【全文翻译】EXPLAINABLE ARTIFICIAL INTELLIGENCE: UNDERSTANDING, VISUALIZING AND INTERPRETING DEEP LEARNING
Explainable artificial intelligence :understanding,...(可解释的人工智慧:理解,可视化和解释深层学习模型
-
-
-
- 1. Introduction
- 2. Why do we need explainable AI ?
- 3. Methods for visualizing, interpreting and explaining deep learning models
-
- 3.1. Sensitivity Analysis
- 3.2. Layer-Wise Relevance Propagation
- 3.3. Software
- 4. Evaluating the quality of explanations
- 5. Experimental evaluation
-
- 5.1. Image Classifification
- 5.2. Text Document Classifification
- 5.3. Human Action Recognition in Videos
- 6. Conclusion
-
-
随着大型数据库的可用性以及深度学习方法的最新改进,在越来越多的复杂任务上,人工智能系统的性能已经达到甚至超过了人类的水平。 这种发展的令人印象深刻的例子可以在诸如图像分类,情感分析,语音理解或战略游戏等领域中找到。 但是,由于它们嵌套的非线性结构,这些非常成功的机器学习和人工智能模型通常以黑匣子的方式应用,即,没有提供有关使它们准确达到其预测的信息。 由于缺乏透明度可能是主要的缺点,例如在医学应用中,用于可视化,解释和解释深度学习模型的方法的开发最近引起了越来越多的关注。 本文概述了该领域的最新发展,并呼吁在人工智能中提供更多的可解释性。 此外,它提供了两种方法来解释深度学习模型的预测,一种方法是计算预测对输入变化的敏感性,另一种方法是根据输入变量有意义地分解决策。 这些方法在三个分类任务上进行了评估。
索引词-人工智能,深度神经网络,黑匣子模型,可解释性,敏感性分析,分层关联传播
1. Introduction
过去几十年来,机器学习和人工智能领域取得了进步。 这种发展的驱动力是支持向量机的较早改进和深度学习方法的较新改进[22]。此外,大型数据库(如ImageNet[9]或Sports1M[17]的可用性)、强大的GPU卡获得的加速增益以及Caffe[15]或TensorFlow[1]等软件框架的高度灵活性也是成功的关键因素。当今基于机器学习的AI系统在许多复杂的任务上表现出色,从图像中的对象检测[14]到自然语言的理解[8]到语音信号的处理[10]。 最重要的是,最近的AI系统甚至可以在困难的战略游戏中击败专业的人类玩家,例如Go [34]和Texas德州扑克[28]。 人工智能系统的巨大成功,尤其是深度学习模型,证明了这项技术的革命性特征,这将在学术界以外产生巨大影响,还将引起行业和社会的颠覆性变化。
然而,尽管这些模型达到了令人印象深刻的预测精度,但是它们嵌套的非线性结构使它们高度不透明,即,尚不清楚输入数据中的哪些信息真正使它们做出了决策。因此,这些模型通常被视为黑匣子。 围棋顶级选手李世石(Lee Sedol)与DeepMind构建的人工智能系统AlphaGo之间的历史性围棋第二局比赛中的第37步证明了AI系统的不透明性。 AlphaGo的举动是完全出乎意料的,并且Go专家以以下方式对其进行了评论:
“这不是人的举动。 我从来没有见过有人玩这种动作。” (Fan Hui,2016)。
尽管在比赛期间尚不清楚系统为何要执行此操作,但这是AlphaGo赢得比赛的决定性步骤。 在这种情况下,AlphaGo的黑匣子特征无关紧要,但是在许多应用中,不可能理解和验证AI系统的决策过程是一个明显的缺点。 例如,在医学诊断中,默认情况下信任黑匣子系统的预测是不负责任的。 取而代之的是,应让每个专家都可以访问每个影响深远的决策以进行适当的验证。 同样,在自动驾驶汽车中,由于错误的预测可能会非常昂贵,因此必须确保模型对正确功能的依赖。 使用可解释和人类可解释的AI模型是提供此类保证的先决条件。更多关于解释人工智能的必要性的讨论可以在第2节找到。
毫不奇怪,“开放式”黑匣子模型技术的发展最近在社区中引起了很多关注[6、35、39、5、33、25、23、30、40、11、27]。这包括开发有助于更好地了解模型学到的知识的方法(即表现)[12、24、29]以及解释单个预测的技术[19、35、39, 5,26]。 这两类方法的教程可以在[27]中找到。 请注意,对于神经网络之外的支持向量机和其他高级机器学习技术,可扩展性也很重要[20]。
本文的主要目的是提高人们对机器学习和人工智能中可解释性必要性的认识。 这是在第2节中完成的。在第3节中,我们介绍了两种最新技术,即敏感性分析(SA)[6,35]和分层相关性传播(LRP)[5],用于根据输入变量解释AI模型的各个预测。 在第4节中讨论了如何客观评估解释质量的问题,在第5节中介绍了图像,文本和视频分类实验的结果。本文在第6节中总结了对未来工作的展望。
