次变量更新的时候都把版本号加一,这样变化过程就从“A-B-A”变成了“1A-2B-3A”。
JDK从1.5开始提供了AtomicStampedReference类来解决ABA问题,具体操作封装在compareAndSet()中。compareAndSet()首先检查当前引用和当前标志与预期引用和预期标志是否相等,如果都相等,则以原子方式将引用值和标志的值设置为给定的更新值。
2. 循环时间长开销大。CAS操作如果长时间不成功,会导致其一直自旋,给CPU带来非常大的开销。
3. 只能保证一个共享变量的原子操作。对一个共享变量执行操作时,CAS能够保证原子操作,但是对多个共享变量操作时,CAS是无法保证操作的原子性的。
Java从1.5开始JDK提供了AtomicReference类来保证引用对象之间的原子性,可以把多个变量放在一个对象里来进行CAS操作。
(2)自旋锁 VS 适应性自旋锁
在介绍自旋锁前,我们需要介绍一些前提知识来帮助大家明白自旋锁的概念。
阻塞或唤醒一个Java线程需要操作系统切换CPU状态来完成,这种状态转换需要耗费处理器时间。如果同步代码块中的内容过于简单,状态转换消耗的时间有可能比用户代码执行的时间还要长。
在许多场景中,同步资源的锁定时间很短,为了这一小段时间去切换线程,线程挂起和恢复现场的花费可能会让系统得不偿失。如果物理机器有多个处理器,能够让两个或以上的线程同时并行执行,我们就可以让后面那个请求锁的线程不放弃CPU的执行时间,看看持有锁的线程是否很快就会释放锁。
而为了让当前线程“稍等一下”,我们需让当前线程进行自旋,如果在自旋完成后前面锁定同步资源的线程已经释放了锁,那么当前线程就可以不必阻塞而是直接获取同步资源,从而避免切换线程的开销。这就是自旋锁。

自旋锁本身是有缺点的,它不能代替阻塞。自旋等待虽然避免了线程切换的开销,但它要占用处理器时间。如果锁被占用的时间很短,自旋等待的效果就会非常好。反之,如果锁被占用的时间很长,那么自旋的线程只会白浪费处理器资源。所以,自旋等待的时间必须要有一定的限度,如果自旋超过了限定次数(默认是10次,可以使用-XX:PreBlockSpin来更改)没有成功获得锁,就应当挂起线程。
自旋锁的实现原理同样也是CAS,AtomicInteger中调用unsafe进行自增操作的源码中的do-while循环就是一个自旋操作,如果修改数值失败则通过循环来执行自旋,直至修改成功。

自旋锁在JDK1.4.2中引入,使用-XX:+UseSpinning来开启。JDK 6中变为默认开启,并且引入了自适应的自旋锁(适应性自旋锁)。
自适应意味着自旋的时间(次数)不再固定,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。如果在同一个锁对象上,自旋等待刚刚成功获得过锁,并且持有锁的线程正在运行中,那么虚拟机就会认为这次自旋也是很有可能再次成功,进而它将允许自旋等待持续相对更长的时间。如果对于某个锁,自旋很少成功获得过,那在以后尝试获取这个锁时将可能省略掉自旋过程,直接阻塞线程,避免浪费处理器资源。
在自旋锁中 另有三种常见的锁形式:TicketLock、CLHlock和MCSlock,本文中仅做名词介绍,不做深入讲解,感兴趣的同学可以自行查阅相关资料。
(3) 无锁 VS 偏向锁 VS 轻量级锁 VS 重量级锁#
这四种锁是指锁的状态,专门针对synchronized的。在介绍这四种锁状态之前还需要介绍一些额外的知识。
首先为什么Synchronized能实现线程同步?
在回答这个问题之前我们需要了解两个重要的概念:“Java对象头”、“Monitor”。
Java对象头
synchronized是悲观锁,在操作同步资源之前需要给同步资源先加锁,这把锁就是存在Java对象头里的,而Java对象头又是什么呢?
我们以Hotspot虚拟机为例,Hotspot的对象头主要包括两部分数据:Mark Word(标记字段)、Klass Pointer(类型指针)。
Mark Word:默认存储对象的HashCode,分代年龄和锁标志位信息。这些信息都是与对象自身定义无关的数据,所以Mark Word被设计成一个非固定的数据结构以便在极小的空间内存存储尽量多的数据。它会根据对象的状态复用自己的存储空间,也就是说在运行期间Mark Word里存储的数据会随着锁标志位的变化而变化。
Klass Point:对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。
Monitor
Monitor可以理解为一个同步工具或一种同步机制,通常被描述为一个对象。每一个Java对象就有一把看不见的锁,称为内部锁或者Monitor锁。
Monitor是线程私有的数据结构,每一个线程都有一个可用monitor record列表,同时还有一个全局的可用列表。每一个被锁住的对象都会和一个monitor关联,同时monitor中有一个Owner字段存放拥有该锁的线程的唯一标识,表示该锁被这个线程占用。
现在话题回到synchronized,synchronized通过Monitor来实现线程同步,Monitor是依赖于底层的操作系统的Mutex Lock(互斥锁)来实现的线程同步。
如同我们在自旋锁中提到的“阻塞或唤醒一个Java线程需要操作系统切换CPU状态来完成,这种状态转换需要耗费处理器时间。如果同步代码块中的内容过于简单,状态转换消耗的时间有可能比用户代码执行的时间还要长”。这种方式就是synchronized最初实现同步的方式,这就是JDK 6之前synchronized效率低的原因。这种依赖于操作系统Mutex Lock所实现的锁我们称之为“重量级锁”,JDK 6中为了减少获得锁和释放锁带来的性能消耗,引入了“偏向锁”和“轻量级锁”。
所以目前锁一共有4种状态,级别从低到高依次是:无锁、偏向锁、轻量级锁和重量级锁。锁状态只能升级不能降级。
通过上面的介绍,我们对synchronized的加锁机制以及相关知识有了一个了解,那么下面我们给出四种锁状态对应的的Mark Word内容,然后再分别讲解四种锁状态的思路以及特点:

无锁
无锁没有对资源进行锁定,所有的线程都能访问并修改同一个资源,但同时只有一个线程能修改成功。
