lucene查询原理
lucene查询原理
-
- 1. lucene 数据模型
- 2. lucene 查询过程
- 3. SkipList
-
- 哨兵数组 skipDoc
- docDeltaBuffer
- Lucene中使用读取跳表SkipList的过程
- 跳表查询演示
-
- 文档号:23
- 文档号:700
- 4. 倒排合并
前言:
lucene 是一个基于java实现的全文信息检索工具包,目前主流的搜索系统 Elasticsearch 和 solr 都是基于 lucene 检索功能实现的。想要理解搜索系统的实现原理,就需要深入 lucene 这一层,看看 lucene 是如何存储需要检索的数据,以及如何完成高效的数据检索。
1. lucene 数据模型
lucene 中包含四种基本的数据类型:
- index:索引,由很多的 Document 组成。相当于 mysql 的数据库
- Document:由很多的 Field 组成。相当于 mysql 的一行数据
- Field:由 Field Name 和 Field Value 组成。相当于 mysql 的字段和字段值
- Term:由很多的字节组成。一般将Text类型的 Field Value 分词之后的每个最小单元叫做 Term。
2. lucene 查询过程
在 lucene 中查询是基于 segment。每个 segment 可以看做是一个独立的 subindex,在建立索引的过程中,lucene会不断的 flush 内存中的数据持久化形成新的 segment。多个 segment也会不断的被 merge 成一个大的 segment,在老的 segment 还有查询在读取的时候,不会被删除,没有被读取且被 merge 的 segement 会被删除。这个过程类似于 LSM 数据库的 merge 过程。下面我们主要看在一个 segment 内部如何实现高效的查询。
为了方便大家理解,我们以人名字,年龄,学号为例,如何实现查某个名字(有重名)的列表。
| docid | id | name | age |
|---|---|---|---|
| 1 | 101 | Alice | 18 |
| 2 | 102 | Alice | 20 |
| 3 | 103 | Alice | 21 |
| 4 | 104 | Alan | 21 |
| 5 | 105 | Alan | 18 |
每个 document 的 name value 经过分词形成多个 term,多个 term 组成 term dictionary,如下显示基于 name 创建倒排链如下:
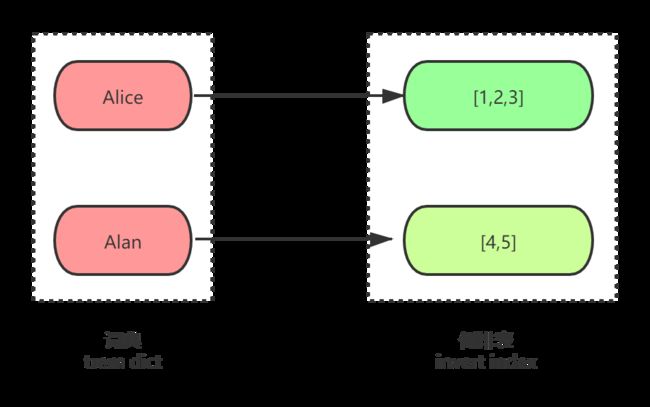
在这里,Alice、Alan 都是 term。所以倒排本质上就是基于 term 的反向列表,方便通过属性反向查找 doc_id。
到这里我们有个很自然的问题,如何快速拿到这个倒排表呢?在 lucene 里面就引入了 term dictonary 的概念,也就是 term 的字典。term 字典里我们可以按照 term 进行排序,那么用一个二分查找就可以找到这个 term 所对应的倒排表信息,这样的复杂度是 logN。
但在 term 很多,内存放不下的时候,效率还是需要进一步提升。 为解决这个问题,lucene 引用 term dict index 来存放 term 的共享前缀,后缀则放在 term dictonary 中。
- term dict index:是采用 FST 数据结构,存放在内存中。term dict index 查到对应的 term dict 的 block 位置之后,再去磁盘上找 term,大大减少了磁盘的 random access 次数
- Term dict:在磁盘上是以分 block 的方式保存的,一个 block 内部利用公共前缀压缩,比如都是 Ab 开头的单词就可以把 Ab 省去
- SkipList: 是以 docId 建立的数据结构
如果所有的 term 都是英文字符的话,可能这个 term index 就真的是 26 个英文字符表构成的了。但是实际的情况是,term 未必都是英文字符,term 可以是任意的 byte 数组。
图示如下:。

在 term dict index 中需要保存的是 Term 的前面部分字段,以及与 Term Dictionary 之间的映射关系,这使得存储的信息量减少。再结合 FST(Finite State Transducer)压缩技术,term dict index 可以被压缩到足够小,以至于可以被缓存进服务器内存中,而 Term 后缀则存放在 trem dict。
整个检索过程如下:
- 内存加载 term dict index(tip文件),通过 FST 匹配前缀找到后缀词块位置。
- 根据词块位置,读取磁盘中 Term dict(tim 文件),匹配后缀,读取倒排表信息。
- 根据倒排表位置去 doc文件 中加载文档数据。
找到了倒排表,怎么通过 docId 找到我们需要的文档呢?