2. Why do we need explainable AI ?
向他人解释自己的决定背后的理由的能力是人类智力的重要方面。它不仅在社交互动中很重要,例如,一个从不透露自己意图和思想的人很可能会被视为“陌生人”,而且在教育环境中也至关重要,因为学生的目标是理解老师的推理。 此外,对决定的解释通常是建立人与人之间信任关系的先决条件,例如,当医学博士向患者解释治疗决定时。
尽管这些社交方面对于技术AI系统而言可能不太重要,但仍有许多争论支持人工智能的可解释性。 这里是最重要的:
- 系统验证:如前所述,在许多应用程序中,默认情况下,一定不能信任黑匣子系统。 例如,在医疗保健中,绝对必要的是使用可以由医学专家解释和验证的模型。 [7]的作者展示了这个领域的一个例子,在这个领域,人工智能系统被训练来预测一个人的肺炎风险,得出了完全错误的结论。 以黑匣子方式应用此模型不会减少而是增加与肺炎相关的死亡人数。 简而言之,该模型发现患有心脏病的哮喘患者死于肺炎的风险比健康人低得多。 医生会立即意识到这是不正确的,因为哮喘和炉膛问题是对恢复预后产生负面影响的因素。 但是,AI模型对哮喘或肺炎一无所知,只是从数据中得知。 在此示例中,数据在系统上受到偏见,因为与健康人相比,大多数哮喘和心脏病患者都受到严格的医学监督。 由于这种监督和这些患者敏感性的提高,该组患者死于肺炎的风险明显较低。 但是,这种相关性没有因果关系,因此不应作为决定肺炎治疗的基础。
- 系统改进:改进AI系统的第一步是了解其弱点。 显然,在黑匣子模型上进行这种弱点分析比在可解释的模型上进行难度更大。 如果人们了解模型在做什么以及为什么会得出预测,那么检测模型或数据集中的偏差(如肺炎样本)就容易得多。 此外,在比较不同的模型或体系结构时,模型的可解释性可能会有所帮助。 例如,[20,2,3]的作者观察到,模型可能具有相同的分类性能,但是在它们用作决策依据的特征方面有很大不同。 这些工作表明,确定最“合适”的模型需要具有可解释性。 甚至可以说,我们越了解我们的模型在做什么(为什么它们有时会失败),改进它们就越容易。
- 从系统中学习:由于当今的AI系统接受了数以百万计的示例训练,因此它们可能会观察到人类无法访问的数据模式,而人类只能通过有限数量的示例进行学习。 当使用可解释的人工智能系统时,我们可以尝试从人工智能系统中提取这些提炼出来的知识,以获取新的视野。 Fan Hui在上面的引用中提到了从AI系统到人类的这种知识转移的一个例子。 人工智能系统找到新的围棋策略,当然现在也被专业的人类玩家采用了。 从模型中提取信息至关重要的另一个主要任务是科学。 简而言之,物理学家,化学家和生物学家对识别自然的隐藏定律很感兴趣,而不仅仅是用黑匣子模型预测一些定律。 因此,只有可解释的模型在该领域才有用(参见[37,32])。
- 遵守法规:人工智能系统正在影响我们日常生活中越来越多的领域。 在法律方面,例如系统做出错误决定时的责任分配,最近也受到了越来越多的关注。 由于在依靠黑匣子模型时可能无法为这些法律问题找到满意的答案,因此未来的AI系统将必须变得更具解释性。 法规可能成为推动人工智慧更多解释的动力的另一个例子是个人权利。 立即受到AI系统决策影响的人员(例如,被银行拒绝贷款的人员)可能想知道为什么系统以这种方式进行决策。 仅可解释的AI系统将提供此信息。 这些担忧使欧盟适应了实施“解释权”的新法规,从而使用户可以要求解释关于她或他自己的算法决策[13]。
这些示例表明,可解释性不仅具有重要和主题性的学术意义,而且在未来的AI系统中将发挥关键作用。
3. Methods for visualizing, interpreting and explaining deep learning models