无锁的特点就是修改操作在循环内进行,线程会不断的尝试修改共享资源。如果没有冲突就修改成功并退出,否则就会继续循环尝试。如果有多个线程修改同一个值,必定会有一个线程能修改成功,而其他修改失败的线程会不断重试直到修改成功。上面我们介绍的CAS原理及应用即是无锁的实现。无锁无法全面代替有锁,但无锁在某些场合下的性能是非常高的。
偏向锁
偏向锁是指一段同步代码一直被一个线程所访问,那么该线程会自动获取锁,降低获取锁的代价。
在大多数情况下,锁总是由同一线程多次获得,不存在多线程竞争,所以出现了偏向锁。其目标就是在只有一个线程执行同步代码块时能够提高性能。
当一个线程访问同步代码块并获取锁时,会在Mark Word里存储锁偏向的线程ID。在线程进入和退出同步块时不再通过CAS操作来加锁和解锁,而是检测Mark Word里是否存储着指向当前线程的偏向锁。引入偏向锁是为了在无多线程竞争的情况下尽量减少不必要的轻量级锁执行路径,因为轻量级锁的获取及释放依赖多次CAS原子指令,而偏向锁只需要在置换ThreadID的时候依赖一次CAS原子指令即可。
偏向锁只有遇到其他线程尝试竞争偏向锁时,持有偏向锁的线程才会释放锁,线程不会主动释放偏向锁。偏向锁的撤销,需要等待全局安全点(在这个时间点上没有字节码正在执行),它会首先暂停拥有偏向锁的线程,判断锁对象是否处于被锁定状态。撤销偏向锁后恢复到无锁(标志位为“01”)或轻量级锁(标志位为“00”)的状态。
偏向锁在JDK 6及以后的JVM里是默认启用的。可以通过JVM参数关闭偏向锁:-XX:-UseBiasedLocking=false,关闭之后程序默认会进入轻量级锁状态。
轻量级锁
是指当锁是偏向锁的时候,被另外的线程所访问,偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,从而提高性能。
在代码进入同步块的时候,如果同步对象锁状态为无锁状态(锁标志位为“01”状态,是否为偏向锁为“0”),虚拟机首先将在当前线程的栈帧中建立一个名为锁记录(Lock Record)的空间,用于存储锁对象目前的Mark Word的拷贝,然后拷贝对象头中的Mark Word复制到锁记录中。
拷贝成功后,虚拟机将使用CAS操作尝试将对象的Mark Word更新为指向Lock Record的指针,并将Lock Record里的owner指针指向对象的Mark Word。
如果这个更新动作成功了,那么这个线程就拥有了该对象的锁,并且对象Mark Word的锁标志位设置为“00”,表示此对象处于轻量级锁定状态。
如果轻量级锁的更新操作失败了,虚拟机首先会检查对象的Mark Word是否指向当前线程的栈帧,如果是就说明当前线程已经拥有了这个对象的锁,那就可以直接进入同步块继续执行,否则说明多个线程竞争锁。
若当前只有一个等待线程,则该线程通过自旋进行等待。但是当自旋超过一定的次数,或者一个线程在持有锁,一个在自旋,又有第三个来访时,轻量级锁升级为重量级锁。
重量级锁
升级为重量级锁时,锁标志的状态值变为“10”,此时Mark Word中存储的是指向重量级锁的指针,此时等待锁的线程都会进入阻塞状态。
整体的锁状态升级流程如下:

综上,偏向锁通过对比Mark Word解决加锁问题,避免执行CAS操作。而轻量级锁是通过用CAS操作和自旋来解决加锁问题,避免线程阻塞和唤醒而影响性能。重量级锁是将除了拥有锁的线程以外的线程都阻塞。
(4)公平锁 VS 非公平锁
公平锁是指多个线程按照申请锁的顺序来获取锁,线程直接进入队列中排队,队列中的第一个线程才能获得锁。公平锁的优点是等待锁的线程不会饿死。缺点是整体吞吐效率相对非公平锁要低,等待队列中除第一个线程以外的所有线程都会阻塞,CPU唤醒阻塞线程的开销比非公平锁大。
非公平锁是多个线程加锁时直接尝试获取锁,获取不到才会到等待队列的队尾等待。但如果此时锁刚好可用,那么这个线程可以无需阻塞直接获取到锁,所以非公平锁有可能出现后申请锁的线程先获取锁的场景。非公平锁的优点是可以减少唤起线程的开销,整体的吞吐效率高,因为线程有几率不阻塞直接获得锁,CPU不必唤醒所有线程。缺点是处于等待队列中的线程可能会饿死,或者等很久才会获得锁。
直接用语言描述可能有点抽象,这里作者用从别处看到的一个例子来讲述一下公平锁和非公平锁。
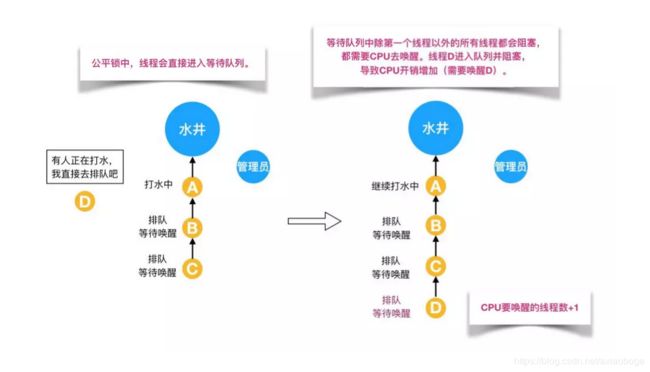
如上图所示,假设有一口水井,有管理员看守,管理员有一把锁,只有拿到锁的人才能够打水,打完水要把锁还给管理员。每个过来打水的人都要管理员的允许并拿到锁之后才能去打水,如果前面有人正在打水,那么这个想要打水的人就必须排队。管理员会查看下一个要去打水的人是不是队伍里排最前面的人,如果是的话,才会给你锁让你去打水;如果你不是排第一的人,就必须去队尾排队,这就是公平锁。
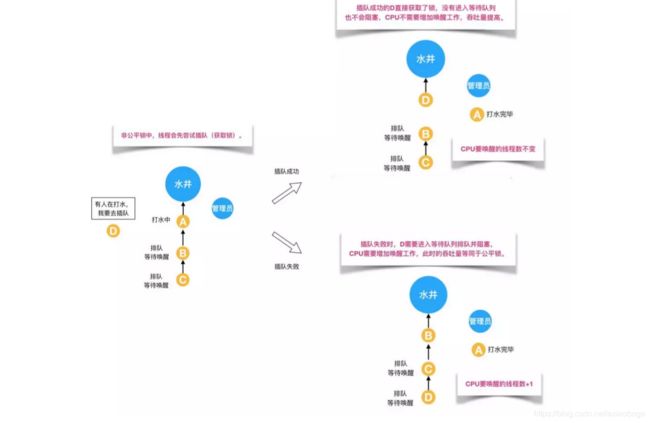
但是对于非公平锁,管理员对打水的人没有要求。即使等待队伍里有排队等待的人,但如果在上一个人刚打完水把锁还给管理员而且管理员还没有允许等待队伍里下一个人去打水时,刚好来了一个插队的人,这个插队的人是可以直接从管理员那里拿到锁去打水,不需要排队,原本排队等待的人只能继续等待。如下图所示:
接下来我们通过ReentrantLock的源码来讲解公平锁和非公平锁。
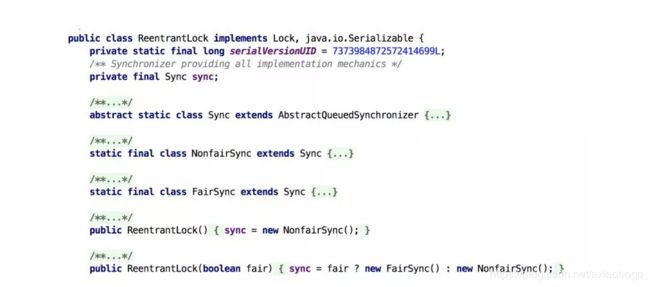
根据代码可知,ReentrantLock里面有一个内部类Sync,Sync继承AQS(AbstractQueuedSynchronizer),添加锁和释放锁的大部分操作实际上都是在Sync中实现的。它有公平锁FairSync和非公平锁NonfairSync两个子类。ReentrantLock默认使用非公平锁,也可以通过构造器来显示的指定使用公平锁。
下面我们来看一下公平锁与非公平锁的加锁方法的源码:

通过上图中的源代码对比,我们可以明显的看出公平锁与非公平锁的lock()方法唯一的区别就在于公平锁在获取同步状态时多了一个限制条件:hasQueuedPredecessors()。

再进入hasQueuedPredecessors(),可以看到该方法主要做一件事情:主要是判断当前线程是否位于同步队列中的第一个。如果是则返回true,否则返回false。
综上,公平锁就是通过同步队列来实现多个线程按照申请锁的顺序来获取锁,从而实现公平的特性。非公平锁加锁时不考虑排队等待问题,直接尝试获取锁,所以存在后申请却先获得锁的情况。