3. SkipList
为了能够快速查找 docid 对应的 document,lucene 采用了SkipList 这一数据结构。SkipList 有以下几个特征:
- skipInterval:该值描述了在 level=0 层,每处理 N 篇 document 文档,就生成一个 skipDatum,该值默认为 128。
- skipMultiplier:该值描述了所有层,每处理 N 个skipDatum,就在上一层生成一个新的 skipDatum,该值默认为 8
- numberOfSkipLevels:skipList中的层数
直接给出一个生成后的跳表:
文档号0~3455的3456篇文档,我们令 skipInterval 为128,即每处理128篇文档生成一个 skipDatum 和对应的 PackedBlock;令 skipMultiplier 为3(源码中默认值为8),即每生成3个 skipDatum 就在上一层生成一个新的 skipDatum 索引,它是 3个 skipDatum 中的最后一个。对于 level > 0 的 skipDatum 都有一个索引值 SkipChildLevelPointer 字段来指向下一层对应的 skipDatum ,例如 level=1 的第一个 skipDatum(383),SkipChildLevelPointer 值就是 127、255、383。
哨兵数组 skipDoc
哨兵数组skipDoc的定义如下所示:
int[] skipDoc;
该数组用来描述每一层中正在处理的 skipDatum ,skipDatum 对应的 PackedBlock 中的最后一篇文档的文档号作为哨兵值添加到哨兵数组中,在初始化阶段,skipDoc 数组中的数组元素如下所示:
int[] skipDoc = {127, 383, 1151, 3455}
初始化阶段将每一层的第一个 skipDatum 对应的 PackedBlock 中的最后一篇文档的文档号作为哨兵值。
docDeltaBuffer
docDeltaBuffer 是一个int类型数组,上文我知道一个 skipDatum 可以映射128篇文档,而 docDeltaBuffer 记录了一个 skipDatum 中所有的文档号。
Lucene中使用读取跳表SkipList的过程
读取过程分为下面三步:
- 步骤一:获得需要更新哨兵值的层数N
- 从 skipDoc 数组的第一个哨兵值开始,依次与待处理的文档号比较,找出所有比待处理的文档号小的层
- 步骤二:从 N 层开始依次更新每一层在 skipDoc 数组中的哨兵值
- 如果待处理的文档号大于当前层的哨兵值,那么令当前层的下一个 skipDatum 对应的 PackedBlock 中的最后一篇文档的文档号作为新的哨兵值,直到待处理的文档号小于当前层的哨兵值
- 在处理 level=0 时,更新后的 skipDatum 对应的 PackedBlock 中的文档集合更新到 docDeltaBuffer 中
- 步骤三:遍历 docDeltaBuffer 数组
- 取出 PackedBlock 中的所有文档号到 docDeltaBuffer 数组中,依次与待处理的文档号作比较,判断 SkipList 中是否存在该文档号
跳表查询演示
我们依次处理下面的文档号,判断是否在跳表 SKipList 中来了解读取过程:
文档号:{23, 700}
文档号:23
更新前的skipDoc数组如下所示:
int[] skipDoc = {127, 383, 1151, 3455}
当前 skipDoc 数组对应的 SkipList 如下所示:
由于文档号 23 小于 skipDoc 数组中的所有哨兵值,故不需要更新 skipDoc 数组中的哨兵值,那么直接遍历 docDeltaBuffer,判断文档号23 是否在该数组中即可。
文档号:700
更新前的skipDoc数组如下所示:
int[] skipDoc = {127, 383, 1151, 3455}
文档号700小于1151、3455,执行了步骤一之后,判断出需要更新哨兵值的层数N为2(两层),即只要从level=1开始更新level=1以及level=0对应的skipDoc数组中的哨兵值。
对于 level=1 层,在执行了步骤二后,更新后的skipDoc数组如下所示:
int[] skipDoc = {127, 767, 1151, 3455}
随后更新 level=0 层,在执行了步骤二后,更新后的 skipDoc 数组如下所示:
int[] skipDoc = {767, 767, 1151, 3455}
这里要注意的是,level=0 层的 skipDatum 更新过程如下所示:
在更新的过程中,跳过了两个 skipDatum ,其原因是在图3中,当更新完 level=1 的 skipDatum 之后,该 skipDatum 通过它包含的SkipChildLevelPointer字段,重新设置在 level=0 层的哨兵值为 511,随后在处理 level=0 时,继续往下遍历 skipDatum 找到 767 > 700,并更新 skipDoc ,然后通过 skipDatum(767 )对应的 PackedBlock 遍历看里面是否有 doc_id = 700,有的话返回读取 doc_id = 700 的文档数据。
为啥使用跳表而不是Hash?
通过区间来查找数据这个操作,跳表天然有序的数据结构效率比 hash 高的多
4. 倒排合并
到这里还有另一个问题,那就是当我们查询中出现了 name=‘Alan’ and name=‘Alice’ limit 0,20 该如何处理?
它会拆分为 term = ‘Alan’ 和 term = 'Alice’的查询。分别得到每个term的倒排链(docId列表),再对多个倒排表做交集。那么倒排表怎么做交集呢?
水平分桶,多线程并行
有序集合1{1,3,5,7,8,9, 10,30,50,70,80,90}和有序集合2{2,3,4,5,6,7, 20,30,40,50,60,70},先进行分桶拆分【桶1的范围为[1, 9]、桶2的范围为[10, 100]、桶3的范围为[101, max_int]】,于是拆分成集合1【a={1,3,5,7,8,9}、b={10,30,50,70,80,90}、c={}】和集合2【d={2,3,4,5,6,7}、e={20,30,40,50,60,70}、e={}】,利用多线程对桶1(a和d)、桶2(b和e)、桶3(c和e)分别求交集,最后求并集。
bitmap,大大提高运算并行度,时间复杂度O(n)
假设set1{1,3,5,7,8,9}和set2{2,3,4,5,6,7}的所有元素都在桶值[1, 16]的范围之内,可以用16个bit来描述这两个集合,原集合中的元素x,在这个16bitmap中的第x个bit为1,此时两个bitmap求交集,只需要将两个bitmap进行“与”操作,结果集bitmap的3,5,7位是1,表明原集合的交集为{3,5,7}
水平分桶(每个桶内的数据一定处于一个范围之内),使用bitmap来表示集合,能极大提高求交集的效率,但时间复杂度仍旧是O(n),但bitmap需要大量连续空间,占用内存较大。