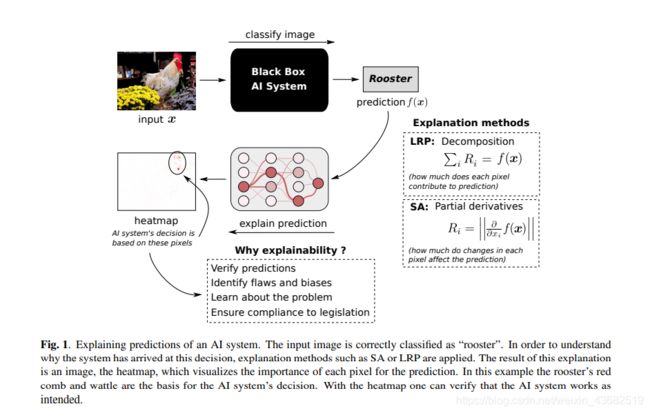
本节介绍了两种流行的技术,用于解释深度学习模型的预测。 图1总结了解释过程。首先,系统将输入图像正确分类为“公鸡”。 然后,使用解释方法来根据输入变量来解释预测。 该解释过程的结果是一个热图,可视化了每个像素对于预测的重要性。 在此示例中,公鸡的鸡冠和红色肉垂是AI系统做出决定的基础。
3.1. Sensitivity Analysis
第一种方法称为敏感度分析(SA)[6,35],它根据模型的局部评估梯度(偏导数)解释预测。 在数学上,敏感度分析将每个输入变量 i i i(例如,图像像素)的重要性量化为

此度量假定最相关的输入要素是输出对其最敏感的要素。 与下一节介绍的方法相反,灵敏度分析并不能解释函数值 f ( x ) f(x) f(x)本身,而只是解释函数值的一种变化。 以下示例说明了为什么测量功能的敏感度可能不够理想以解释AI系统的预测。
通过敏感度分析计算出的热图表明(从AI系统的角度来看)需要改变哪些像素才能使图像看起来(或多或少)与预测的类类似。 例如,在图1所示的示例中,这些像素是遮盖住公鸡一部分的黄色花朵。 以特定方式更改这些像素将重建公鸡的被遮挡部分,这很可能还会增加分类得分,因为更多的公鸡会在图像中可见。 注意,这样的热图不会指示哪些像素对于预测“公鸡”实际上是关键的。 黄色花朵的存在当然并不表示图像中有公鸡。 由于这种特性,SA在第5节中提出的定量评估实验中表现不佳。有关敏感性分析的缺点的更多讨论可以在[27]中找到。
3.2. Layer-Wise Relevance Propagation
在下文中,我们提供了一个通用框架来分解现代人工智能系统的预测,例如前馈神经网络和词袋模型[5]、长短期记忆(LSTM)网络[4]和Fisher向量分类器[20],这些都是根据输入变量进行的。与灵敏度分析相比,该方法解释了与最大不确定性状态相关的预测,即,它识别了对预测“公鸡”至关重要的像素。最近的工作[26]也显示了与泰勒分解(Taylor decomposition)的密切关系,泰勒分解是数学中一种通用的函数分析工具。
最近一种称为分层相关传播(LRP)的技术[5]通过分解来解释分类器的决策。 在数学上,它使用局部重新分配规则向后重新分配预测 f ( x ) f(x) f(x),直到为每个输入变量(例如,图像像素)分配相关性得分 R i R_i Ri。此重新分发过程的关键属性称为相关性保留,可以概括为

此属性表示,在重新分配过程的每个步骤(例如,在深度神经网络的每一层),相关性的总量(即预测 f ( x ) f(x) f(x))都得到保留。 重新分配过程中不会人为地添加或删除任何相关性。 每个输入变量的相关性分数Ri确定了该变量对预测有多大贡献。 因此,与灵敏度分析相反,LRP真正分解了函数值 f ( x ) f(x) f(x)。
在下文中,我们描述了前馈神经网络的LRP重新分配过程,还针对其他流行模型提出了重新分配程序[5,4,20]。令 x j x_j xj为第1层的神经元激活, R k R_k Rk为与第1 +1层神经元相关的关联分数, w j k w_{jk} wjk为将神经元 j j j与神经元 k k k连接的权重。 简单的LRP规则通过以下方式将相关性从 l + 1 l + 1 l+1层重新分配给 l l l层:
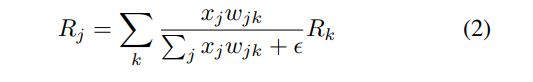