(5)可重入锁 VS 非可重入锁
可重入锁又名递归锁,是指在同一个线程在外层方法获取锁的时候,再进入该线程的内层方法会自动获取锁(前提锁对象得是同一个对象或者class),不会因为之前已经获取过还没释放而阻塞。Java中ReentrantLock和synchronized都是可重入锁,可重入锁的一个优点是可一定程度避免死锁。下面用示例代码来进行分析:

在上面的代码中,类中的两个方法都是被内置锁synchronized修饰的,doSomething()方法中调用doOthers()方法。因为内置锁是可重入的,所以同一个线程在调用doOthers()时可以直接获得当前对象的锁,进入doOthers()进行操作。
如果是一个不可重入锁,那么当前线程在调用doOthers()之前需要将执行doSomething()时获取当前对象的锁释放掉,实际上该对象锁已被当前线程所持有,且无法释放。所以此时会出现死锁。
而为什么可重入锁就可以在嵌套调用时可以自动获得锁呢?我们通过图示和源码来分别解析一下。
还是打水的例子,有多个人在排队打水,此时管理员允许锁和同一个人的多个水桶绑定。这个人用多个水桶打水时,第一个水桶和锁绑定并打完水之后,第二个水桶也可以直接和锁绑定并开始打水,所有的水桶都打完水之后打水人才会将锁还给管理员。这个人的所有打水流程都能够成功执行,后续等待的人也能够打到水。这就是可重入锁。
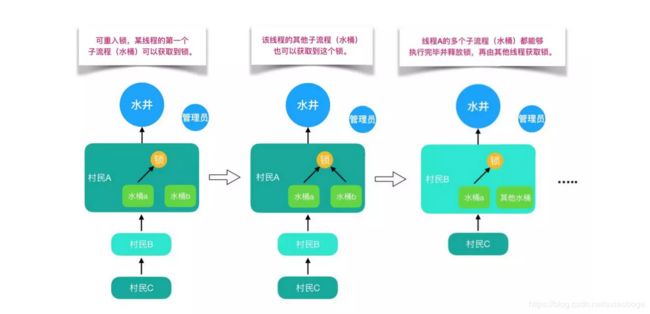
但如果是非可重入锁的话,此时管理员只允许锁和同一个人的一个水桶绑定。第一个水桶和锁绑定打完水之后并不会释放锁,导致第二个水桶不能和锁绑定也无法打水。当前线程出现死锁,整个等待队列中的所有线程都无法被唤醒。

之前我们说过ReentrantLock和synchronized都是重入锁,那么我们通过重入锁ReentrantLock以及非可重入锁NonReentrantLock的源码来对比分析一下为什么非可重入锁在重复调用同步资源时会出现死锁。
首先ReentrantLock和NonReentrantLock都继承父类AQS,其父类AQS中维护了一个同步状态status来计数重入次数,status初始值为0。
当线程尝试获取锁时,可重入锁先尝试获取并更新status值,如果status == 0表示没有其他线程在执行同步代码,则把status置为1,当前线程开始执行。如果status != 0,则判断当前线程是否是获取到这个锁的线程,如果是的话执行status+1,且当前线程可以再次获取锁。而非可重入锁是直接去获取并尝试更新当前status的值,如果status != 0的话会导致其获取锁失败,当前线程阻塞。
释放锁时,可重入锁同样先获取当前status的值,在当前线程是持有锁的线程的前提下。如果status-1 == 0,则表示当前线程所有重复获取锁的操作都已经执行完毕,然后该线程才会真正释放锁。而非可重入锁则是在确定当前线程是持有锁的线程之后,直接将status置为0,将锁释放。

(6)独享锁 VS 共享锁
独享锁和共享锁同样是一种概念。我们先介绍一下具体的概念,然后通过ReentrantLock和ReentrantReadWriteLock的源码来介绍独享锁和共享锁。
独享锁也叫排他锁,是指该锁一次只能被一个线程所持有。如果线程T对数据A加上排它锁后,则其他线程不能再对A加任何类型的锁。获得排它锁的线程即能读数据又能修改数据。JDK中的synchronized和JUC中Lock的实现类就是互斥锁。
共享锁是指该锁可被多个线程所持有。如果线程T对数据A加上共享锁后,则其他线程只能对A再加共享锁,不能加排它锁。获得共享锁的线程只能读数据,不能修改数据。
独享锁与共享锁也是通过AQS来实现的,通过实现不同的方法,来实现独享或者共享。
下图为ReentrantReadWriteLock的部分源码:

我们看到ReentrantReadWriteLock有两把锁:ReadLock和WriteLock,由词知意,一个读锁一个写锁,合称“读写锁”。再进一步观察可以发现ReadLock和WriteLock是靠内部类Sync实现的锁。Sync是AQS的一个子类,这种结构在CountDownLatch、ReentrantLock、Semaphore里面也都存在。
在ReentrantReadWriteLock里面,读锁和写锁的锁主体都是Sync,但读锁和写锁的加锁方式不一样。读锁是共享锁,写锁是独享锁。读锁的共享锁可保证并发读非常高效,而读写、写读、写写的过程互斥,因为读锁和写锁是分离的。所以ReentrantReadWriteLock的并发性相比一般的互斥锁有了很大提升。
那读锁和写锁的具体加锁方式有什么区别呢?
在最开始提及AQS的时候我们也提到了state字段(int类型,32位),该字段用来描述有多少线程获持有锁。
在独享锁中这个值通常是0或者1(如果是重入锁的话state值就是重入的次数),在共享锁中state就是持有锁的数量。但是在ReentrantReadWriteLock中有读、写两把锁,所以需要在一个整型变量state上分别描述读锁和写锁的数量(或者也可以叫状态)。于是将state变量“按位切割”切分成了两个部分,高16位表示读锁状态(读锁个数),低16位表示写锁状态(写锁个数)。如下图所示:

了解了概念之后我们再来看代码,先看写锁的加锁源码:

-
这段代码首先取到当前锁的个数c,然后再通过c来获取写锁的个数w。因为写锁是低16位,所以取低16位的最大值与当前的c做与运算( int w = exclusiveCount(c); ),高16位和0与运算后是0,剩下的就是低位运算的值,同时也是持有写锁的线程数目。
-
在取到写锁线程的数目后,首先判断是否已经有线程持有了锁。如果已经有线程持有了锁(c!=0),则查看当前写锁线程的数目,如果写线程数为0(即此时存在读锁)或者持有锁的线程不是当前线程就返回失败(涉及到公平锁和非公平锁的实现)。
-
如果写入锁的数量大于最大数(65535,2的16次方-1)就抛出一个Error。
-
如果当且写线程数为0(那么读线程也应该为0,因为上面已经处理c!=0的情况),并且当前线程需要阻塞那么就返回失败;如果通过CAS增加写线程数失败也返回失败。
-
如果c=0,w=0或者c>0,w>0(重入),则设置当前线程或锁的拥有者,返回成功!