加上一个小的稳定项 ϵ \epsilon ϵ以防止被零除。 直观地,此规则基于两个标准,即从(i)神经元激活 x j x_j xj,即更多激活的神经元获得更大份额的相关性,和(ii),将相关性从 l + 1 l + 1 l+1层按比例重新分配给 l l l层中的每个神经元。 连接的强度 w j k w_{jk} wjk,即更多的关联性通过更突出的连接流动。 请注意,相关性守恒 ϵ \epsilon ϵ= 0。
“ alpha-beta”规则是[5]中引入的另一种重新分配规则:
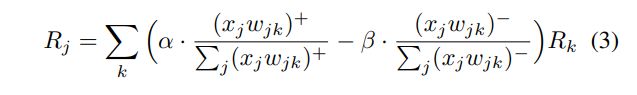
其中 ( ) + ()^+ ()+和 ( ) − ()^- ()−分别代表正数和负数。 相关性的守恒由附加约束 α − β α-β α−β= 1来强制执行。对于特殊情况 α α α= 1,[26]的作者表明,当神经网络出现神经网络功能时,这种重新分布规则与神经网络功能的“深度泰勒分解”相吻合。 网络由ReLU神经元组成。
3.3. Software
LRP工具箱[21]提供了该方法的python和matlab实现,以及与流行框架(例如Caffe和TensorFlow)的集成。 使用此工具箱,可以将LRP直接应用于其他人的模型。 工具箱代码,在线演示者以及更多信息可以在www.explain-ai.org上找到。
4. Evaluating the quality of explanations
为了比较通过不同的解释方法(例如SA和LRP)产生的热图,需要一种客观的方法来衡量解释的质量。 [31]的作者提出了一种基于摄动分析的质量度量。 该方法基于以下三个思想:
- 对输入非常重要的输入变量的扰动比对输入量较小的输入维的扰动导致预测分数的下降幅度更大。
- SA和LRP等解释方法为每个输入变量提供一个分数。 因此,可以根据该相关性得分对输入变量进行排序。
- 可以迭代扰动输入变量(从最相关的变量开始),并在每个扰动步骤之后跟踪预测分数。 预测得分的平均下降(或预测准确性的下降)可以用作解释质量的客观衡量指标,因为较大的下降表明解释方法已成功识别了真正相关的输入变量。
在以下评估中,我们使用与模型无关的每个扰动(例如,用均匀分布的随机样本替换输入值)以避免偏差。
5. Experimental evaluation
本节针对三个不同的问题对SA和LRP进行了评估,即图像的注释,文本文档的分类以及视频中人为行为的识别。
5.1. Image Classifification
在第一个实验中,我们使用最先进的深度神经网络GoogleNet模型[38]对来自ILSVRC2012 [9]数据集的一般对象进行分类。

图2(A)显示了来自该数据集的两个图像,分别正确地分类为“火山”和“咖啡杯”。 热图将SA和LRP获得的解释可视化。 咖啡杯图像的LRP热图显示,该模型已将咖啡杯的椭圆形识别为该图像类别的相关特征。在另一个示例中,山的特定形状被视为图像中存在火山的证据。 SA热图比使用LRP计算的热图大得多,并且将大值 R i R_i Ri分配给了由纯背景(例如天空)组成的区域,尽管这些像素并不能真正表示图像类别“ 火山”。 与LRP相比,SA不会指示每个像素对预测有多大贡献,而是可以确保分类器对输入变化的敏感性。 因此,与SA相比,LRP在主观上可以更好地解释模型的预测。
图2(A)的下部显示了第4节介绍的每个扰动分析的结果。y轴显示了ILSVRC2012数据集的前5040张图像的预测得分平均值的相对下降,即值0.8表示原始分数平均下降了20%。 在每个扰动步骤中,将图像的9x9色块(根据SA或LRP分数选择)替换为从均匀分布中采样的随机值。 由于使用LRP热图干扰图像时的预测分数下降要比使用SA热图时预测分数的下降快得多,因此LRP客观上也比SA提供更好的解释。关于该图像分类实验的更多讨论可以在[31]中找到。
5.2. Text Document Classifification
在该实验中,训练了一个基于词嵌入的卷积神经网络,以对20Newsgroup数据集中的文本文档进行分类。
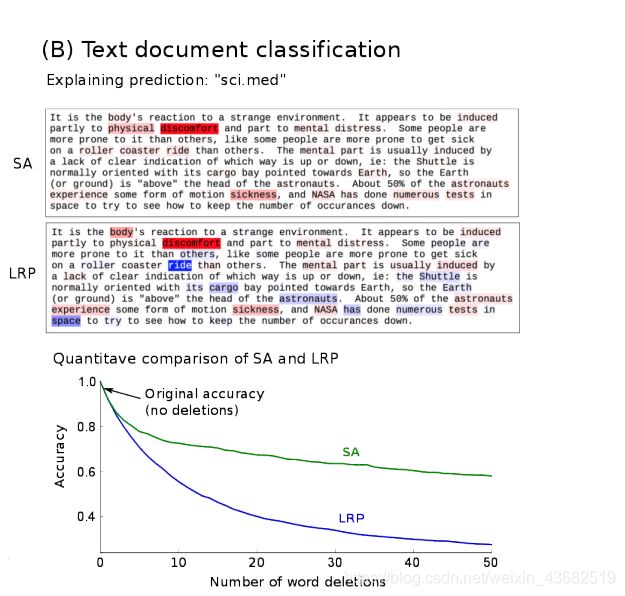
图2(B)显示了SA和LRP热图(例如,将相关分数 R i R_i Ri分配给每个单词),该图覆盖在文档的顶部,该文档被分类为主题“ sci.med”,即,假定该文本为关于医学主题。 SA和LRP这两种解释方法都表明诸如“疾病”,“身体”或“不适”之类的单词是此分类决策的基础。 与敏感性分析相反,LRP区分正(红色)和负(蓝色)词,即支持分类决策“ sci.med”的词和矛盾的词,即代表另一种类别的词(例如,“ sci.space”)。显然,诸如“骑”,“宇航员”和“航天飞机”之类的单词强烈代表主题空间,但不一定代表主题医学。通过LRP热图,我们可以看到,尽管分类器决定了正确的“ sci.med”类,但文本中有证据与此决定相矛盾。 SA方法不能区分正面证据和负面证据。图的下部显示了定量评估的结果。 y轴显示20Newsgroup数据集中超过4154个文档的预测准确性的相对降低。 在每个扰动步骤,通过将相应的输入值设置为0,删除最重要的单词(根据SA或LRP分数)。同样,该结果从数量上证实了LRP比SA提供更多的信息热图,因为与SA热图相比,这些热图导致分类准确性的下降幅度更大。
可以在[3]中找到有关此文本文档分类实验的更多讨论。
5.3. Human Action Recognition in Videos
最后一个例子演示了Fisher Vector / SVM分类器[16]的解释,该分类器经过训练可以从压缩视频中预测人类的行为。 为了减少计算成本,分类器是在逐块运动矢量(不是单个像素)上训练的。 评估是在HMDB51数据集上进行的[18]。

图2(C)显示了LRP热图叠加在视频样本的五个示例帧上。 该视频已正确分类为显示动作“仰卧起坐”。 可以看到,该模型主要集中在人的上半身周围的块上。 这是完全合理的,因为视频帧的这一部分显示的运动表示“仰卧起坐”动作,即身体的向上和向下运动。
图2(C)底部的曲线显示了(四个连续)帧的相关性分布。 可以看到,对于该人正在执行向上和向下运动的帧,相关性得分更高。 因此,LRP热图不仅可视化了视频帧内动作的相关位置(即发生相关动作的位置),而且还标识了视频序列内最相关的时间点(即相关动作发生的时间)。
关于该实验的更多讨论可以在[36]中找到。
6. Conclusion
本文探讨了人工智能的可解释性问题。 讨论了为什么黑匣子模型对于某些应用程序是不可接受的,例如在医疗领域,其中系统的错误决策可能非常有害。 此外,可解释性是解决因AI系统使用量增加而引起的法律问题的先决条件,例如在系统故障的情况下如何分配责任。由于“解释权”已经成为欧洲法律的一部分,可以预期它也将极大地促进人工智能系统的可解释性。
除了作为AI与社会之间的门户之外,解释能力还是一种强大的工具,可用于检测模型中的缺陷和数据中的偏差,验证预测,改进模型,并最终获得对当前问题的新见解。 (例如,在科学界)。
在未来的工作中,我们将研究可解释性的理论基础,特别是事后可解释性之间的联系,即,给出一个经过训练的模型,目标是解释其预测,而可解释性则直接结合到可解释性的结构中。 该模型。 此外,我们将研究新的方法以更好地了解所学的表示形式,尤其是一般化,紧凑性和可解释性之间的关系。 最后,我们将把诸如LRP之类的解释方法应用于新领域,例如通信领域,并在本文所描述的方法之外寻找这些方法的应用。