tryAcquire()除了重入条件(当前线程为获取了写锁的线程)之外,增加了一个读锁是否存在的判断。如果存在读锁,则写锁不能被获取,原因在于:必须确保写锁的操作对读锁可见,如果允许读锁在已被获取的情况下对写锁的获取,那么正在运行的其他读线程就无法感知到当前写线程的操作。
因此,只有等待其他读线程都释放了读锁,写锁才能被当前线程获取,而写锁一旦被获取,则其他读写线程的后续访问均被阻塞。写锁的释放与ReentrantLock的释放过程基本类似,每次释放均减少写状态,当写状态为0时表示写锁已被释放,然后等待的读写线程才能够继续访问读写锁,同时前次写线程的修改对后续的读写线程可见。
接着是读锁的代码:
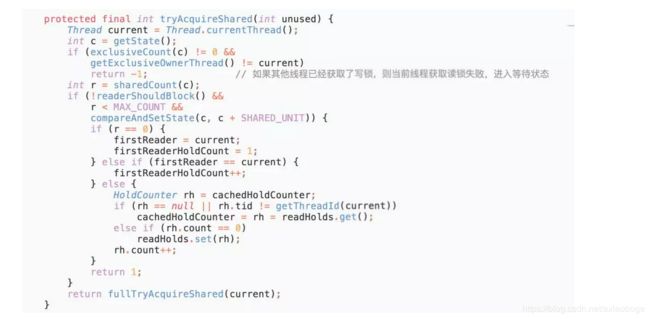
可以看到在tryAcquireShared(int unused)方法中,如果其他线程已经获取了写锁,则当前线程获取读锁失败,进入等待状态。如果当前线程获取了写锁或者写锁未被获取,则当前线程(线程安全,依靠CAS保证)增加读状态,成功获取读锁。读锁的每次释放(线程安全的,可能有多个读线程同时释放读锁)均减少读状态,减少的值是“1<<16”。所以读写锁才能实现读读的过程共享,而读写、写读、写写的过程互斥。
此时,我们再回头看一下互斥锁ReentrantLock中公平锁和非公平锁的加锁源码:

我们发现在ReentrantLock虽然有公平锁和非公平锁两种,但是它们添加的都是独享锁。根据源码所示,当某一个线程调用lock方法获取锁时,如果同步资源没有被其他线程锁住,那么当前线程在使用CAS更新state成功后就会成功抢占该资源。而如果公共资源被占用且不是被当前线程占用,那么就会加锁失败。所以可以确定ReentrantLock无论读操作还是写操作,添加的锁都是都是独享锁。
(7) 独享锁/共享锁
独享锁是指该锁一次只能被一个线程所持有。
共享锁是指该锁可被多个线程所持有。
对于Java ReentrantLock而言,其是独享锁。但是对于Lock的另一个实现类ReadWriteLock,其读锁是共享锁,其写锁是独享锁。
读锁的共享锁可保证并发读是非常高效的,读写,写读,写写的过程是互斥的。
独享锁与共享锁也是通过AQS来实现的,通过实现不同的方法,来实现独享或者共享。
对于Synchronized而言,当然是独享锁。
(8)互斥锁/读写锁
上面讲的独享锁/共享锁就是一种广义的说法,互斥锁/读写锁就是具体的实现。
互斥锁在Java中的具体实现就是ReentrantLock。
读写锁在Java中的具体实现就是ReadWriteLock。
(9)分段锁
分段锁其实是一种锁的设计,并不是具体的一种锁,对于ConcurrentHashMap而言,其并发的实现就是通过分段锁的形式来实现高效的并发操作。
我们以ConcurrentHashMap来说一下分段锁的含义以及设计思想,ConcurrentHashMap中的分段锁称为Segment,它即类似于HashMap(JDK7和JDK8中HashMap的实现)的结构,即内部拥有一个Entry数组,数组中的每个元素又是一个链表;同时又是一个ReentrantLock(Segment继承了ReentrantLock)。
当需要put元素的时候,并不是对整个hashmap进行加锁,而是先通过hashcode来知道他要放在哪一个分段中,然后对这个分段进行加锁,所以当多线程put的时候,只要不是放在一个分段中,就实现了真正的并行的插入。
但是,在统计size的时候,可就是获取hashmap全局信息的时候,就需要获取所有的分段锁才能统计。
分段锁的设计目的是细化锁的粒度,当操作不需要更新整个数组的时候,就仅仅针对数组中的一项进行加锁操作。
三十四、公平锁与非公平锁
公平锁:多个线程按照申请锁的顺序去获得锁,线程会直接进入队列去排队,永远都是队列的第一位才能得到锁。
- 优点:所有的线程都能得到资源,不会饿死在队列中。
- 缺点:吞吐量会下降很多,队列里面除了第一个线程,其他的线程都会阻塞,cpu唤醒阻塞线程的开销会很大。
非公平锁:多个线程去获取锁的时候,会直接去尝试获取,获取不到,再去进入等待队列,如果能获取到,就直接获取到锁。
- 优点:可以减少CPU唤醒线程的开销,整体的吞吐效率会高点,CPU也不必取唤醒所有线程,会减少唤起线程的数量。
- 缺点:你们可能也发现了,这样可能导致队列中间的线程一直获取不到锁或者长时间获取不到锁,导致饿死。
三十五、lock()

(1)Lock和ReadWriteLock是两大锁的根接口,Lock代表实现类是ReentrantLock(可重入锁),ReadWriteLock(读写锁)的代表实现类是ReentrantReadWriteLock。
Lock 接口支持那些语义不同(重入、公平等)的锁规则,可以在非阻塞式结构的上下文(包括 hand-over-hand 和锁重排算法)中使用这些规则。主要的实现是 ReentrantLock。
ReadWriteLock 接口以类似方式定义了一些读取者可以共享而写入者独占的锁。此包只提供了一个实现,即 ReentrantReadWriteLock,因为它适用于大部分的标准用法上下文。但程序员可以创建自己的、适用于非标准要求的实现。
(2)Condition 接口描述了可能会与锁有关联的条件变量。这些变量在用法上与使用 Object.wait 访问的隐式监视器类似,但提供了更强大的功能。需要特别指出的是,单个 Lock 可能与多个 Condition 对象关联。为了避免兼容性问题,Condition 方法的名称与对应的 Object 版本中的不同。
synchronized是java中的一个关键字,也就是说是Java语言内置的特性。那么为什么会出现Lock呢?
1)Lock不是Java语言内置的,synchronized是Java语言的关键字,因此是内置特性。Lock是一个类,通过这个类可以实现同步访问;
2)Lock和synchronized有一点非常大的不同,采用synchronized不需要用户去手动释放锁,当synchronized方法或者synchronized代码块执行完之后,系统会自动让线程释放对锁的占用;而Lock则必须要用户去手动释放锁,如果没有主动释放锁,就有可能导致出现死锁现象。
synchronized 的局限性 与 Lock 的优点
如果一个代码块被synchronized关键字修饰,当一个线程获取了对应的锁,并执行该代码块时,其他线程便只能一直等待直至占有锁的线程释放锁。事实上,占有锁的线程释放锁一般会是以下三种情况之一:
1:占有锁的线程执行完了该代码块,然后释放对锁的占有;
2:占有锁线程执行发生异常,此时JVM会让线程自动释放锁;
3:占有锁线程进入 WAITING 状态从而释放锁,例如在该线程中调用wait()方法等。
试考虑以下三种情况:
Case 1 :
在使用synchronized关键字的情形下,假如占有锁的线程由于要等待IO或者其他原因(比如调用sleep方法)被阻塞了,但是又没有释放锁,那么其他线程就只能一直等待,别无他法。这会极大影响程序执行效率。因此,就需要有一种机制可以不让等待的线程一直无期限地等待下去(比如只等待一定的时间 (解决方案:tryLock(long time, TimeUnit unit)) 或者 能够响应中断 (解决方案:lockInterruptibly())),这种情况可以通过 Lock 解决。
Case 2 :
我们知道,当多个线程读写文件时,读操作和写操作会发生冲突现象,写操作和写操作也会发生冲突现象,但是读操作和读操作不会发生冲突现象。但是如果采用synchronized关键字实现同步的话,就会导致一个问题,即当多个线程都只是进行读操作时,也只有一个线程在可以进行读操作,其他线程只能等待锁的释放而无法进行读操作。因此,需要一种机制来使得当多个线程都只是进行读操作时,线程之间不会发生冲突。同样地,Lock也可以解决这种情况 (解决方案:ReentrantReadWriteLock) 。
Case 3 :
我们可以通过Lock得知线程有没有成功获取到锁 (解决方案:ReentrantLock) ,但这个是synchronized无法办到的。
上面提到的三种情形,我们都可以通过Lock来解决,但 synchronized 关键字却无能为力。事实上,Lock 是 java.util.concurrent.locks包 下的接口,Lock 实现提供了比 synchronized 关键字 更广泛的锁操作,它能以更优雅的方式处理线程同步问题。也就是说,Lock提供了比synchronized更多的功能。
// 获取锁
void lock()
// 如果当前线程未被中断,则获取锁,可以响应中断
void lockInterruptibly()
// 返回绑定到此 Lock 实例的新 Condition 实例
Condition newCondition()
// 仅在调用时锁为空闲状态才获取该锁,可以响应中断
boolean tryLock()
// 如果锁在给定的等待时间内空闲,并且当前线程未被中断,则获取锁
boolean tryLock(long time, TimeUnit unit)
// 释放锁
void unlock()下面来逐个分析Lock接口中每个方法。lock()、tryLock()、tryLock(long time, TimeUnit unit) 和 lockInterruptibly()都是用来获取锁的。unLock()方法是用来释放锁的。newCondition() 返回 绑定到此 Lock 的新的 Condition 实例 ,用于线程间的协作,详细内容请查找关键词:线程间通信与协作。
1). lock()
在Lock中声明了四个方法来获取锁,那么这四个方法有何区别呢?首先,lock()方法是平常使用得最多的一个方法,就是用来获取锁。如果锁已被其他线程获取,则进行等待。在前面已经讲到,如果采用Lock,必须主动去释放锁,并且在发生异常时,不会自动释放锁。因此,一般来说,使用Lock必须在try…catch…块中进行,并且将释放锁的操作放在finally块中进行,以保证锁一定被被释放,防止死锁的发生。通常使用Lock来进行同步的话,是以下面这种形式去使用的:
Lock lock = ...;
lock.lock();
try{
//处理任务
}catch(Exception ex){
}finally{
lock.unlock(); //释放锁
}
2). tryLock() & tryLock(long time, TimeUnit unit)
tryLock()方法是有返回值的,它表示用来尝试获取锁,如果获取成功,则返回true;如果获取失败(即锁已被其他线程获取),则返回false,也就是说,这个方法无论如何都会立即返回(在拿不到锁时不会一直在那等待)。
tryLock(long time, TimeUnit unit)方法和tryLock()方法是类似的,只不过区别在于这个方法在拿不到锁时会等待一定的时间,在时间期限之内如果还拿不到锁,就返回false,同时可以响应中断。如果一开始拿到锁或者在等待期间内拿到了锁,则返回true。
一般情况下,通过tryLock来获取锁时是这样使用的:
Lock lock = ...;
if(lock.tryLock()) {
try{
//处理任务
}catch(Exception ex){
}finally{
lock.unlock(); //释放锁
}
}else {
//如果不能获取锁,则直接做其他事情
}
3). lockInterruptibly()
lockInterruptibly()方法比较特殊,当通过这个方法去获取锁时,如果线程 正在等待获取锁,则这个线程能够 响应中断,即中断线程的等待状态。例如,当两个线程同时通过lock.lockInterruptibly()想获取某个锁时,假若此时线程A获取到了锁,而线程B只有在等待,那么对线程B调用threadB.interrupt()方法能够中断线程B的等待过程。
由于lockInterruptibly()的声明中抛出了异常,所以lock.lockInterruptibly()必须放在try块中或者在调用lockInterruptibly()的方法外声明抛出 InterruptedException,但推荐使用后者,原因稍后阐述。因此,lockInterruptibly()一般的使用形式如下:
public void method() throws InterruptedException {
lock.lockInterruptibly();
try {
//.....
}
finally {
lock.unlock();
}
}
注意,当一个线程获取了锁之后,是不会被interrupt()方法中断的。因为interrupt()方法只能中断阻塞过程中的线程而不能中断正在运行过程中的线程。因此,当通过lockInterruptibly()方法获取某个锁时,如果不能获取到,那么只有进行等待的情况下,才可以响应中断的。与 synchronized 相比,当一个线程处于等待某个锁的状态,是无法被中断的,只有一直等待下去。
Lock和syncronized的区别
synchronized是Java语言的关键字。Lock是一个类。
synchronized不需要用户去手动释放锁,发生异常或者线程结束时自动释放锁;Lock则必须要用户去手动释放锁,如果没有主动释放锁,就有可能导致出现死锁现象。
lock可以配置公平策略,实现线程按照先后顺序获取锁。
提供了trylock方法 可以试图获取锁,获取到或获取不到时,返回不同的返回值 让程序可以灵活处理。
lock()和unlock()可以在不同的方法中执行,可以实现同一个线程在上一个方法中lock()在后续的其他方法中unlock(),比syncronized灵活的多。
Lock接口抽象方法
void lock():获取锁,如果锁不可用,则出于线程调度的目的,当前线程将被禁用,并且在获取锁之前处于休眠状态。
Lock lock = ...;
lock.lock();
try{
//处理任务
}catch(Exception ex){
}finally{
lock.unlock(); //释放锁
}
boolean tryLock():如果锁可用立即返回true,如果锁不可用立即返回false;
boolean tryLock(long time, TimeUnit unit) throws InterruptedException:如果锁可用,则此方法立即返回true。 如果该锁不可用,则当前线程将出于线程调度目的而被禁用并处于休眠状态,直到发生以下三种情况之一为止:①当前线程获取到该锁;②当前线程被其他线程中断,并且支持中断获取锁;③经过指定的等待时间如果获得了锁,则返回true,没获取到锁返回false。
Lock lock = ...;
if(lock.tryLock()) {
try{
//处理任务
}catch(Exception ex){
}finally{
lock.unlock(); //释放锁
}
}else {
//如果不能获取锁,则直接做其他事情
}
void unlock():释放锁。释放锁的操作放在finally块中进行,以保证锁一定被被释放,防止死锁的发生。
ReentrantLock
重入锁也叫做递归锁,指的是同一线程 外层函数获得锁之后 ,内层递归函数仍然有获取该锁的代码,但不受影响。避免死锁问题的,synchronized也可重入。
synchronized重入测试
public class ReentrantDemo {
public synchronized void method1() {
System.out.println("synchronized method1");
method2();
}
public synchronized void method2() {
System.out.println("synchronized method2");
}
public static void main(String[] args) {
ReentrantDemo reentrantDemo = new ReentrantDemo();
reentrantDemo.method1();
}
}
ReentrantLock重入测试
public class ReentrantDemo implements Runnable {
Lock lock = new ReentrantLock();
@Override
public void run() {
set();
}
public void set() {
try {
lock.lock();
System.out.println("set 方法");
get();
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();// 必须在finally中释放
}
}
public void get() {
try {
lock.lock();
System.out.println("get 方法");
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public static void main(String[] args) {
ReentrantDemo reentrantDemo = new ReentrantDemo();
new Thread(reentrantDemo).start();
}
}
测试结果:同一个线程,首先在set方法中获取锁,然后调用get方法,get方法中重复获取同一个锁。两个方法都执行成功。
NonReentrantLock
不可重入锁,new NonReentrantLock()
public class NonLockDemo implements Runnable {
Lock lock = new NonReentrantLock();
@Override
public void run() {
set();
}
public void set() {
try {
lock.lock();
System.out.println("set 方法");
get();
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();// 必须在finally中释放
}
}
public void get() {
try {
boolean b = lock.tryLock();
if (b) {
System.out.println("get 方法");
} else {
System.out.println("get 方法获取锁失败");
}
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public static void main(String[] args) {
NonLockDemo nonLockDemo = new NonLockDemo();
new Thread(nonLockDemo).start();
}
}测试结果:同一个线程先调用set方法并获取到锁后继续调用get方法,此时set方法还未执行所得释放,在get方法中尝试获取锁时返回false。
ReentrantReadWriteLock
读写锁,可以分别获取读锁或写锁。也就是说将数据的读写操作分开,分成2个锁来分配给线程,从而使得多个线程可以同时进行读操作。读锁使用共享模式;写锁使用独占模式;读锁可以在没有写锁的时候被多个线程同时持有,写锁是独占的。当有读锁时,写锁就不能获得;而当有写锁时,除了获得写锁的这个线程可以获得读锁外,其他线程不能获得读锁
writeLock():获取写锁。
readLock():获取读锁。
执行三个线程进行读写操作,并设置一个屏障,线程依次准备就绪后未获取锁之前都在等待,当第三个线程执行 cyclicBarrier.await();后屏障解除,三个线程同时执行。
public class WriteAndReadLockTest {
private static ReentrantReadWriteLock reentrantReadWriteLock = new ReentrantReadWriteLock();
private static ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(10, 10,
60L, TimeUnit.SECONDS, new LinkedBlockingQueue());
private static CyclicBarrier cyclicBarrier = new CyclicBarrier(3);
private static int i = 100;
public static void main(String[] args) {
threadPoolExecutor.execute(()->{
read(Thread.currentThread());
});
threadPoolExecutor.execute(()->{
write(Thread.currentThread());
});
threadPoolExecutor.execute(()->{
read(Thread.currentThread());
});
threadPoolExecutor.shutdown();
}
private static void read(Thread thread) {
try {
cyclicBarrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
reentrantReadWriteLock.readLock().lock();
try {
System.out.println("读线程 "+ thread.getName() + " 开始执行, i=" + i);
Thread.sleep(1000);
System.out.println(thread.getName() +" is over!");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
reentrantReadWriteLock.readLock().unlock();
}
}
private static void write(Thread thread) {
try {
cyclicBarrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
reentrantReadWriteLock.writeLock().lock();
try {
i++;
System.out.println("写线程 "+ thread.getName() + " is doing, i=" + i);
System.out.println(thread.getName() +" is over!");
} finally {
reentrantReadWriteLock.writeLock().unlock();
}
}
}
执行结果:线程1先获取到了读锁,因为读锁时可以共享的,所有线程3也可以获取到读锁,线程1、3读操作完成后将读锁释放后,线程2才能获取到写锁并开始执行写操作。
公平锁与非公平锁
公平锁:就是很公平,在并发环境中,每个线程在获取锁时会先查看此锁维护的等待队列,如果为空,或者当前线程线程是等待队列的第一个,就占有锁,否则就会加入到等待队列中,以后会按照FIFO的规则从队列中取到自己
非公平锁:比较粗鲁,上来就直接尝试占有锁,如果尝试失败,就再采用类似公平锁那种方式
如何实现
ReentrantLock:模式是非公平锁。也可通过构造方法创建公平锁;
public ReentrantLock() {
sync = new NonfairSync();
}
public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
}ReentrantReadWriteLock:默认是非公平锁,也可以通过构造方法创建公平锁;
public ReentrantReadWriteLock() {
this(false);
}
public ReentrantReadWriteLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
readerLock = new ReadLock(this);
writerLock = new WriteLock(this);
}优缺点
非公平锁性能高于公平锁性能。首先,在恢复一个被挂起的线程与该线程真正运行之间存在着严重的延迟。而且,非公平锁能更充分的利用cpu的时间片,尽量的减少cpu空闲的状态时间。
三十六、两个线程交替打印
volatile仅仅用来保证该变量对所有线程的可见性,但不保证原子性
AtomicXXX具有原子性和可见性
synchronized和lock都可以保证原子性和可见性
两个线程交替打印奇数和偶数,最关键的是如何协作的问题。
- 打印的数可以用java里面的
atomicInteger来保证原子性; - 打印何时结束需要设置一个上限,比如打印到100结束;
public class PrintABAtomic implements IPrintAB {
// 打印何时结束需要设置一个上限,打印到100结束;
private static final int MAX_PRINT_NUM = 100;
private static final AtomicInteger atomicInteger = new AtomicInteger(0);
@Override
public void printAB() {
new Thread(() -> {
while (atomicInteger.get() < MAX_PRINT_NUM) {
// 打印偶数.
if (atomicInteger.get() % 2 == 0) {
log.info("num:" + atomicInteger.get());
atomicInteger.incrementAndGet();
}
}
}).start();
new Thread(() -> {
while (atomicInteger.get() < MAX_PRINT_NUM) {
// 打印奇数.
if (atomicInteger.get() % 2 == 1) {
log.info("num:" + atomicInteger.get());
atomicInteger.incrementAndGet();
}
}
}).start();
}
}分析一下,其实这样是有问题的,在A线程判断了while循环条件为真,假设此时是99,则B线程抢到了处理机,判断while循环条件为真,接着判断为奇数打印,此时数值+1为100,但是A线程又抢到了处理机,这是认为已经符合while循环条件,则判断100是奇数并且打印输出。
觉得这样操作是比较合理的:
package test.one;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
public class PrintABVolatile {
private static final int MAX_PRINT_NUM = 10000;
private static ReentrantLock lock = new ReentrantLock();
private static Condition t1 = lock.newCondition();
private static Condition t2 = lock.newCondition();
//保证先启动线程A
private static CountDownLatch count = new CountDownLatch(1);
public void printAB() {
//打印偶数
new Thread(() -> {
lock.lock();
count.countDown();
try {
for(int i=0;i {
try {
count.await();
} catch (InterruptedException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
lock.lock();
try {
for(int i=0;i 三十七、多线程哈希表
HashTable
单纯的使用一个synchronized进行加锁,具体相当于针对整个 HashTable对象,但是坏处就是这样的话锁冲突的概率是非常高的
如果有多个线程,线程1操作的在第一个链表上,线程2操作的元素在别的链表上,这个时候不涉及到线程安全。
此时两个线程,修改不同的变量,实际上是没有线程安全的,但是HashTable直接一把锁,锁住了,线程1去操作的时候,线程2就会被阻塞等待,这样效率就会比较低。
此外,在扩容的时候,如果某个线程T正好触发了扩容,那么这个T就倒霉了,就要负责完成整个扩容过程
ConcurrentHashMap
内部针对多线程做出了一定的优化,并不是针对整个对象加一把锁,而是分成了很多把锁~ 降低锁冲突的概率
注意:java1.8之后才是这样分的,而java1.7里采用分段锁,好几个链表公用一把锁。
1.每个链表 / 红黑树 分配一把锁
只有当两个线程恰好修改的是同一个链表/红黑树的时候才会涉及到锁冲突
2.针对读操作,ConcurrentHashMap直接不加锁!!!这是一个比较激进的手段,但是也不至于产生大问题~
但是如果是一个线程读,一个线程写,就会有一点问题?
如果读不加锁,读操作就可能会读到一个写之前的值,也可能读到一个写之后的值,还可能读到一个写中间的值…
但是在大部分的场景下,也没啥影响。
举个例子:这个时候你就在想,正好在12点这个时间点上,你展示的是修改前的数据还是修改后的数据,那个合理呢?仔细想一想,这都无所谓,都能说得通,这个时候线程不安全,也就不是啥大问题,影响不大
ConcurrentHashMap 敢这样做,就是因为大部分场景对于读的线程安全操作没有很高要求,如果要是想让读也更准确的话,优化手段应该是使用读写锁
3.ConcurrentHashMap内部也使用了广泛的CAS操作,来提高效率:
比如,获取元素个数的时候,没加锁,直接CAS;
比如,修改元素,获取对应的链表下标的时候,也是使用CAS…
4.针对扩容进行了优化
ConcurrentHashMap把扩容任务分散开了,类似于蚂蚁搬家一样,一次只扩容一点
当ConcurrentHashMap触发扩容的时候,比如说线程T触发了扩容,T线程把ConcurrentHashMap中一部分元素顺便搬运到新的hash表上去,然后线程B再搬运一部分,然后A线程也搬运一点元素到新hash表,由N个线程分批完成一点,逐渐完成扩容。
这个就可以避免把压力全给1个线程,平滑的进行过渡,从而降低整体的开销
总结
HashTable 是一个线程安全的类,它使用synchronized来锁住整张Hash表来实现线程安全,即每次锁住整张表让线程独占,相当于所有线程进行读写时都去竞争一把锁,导致效率非常低下。
ConcurrentHashMap可以做到读取数据不加锁,并且其内部的结构可以让其在进行写操作的时候能够将锁的粒度保持地尽量地小,允许多个修改操作并发进行,其关键在于使用了锁分离技术。它使用了多个锁来控制对hash表的不同部分进行的修改。只要不争夺同一把锁,它们就可以并发进行。
Map 这样的 Key Value 在软件开发中是非常经典的结构,常用于在内存中存放数据。
(1)HashMap
众所周知 HashMap 底层是基于 数组 + 链表 组成的,不过在 jdk1.7 和 1.8 中具体实现稍有不同。
Base 1.7
1.7 中的数据结构图:
HashMap 中比较核心的几个成员变量;看看分别是什么意思?
-
初始化桶大小,因为底层是数组,所以这是数组默认的大小。
-
桶最大值。
-
默认的负载因子(0.75)
-
table真正存放数据的数组。 -
Map存放数量的大小。 -
桶大小,可在初始化时显式指定。
-
负载因子,可在初始化时显式指定。
重点解释下负载因子:
由于给定的 HashMap 的容量大小是固定的,比如默认初始化16.
给定的默认容量为 16,负载因子为 0.75。Map 在使用过程中不断的往里面存放数据,当数量达到了 16 * 0.75 = 12 就需要将当前 16 的容量进行扩容,而扩容这个过程涉及到 rehash、复制数据等操作,所以非常消耗性能。
因此通常建议能提前预估 HashMap 的大小最好,尽量的减少扩容带来的性能损耗。
根据代码可以看到其实真正存放数据的是
transient Entry
这个数组,那么它又是如何定义的呢?
Entry 是 HashMap 中的一个内部类,从他的成员变量很容易看出:
-
key 就是写入时的键。
-
value 自然就是值。
-
开始的时候就提到 HashMap 是由数组和链表组成,所以这个 next 就是用于实现链表结构。
-
hash 存放的是当前 key 的 hashcode。
知晓了基本结构,那来看看其中重要的写入、获取函数:
put 方法
-
判断当前数组是否需要初始化。
-
如果 key 为空,则 put 一个空值进去。
-
根据 key 计算出 hashcode。
-
根据计算出的 hashcode 定位出所在桶。
-
如果桶是一个链表则需要遍历判断里面的 hashcode、key 是否和传入 key 相等,如果相等则进行覆盖,并返回原来的值。
-
如果桶是空的,说明当前位置没有数据存入;新增一个 Entry 对象写入当前位置。
当调用 addEntry 写入 Entry 时需要判断是否需要扩容。
如果需要就进行两倍扩充,并将当前的 key 重新 hash 并定位。
而在 createEntry 中会将当前位置的桶传入到新建的桶中,如果当前桶有值就会在位置形成链表。
get 方法
-
首先也是根据 key 计算出 hashcode,然后定位到具体的桶中。
-
判断该位置是否为链表。
-
不是链表就根据
key、key 的 hashcode是否相等来返回值。 -
为链表则需要遍历直到 key 及 hashcode 相等时候就返回值。
-
啥都没取到就直接返回 null 。
Base 1.8
不知道 1.7 的实现大家看出需要优化的点没有?
其实一个很明显的地方就是:
当 Hash 冲突严重时,在桶上形成的链表会变的越来越长,这样在查询时的效率就会越来越低;时间复杂度为
O(N)。
因此 1.8 中重点优化了这个查询效率。
1.8 HashMap 结构图:
先来看看几个核心的成员变量:
和 1.7 大体上都差不多,还是有几个重要的区别:
-
TREEIFY_THRESHOLD用于判断是否需要将链表转换为红黑树的阈值。 -
HashEntry 修改为 Node。
Node 的核心组成其实也是和 1.7 中的 HashEntry 一样,存放的都是 key value hashcode next 等数据。
put 方法
看似要比 1.7 的复杂,我们一步步拆解:
-
判断当前桶是否为空,空的就需要初始化(resize 中会判断是否进行初始化)。
-
根据当前 key 的 hashcode 定位到具体的桶中并判断是否为空,为空表明没有 Hash 冲突就直接在当前位置创建一个新桶即可。
-
如果当前桶有值( Hash 冲突),那么就要比较当前桶中的
key、key 的 hashcode与写入的 key 是否相等,相等就赋值给e,在第 8 步的时候会统一进行赋值及返回。 -
如果当前桶为红黑树,那就要按照红黑树的方式写入数据。
-
如果是个链表,就需要将当前的 key、value 封装成一个新节点写入到当前桶的后面(形成链表)。
-
接着判断当前链表的大小是否大于预设的阈值,大于时就要转换为红黑树。
-
如果在遍历过程中找到 key 相同时直接退出遍历。
-
如果
e != null就相当于存在相同的 key,那就需要将值覆盖。 -
最后判断是否需要进行扩容。
get 方法
get 方法看起来就要简单许多了。
-
首先将 key hash 之后取得所定位的桶。
-
如果桶为空则直接返回 null 。
-
否则判断桶的第一个位置(有可能是链表、红黑树)的 key 是否为查询的 key,是就直接返回 value。
-
如果第一个不匹配,则判断它的下一个是红黑树还是链表。
-
红黑树就按照树的查找方式返回值。
-
不然就按照链表的方式遍历匹配返回值。
从这两个核心方法(get/put)可以看出 1.8 中对大链表做了优化,修改为红黑树之后查询效率直接提高到了 O(logn)。
但是 HashMap 原有的问题也都存在,比如在并发场景下使用时容易出现死循环。
但是为什么呢?简单分析下。
看过上文的还记得在 HashMap 扩容的时候会调用 resize() 方法,就是这里的并发操作容易在一个桶上形成环形链表;这样当获取一个不存在的 key 时,计算出的 index 正好是环形链表的下标就会出现死循环。
如下图:
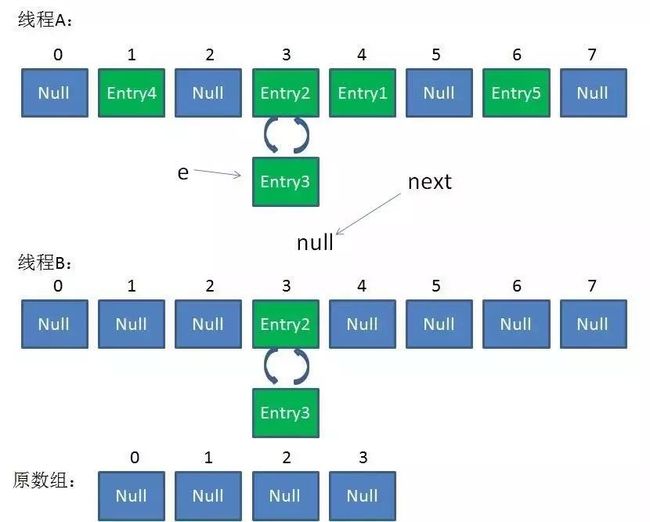
遍历方式
还有一个值得注意的是 HashMap 的遍历方式,通常有以下几种:
Iterator> entryIterator = map.entrySet().iterator();
while (entryIterator.hasNext()) {
Map.Entry next = entryIterator.next();
System.out.println("key=" + next.getKey() + " value=" + next.getValue());
}
Iterator iterator = map.keySet().iterator();
while (iterator.hasNext()){
String key = iterator.next();
System.out.println("key=" + key + " value=" + map.get(key));
} 强烈建议使用第一种 EntrySet 进行遍历。
第一种可以把 key value 同时取出,第二种还得需要通过 key 取一次 value,效率较低。
简单总结下 HashMap:无论是 1.7 还是 1.8 其实都能看出 JDK 没有对它做任何的同步操作,所以并发会出问题,甚至出现死循环导致系统不可用。
因此 JDK 推出了专项专用的 ConcurrentHashMap ,该类位于 java.util.concurrent 包下,专门用于解决并发问题。
坚持看到这里的朋友算是已经把 ConcurrentHashMap 的基础已经打牢了,下面正式开始分析。
(2)ConcurrentHashMap
ConcurrentHashMap 同样也分为 1.7 、1.8 版,两者在实现上略有不同。
Base 1.7
先来看看 1.7 的实现,下面是他的结构图:
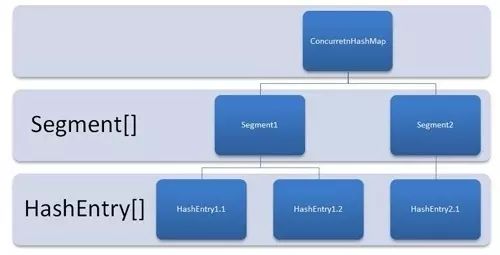
如图所示,是由 Segment 数组、HashEntry 组成,和 HashMap 一样,仍然是数组加链表。
它的核心成员变量:
Segment 是 ConcurrentHashMap 的一个内部类
其中 HashEntry 的组成和 HashMap 非常类似,唯一的区别就是其中的核心数据如 value ,以及链表都是 volatile 修饰的,保证了获取时的可见性。
原理上来说:ConcurrentHashMap 采用了分段锁技术,其中 Segment 继承于 ReentrantLock。不会像 HashTable 那样不管是 put 还是 get 操作都需要做同步处理,理论上 ConcurrentHashMap 支持 CurrencyLevel (Segment 数组数量)的线程并发。每当一个线程占用锁访问一个 Segment 时,不会影响到其他的 Segment。
put 方法
首先是通过 key 定位到 Segment,之后在对应的 Segment 中进行具体的 put。
虽然 HashEntry 中的 value 是用 volatile 关键词修饰的,但是并不能保证并发的原子性,所以 put 操作时仍然需要加锁处理。
首先第一步的时候会尝试获取锁,如果获取失败肯定就有其他线程存在竞争,则利用 scanAndLockForPut() 自旋获取锁。
1.尝试自旋获取锁。
2.如果重试的次数达到了 MAX_SCAN_RETRIES 则改为阻塞锁获取,保证能获取成功。
流程:
-
将当前 Segment 中的 table 通过 key 的 hashcode 定位到 HashEntry。
-
遍历该 HashEntry,如果不为空则判断传入的 key 和当前遍历的 key 是否相等,相等则覆盖旧的 value。
-
不为空则需要新建一个 HashEntry 并加入到 Segment 中,同时会先判断是否需要扩容。
-
最后会解除在 1 中所获取当前 Segment 的锁。
get 方法
get 逻辑比较简单:
只需要将 Key 通过 Hash 之后定位到具体的 Segment ,再通过一次 Hash 定位到具体的元素上。
由于 HashEntry 中的 value 属性是用 volatile 关键词修饰的,保证了内存可见性,所以每次获取时都是最新值。
ConcurrentHashMap 的 get 方法是非常高效的,因为整个过程都不需要加锁。
Base 1.8
1.7 已经解决了并发问题,并且能支持 N 个 Segment 这么多次数的并发,但依然存在 HashMap 在 1.7 版本中的问题。
那就是查询遍历链表效率太低。
因此 1.8 做了一些数据结构上的调整。
首先来看下底层的组成结构:
看起来是不是和 1.8 HashMap 结构类似?
其中抛弃了原有的 Segment 分段锁,而采用了 CAS + synchronized 来保证并发安全性。
也将 1.7 中存放数据的 HashEntry 改为 Node,但作用都是相同的。
其中的 val next 都用了 volatile 修饰,保证了可见性。
put 方法
重点来看看 put 函数:
-
根据 key 计算出 hashcode 。
-
判断是否需要进行初始化。
-
f即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。 -
如果当前位置的
hashcode == MOVED == -1,则需要进行扩容。 -
如果都不满足,则利用 synchronized 锁写入数据。
-
如果数量大于
TREEIFY_THRESHOLD则要转换为红黑树。
get 方法
-
根据计算出来的 hashcode 寻址,如果就在桶上那么直接返回值。
-
如果是红黑树那就按照树的方式获取值。
-
就不满足那就按照链表的方式遍历获取值。
1.8 在 1.7 的数据结构上做了大的改动,采用红黑树之后可以保证查询效率(
O(logn)),甚至取消了 ReentrantLock 改为了 synchronized,这样可以看出在新版的 JDK 中对 synchronized 优化是很到位的。